입사 1년차를 앞두고 있는 지금, 처음으로 실제 장애 상황에서 1선 대응 및 이후 원인 분석까지 진행하여 공유하였던 뜻 깊은 작업이었다.
나의 공부가 헛되지 않았구나! 기분이 매우 좋은 순간이었다.장애 대응 할 때에도 MSK 문제가 해소된 이후, MSK와 연관된 4개의 서비스 모듈을 재기동 할 때 Lag이 한꺼번에 해소 되면서 DB에 부하가 가지 않게 서비스 지표와 DB 지표를 동시에 확인 후 순차적으로 진행하며 문제 없이 장애 해소에 기여했다는 것도 뜻깊었다.
함께 고민을 같이하고 금요일 밤시간까지 함께 부하테스트를 진행한 사우님께 감사인사를 하고싶다.
장애 원인 분석 배경
어제, MSK 장애가 발생했다.
원인은 타 팀에서 엉뚱한 MSK(그게 우리 서비스의 MSK.. 특히 그게 국내일줄은 몰랐지..)에 ACL작업을 하면서 벌어진 해프닝이었다.
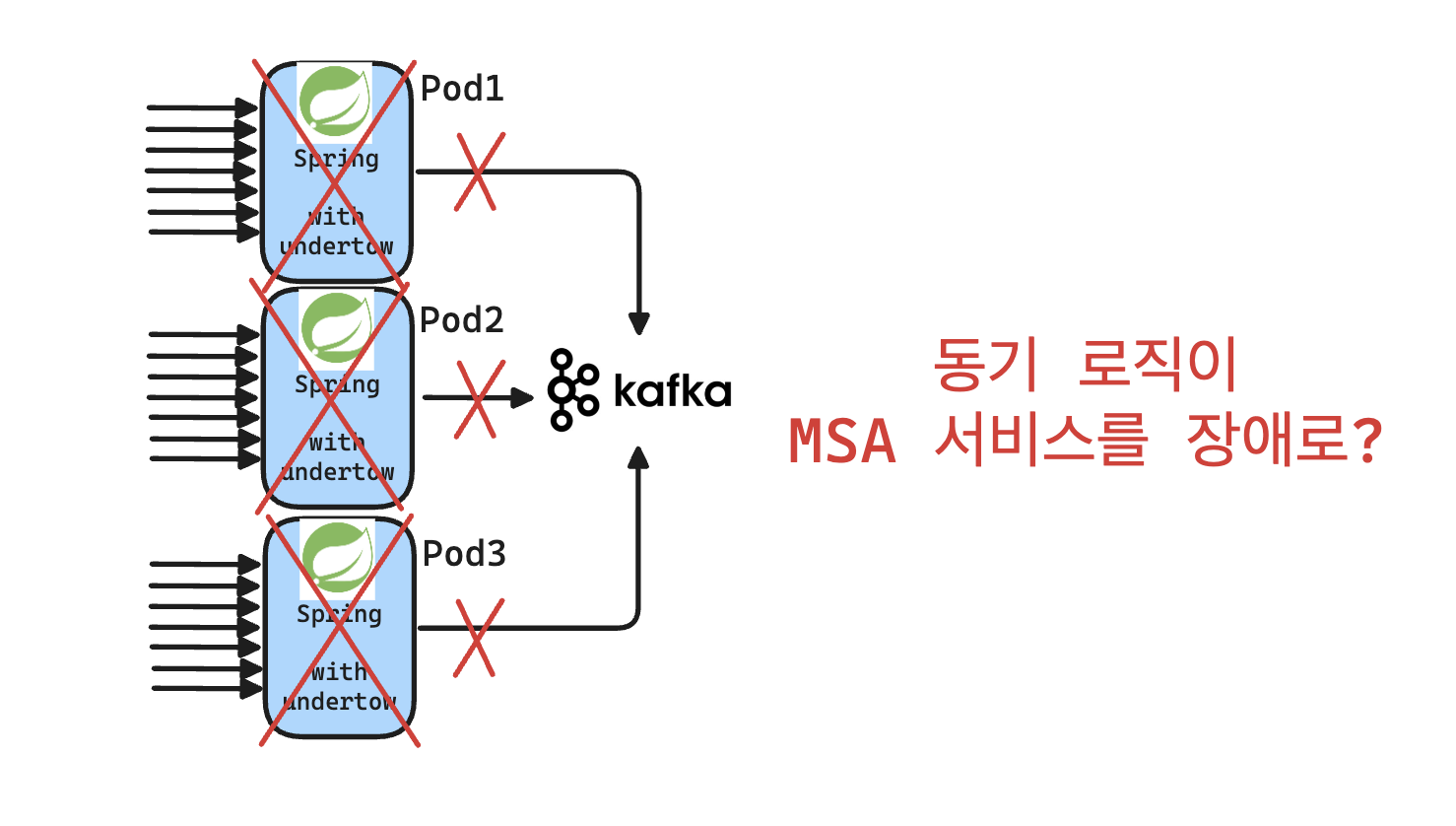
바람직한 MSA서비스라면, 하나의 시스템에 장애가 발생하게 될 경우, 이와 연동된 API만 문제가 있고, 서비스 전체적으로는 문제가 없어야 정상일 것이다.
하지만, 이번 경우에 MSK장애 하나로 MSA 서비스의 1/3 정도가 컨테이너 다운이 되어버렸다.
그래서 장애 다음 날인 오늘 장애 원인을 바로 분석해보기 시작했다.
분석 중에, 갑자기 실 전체 서비스 운영인원들에게 각 서비스별 장애 원인 분석을 진행해달라고 요청이 왔었다.. 마침 잘됐다!
서비스들 중에는 컨테이너가 다운되지는 않았지만 MSK장애 해소 이후, Consume(Subscribe)이 바로 되지 않고 재기동을 해야만 Consume이 성공한 서비스도 있다. 어쩌다보니 두 케이스 둘다 담당하고 있는 서비스에 포함되어서.. 해당 이유가 무엇인지 원인 확인 요청도 주셨다. 이 부분은 추후에 인프라팀과 원인을 분석해볼 예정이다.
장애 원인 추리기
1. Pod Down 시간 확인 (사실은 Container Down)
정확히 어느 시간에 Pod가 Down되었는지 확인해보았다. 그라파나와 연동된 Teams로 장애 알림을 수신하고 있는데, 담당 서비스 pod의 변경점 알림이 수신된 시간대를 파악하였다.
나중에 알게된 것인데, 정확히 해당 알림은 Pod 재기동 문제가 아니고, Pod내의 서비스 컨테이너의 health check가 되지 않는 경우에도 Pod 변경점으로 보고 알림이 온다는 것을 알게 되었다. 실제로도 Pod 재기동이 아니고, 컨테이너 재기동 상황이었다.
2. Metric + k8s 지표
처음 출근해서 바로 살펴봤던 지표는 MSK장애 발생 당시 Pod별 Metric 지표이다.
근데 웬걸? CPU, Memory, Thread 전반적으로 별다른 이상 징후가 없었다. HPA가 적용될 만큼의 지표조차 다다르지 않아 문제가 없어보였다. 대체 왜일까?
쿠버네티스를 잘 모르긴 하지만, 알림을 수신한 서비스(Pod)들이 같은 Node라서 다같이 Down이 된게 아닐까? 싶었지만, 그것도 아니었다. MSK 통신 오류인데 Node랑은 큰 상관은 없어보이긴 한다...
3. Log
이후에는 로그를 살펴봤다.
장애 상황에 어떤 로그가 찍혀있을까 살펴봤더니, 이게 또 웬걸, 서비스 요청을 잘 처리하다가 갑자기 Spring Boot server가 재시작 되는 로깅이 된다. 중간에 아무런 에러 로깅도 찍히지 않았다.
4. 설정 비교
3번까지 분석을 해도, 뇌 속에는 물음표만 남겨있었다. 다행인지는 몰라도, 담당 서비스들 중에 비교 대조 해볼만한 서비스가 있었다.
- Container down이 일어난 서비스
- Container 및 Pod는 매우 정상이나, 장애 당시 Consume이 되지 않고, 장애 해소 이후 재기동으로 Conusme이 된 서비스
(1) 설정값 비교 (KafkaConfig)
1번 서비스, 2번 서비스 모두 kafka관련 설정이 모두 동일했다. 직렬/역직렬화 하는 부분에서 차이가 있기는 했는데, 기본적인 카프카 설정값들은 모두 동일해보여서 문제가 되지 않아보였다.
(2) MSK 로직 비교
- Container Down이 일어난 서비스에서는 Kafka Pub 로직이 동기/비동기 로직이 둘 다 존재했다.
- 그렇지 않은 서비스에서는 Pub 로직이 모두 비동기였다.
그렇다면 이 차이 때문이 아닐까? 고민하기 시작했다.
5. 동기/비동기 차이에 따른 근거 마련
심증으로는 동기로직 때문에 문제가 생긴것 같은데, 근거가 없었다.
이 때부터 나와 같이 분석을 하고 있는 다른 팀의 친한 3년차 사우님과 함께 분석을 진행하였다.
실제 이 사우님은 검증계에 테스트 해볼 수 있는 k8s namespace를 가지고 있었고 우리는 이를 적극 활용하여 문제의 원인을 분석해 보기로 했다.
검증계 부하 테스트 시작
1. 환경 구축
실제 kafka fail 상황을 만들기 위해서, 사우님이 실제 pod와 통신할 수 없는 잘못된 kafka 정보로 pod container를 기동하였다.
그 이후 kafka sync pub 로직이 적용된 API에 부하테스트를 진행하였다.
2. 부하 시작... 그런데?
Jmeter로 부하를 주기 시작했다.
그런데 이상한게 Request Rate 지표가 아무리봐도 이상했다. 부하를 준만큼 Request Rate이 늘어나지 않고, 0.5~1 사이의 계단형 주기 함수 형태로 유지되었다.
무엇이 문제일까? 그라파나 대시보드가 잘못됐나? (대시보드 설정 값과 쿼리를 볼 수 있는 권한이 없어서 추측 밖에 할 수 없었다..)
3. 실제 비즈니스 로직 수행 여부 확인
kafka sync pub 로직이 적용된 API에 앞단에 해당 로직이 수행되고 있는 시간대를 로깅할 수 있게끔 로직을 추가했다. 그렇다면 진짜로 부하를 서버가 받고 있는지 알 수 있겠지!
결과는, 정말 신기하게도 200개의 요청을 2초동안 나누어서 부하 테스트를 진행했음에도, 로그에는 1분 텀으로 16개의 요청만 인입되었다. 즉 100개의 요청 1초 텀으로 2초동안 동시에 보냈을때 초기에 요청 16개만 앞단에서 수용할 수 있다는 뜻이었다. 아마 thread pool timeout 시간이 1분으로 설정되어 있던 것 같다.
4. 번뜩! 이거 웹서버 문제다.
https://velog.io/@goat_hoon/tomcat-thread-vs-async-thread
불과 3달전 발생했던 장애 상황을 해결하며 회고했던 문제가 떠올랐다.
그 때 당시, tomcat 스레드의 수를 조절하면서 동시에 처리할 수 있는 요청의 수를 테스트 했는데, 이 설정 때문에 앞단에 웹서버가 받지 못하는 것이 아닌지 범위를 좁혀갔다.
그래서 옆 사우분께 물어봤다.
"이거 tomcat 쓰는거죠?"
"아뇨, undertow인데요?"
undertow는 또 뭐야..
undertow? 오늘 처음 알게된 내용인데, tomcat과 같이 앞단의 웹서버 역할을 하는 것인데, 논블록킹 I/O를 지원하며 대용량 트래픽 처리에 최적화된 웹서버라고 한다. 이는 다음에 또 공부를 해봐야겠다.
"그러면 default worker thread수는 몇개에요?"
라고 질문했고 찾아보니, 코어수 * 8 이라고 한다.
그 때, 뇌 속에 생각이 스쳤다.
'우리 서비스 코어수가 8core로 helm chart에 지정되어 있었는데, 이거 Thread지표로 확인할 수 없었던게 8*8 = 64개의 thread만 사용하고 있어서 티가 안났나?'
아니나 다를까, 실제 JVM thread 지표에서 장애 시간대에 timed_waiting 상태의 thread가 max 64개까지 늘어나 거의 일직선으로 유지되고 있는 것을 확인할 수 있었다.
지표상 waiting상태의 thread수가 200개 정도 있었는데, 이 지표는 무엇일까? 200개가 tomcat 스레드 수의 default값으로 알고 있어서 웹서버로 tomat을 이용하고 있을거라고 단언했었다.
5. undertow worker thread 수를 늘려보죠
이후 worker thread수를 늘려보자고 제안했다.
200개까지 늘린 후에 부하테스트를 진행해본 결과, 정상적으로 인입이 되기 시작했고, thread수도 마찬가지로 늘어나기 시작했다.
운영환경처럼 꾸준한 부하를 준 것은 아니라서 timed_waiting 상태의 스레드가 늘어나고 이후에 다시 줄어드는 현상을 볼 수 있었다.
6. pod 컨테이너 재기동 확인하기
이후 max worker thread 수의 임계치까지 부하를 조절하면서 테스트 해봤을 때, 운영환경에서와 동일하게 container health check가 되지 않아서 pod가 깨지는 현상이 발생되었고, 재현에 성공했다.
결과
그래서 장애 원인을 다음과 같이 분석할 수 있었다.
MSK 장애로 인해 Kafka 동기 Pub 로직이 worker thread pool을 전부 점유하였고, 그 결과 health check API가 응답하지 못해 컨테이너가 비정상 종료 및 재기동됨
그리고 해결 방안으로, 동기 로직을 비동기 로직으로 전환하고, 비동기 스레드 풀 사용 시 OOM 방지를 위해 적절한 스레드풀 전략 및 TimeOut 설정을 제안한 상태이다.
끝!


멋져요잉