참고
- 2020-09-03-01)오라클객체-뷰.sql
- 2020-09-03-02)오라클객체-SEQUENCE.sql
- 2020-09-03-03)오라클객체-SYNONYM.sql
- 2020-09-03-04)오라클객체-INDEX.sql
- view, sequence, synonym, index 등이 제공됨
1. VIEW
- 가상의 테이블
- 검색명령의 결과 집합
- 필요한 정보가 다수의 테이블에 존재하는 경우
- 특정 자료에 대한 접근제한(보안성 확보)
- 커서하고 거의 동일한 집합(커서보다 조금 더 좁은 의미)
- 이름 붙여서 저장해놓으면 쿼리의 대상이 될 수 있음
- READ ONLY 옵션 부여하지 않으면 뷰 내용변경시 원본에도 영향 미침 (DEFAULT값: 원본도 변경)
- 파이차트? 할때 10분에 한번씩 조인하는 것보다 뷰를 날리면 쉽게 작업
사용형식

- [FORCE|NOFORCE]
- FORCE: 기준 테이블이 없어도 VIEW를 생성할 수 있게 만들어 주는 것
- NOFORCE : 기준 테이블 없으면 VIEW 생성 불가(DEFAULT)
- '컬럼LIST'
- 생성되는 뷰의 컬럼명, 생략되면 기준테이블의 컬럼명을 사용
- [WITH CHECK OPTION]
- SELECT 문에서 조건을 부여하여 VIEW가 생성된 경우 그 조건에 맞지 않는 VIEW의 수정(UPDATE)이나 INSERT 는 제한
- ex. 마일리지 3천이상 검색해 view를 만듬. 그 중 한명을 2500으로 변경하는 건 불가. 뷰 내 조작 제한때문
- SELECT 문에서 조건을 부여하여 VIEW가 생성된 경우 그 조건에 맞지 않는 VIEW의 수정(UPDATE)이나 INSERT 는 제한
- [WITH READ ONLY]
- 읽기전용 뷰생성
주의사항
- WITH CHECK OPTION | WITH READ ONLY 둘중 하나만 쓸 수 있어
- READ ONLY 쓰면 수정이 안되니까
- 제약조건 (WITH절 포함)이 있는 VIEW에서 ORDER BY절 사용금지
- 뷰가 GROUP BY, DISTINCT 사용하여 생성된 경우 INSERT,UPDATE,DELETE를 사용할 수 없음
- 표현식 또는 함수(일반)를 사용하여 뷰가 생성된 경우 해당 컬럼을 수정할 수 없다
- CURRVAL, NEXTVAL 등의 의사레코드는 사용할 수 없음
- ROWID, ROWNUM 등은 컬럼별칭 사용
예시
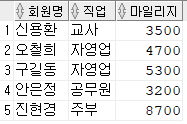
1. 회원테이블에서 마일리지가 3000이상인 회원의 회원명, 직업,마일리지 조회하고 결과를 뷰로 생성
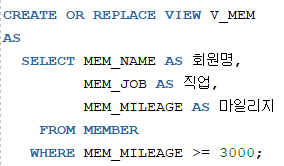

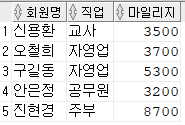

- 뷰 V_MEM
- 원본테이블도 변경됨
- 지우는 건 안됨
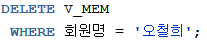
- 자식테이블(CART)이 존재하기 때문에 원본데이터(MEMBER)를 지울 수 없음
- ORA-02292: integrity constraint (chichi.FR_CART_MEMBER) violated - child record found
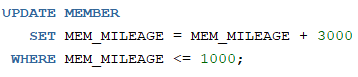
- 원본도 변경됨

2. 2005년 7월 회원별 구매정보를 조회하시오
- Alias: 회원명, 구매수량합계, 구매금액합계
- 단 결과를 뷰로 생성하시오

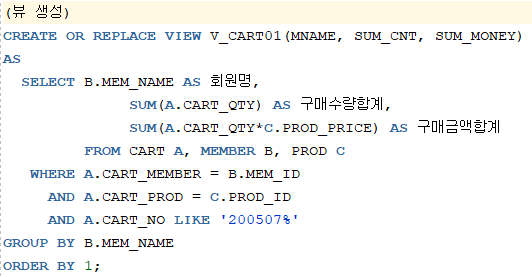
- 



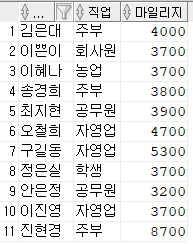
- ORA-01402: view WITH CHECK OPTION where-clause violation
- 뷰가 3000 이상인애들 모아놓은건ㄷㅔ 2500으로 하려니 오류뜸
2. SEQUENCE
- 연속적으로 증가 또는 감소하는 값을 생성하는 객체
- 테이블의 기본키 항목을 설정할 컬럼이 없는 경우 주로 사용
사용형식
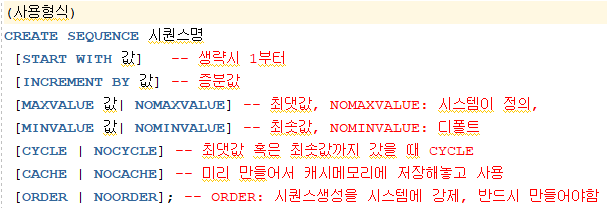
- REPLACE 불가

- 시퀀스가 생성된 후 해당 세션에서 처음 명령은 시퀀스명.nextval 이어야 함
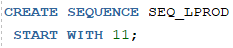
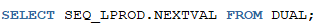
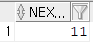
예시
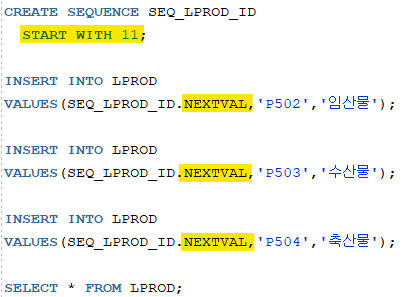
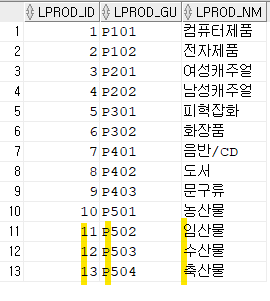
1. 분류테이블에 새로운 분류 데이터를 입력하시오
- LPROD_ID는 SEQUENCE 객체를 사용할 것

3. SYNONYM 동의어
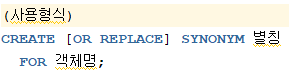
- 오라클에 사용되는 객체에 부여하는 별칭
- 컬럼에 부여하는 별칭은 그 쿼리 안에서만 유효하지만, SYNONYM으로 부여하면 어느 쿼리에서나 사용가능
사용형식
예시
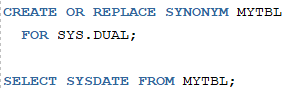
1. DUAL을 MYTBL로
2. DEPARTMENTS를 DEPT로

4.INDEX
- 검색효율을 높이기 위한 객체
인덱스가 필요한 컬럼
- 자주 검색해야하는 컬럼
- WHERE 절에서 동등연산자('=')을 사용하는 컬럼
- 기본키와 외래키
- 기본키 : 자동생성
- 외래키 : 자주 조인이 일어날 때 생성
- 조인(조인조건)이나 정렬(ORDER BY)에 사용되는 컬럼
- 인덱스값 불필요한 경우 : 컬럼의 도메인이 아주 작아 중복되는 값이 많을때 (ex 남17명, 여8명)
인덱스의 종류
(1) Unique/Non-Unique
- 중복 값을 허용하는지 여부에 따른 분류
- Non-Unique는 중복 값 허용
- Null도 사용가능하나(기본키와 외래키 인덱스는 제외) 한번만 사용
(2) 자동 index
- 테이블 생성시 PK, Unique 조건 부여시 생성
(3) Normal Index (B-Tree Index)
- Default Index
- 트리구조 사용
- ROWID(물리적 주소)와 컬럼명 값을 조합하여 산출된 주소 사용
(4) Bitmap Index
- 관계차수가 적은 경우 효율적
- 자료변동(추가,변경,삭제)가 많은 경우 비효율적
- ROWID와 컬럼 값을 이진으로 조합한 주소사용
(5) Function-Based Index
- 함수가 사용된 컬럼을 인덱스컬럼으로 선택한 경우
- 조건절에 함수사용이 많은 경우 효율적
- 성별: MEM_REGNO2에서 SUBSTR 함수 사용해서 구함
사용형식

예시
1. 회원테이블에서 회원명으로 인덱스를 생성
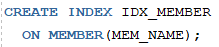
{kind=link}
2. BUYER테이블에서 거래처코드와 이름을 합친 인덱스 생성


- SUBSTR 함수 기반 인덱스
인덱스 재생성 (REBUILD)
- 다른 테이블 스페이스로 테이블이 이동된 경우
- 자료의 변경이 심각하게 발생 된 경우
- 검색속도는 좋을지 몰라도 공간이 많이 소요되며 인덱스 파일관리를 위한 자원소모(시간,공간,프로세싱타임) -> DB에 부담 됨
사용형식
ALTER INDEX 인덱스명 REBUILD;

갈 길이 멀다