
Spark SQL 소개
1. 빅데이터 정의와 예
- “서버 한대로 처리할 수 없는 규모의 데이터”
- “기존의 소프트웨어로는 처리할 수 없는 규모의 데이터”
- 4V(Volume, Velocity, Variety, Varecity)
- 데이터 [크기 대용량/ 처리 속도 / 구조화&비구조화 /품질]
2. 빅데이터 처리가 갖는 특징
- 비구조화된 데이터일 가능성이 높음: SQL만으로는
부족 ->결국 다수의 컴퓨터로 구성된 프레임웍이 필요
3. 하둡의 등장과 소개
1) 하둡(Hadoop)이란?
-
오픈소스 소프트웨어 플랫폼 : 다수의 싸구려 컴퓨터로 구축된 시스템(분산 파일 시스템=HDFS & 분산 컴퓨팅 시스템=MapReduce)
-
MapReduce 위에 다양한 컴퓨팅 언어들이 만들어짐
-
하둡의 발전 : 하둡 2.0
-

-
Storage Layer : HDFS 2
-
Resource Management Layer : YARN(하둡 2/3에서의 분산 컴퓨팅 시스템 이름)
-
Application Layer : MapReduce, Spark, Tez , etc
-
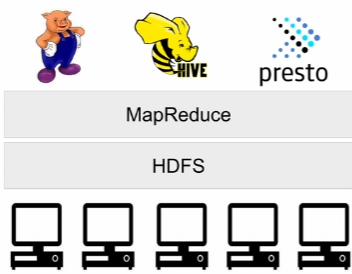
2) HDFS - 분산 파일 시스템
3) MapReduce: 분산 컴퓨팅
- Spark = 새로운 분산 컴퓨팅 시스템
4. YARN의 동작 방식
1) 분산 컴퓨팅 시스템: 하둡 2.0 (YARN 1.0)
- YARN : 하둡 2.0의 클러스터 자원 관리자
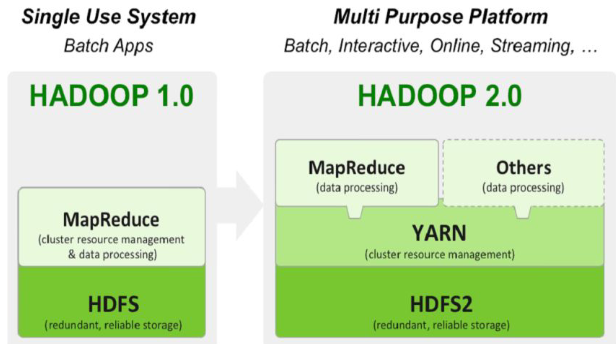
2) YARN의 동작
5. 맵리듀스 프로그래밍 소개
1) 맵리듀스 프로그래밍의 특징
2) 맵과 리듀스
3) MapReduce 프로그램 동작 예시
4) MapReduce: 프로그래밍 예제: Word Count Reducer
5) MapReduce: Shuffling and Sorting
6) MapReduce: Data Skew
7) MapReduce 프로그래밍의 문제점
6. 하둡 설치와 맵리듀스 프로그래밍 실습
7. Spark 소개
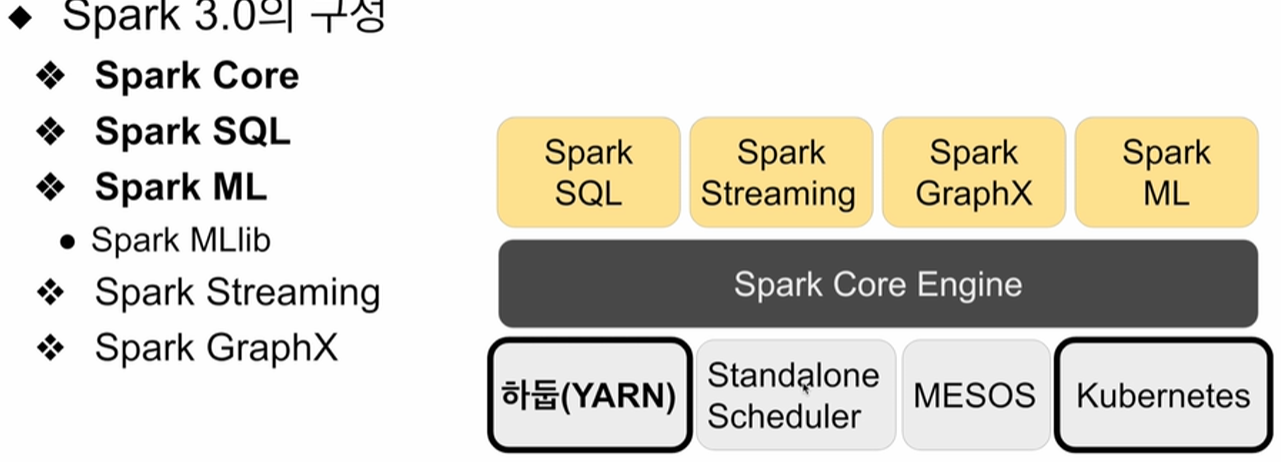
Spark 데이터 시스템 사용 예시 1
- 대용량 비구조화된 데이터 처리하기(Hive의 대체 기술)
- ETL or ELT
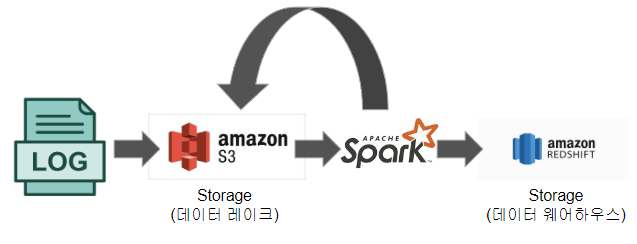
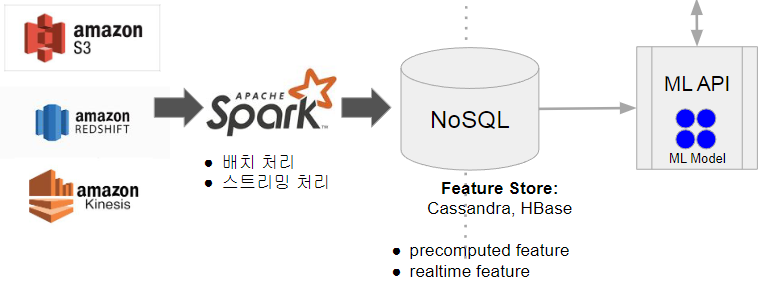
Spark 데이터 시스템 사용 예시 2
- ML 모델에 사용되는 대용량 피쳐 처리
실습 Spark 환경
- Spark 버전 3
- Python 사용: PySpark
