
🔍 Intro
클라우드를 이해하기 이전에, 인프라의 개념부터 잡는 것이 선행되어야 한다. 인프라를 공부하다 보면, 흔히 혼동되는 두 가지 개념이 있는데, 바로 Infrastructure와 Infrastructure Architecture이다.
이 글에서는 두 개념의 차이와 역할을 명확히 짚고, 각각의 용어가 어떤 것을 의미하는지 정리했다.
Infrastructure
-
서버, 네트워크, 스토리지 등 IT 자원 그 자체를 의미
-
실생활에 예를 들어 기차의 레일, 객차, 기관차, 역, 신호 시스템처럼
실제로 눈에 보이고 동작하는 물리적 자원과 설비다. -
Infrastructure는 서비스가 움직이기 위한 물리적/논리적 기반이며,
이 구성 요소들이 제대로 작동하지 않으면 기차는 절대 달릴 수 없다. -
클라우드 환경에서는 이 모든 인프라 자원을
가상화(Virtualization) 및 서비스화(As-a-Service) 하여 제공- 예시 서버 ➡️ AWS EC2 스토리지 ➡️ AWS S3 네트워크 ➡️ AWS VPC, Route 53 보안 구성 ➡️ IAM, Security Group 이처럼 실제로는 복잡한 인프라가 존재하지만, 사용자는 그 복잡함을 느끼지 않고 필요한 만큼만, 필요한 방식으로 사용할 수 있게 하는 것
Infra Architecture
-
서버, 네트워크, 스토리지 같은 인프라 자원들을
어떻게 배치하고 연결할지, 어떤 규칙과 목적에 따라 구성할지에 대한 설계 구조를 의미
단순히 자원을 갖고 있는 것이 아니라 그 자원들을 효율적이고 목적에 맞게 설계하는 일 -
기차 시스템에 다시 비유해보면 앞에서 인프라를 "레일, 기관차, 신호 시스템" 같은 기차 자원들이라고 했다면, Infrastructure Architecture는 이 자원들을 다음과 같이 설계하는 계획이다.
- 예시 어떤 노선으로 기차를 운영할 것인가? ➡️ 어떤 경로(VPC/Subnet)를 통해 네트워크를 구성할지 정차역은 어디에 위치해야 승객들이 효율적으로 이동할까? ➡️ 로드 밸런서, 게이트웨이, 엔드포인트 위치를 어떻게 설계할까 비상 시 우회 노선은? 정비는 어디서? ➡️ 이중화 구성, 고가용성(HA), DR(재해복구) 전략 즉, 기차 자원들이 있다고 해도, 노선, 시간표, 정차역, 우선순위, 안전 기준 등이 없다면 기차 시스템은 운영되지 못한다. 이 모든 걸 정리하는 것 : 아키텍처 -
아키텍처의 가장 중요한 요소는 비용이다.
시스템에서 가장 중요한장점은 살리고단점을 최소화하면서 비용을 최소한으로 하는 것이 중요
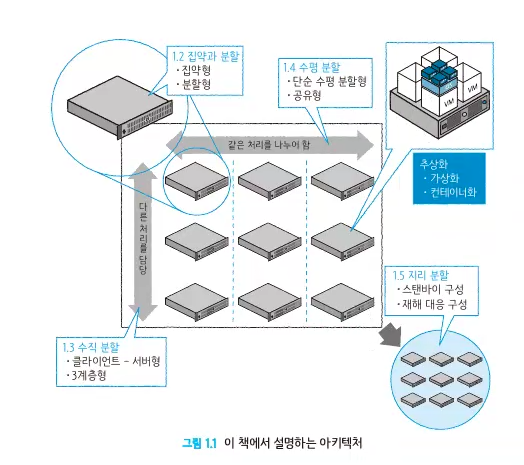
Architecture 종류
집약형
초창기에는 메인프레임환경(MF) (대형 컴퓨터를 이용해서 업무를 처리) 으로 아키텍처를 실행했다.
하나의 컴퓨터로 기업의 주요 업무를 처리하는 구조
- 예시
중앙 집중화된 머신 : 각각의 I/O(더미터미널)로 중앙에서
모든 데이터를 관리하는 거대한 컴퓨터에 처리사항을 요청하는 형태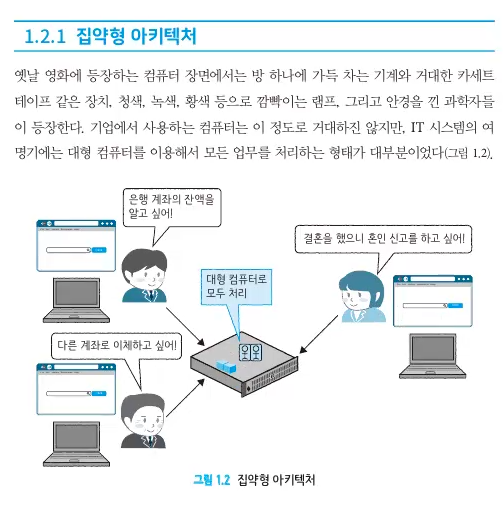
장점
- 구성이 간단하고, 컴퓨터의 주요 부품이 모두 다중화돼 있어서 하나가 고장나더라도 업무를 계속진행가능하다.
단점
- 대형 컴퓨터의 도입 비용과 유지 비용이 비싸고, 확장성에 한계가 있다.
분할형
여러대의 컴퓨터를 조합해서 하나의 시스템을 구축하는 구조(Open System)
아키텍처의 가장 중요한 요소는 투입비용 : 시스템에서 가장 중요한 장점은 살리고 단점을 최소화하면서 비용을 최소한으로 하는 것이 중요
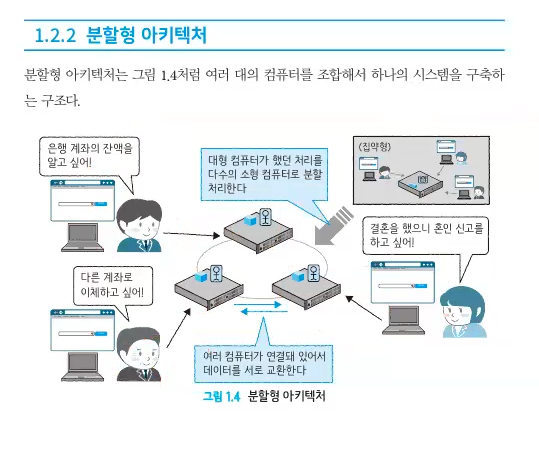
장점
-
소형 컴퓨터 사는 비용이 대형컴퓨터사는 비용보다 압도적으로 저렴하다.
-
안정성은 한 대의 컴퓨터만으로는 대형컴퓨터에 미치지 못한다.
보완하기 위해 분할형 아키텍처에서는 여러 대의 컴퓨터를 이용해 한 대가 고장 나도 안정성을 담보하고 있다.
단점
- 대수가 늘어나면 관리 구조가 복잡해지고, 한대가 망가지면 영향 범위를 최소화하기 위한 구조를 검토해야 한다.
수직 분할형 아키텍처
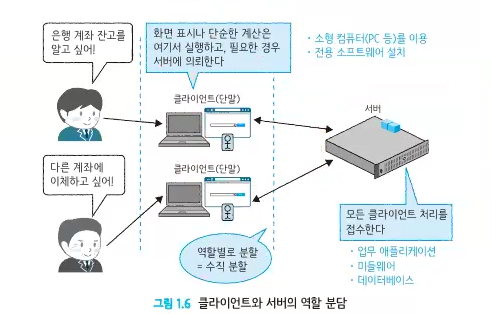
-
각각의 서버가 전혀 다른 작업을 하는 것인지, 비슷한 작업을 하는 것인지에 대한 관점
-
서버별로 다른 역할을 담당하는 수직 분할형 아키텍처 :
💡수직형이라고 표현하는 것은 특정 서버 측면에서 봤을 때, 역할에 따라 위 또는 아래 계층으로 나뉘기 때문 -
대표적인 아키텍처 : 클라이언트-서버형 아키텍처 C/S Architecher
-
클라이언트 또는 단말이라 불리는 소형 컴퓨터가 접속해서 이용하는 형태
장점
- 클라이언트 측에서 많은 처리를 실행할 수 있어서 소수의 서버로 다수의 클라이언트를 처리할 수 있다.
단점
- 클라이언트 측의 소프트웨어 정기 업데이트가 필요하고, 서버 확장성에 한계가 발생할 수 있다.
3계층형 아키텍처
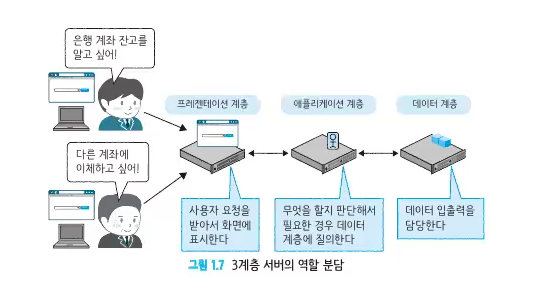
-
프레젠테이션 ➡️ 사용자 입력을 받고, 웹 브라우저 화면을 표시한다.
-
애플리케이션 계층 ➡️ 사용자 요청에 따라 업무를 처리한다.
-
데이터 계층 ➡️ 애플리케이션 계층의 요구에 따라 데이터 입출력을 한다.
장점
- C/S에 비해 서버에 부하가 집중되는 문제가 해결됨, 클라이언트 단말의 정기 업데이트 필요없음, 처리 반환에 의한 서버 부하 절감
단점
- 구조가 C/S 구성보다 복잡하다.
수평 분할형 아키텍처
-
용도가 같은 서버를 늘려나가는 방식
-
클라이언트들의 기하급수적인 증가 또는 서버의 안정성 향상을 위해 사용한다.
-
대부분의 시스템이 수직-수평 방식을 함께 채택하고 있다.
단순 수평 분할형 아키텍처
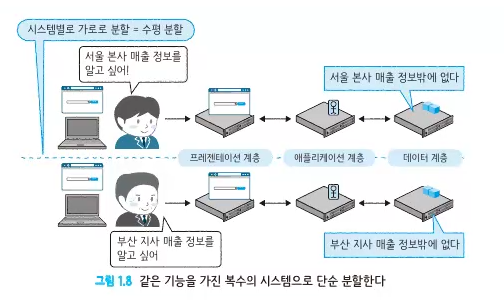
-
시스템을 둘로 분할하면 전체 처리 성능을 두 배로 향상할 수 있다. 하지만 만약 이용자의 대부분이 A쪽 시스템을 이용하고 B쪽은 한산하다면 A쪽은 과부하가 걸리고 B쪽 시스템은 놀고 있는 상태가 되어 두 배 성능을 기대하기 어렵다.
-
A 지사에서 B지사의 정보를 받아오고 싶으면 A지사가 B지사 측 시스템에 접속하면 된다.
-
수평분할을 샤딩이나 파티셔닝이라 부르기도 한다.
* 샤딩: 대용량 DB의 성능 개선을 위한 수평 분할 방법 * 파티셔닝: 로직과 기능을 기능적으로 나누는 것
장점
- 서버를 수평으로 늘리기 때문에 확장성이 좋아지고, 분할한 시스템이 독립적으로 운영되어 서로 영향을 주지 않는다.
단점
-
데이터를 일원화해서 보기 어렵다.
-
애플리케이션 업데이트를 양쪽 모두 해 줘야 한다.
-
처리량이 균등하게 분할되지 않으면 서버별 처리량 편차가 발생한다.
공유형 아키텍처
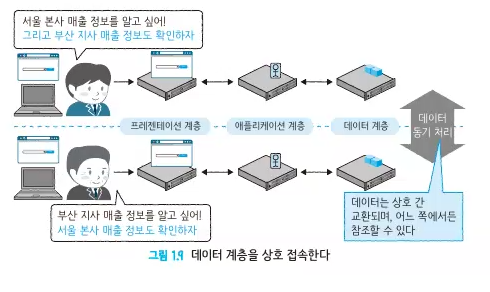
-
단순 분할형과 달리 일부 계층에서 상호접속이 이루어진다.(데이터의 동기화가 된다)
-
데이터를 모아놔야지 보안관리에 용이해지기 때문에, 데이터를 모아서 참조할 수 있다.
장점
- 수평으로 서버를 늘리기 때문에 확장성이 향상되고, 분할한 시스템이 서로 다른 시스템의 데이터를 참조할 수 있다.
단점
- 분할한 시스템 간 독립성이 낮아지고, 공유한 계층의 확장성이 낮아진다.
지리 분할형 아키텍처
- 업무 연속성 및 시스템 가용성을 높이기 위한 방식으로 지리적으로 분할하는 아키텍처
스탠바이형 아키텍처
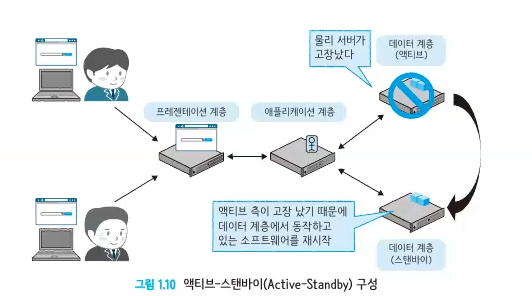
-
물리 서버를 최소 두 대를 준비하여 한 대가 고장 나면 가동 중인 소프트웨어를 다른 한 대로 운영하는 방식
-
액티브 데이터 계층과 스탠바이 데이터 계층이 같은 데이터를 공유하고, 만약 액티브가 죽으면 스탠바이에서 액티브의 역할을 대신하면서(장애조치) 소프트웨어를 재시작한다(장애복구).
-
기존 액티브에 장애가 발생하면 스탠바이는 액티브 상태, 기존 액티브는 스탠바이 상태로 변경된다.
-
장애조치는 automatic, 장애 복구는 manual인데 이유는 장애조치가 automatic으로 이루어져야 클라이언트가 데이터를 받을 때 생기는 delay를 최소화 시킬 수 있고, 장애복구가 manual인 이유는 대체된 액티브 서버가 스탠바이로 장애가 생기기 전까지 굳이 바뀔 이유가 없기 때문이다.
단점
- resource 측면에서 낭비가 발생한다.(stanby상태는 항상 대기중이기 때문에)
재해 대책형 아키텍처
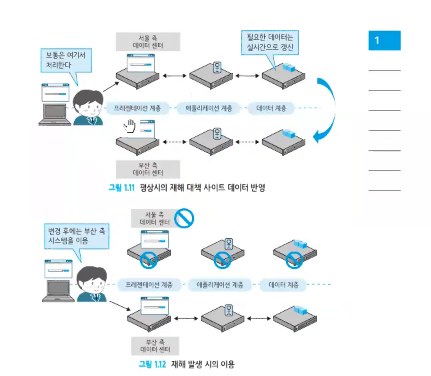
-
재해 발생에 대응하기 위한 재해 복구(DR)구성을 취하는 것
-
실시간성을 유지해서 사이트 간 동기 처리를 하여 재해발생시 서버를 우회해서 데이터를 출력한다.
💡 정리
인프라(Infra)
-
인프라는 서버, 네트워크, 스토리지 등 IT 자원 그 자체를 의미
-
기차의 레일이나 기관차, 역, 신호 시스템 같은 물리적 설비와 같다.
인프라 아키텍처(Infrastructure Architecture)
-
인프라 자원들을 어떻게 배치하고 연결할지 설계하는 구조
-
기차 노선, 정차역, 우회로 같은 운영 계획과 비슷하다.
-
효율성, 비용, 안정성 등을 고려해서 설계하는 것이 중요하다.
아키텍처 종류
-
집약형 아키텍처
하나의 대형 컴퓨터가 모든 작업을 처리하는 방식이다.
구성은 간단하지만 비용이 높고 확장성에 한계가 있다. -
분할형 아키텍처
여러 대의 컴퓨터를 조합해 시스템을 만드는 방식이다.
비용 효율적이고 안정성이 뛰어나지만 관리가 복잡할 수 있다. -
수직 분할형 아키텍처
서버별로 역할을 다르게 분리하는 구조로, 대표적으로 클라이언트-서버 모델이 있다. -
3계층형 아키텍처
프레젠테이션, 애플리케이션, 데이터 계층으로 분리해 부하 분산과 관리 효율을 높인다. -
수평 분할형 아키텍처
같은 역할의 서버를 여러 대 운영해 확장성과 안정성을 높이는 방식이다.
샤딩, 파티셔닝도 여기에 속한다. -
공유형 아키텍처
분할 시스템 간 데이터를 동기화해 참조할 수 있지만 확장성이 떨어질 수 있다. -
지리 분할형 아키텍처
지리적으로 분산해 재해 대응과 가용성을 강화하는 구조다. -
스탠바이형 아키텍처
최소 두 대의 서버를 운영해 한 대 장애 시 자동으로 대체하는 방식이다.
장애 복구는 수동으로 진행되며 리소스 낭비가 있을 수 있다. -
재해 대책형 아키텍처
재해 발생에 대비해 실시간 데이터 동기화 및 우회 구성을 갖춘 구조다.
