
로드테스트 진행 계기
교수님께서 실제 수업시간에 저희 서비스를 사용해보시면서, 회원가입 과정에서 서버가 터져버린 문제가 있었습니다. 50명 정도의 동시 트래픽이었는데, 이를 못버티고 터져버렸죠..
그래서, 5월 10일에 1차 로드테스트를 진행하게 되었습니다.
1차 로드테스트 진행
저희 인프라 팀에서는, 세가지 정도의 가설을 세웠습니다.
- 가설1. DB I/O Log I/O 두개가 cpu를 많이 소모
- 가설2. 로그 수집하는 컨테이너 또한 CPU를 많이 사용할 것이다.
- 가설3. 회원가입 request 처리가 그냥 오래걸린다.
저희 1차 로드테스트에서는 Log I/O에 집중하면서 테스트를 진행하였습니다 (1,2번 가설 증명)
로드테스트는 크게 두가지로 이뤄졌습니다.
- 문제가 있었던 회원가입 Post의 로드테스트
- 서비스의 Key Feature인 코드 채점 로드테스트
두가지의 로드테스트에서 로그 I/O를 백엔드 코드에서 직접 설정하면서 진행하였습니다.
1차 로드테스트 결과
(1) 회원가입 API 테스트
| 회원가입 성공, 로그 출력 O | 회원가입 실패, 로그 출력 X | 회원가입 성공, 로그 출력 X | |
|---|---|---|---|
| 10vus, 10s | avg=629.82ms | ||
| 100vus, 10s | avg=6.84s max=26.36s | avg=183.89ms | |
| 100vus, 30s | avg=372.84ms | ||
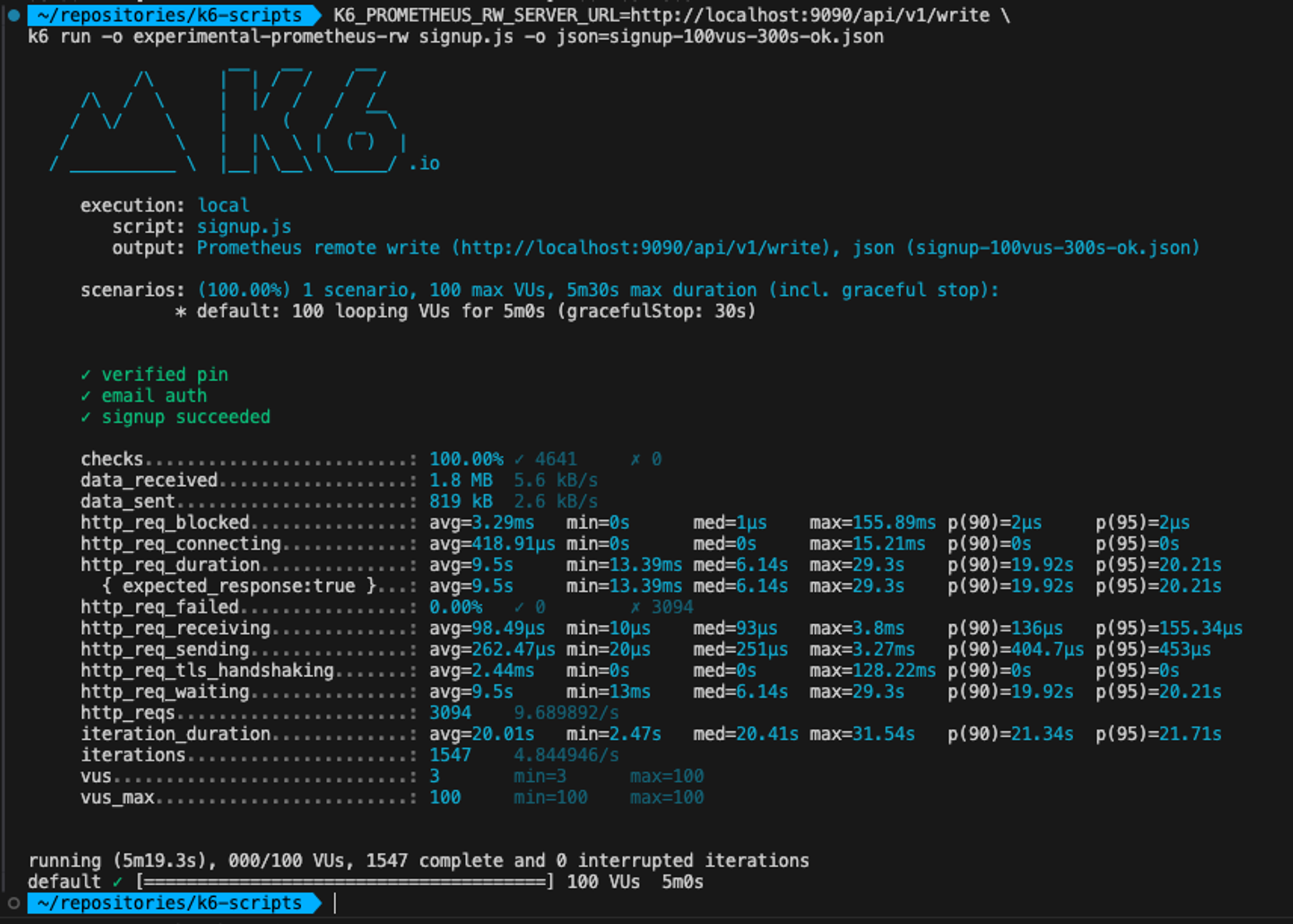
| 100vus, 300s | avg=9.5s, max = 29.3s | avg=9.62s, max = 29.4s |
로그 출력을 키고, 회원가입 성공의 100명의 요청을 10초동안 처리하는데 평균 6초가 걸렸습니다. 눈으로 봐도 느린 시간입니다. 게다가 최대 response time은 26초였습니다.
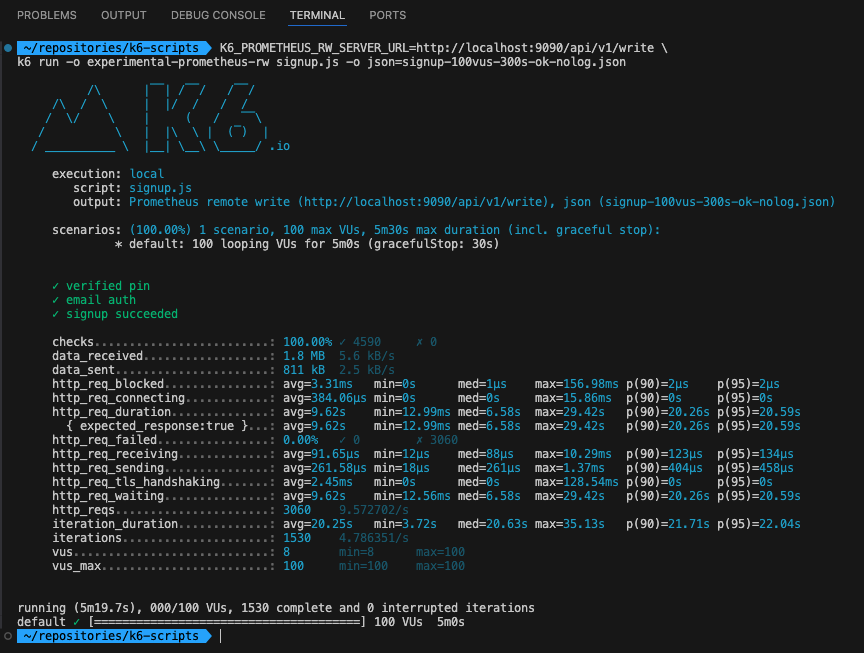
추가적으로 100명의 요청을 300초동안 보냈을때, 로그 출력 유무를 변인으로 비교해보면, 비슷한 결과가 나오게 되었습니다. 아래 사진은 로그를 키고한 결과와 끄고한 결과입니다.
(On)
(Off)
(2) 코드 제출 API
| 10vus, 10s | avg=76.32ms |
|---|---|
| 100vus, 10s | avg=448.85ms |
아래 사진은 100명의 user가 10초동안 보냈을때의 결과입니다.
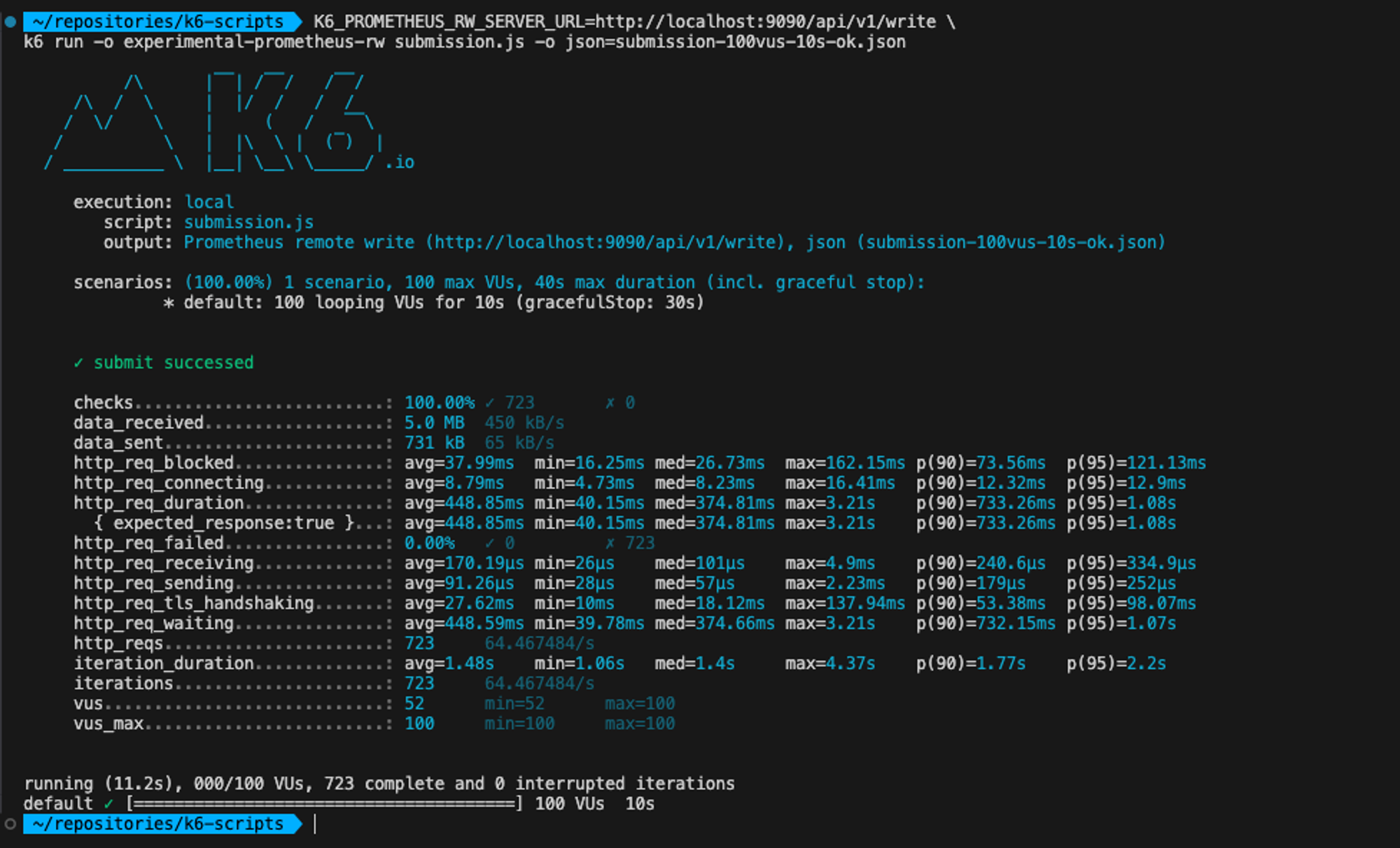
코드제출은 회원가입에 비해 굉장히 적은 response time 결과가 도출되었습니다.
결론
- 가설1. DB I/O Log I/O 두개가 cpu를 많이 소모 ❌
→ 차이 없음 - 가설2. 로그 수집하는 컨테이너 또한 CPU를 많이 사용할 것이다. ❌
→ 이 부분은 언급하진 않았지만, 실제 서버안에서 컨테이너 환경의 metric을docker stats로 관찰한 결과 CPU를 적게 사용하는 것으로 관찰하였습니다. - 가설3. 회원가입 request 처리가 그냥 오래 걸려서. ❓
그렇다면 “가설3. 회원가입 request 처리가 오래 걸려서” 를 검증하기 위한 로드테스트를 한번 더 진행할 계획을 세웠습니다.
또한, 코드제출과 회원가입이 무슨 차이가 있는지에도 주목하였습니다.
1차 로드테스트의 분석
2차 로드테스트를 진행하기에 앞서, 1차 로드테스트의 결과를 면밀히 분석해보았습니다.
포인트로 삼았던 지점은 두가지 입니다.
- 100명의 user가 300초동안 보내도, request가 3094번만 갔다는 점.
- 회원가입과 코드제출 API의 Response Time이 같은 Post 요청임에도 유의미하게 차이가 난다는 점
이 두가지 측면에 집중하며 딥다이브 해보았습니다.
결국, 커넥션 개수의 문제일 것이다.
100명의 user가 1초에 한번씩 300초동안 요청을 동시에 보내면, 100 * 300 = 30000인데 고작 10%의 요청만 처리가 되었다는 것은 서버와 DB간의 Connection 병목이 생겼을 것이라고 생각하였고, 이는 Connection Pool 개수의 문제라고 생각하였습니다. 이를 알아보기 위해 RDS Metric정보를 살펴보았습니다.
대시보드에 있는 대표적인 28개의 Metric 정보만 가져와봤습니다. (빨간색 박스가 더욱 주목한 부분입니다)
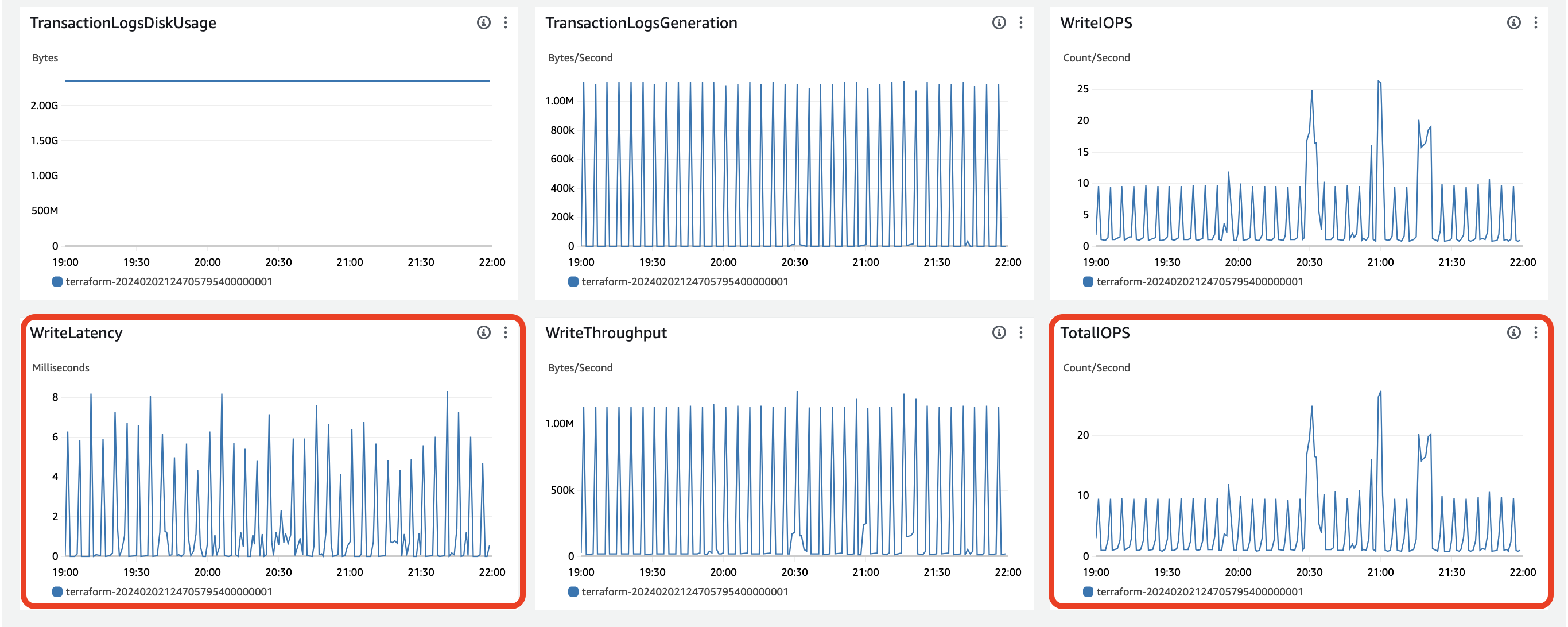
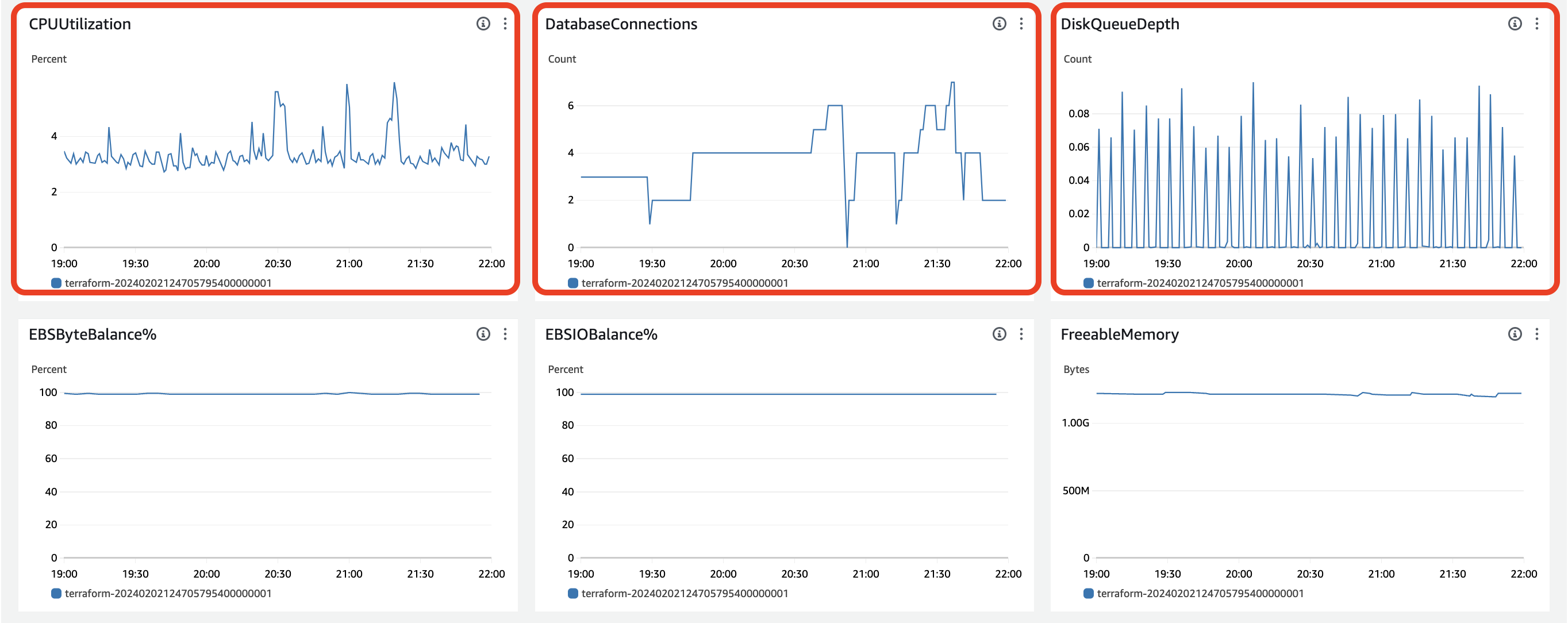
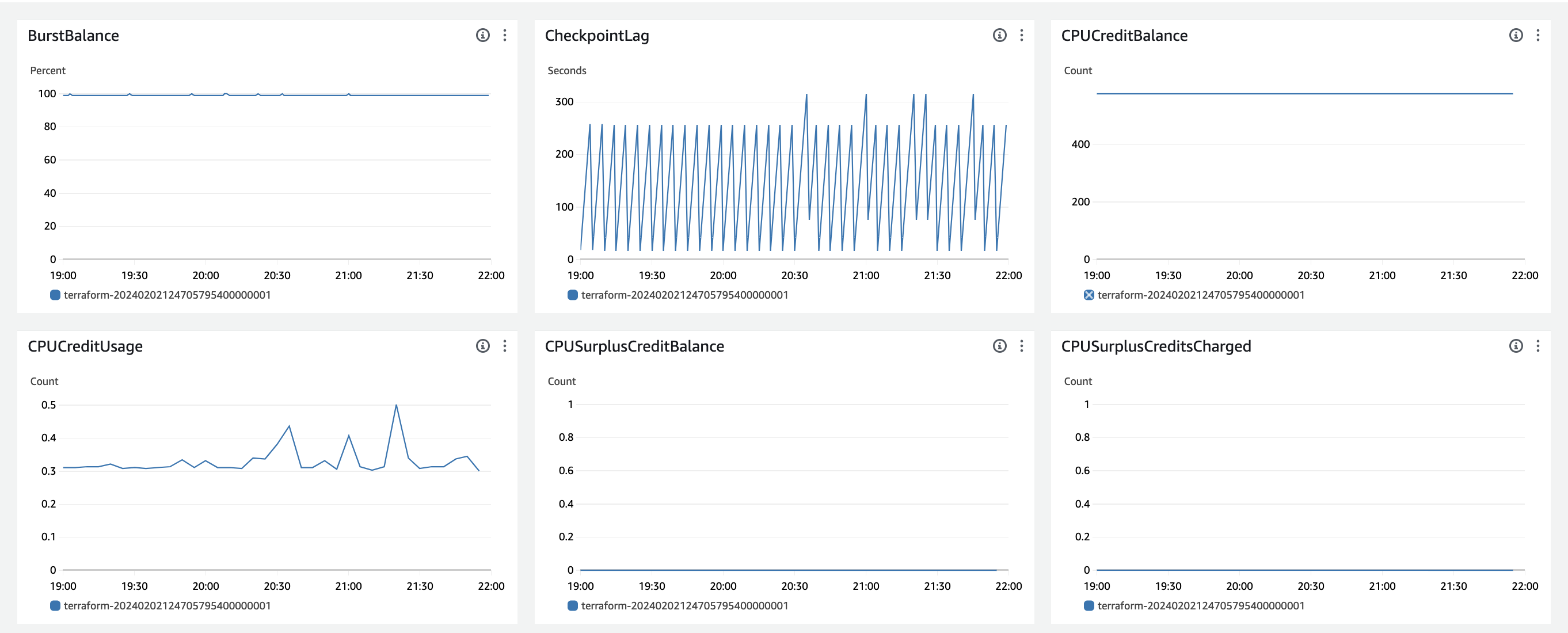
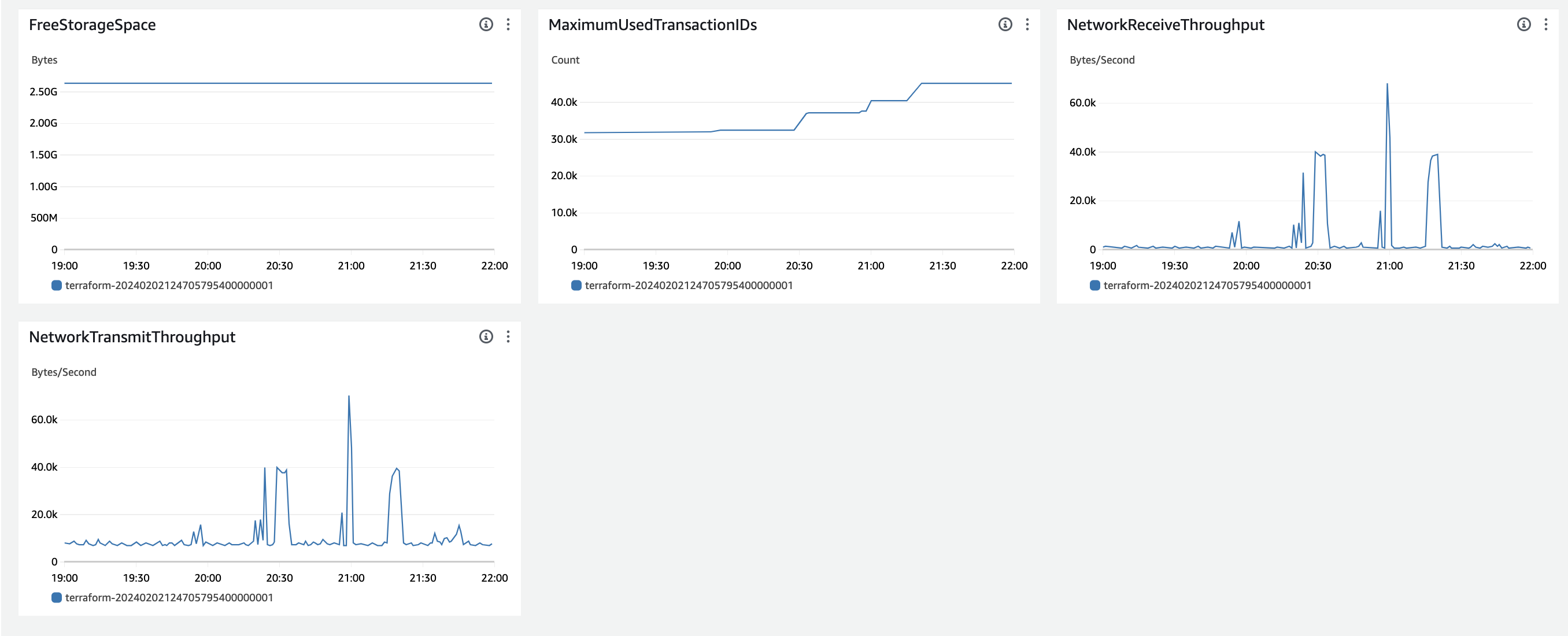
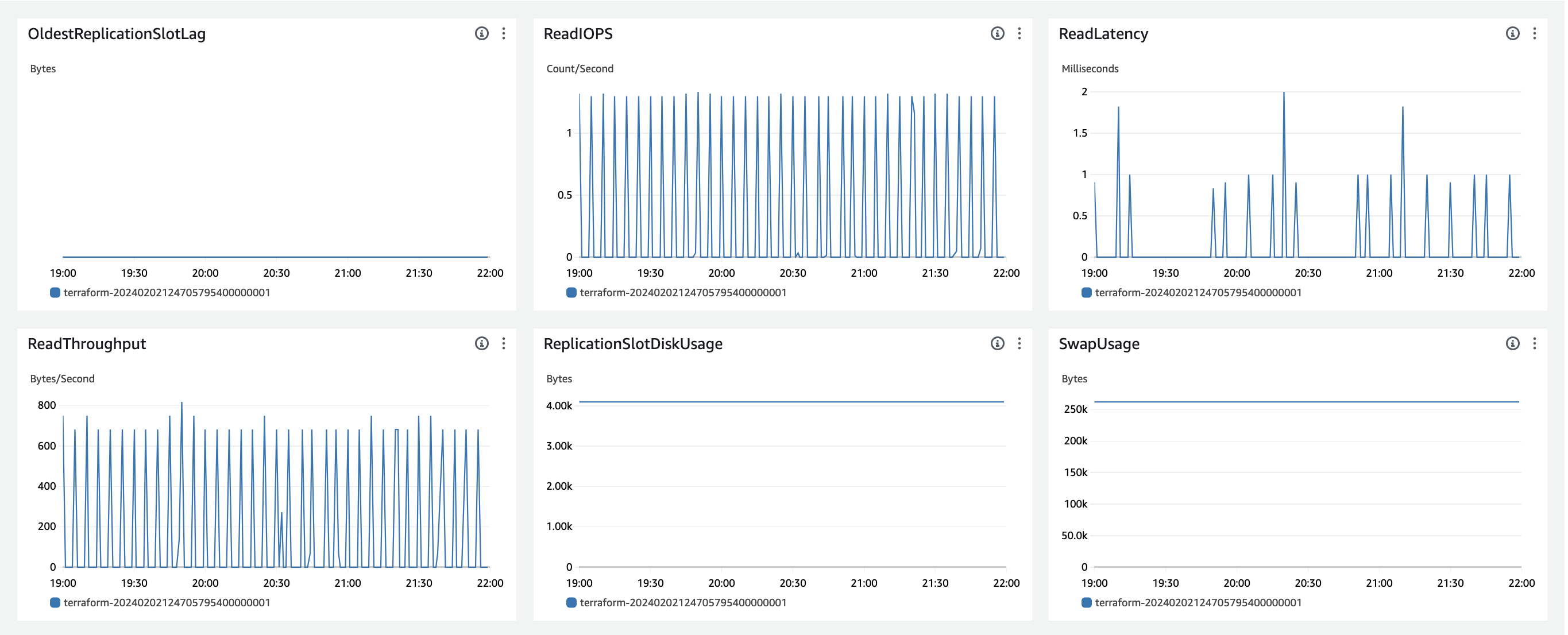
- 아래는 이외의 지표들입니다.
(1) IOPS 처리 지표
현재 사용하고 있는 RDS volume storage : 5GB
공식문서에 따르면, RDS의 IOPS(Read + Write)는 Volume Storage * 3 의 IOPS까지 최소한 보장이 된다고 합니다. 하지만 저희가 설정한 5GB의 Volume Storage는 5GB로 매우 적어서, 해당 계산식이 적용되는 것이 아니라, 100 IOPS가 보장이 됩니다.
https://docs.aws.amazon.com/ebs/latest/userguide/general-purpose.html
저희의 로드테스트(Post 처리)는, 100명의 유저가 1초에 한번 요청을 동시에 보내고, 10초, 그리고 300초동안 보냈습니다.
만약 이를 모두 다 처리해야 했다면, 로드 테스트 당시 최소 100 IOPS가 나와야하는데, 최대 27 IOPS를 쓰고 있는 상황입니다. 또한 write latency도 매우 2~8ms (avg)로 매우 적은 시간입니다.
그래서, RDS자체의 문제는 없고, DB와 서버간의 Connection 문제로 병목지점이 생겼을 것이라고 추측하는 것입니다.
아래는 각 로드 테스트 별로, 결과 분석입니다.
-
19시 56분경, 100명의 user가 10초동안 회원가입 요청을 1초에 한번씩 동시에 보냈을 때, 로드테스트 결과입니다.
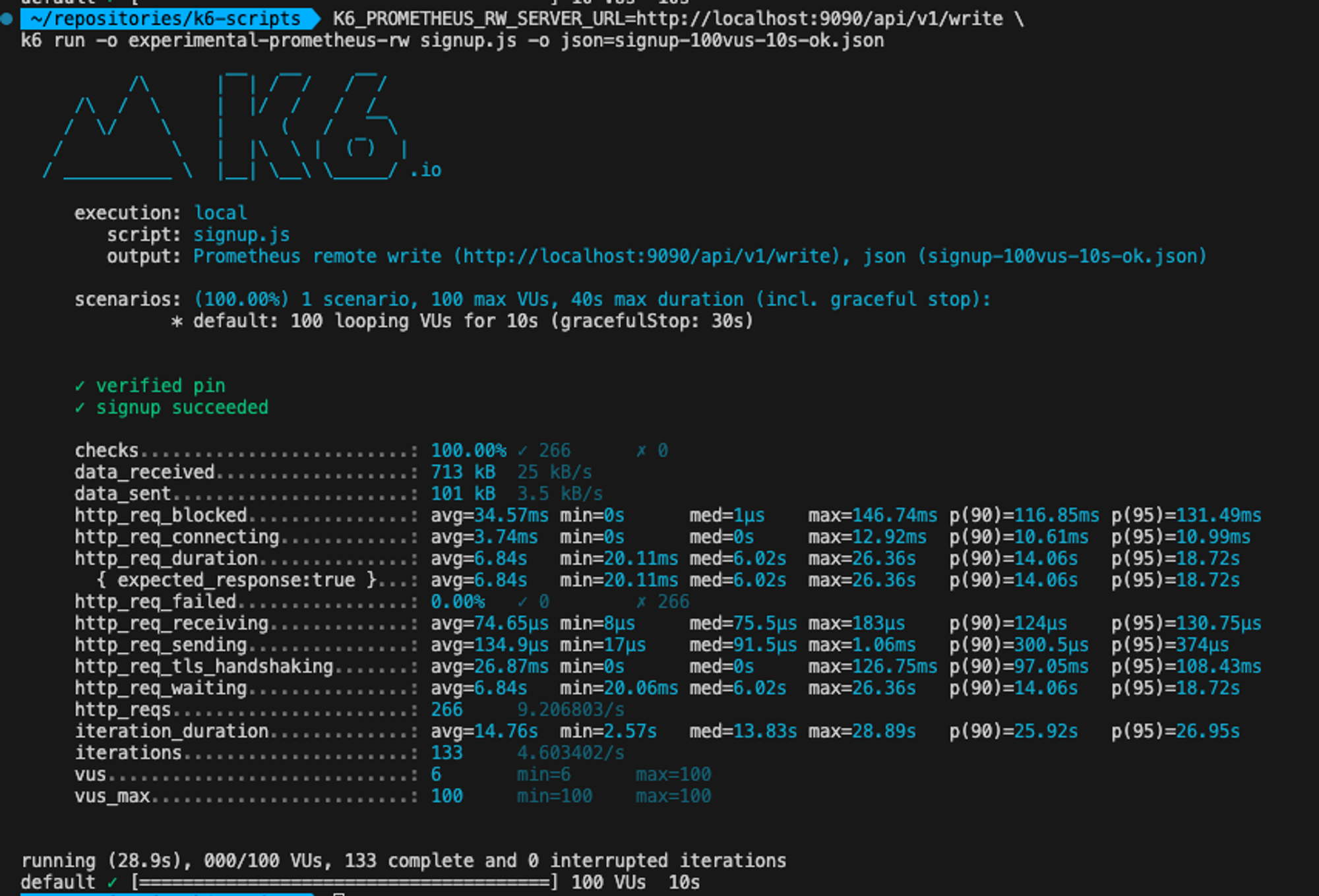
http_reqs : 총 req의 개수 266 http_req_duration: req 전송부터 응답까지 총 시간 avg=6.84s min=20.11ms, max=26.36s 당시에 write IOPS가 13 (avg) 까지 올라갔습니다. 그럼
13 * 10을 하면 130개의 요청이 처리되었을 것이라고 생각됩니다.
모든 요청을 다 처리했다면 최소100 * 10개 = 1000개의 request가 보내졌을텐데, 이렇지 않았습니다.
-
20시 33분경, 100명의 user가 300초동안 회원가입 요청을 1초에 한번씩 동시에 보냈을 때, 로드테스트 결과입니다.
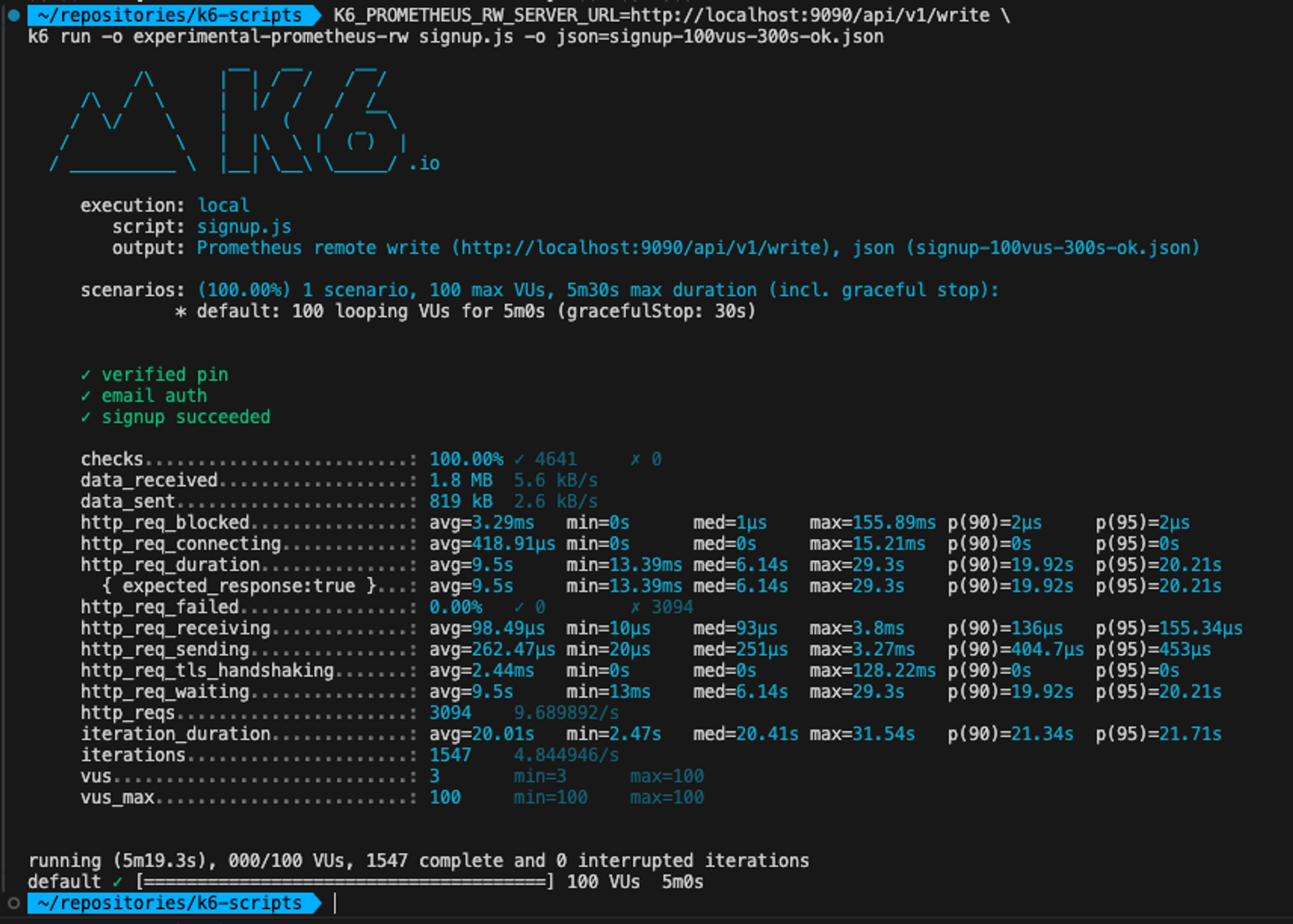
http_reqs : 총 req의 개수 3094 http_req_duration: req 전송부터 응답까지 총 시간 avg=9.5s min=13.39ms, max=29.3s 모두 처리했다면
100 * 300 = 30000개의 request가 처리되어야 하지만, 이보다 훨씬적은 3000개의 request가 처리되었습니다.
당시에, IOPS는 25개정도로 처리되었다는 것을 확인할 수 있었습니다. 그러면 request는 25*300 = 7500개의 request가 처리되었을 것입니다. 25도 결국 평균이라, 사실 정확한 request 처리를 알 순 없지만, 이정도면 어느정도의 연관관계가 있지 않을까 생각합니다.
-
20시 59분경, 100명의 user가 10초동안 코드 채점 요청을 1초에 한번씩 동시에 보냈을 때, 로드테스트 결과입니다.
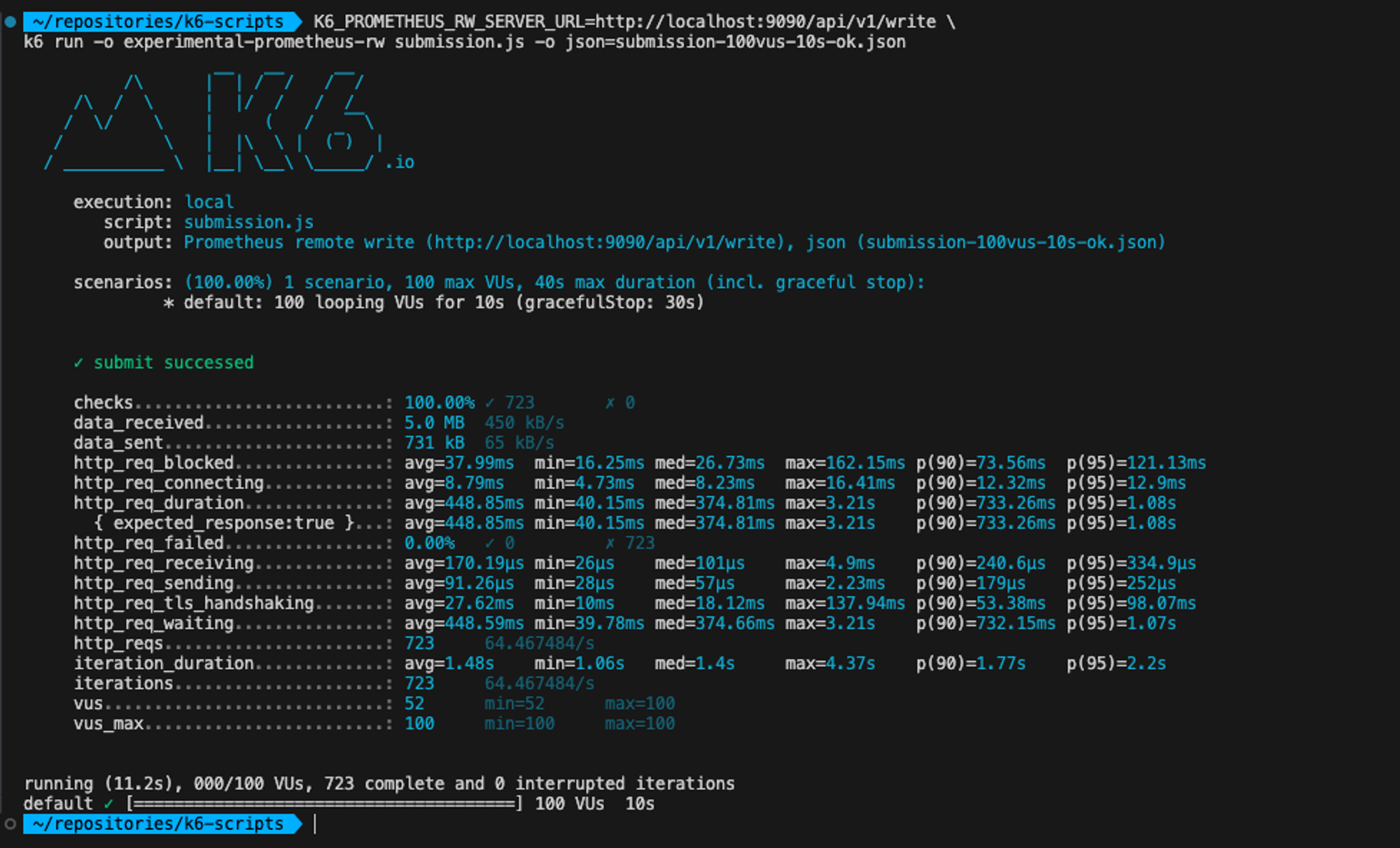
http_reqs : 총 req의 개수 723 http_req_duration: req 전송부터 응답까지 총 시간 avg=448.85ms min=40.15ms, max=3.21s client-api 컨테이너 max_cpu=% max_memory=% client-api-logrouter 컨테이너 max_cpu=% max_memory=%
그렇다면, 왜 코드제출요청과 회원가입 요청의 Response Time이 크게 차이가 나는지 분석해보았습니다.
이를 위해 백엔드 코드를 분석해보았습니다.
// 회원가입 서비스 로직
async signUp(req: Request, signUpDto: SignUpDto) {
const { email } = await this.verifyJwtFromRequestHeader(req)
if (email != signUpDto.email) {
this.logger.debug(
{
verifiedEmail: email,
requestedEmail: signUpDto.email
},
'signUp - fail (unauthenticated email)'
)
throw new UnprocessableDataException('The email is not authenticated one')
}
const duplicatedUser = await this.prisma.user.findUnique({
where: {
username: signUpDto.username
}
})
if (duplicatedUser) {
this.logger.debug('username duplicated')
throw new DuplicateFoundException('Username')
}
if (!this.isValidUsername(signUpDto.username)) {
this.logger.debug('signUp - fail (invalid username)')
throw new UnprocessableDataException('Bad username')
} else if (!this.isValidPassword(signUpDto.password)) {
this.logger.debug('signUp - fail (invalid password)')
throw new UnprocessableDataException('Bad password')
}
await this.deletePinFromCache(emailAuthenticationPinCacheKey(email))
const user: User = await this.createUser(signUpDto)
const CreateUserProfileData: CreateUserProfileData = {
userId: user.id,
realName: signUpDto.realName
}
await this.createUserProfile(CreateUserProfileData)
await this.registerUserToPublicGroup(user.id)
return user
}해당 요청에서 보면, write와 관련된 요청이 createUser, createUserProfile, registerUserToPublicGroup 입니다. 총 세개의 DB write입니다.
// 코드 제출 서비스 로직
async submitToProblem(
submissionDto: CreateSubmissionDto,
userId: number,
problemId: number,
groupId = OPEN_SPACE_ID
) {
const problem = await this.prisma.problem.findFirstOrThrow({
where: {
id: problemId,
groupId,
exposeTime: {
lt: new Date()
}
}
})
return await this.createSubmission(submissionDto, problem, userId)
}이는 createSubmission 만, DB write작업을 합니다.
그러다보니 회원가입 요청 하나에, write만을 위한 3개의 connection이 필요합니다. 예시로 load test중 우리가 회원가입 광클시 희박한 확률로 되었던 이유가, 해당 요청이 바로 connection pool에게 요청받고 운좋게 3개의 write를 바로바로 connection과 연결되어 처리되지 않았을까 생각합니다. 그래서 connection을 맺기 위한 병목이 생겼을 것입니다.
( 별개로, 만일 100IOPS (BaseLine) 보다 높았더라면(시간당 처리를 더 많이 해야했다면) CPU credit을 소모하게 되는데, 소모하지 않고있는 것을 보입니다. )
(2) Database Connections
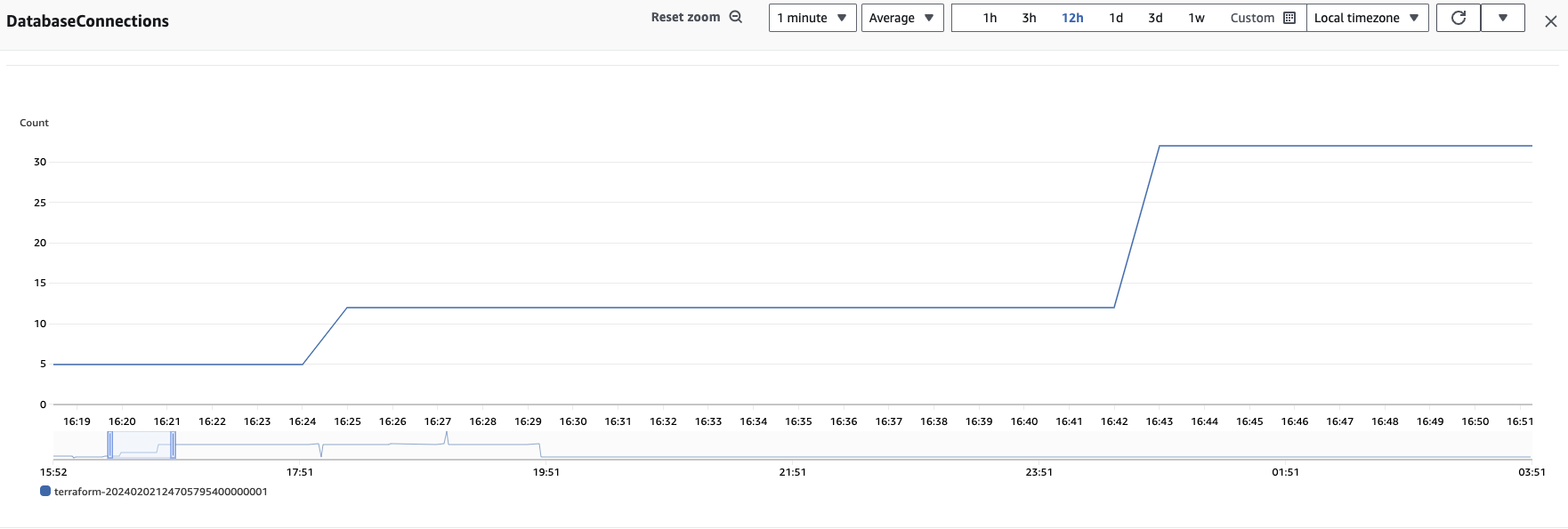
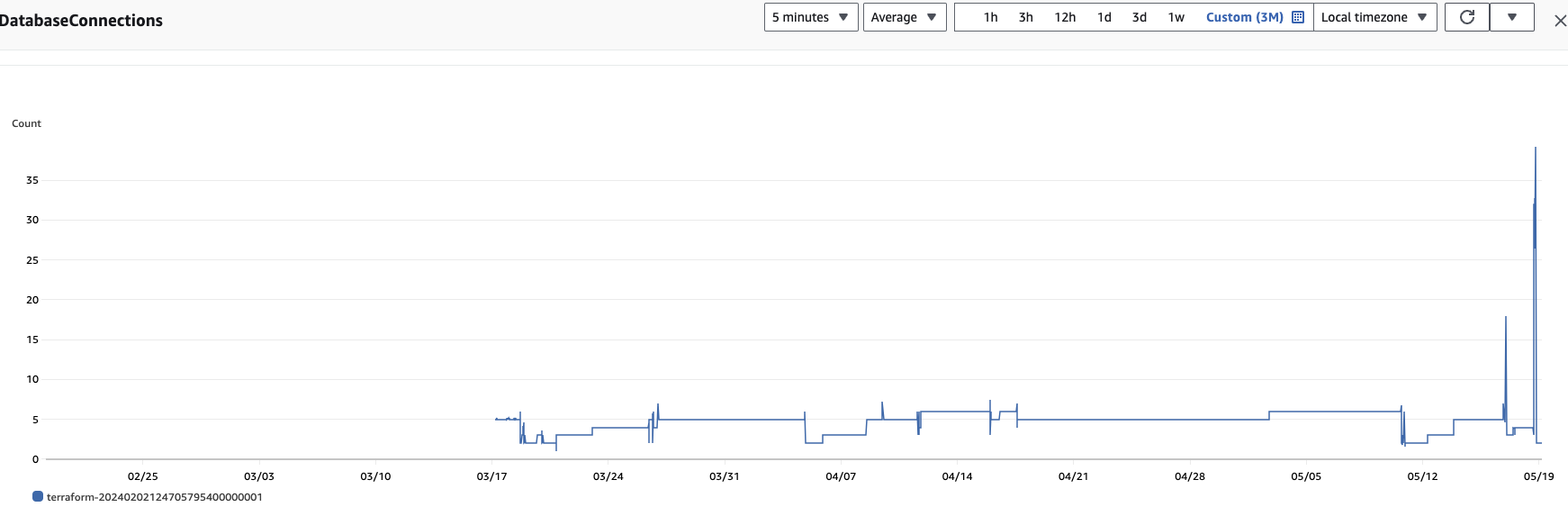
Database Connections 수를 보면, 3~7로 변동이 있습니다. 현재는 이 Connection수가 백엔드 서버가 DB와 통신하기 위한 Connection Pool의 개수 자체를 의미하는지, 아니면 말 그대로, Connection Pool에서 할당받은 Connection의 개수를 의미하는지 체크해보긴 해야합니다. (결과는 connection 개수였습니다. (Pool 개수 x)
그래서 백엔드 ORM Prisma의 connection_limit의 개수를 늘려보면서 체크해볼 예정입니다. prisma의 최대 connection가 physical_cpu_core * 2 + 1 이라고는 하는데, 저희는 클라우드 환경이어서 vCPU를 사용하기 때문에, 이러한 계산식이 적용되지 않을 가능성도 큽니다.
만약 Connection_limit수를 늘려서, 속도가 크게 개선된다면, connection개수가 적어서 생긴 문제가 맞을 것입니다.
(3) Disk Queue Depth
그리고, metric정보에 DiskQueueDepth라는 것이 있는데, 이는 RDS가 I/O를 처리하고 있어서 다른 wrtie,read request가 작업을 기다리는 수인데요.
이 또한 별 차이가 없습니다. 즉 DB의 처리 작업 자체에서 병목지점이 없을 것이라고 추측됩니다.
2-1차 로드 테스트 진행
그래서 5월 18일, 2차 로드테스트를 김일건님과 강은수님이랑 함께 진행하게 되었습니다 야호!
(2-1차인 이유는, 2-2차에서 해결했기 때문입니다)
2-1차에서는 앞서 분석한대로, connection_limit의 수를 30개로 지정해서 먼저 로드테스트를 진행해보았습니다. (schema.prisma에서 이를 지정할 수 있습니다)
2-1차 로드 테스트 결과
| Test 시작 시각 | Test 시나리오 | Test 조건 | [결과] Duration | [결과] Connections |
|---|---|---|---|---|
| 16:25 | 회원가입 성공 | 10vus, 10s | avg=910ms p(95)= 2.93 | 5→12개로 증가 |
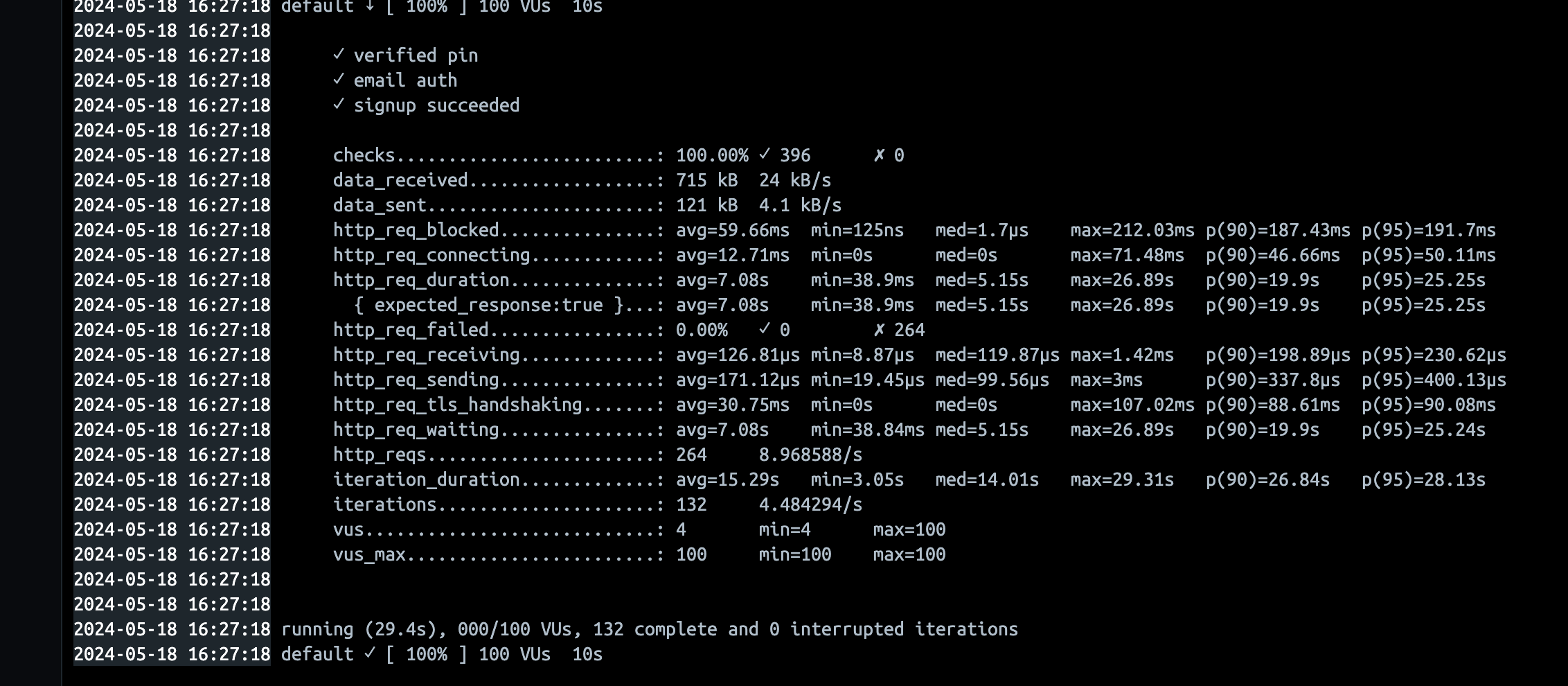
| 16:26 | 회원가입 성공 | 100vus, 10s | avg=7.08s p(95)=25.25 | 12개 그대로 사용 |
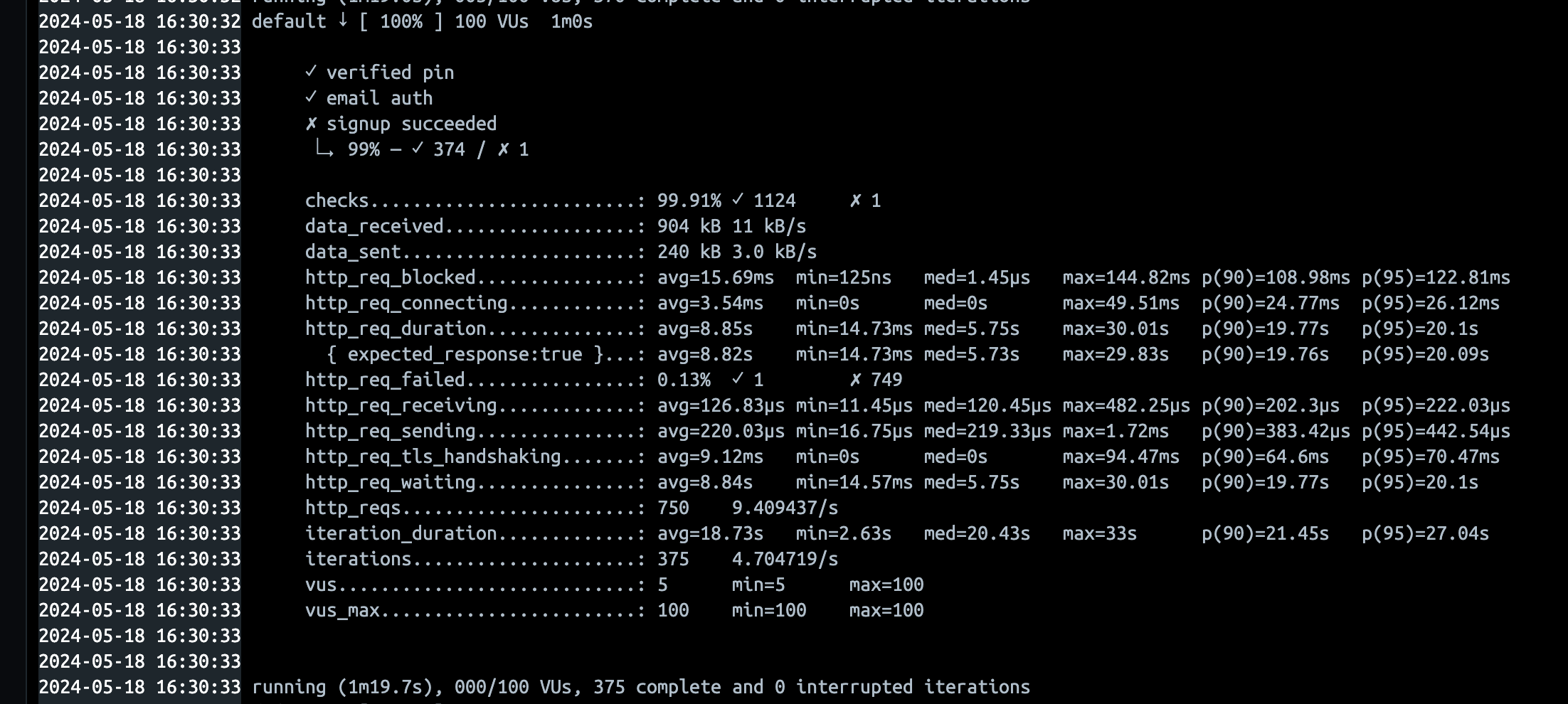
| 16:29 | 회원가입 성공 | 100vus, 60s | avg=8.85s p(95)=25.25 | 12개 그대로 사용 |
| 16:43 | 회원가입 성공 | 100vus, 300s | avg=9.51s p(95)=20s | 12→30개 full 사용 |
- 회원가입 성공 10vus, 10s

- 회원가입 성공 100vus, 10s
- 회원가입 성공 100vus, 60s
- 회원가입 성공 100vus, 300s
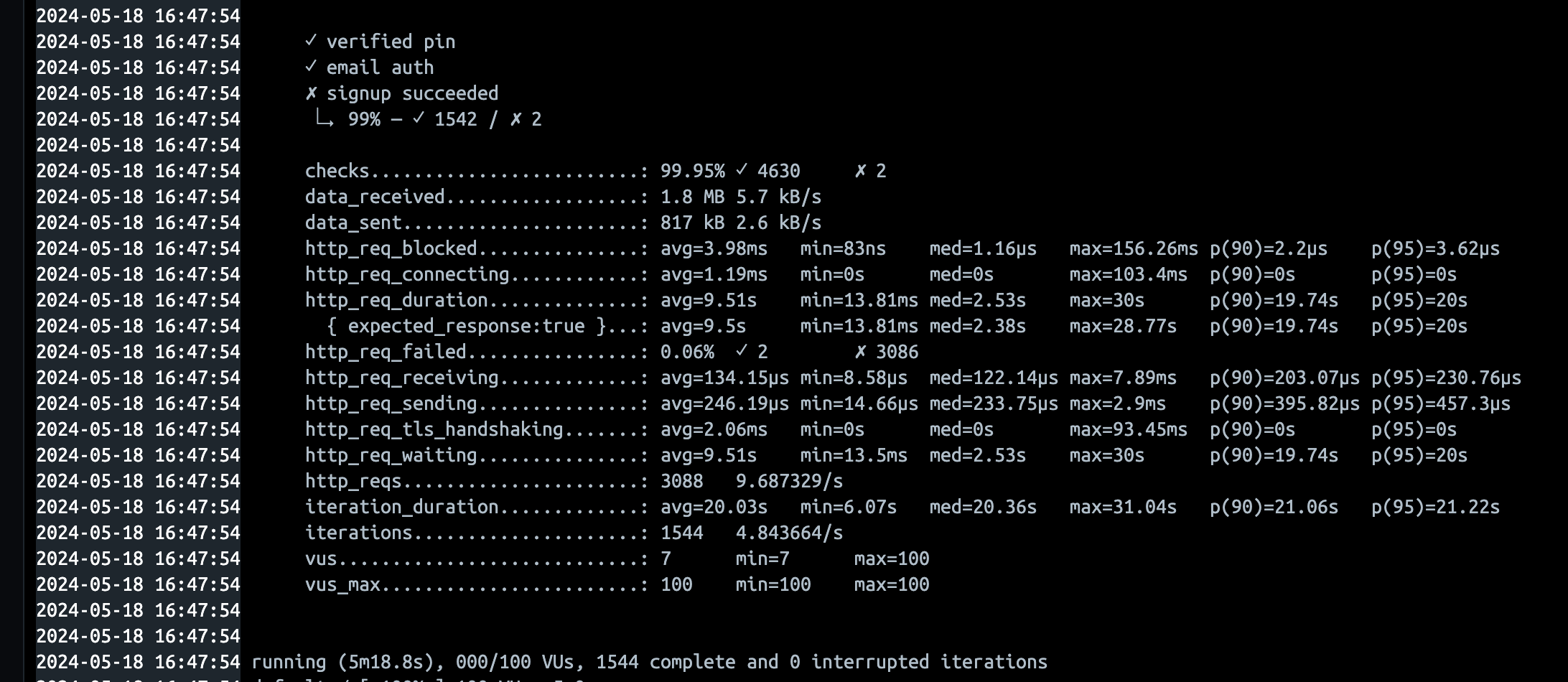
살짝보면, 약간의 성능개선이 이뤄진것 같지만, 사실 차이가 없습니다. 즉 Connection의 문제는 아니었습니다.
하지만 이전에는 충분한 Connection 수가 사용 되고 있지 않다는 사실은 Metric 정보로 확인이 되긴 하였습니다.
3달치로 보면 압도적이죠?
2-1차 로드 테스트 분석
그렇다면, 무엇이 문제일까.. 또 분석하게 되었습니다.
앞선 1차 결과 분석 내용을 다시 집중하게 되었습니다.
앞에서 이렇게 말했었습니다.
회원가입 요청 하나에, write만을 위한 3개의 connection이 필요합니다. 예시로 load test중 우리가 회원가입 광클시 희박한 확률로 되었던 이유가, 해당 요청이 바로 connection pool에게 요청받고 운좋게 3개의 write를 바로바로 connection과 연결되어 처리되지 않았을까 생각합니다. 그러다보니 connection을 맺기 위한 병목이 생겼을 것입니다.
이 부분에 더욱 집중해보았습니다. 만일, connection의 연결 개수와 무관하게, write connection이 한번마다 다시 발생한다면, I/O가 생기지 않을까? 그래서 Overhead가 커졌을 수도 있다. 라고 생각하고 코드를 들여다보았습니다.
여기서 하나 더 문제가 될 수 있는 부분을 발견합니다.
바로 await 때문에 발생하는 문제입니다.
문제삼은 부분은 다음과 같습니다.
const user: User = await this.createUser(signUpDto)
const CreateUserProfileData: CreateUserProfileData = {
userId: user.id,
realName: signUpDto.realName
}
await this.createUserProfile(CreateUserProfileData)
await this.registerUserToPublicGroup(user.id)만일, 100명의 유저가 같은 Request를 동시에 보낸다면, 위 서비스 로직을 싱글쓰레드 기반으로 동작하게 되고, 비동기 처리를 위한 await함수가 동작하면서 DB와 접근하게 될 것입니다. 하지만, “100명” 이라는 상황의 특수성에 집중해보면 다음과 같은 문제가 발생할 수 있습니다.
만일 커넥션수가 1개의 상황을 가정해보겠습니다.
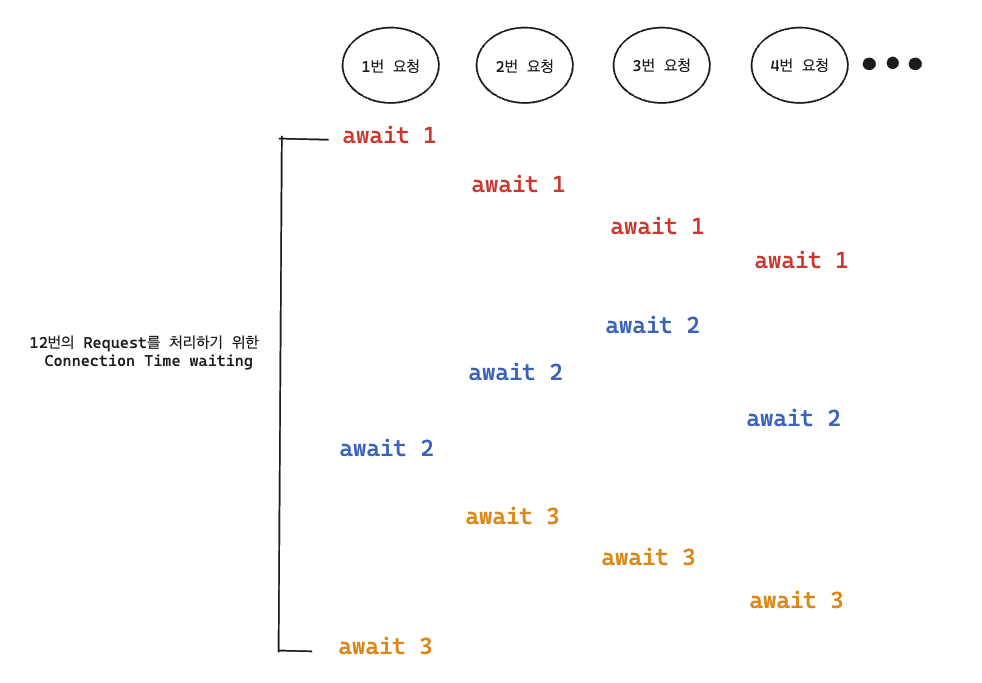
커넥션수가 1개라면, DB와 접근하기 위한 비동기 처리 함수 await 에 의하여 하나의 요청에 있어서 DB로부터 response가 올때까지 기다리게 됩니다.
하지만 만일, 그 중간에 다른 요청이 끼어들게 된다면, 방금전 요청을 처리했던 await 다음 await 실행까지 많은 시간이 걸리게 됩니다.
위 그림은 4개처럼 그려놔서, 최악의 경우 하나의 요청이 12번의 Connection 에 해당하는 결과값을 기다리게 됩니다.
로드 테스트 상황에서는 100명의 유저가 한번에 보냈으니, 300번의 Connection 결과값을 기다리게 되는 것입니다.
Connection 수가 1개가 아닌 2개로 늘어난다고 하면, 약간의 이점을 볼 수 있습니다.
주의 ! (자바스크립트의 async await에 내부적으로 정확히 알지는 못해서, 멀티쓰레드처럼 그려놓긴 했습니다. 사실은 약간의 시간차가 있다고 생각하시면 됩니다.)
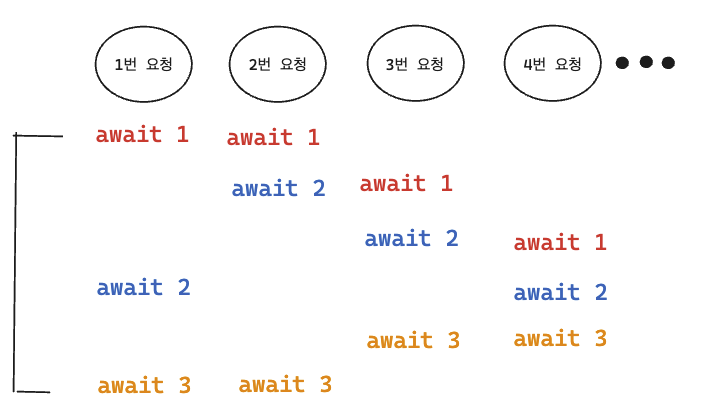
하지만 100명의 유저가 요청하는 상황속에서 하나의 요청에 해당하는 비동기 함수 들이 운좋게 Connection을 모두 다가져가서 처리할 확률은 희박합니다. 그래서 avg 타임에는 큰 차이가 없고, worst time 개선이 이뤄지지 않았을까 추측합니다. (1번 요청을 보면 worst time이 connection 수 6개의 할당 시간으로 줄었습니다)
그렇다면, 이를 해결하기 위해, Response Time을 보장받을 수 있는 방법을 모색하게 되었습니다.
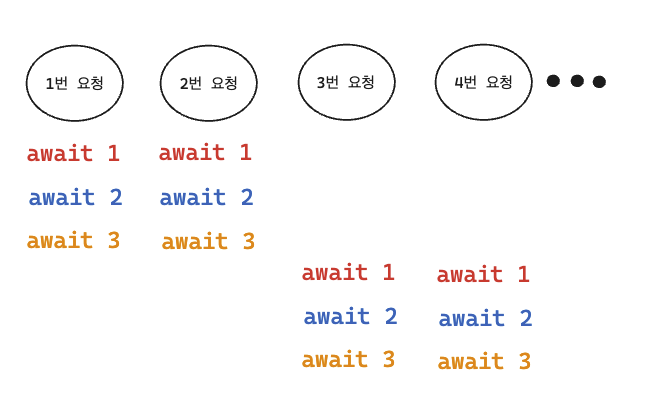
위 사진처럼 말입니다!
2-2차 로드테스트 진행
Spring으로 백엔드를 개발해본 경험으로 생각해봤을 때, Spring에는 서비스 로직에 @Transactional 어노테이션을 붙여서 서비스로직에서 부르는 여러 데이터 call의 단일 DB Connection을 보장받고, ACID 로직을 수행할 수 있습니다.
그렇다면 Nest도 똑같이 적용하면 되지 않을까 생각했었고, 냅다, 프로젝트 폴더에서 transaction 을 검색해보았습니다.
async updateWorkbookProblemsOrder(
groupId: number,
workbookId: number,
// orders는 항상 workbookId에 해당하는 workbookProblems들이 모두 딸려 온다.
orders: number[]
): Promise<Partial<WorkbookProblem>[]> {
// id를 받은 workbook이 현재 접속된 group의 것인지 확인
await this.prisma.workbook.findFirstOrThrow({
where: { id: workbookId, groupId }
})
// workbookId를 가지고 있는 workbookProblem을 모두 가져옴
const workbookProblemsToBeUpdated =
await this.prisma.workbookProblem.findMany({
where: { workbookId }
})
// orders 길이와 찾은 workbookProblem 길이가 같은지 확인
if (orders.length !== workbookProblemsToBeUpdated.length) {
throw new UnprocessableDataException(
'the len of orders and the len of workbookProblem are not equal.'
)
}
//problemId 기준으로 오름차순 정렬
workbookProblemsToBeUpdated.sort((a, b) => a.problemId - b.problemId)
const queries = workbookProblemsToBeUpdated.map((record) => {
const newOrder = orders.indexOf(record.problemId) + 1
return this.prisma.workbookProblem.update({
where: {
// eslint-disable-next-line @typescript-eslint/naming-convention
workbookId_problemId: {
workbookId,
problemId: record.problemId
}
},
data: { order: newOrder }
})
})
return await this.prisma.$transaction(queries)
}위 함수에서 마지막에 this.prisma.$transaction 을 통해 prisma에도 transaction 기능이 있구나. 하고 생각하였습니다.
찾아보니, transaction 처리는 하나의 connection을 사용하는 것을 알게되었습니다.
결국 그러면,
const user: User = await this.createUser(signUpDto)
const CreateUserProfileData: CreateUserProfileData = {
userId: user.id,
realName: signUpDto.realName
}
await this.createUserProfile(CreateUserProfileData)
await this.registerUserToPublicGroup(user.id)이 코드를 하나의 transaction으로 처리하게 되었습니다.
하지만, Nest와 Prisma에 능숙한 것이 아니라, 그냥 내부 로직에서 write만 담당하는 Prisma API콜부분만 따와서 다음과 같이 작성하였습니다.
아래는 해당 커밋입니다.
Commits · skkuding/codedang
const returnUser: User = await this.prisma.$transaction(async (prisma) => {
const user = await prisma.user.create({
data: {
username: newSignUpDto.username,
password: newSignUpDto.password,
email: newSignUpDto.email
}
})
await prisma.userProfile.create({
data: {
realName: newSignUpDto.realName,
user: {
connect: { id: user.id }
}
}
})
await prisma.userGroup.create({
data: {
userId: user.id,
groupId: 1,
isGroupLeader: false
}
})
return user
})2-2차 로드테스트 결과
하지만 성능차이가 크지 않았었습니다.
백엔드 로직 문제 찾기 및 마지막 로드테스트
마지막 로드 테스트에서 백엔드 코드를 처음부터 분석하며 오버헤드가 될 지점을 찾아보았습니다. 각 코드별로 수행 시간을 console.log로 찍어서 Tracing하는 작업을 하려고 하였습니다.
해당 작업을 들어가기 전에, 비밀번호 hash함수가 병목의 요인이 될 수 있다는 서칭 결과를 바탕으로 hash함수의 시간복잡도를 낮추는 옵션을 추가하자 성능이 급격히 좋아졌습니다.
그 결과로, 다음과 같이 성능을 개선할 수 있게 되었습니다.
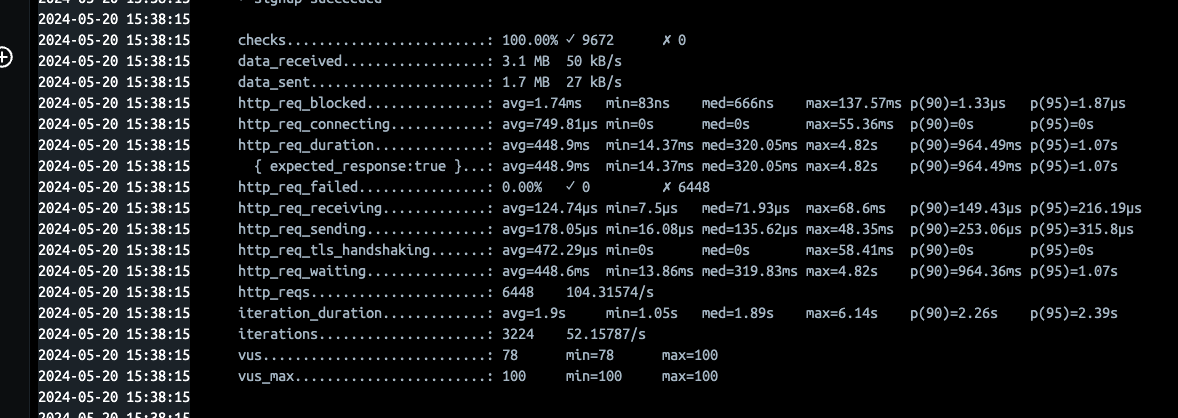
평균 응답 시간을 6,84초에서 0.45초, 상위 95% 응답 시간을 18.72초에서 1.07초로 줄일 수 있었습니다.
마지막으로
다소 허무하게 끝난감이 없지않아 있긴 합니다만.. 어쨌든 이번 로드테스트로 얻은 지식, 그리고 결국 '해결'해냈다는 점이 값진 경험이었던 것 같습니다.
transaction처리가 성능 개선에 큰 영향을 미치지 않았어도,transaction 처리가 유의미하다는 것을 검증하였습니다.
해당 글은 따로 포스트 하였습니다.
https://velog.io/@goat_hoon/Connection-개수-Transaction-유무에-따른-동시-요청들의-처리-순서-메카니즘-분석하기-Nest
앞으로 인프라에서 할일은, Connection 수를 튜닝하면서 ‘초’를 늘리는게 아니라, ‘유저의 수’ 를 늘리면서 얼만큼 트래픽을 받아내는지를 검증하는 작업을 하게될 것 같습니다 !
그래도 긴 글 읽어주셔서 감사하고, 백엔드 코드를 작성할 때, DB I/O와 트랜잭션, 비동기 처리 모두를 고려하며 작성하자! 라는 교훈을 얻고 가셨으면 좋겠습니다 :) 모두 화이팅 !
위 글은 성균관대 동아리 Skkuding에서 서비스를 운영하며 경험한 로드테스트 및 성능 개선 글입니다 !
