
소프트웨어 마에스트로 프로젝트 과정중 겪은 SQL 쿼리 최적화에 대한 생각이 담겨있다.
맞는 방향인지는 아직 의문이다. 추후에 테스트를 해볼 것이다.
참조할 테이블은 두가지 이다.
erd cloud에 정리한 ERD 테이블과, 실제 DB에 등록한 테이블 사진을 같이 첨부하겠다.
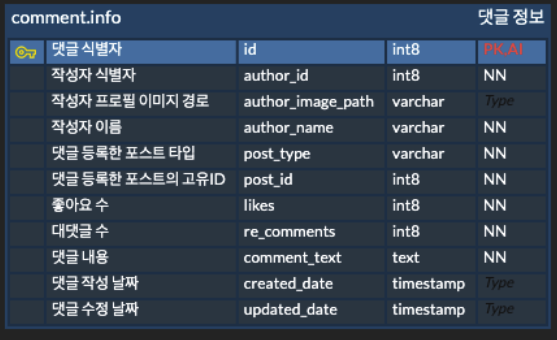
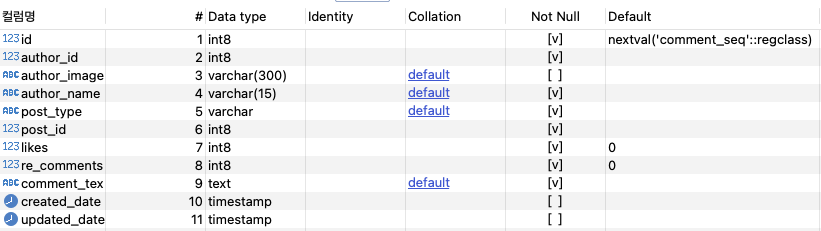
1. comment.info
comment schema에 존재하는 info 테이블로써, 게시글 종류, 게시글 고유 id 별 등록된 댓글 정보가 담겨져 있다.
쿼리에서는 alias로 COMMENT 라고 정하였다.
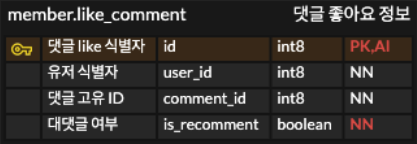
2. member.like_comment
member schema에 존재하는 like_comment 테이블로써, 유저들이 좋아요를 누른 댓글들의 정보가 담겨져 있다.
alias로 whoLikeCOMMENT 라고 정하였따.

내가 SQL로 얻고자 하는 것은 다음과 같다.
말이 길어질 것 같으니 세분화 하여 정리하겠다.
-
post_type이 '?'(MEMO,QNA..) 이면서 해당 post_type의 고유 post_id '?' 를 가지고 있는 게시글에 등록된 댓글들을 조회해야 한다.
-
조회한 댓글 중에서, 로그인한 유저가 좋아요한 댓글들을 바로 확인하기 위해서 member.like_comment (이하 별칭 whoLikeCOMMENT) 테이블과 comment.info(이하 별칭 COMMENT)테이블에서 같은 comment id를 가지는 댓글들을 가져온다.
-
가져온 댓글들 중에서 로그인한 유저가 좋아요를 했는지 확인하는 과정을 거쳐, 좋아요를 눌렀으면 댓글마다 isLike 필드에 true를, 아니면 false를 반환한다.
다음은 단계별로 이를 해결하기 위한 생각이다.
하기 힘들었던 생각은 밑줄 및 이탈릭체로 강조해보았다.
-
WHERE 절이 필요하다. WHERE절로 post_type과 post_id를 COMMENT 테이블에서 필터링하는 로직이 필요하겠다
-
로그인한 유저가 어떤 댓글에 좋아요를 했는지 알고자 한다면 whoLikeCOMMENT 테이블과의 JOIN이 필요하다. 이 테이블과 COMMENT테이블을 고유 comment id로 join하자. 이 때,
문제가 되는 것은 (inner) join을 사용하면, 좋아요 한 댓글 정보만 남는 것이 문제이다.
그렇다면 COMMENT 테이블 정보(댓글 정보)는 그대로 유지하기 위하여 COMMENT 테이블에 LEFT JOIN을 걸자.
그러면, 댓글정보는 남길 수 있고, 좋아요 정보만 그대로 합쳐진다. -
로그인한 유저가 댓글을 좋아요 했는지 알기 위해서는 join하는 과정에서부터 좋아요한 유저가 로그인한 유저인지 확인하는 과정이 필요하다.
또한 여기에서는 대댓글 정보는 제거해야 하므로, 해당 로직도 포함되어야 한다. 그 후에, join된 가상의 테이블 정보를 바탕으로 내가 좋아요를 눌렀으면 whoLikeCOMMENT.user_id 정보가 가상의 테이블에 존재할 것이므로, CASE 문법을 활용하여 is_like column을 만들고, 좋아요를 눌렀으면 true를, 누르지 않았으면 false를 반환한다.
이를 활용하여 만든 첫번쨰 쿼리는 JOIN문을 활용한 것이었다.
1. Join문 활용
SELECT
COMMENT.id,
COMMENT.author_id,
COMMENT.author_image_path,
COMMENT.author_name,
COMMENT.likes,
COMMENT.re_comments,
COMMENT.comment_text,
COMMENT.created_date,
COMMENT.updated_date,
CASE WHEN whoLikeCOMMENT.user_id = ? THEN TRUE ELSE FALSE END AS is_liked -- 로그인된 사용자가 좋아요를 했는지 확인하는 부분
FROM comment.info COMMENT
LEFT JOIN member.like_comment whoLikeCOMMENT ON
COMMENT.id = whoLikeCOMMENT.comment_id
AND whoLikeCOMMENT.user_id = ?
AND whoLikeCOMMENT.is_recomment = false
WHERE COMMENT.post_type = ?
AND COMMENT.post_id = ?
ORDER BY COMMENT.created_date;하지만 이 쿼리는 영 찝찝했다.
이유는 JOIN되는 두가지 테이블의 데이터가 너무 많아지게 된다면, JOIN 연산을 하는데에 너무 많은 비용이 들 것 같았다.
그렇다면, join연산에 들어가는 데이터의 양을 줄이는 것이 가장 필요했다.
그러기 위한 방법에는 서브쿼리를 활용하는 방법으로 해결했다.
2. 서브 쿼리 활용
SELECT
COMMENT.id,
COMMENT.author_id,
COMMENT.author_image_path,
COMMENT.author_name,
COMMENT.likes,
COMMENT.re_comments,
COMMENT.comment_text,
COMMENT.created_date,
COMMENT.updated_date,
CASE WHEN whoLikeCOMMENT.user_id = ? THEN TRUE ELSE FALSE END AS is_liked
FROM (
SELECT
id,
author_id,
author_image_path,
author_name,
likes,
re_comments,
comment_text,
created_date,
updated_date
FROM comment.info
WHERE post_type = ?
AND post_id = ?
) COMMENT
LEFT JOIN member.like_comment whoLikeCOMMENT ON
COMMENT.id = whoLikeCOMMENT.comment_id
AND whoLikeCOMMENT.user_id = ?
AND whoLikeCOMMENT.is_recomment = false
ORDER BY COMMENT.created_date;서브쿼리는 "쿼리 짜기 편해서" 작성한다 라는 인식이 강하다. 물론 나도 그랬다.
하지만, 위 쿼리처럼 작성하게 된다면, 어떤 장점이 생기는지 설득하려고 한다.
- FROM 절에 서브쿼리는 "특정 post"에 존재하는 댓글이다. 수없이 많은 포스트들 중에서 단 한가지 포스트에 존재하는 댓글들의 정보를 가져와서 Full Search 한번에 댓글 데이터를 기하 급수적으로 줄일 수 있을 것이다.
- 기하급수적으로 줄어든 댓글 정보 (가상 테이블)에 LEFT JOIN을 걸면 JOIN 비용을 훨씬 아낄 수 있을 것이다.
이러한 이유로 서브쿼리로 작성을 해보았다.
최대한 성능을 최적화하기 위한 방안으로 처음부터 잘 작성해보자 라는 마인드를 가지고 해보았지만, 실상은 그렇지 않을 수 있다.
추후에 실제로 성능을 측정해보겠다.
검증 포스트 입니다.
결론은 '차이가 없다' 입니다.
https://velog.io/@goat_hoon/여러분들은-속도를-고려하며-쿼리를-작성하고-계신가요
