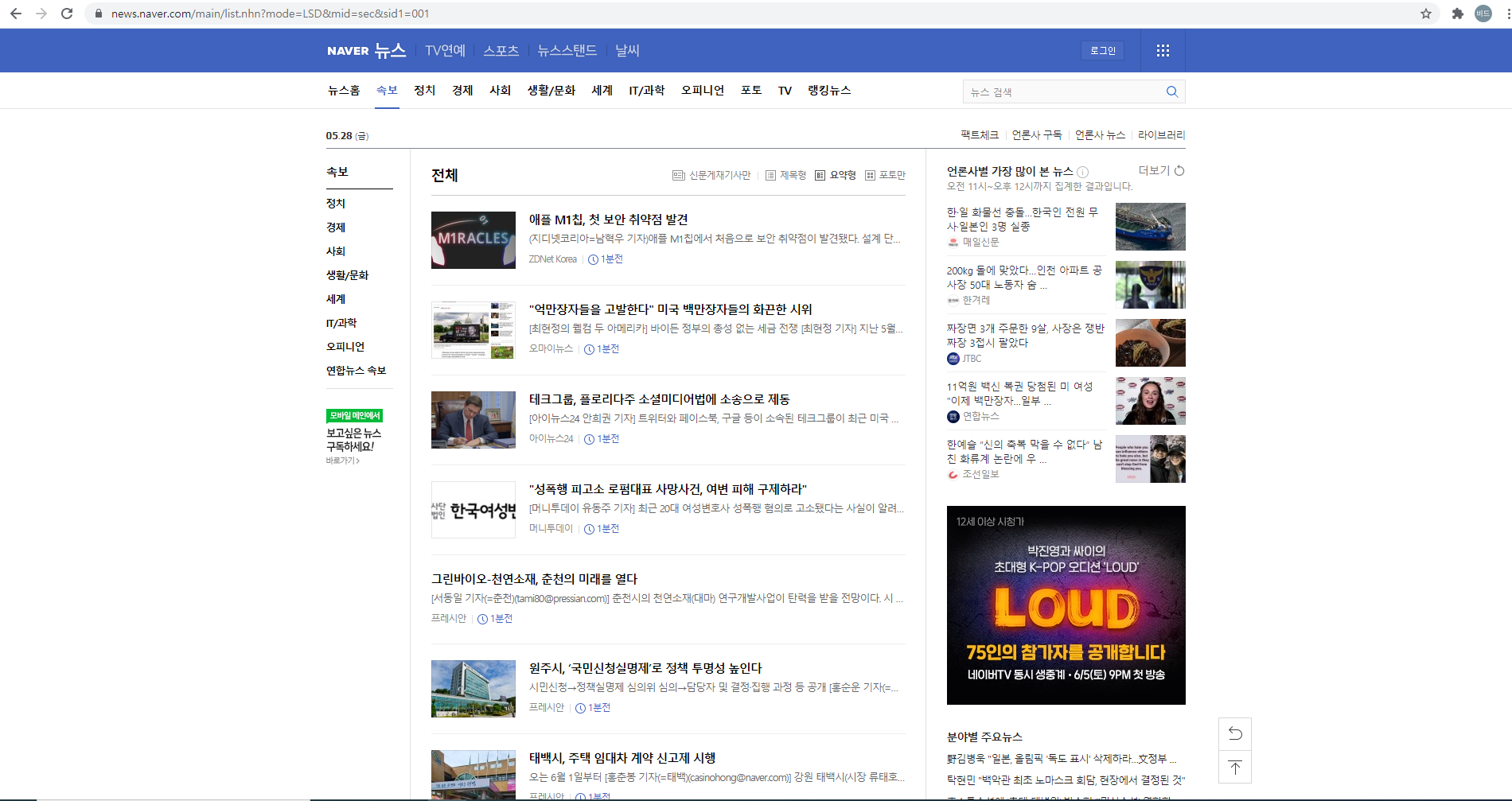
네이버 뉴스기사 속보 페이지 크롤링 코드
원하는 날짜와 페이지 범위를 입력하면 csv 파일로 저장해주는 코드
심심해서 만들어 봤다.
import requests
from bs4 import BeautifulSoup
import pandas as pd
import urllib.request
def page_get():
x, y = map(str, input('가져올 뉴스의 시작 날짜와 종료 날짜를 입력하세요.(예 : 19980501 20200131) :').split())
a, b = map(int, input('시작 페이지와 종료 페이지를 입력하세요.(예 : 1 15) :').split())
print('\n' * 2)
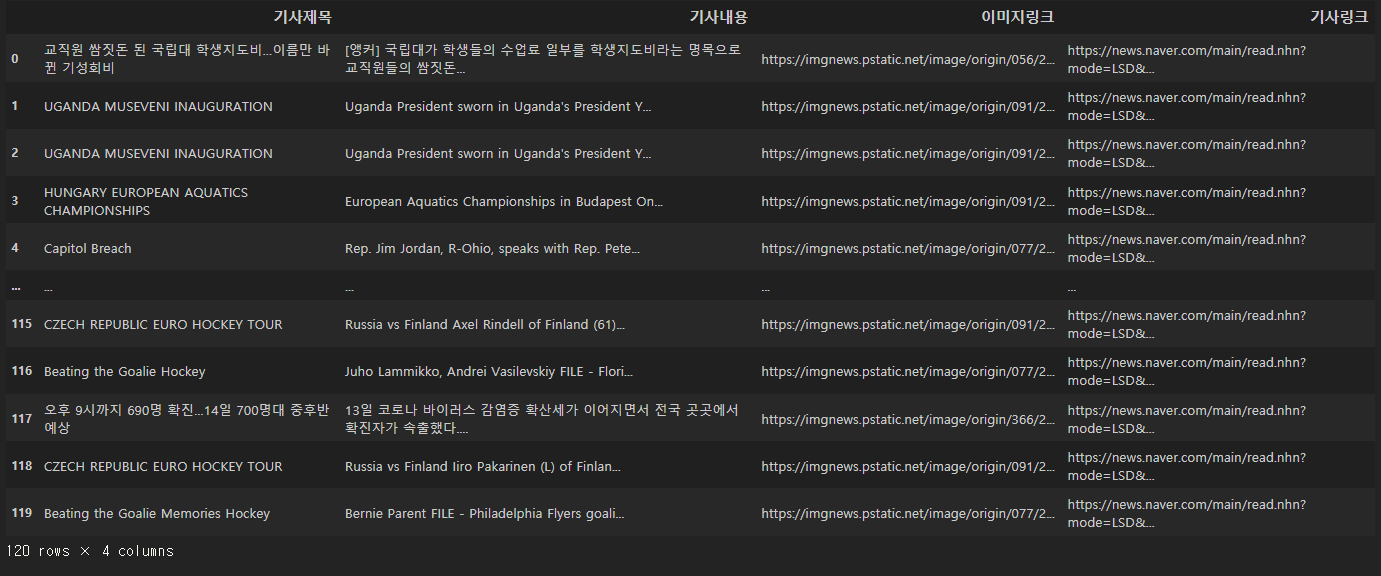
df = pd.DataFrame(columns=['기사제목', '기사내용', '이미지링크', '기사링크'])
df_title = []
df_link = []
df_img = []
df_content = []
for date in (pd.date_range(start=x, end=y).strftime("%Y%m%d").to_list()):
for num in range(a, b+1):
url = 'https://news.naver.com/main/list.nhn?mode=LSD&mid=sec&sid1=001&date=%s&page=%d'%(date, num)
headers = {'User-Agent' : 'Mozilla/5.0'}
html = requests.get(url, headers=headers)
soup = BeautifulSoup(html.text)
headline = soup.find_all('dl')
for item in headline:
try:
title = item.find('a', {'class' : 'nclicks(fls.list)'}).find('img')['alt']
print('[기사 제목]')
print(title)
except:
title = 'No Title'
print('No Title')
df_title.append(title)
write = item.find('a')['href']
print('[기사 링크]')
print(write)
df_link.append(write)
try:
img = item.find('dt', {"class" : "photo"}).find('img')['src']
print('[기사 이미지]')
print(img)
except:
img = 'No img'
print('No Image')
df_img.append(img)
try:
content = item.find('span', {'class' : 'lede'}).text
print(['기사 본문'])
print(content)
except:
content = 'No content'
print('No Contents')
df_content.append(content)
print('-' * 30)
df['기사제목'] = df_title
df['기사내용'] = df_content
df['이미지링크'] = df_img
df['기사링크'] = df_link
df.drop_duplicates()
df.to_csv('../data/naver_news_multi.csv', encoding='utf-8-sig', index=False)
for row in range(0, len(df)):
try:
img_file = df.iloc[row, 2].split("?")
img_name = img_file[0].split("/")[-1]
down_filename = '../data/img_file/' + img_name
url = img_file[0]
urllib.request.urlretrieve(url, down_filename)
except:
pass실행 결과

.