문제 설명
여러 언론사에서 쏟아지는 뉴스, 특히 속보성 뉴스를 보면 비슷비슷한 제목의 기사가 많아 정작 필요한 기사를 찾기가 어렵다. Daum 뉴스의 개발 업무를 맡게 된 신입사원 튜브는 사용자들이 편리하게 다양한 뉴스를 찾아볼 수 있도록 문제점을 개선하는 업무를 맡게 되었다.
개발의 방향을 잡기 위해 튜브는 우선 최근 화제가 되고 있는 "카카오 신입 개발자 공채" 관련 기사를 검색해보았다.
카카오 첫 공채..'블라인드' 방식 채용
카카오, 합병 후 첫 공채.. 블라인드 전형으로 개발자 채용
카카오, 블라인드 전형으로 신입 개발자 공채
카카오 공채, 신입 개발자 코딩 능력만 본다
카카오, 신입 공채.. "코딩 실력만 본다"
카카오 "코딩 능력만으로 2018 신입 개발자 뽑는다"
기사의 제목을 기준으로 "블라인드 전형"에 주목하는 기사와 "코딩 테스트"에 주목하는 기사로 나뉘는 걸 발견했다. 튜브는 이들을 각각 묶어서 보여주면 카카오 공채 관련 기사를 찾아보는 사용자에게 유용할 듯싶었다.
유사한 기사를 묶는 기준을 정하기 위해서 논문과 자료를 조사하던 튜브는 "자카드 유사도"라는 방법을 찾아냈다.
자카드 유사도는 집합 간의 유사도를 검사하는 여러 방법 중의 하나로 알려져 있다. 두 집합 A, B 사이의 자카드 유사도 J(A, B)는 두 집합의 교집합 크기를 두 집합의 합집합 크기로 나눈 값으로 정의된다.
예를 들어 집합 A = {1, 2, 3}, 집합 B = {2, 3, 4}라고 할 때, 교집합 A ∩ B = {2, 3}, 합집합 A ∪ B = {1, 2, 3, 4}이 되므로, 집합 A, B 사이의 자카드 유사도 J(A, B) = 2/4 = 0.5가 된다. 집합 A와 집합 B가 모두 공집합일 경우에는 나눗셈이 정의되지 않으니 따로 J(A, B) = 1로 정의한다.
자카드 유사도는 원소의 중복을 허용하는 다중집합에 대해서 확장할 수 있다. 다중집합 A는 원소 "1"을 3개 가지고 있고, 다중집합 B는 원소 "1"을 5개 가지고 있다고 하자. 이 다중집합의 교집합 A ∩ B는 원소 "1"을 min(3, 5)인 3개, 합집합 A ∪ B는 원소 "1"을 max(3, 5)인 5개 가지게 된다. 다중집합 A = {1, 1, 2, 2, 3}, 다중집합 B = {1, 2, 2, 4, 5}라고 하면, 교집합 A ∩ B = {1, 2, 2}, 합집합 A ∪ B = {1, 1, 2, 2, 3, 4, 5}가 되므로, 자카드 유사도 J(A, B) = 3/7, 약 0.42가 된다.
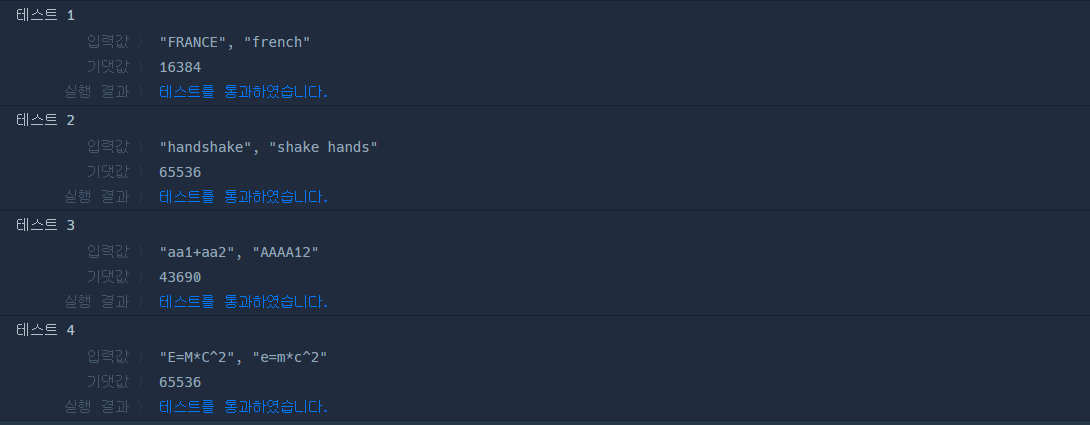
이를 이용하여 문자열 사이의 유사도를 계산하는데 이용할 수 있다. 문자열 "FRANCE"와 "FRENCH"가 주어졌을 때, 이를 두 글자씩 끊어서 다중집합을 만들 수 있다. 각각 {FR, RA, AN, NC, CE}, {FR, RE, EN, NC, CH}가 되며, 교집합은 {FR, NC}, 합집합은 {FR, RA, AN, NC, CE, RE, EN, CH}가 되므로, 두 문자열 사이의 자카드 유사도 J("FRANCE", "FRENCH") = 2/8 = 0.25가 된다.
입력 형식
- 입력으로는 str1과 str2의 두 문자열이 들어온다. 각 문자열의 길이는 2 이상, 1,000 이하이다.
- 입력으로 들어온 문자열은 두 글자씩 끊어서 다중집합의 원소로 만든다. 이때 영문자로 된 글자 쌍만 유효하고, 기타 공백이나 숫자, 특수 문자가 들어있는 경우는 그 글자 쌍을 버린다. 예를 들어 "ab+"가 입력으로 들어오면, "ab"만 다중집합의 원소로 삼고, "b+"는 버린다.
- 다중집합 원소 사이를 비교할 때, 대문자와 소문자의 차이는 무시한다. "AB"와 "Ab", "ab"는 같은 원소로 취급한다.
출력 형식
입력으로 들어온 두 문자열의 자카드 유사도를 출력한다. 유사도 값은 0에서 1 사이의 실수이므로, 이를 다루기 쉽도록 65536을 곱한 후에 소수점 아래를 버리고 정수부만 출력한다.
문제 풀이
간단한 문제라고 생각했으나
자카드 유사도는 원소의 중복을 허용하는 다중집합에 대해 확장할 수 있다.
이 조건 때문에 고민을 하게 됐다.
str1과 str2의 리스트를 생성하고 교집합과 합집합을 구하기 위해 set() 메서드를 사용할 경우 중복되는 원소를 모두 삭제하기 때문에 자카드 유사도를 구할 수 없다.
문제의 예시를 예로 들자면, str1 = 'aa1+aa2', str2 = 'AAAA12' 에서 'aa'라는 공통 원소가 모조리 삭제되어 str1과 str2의 교집합은 {'aa'}, 합집합도 {'aa'}가 되어 자카드 유사도가 1이 되어버린다.
하지만 조건에서 다중집합을 허용한다고 했기 때문에, 실제로는 교집합은 {'aa', 'aa'}, 합집합은 {'aa', 'aa', 'aa'}가 되어야 한다.
따라서 일반적인 set() 메서드를 사용해서는 정답을 구할 수 없다.
이를 해결하기 위해 한참 고민하다가 collections 패키지를 떠올려 문제를 해결할 수 있었다.
풀이 과정
str1과 str2 매개변수 전처리
가장 먼저 해야 할 일은 매개변수인 str1과 str2의 전처리였다. 조건에서 대문자와 소문자의 차이는 무시하고, 오로지 영문자로 이루어진 조합의 경우에만 자카드 유사도에 사용한다 했으므로 이를 충족하는 리스트 형태로 바꿔주었다.
str1_low = str1.lower()
str2_low = str2.lower()
str1_lst = []
str2_lst = []
for i in range(len(str1_low)-1):
if str1_low[i].isalpha() and str1_low[i+1].isalpha():
str1_lst.append(str1_low[i] + str1_low[i+1])
for j in range(len(str2_low)-1):
if str2_low[j].isalpha() and str2_low[j+1].isalpha():
str2_lst.append(str2_low[j] + str2_low[j+1])Counter 객체 변환
전처리 된 리스트 형태의 str1_lst와 str2_lst를 각각 Counter 객체로 변환시켜준다.
from collections import Counter
Counter1 = Counter(str1_lst)
Counter2 = Counter(str2_lst)Counter 메서드는 각각의 리스트는 해당 원소값을 key값으로 하고, 원소의 갯수를 value값으로 하는 dictionary 형태의 구조를 반환한다.
예를 들어 str1 = FRANCE, str2 = french 라면, 이 로직을 거쳤을 경우 Counter1과 Counter2는 각각 다음의 값을 출력한다.
print(Counter1, Couner2)
>>> Counter({'fr': 1, 'ra': 1, 'an': 1, 'nc': 1, 'ce': 1}) Counter({'fr': 1, 're': 1, 'en': 1, 'nc': 1, 'ch': 1})여기에서 우리가 필요한 것은 dictionary 형태의 구조가 아니라, 각각의 key값에 해당하는 고유의 원소값이다.
따라서 elements() 메서드를 사용해 원소값만을 추출하였다.
교집합과 합집합 구현
Counter 메서드의 특징은 set() 함수와 마찬가지로 집합 구조를 생성할 수 있다는 것이다.
교집합은 & 표현, 합집합은 | 표현으로 쉽게 구현할 수 있다.
inter = list((Counter1 & Counter2).elements())
union = list((Counter1 | Counter2).elements())
print(inter, union)
>>> ['fr', 'nc'] ['fr', 'ra', 'an', 'nc', 'ce', 're', 'en', 'ch']자카드 유사도 계산
문제의 정의에서 자카드 유사도는 (교집합의 갯수 / 합집합의 갯수) 로 계산한다.
다만 이 문제의 경우 자카드 유사도는 0에서 1사이의 실수로 나타나기 때문에 다루기 쉽도록 자카드 유사도에 65536을 곱한 뒤 정수 부분만 출력하도록 하였다.
교집합과 합집합이 모두 0 인 경우 자카드 유사도가 0이거나 계산할 수 없으므로, 이 경우 65536이 출력되도록 한다.
그 외의 경우에는 공식에 따라 자카드 유사도를 출력하면 된다.
if len(union) == 0 and len(inter) == 0:
return 65536
else:
return int(len(inter) / len(union) * 65536)위 과정의 최종코드는 다음과 같다.
from collections import Counter
def solution(str1, str2):
str1_low = str1.lower()
str2_low = str2.lower()
str1_lst = []
str2_lst = []
for i in range(len(str1_low)-1):
if str1_low[i].isalpha() and str1_low[i+1].isalpha():
str1_lst.append(str1_low[i] + str1_low[i+1])
for j in range(len(str2_low)-1):
if str2_low[j].isalpha() and str2_low[j+1].isalpha():
str2_lst.append(str2_low[j] + str2_low[j+1])
Counter1 = Counter(str1_lst)
Counter2 = Counter(str2_lst)
inter = list((Counter1 & Counter2).elements())
union = list((Counter1 | Counter2).elements())
if len(union) == 0 and len(inter) == 0:
return 65536
else:
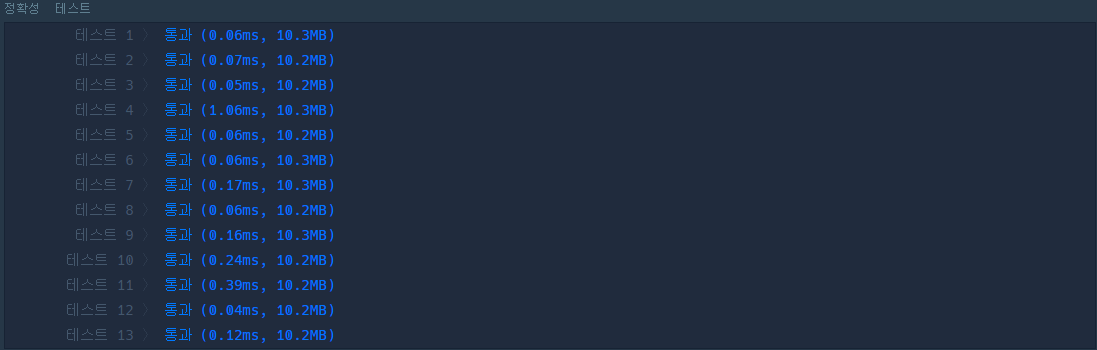
return int(len(inter) / len(union) * 65536)실행 결과
채점 결과