
이 포스트의 내용은 구글의 V8엔진 엔지니어인 Benedikt Meurer와 Mathias Bynens 의 JavaScript Engines: The Good Parts 세션을 기반으로 작성하였습니다.
지난 포스트에서는 JS엔진의 종류와 최적화 컴파일러에 대하여 알아보았습니다.
이번 포스트에서는 객체와 배열의 속성에 접근하는 속도를 빠르게 하기 위해 엔진이 어떤 트릭을 사용했는지 알아보겠습니다.
JS 엔진이 객체 모델을 구현하는 방법
먼저 JS엔진은 객체 모델을 어떻게 구현했는지 짚고 가겠습니다.
객체의 정의
객체는 JS 명세에 따르면 String으로 된 키와 이것으로 접근할 수 있는 값들을 가지고 있는 딕셔너리입니다. 이 키는 단순히 [[value]]에 맵핑되는 것 뿐만 아니라 속성 값(property attributes) 이라고 하는 스펙에도 매핑됩니다.
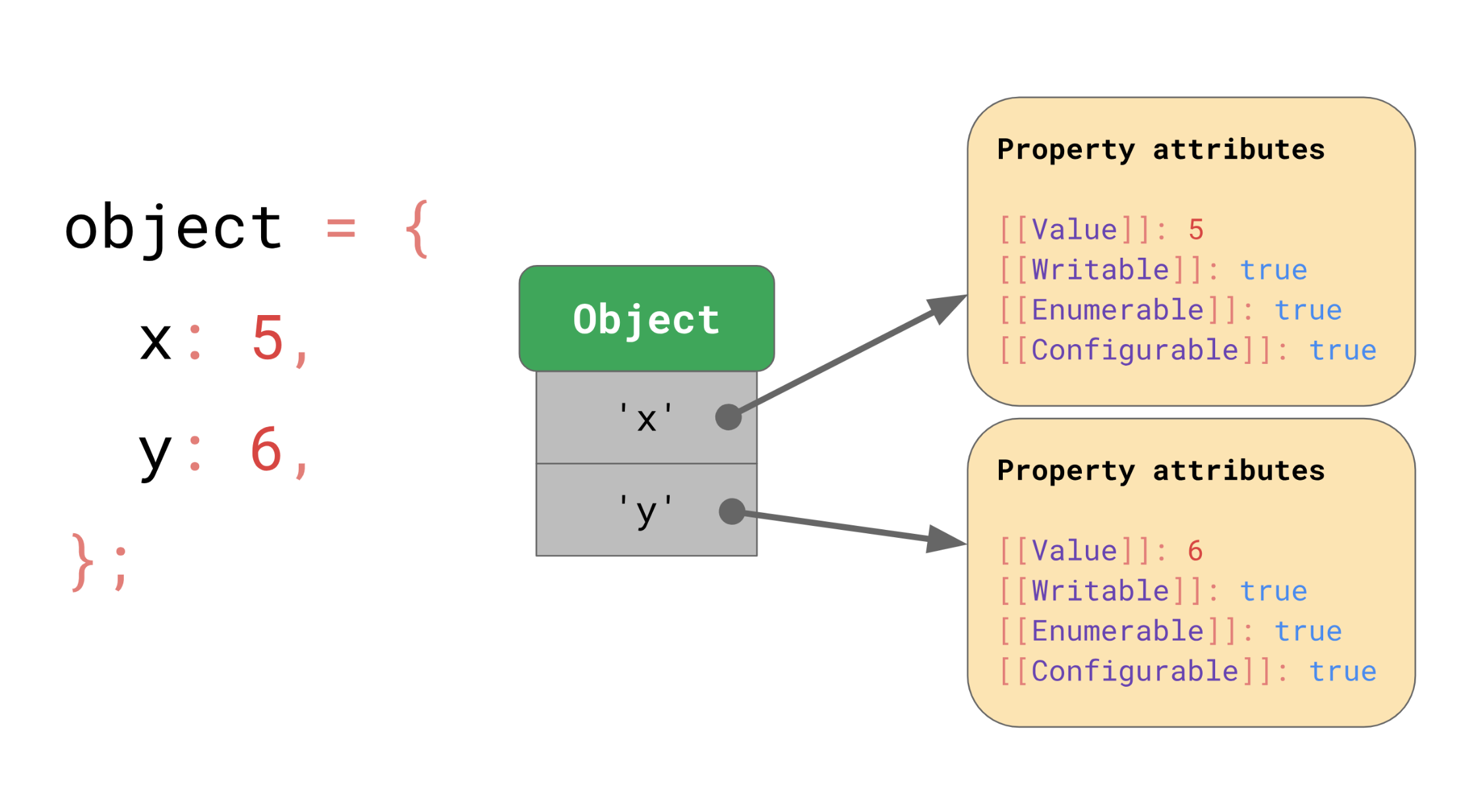
속성 값(property attributes)
객체는 기본적인 속성 값으로 [[Writable]], [[Enumerable]], [[Configurable]] 상태를 가집니다.

- Writable: 할당연산자를 통해 값을 바꿀 수 있는지를 기술합니다.
- Configurable: 이 속성 기술자는 해당 객체로부터 그 속성을 제거할 수 있는지를 기술합니다.
- Enumerable: 해당 객체의 키가 열거 가능한지를 기술합니다.
어떤 객체나 속성이든 Object.getOwnPropertyDescriptor API를 이용해 이 값들에 접근할 수 있습니다.
const object = { foo: 42 };
Object.getOwnPropertyDescriptor(object, 'foo');
// => {value: 42, writable: true, enumerable: true, configurable: true}객체가 기본적으로 가지는 값과 속성을 알아보았습니다. 이번엔 배열입니다.
JS의 배열
배열은 조금 다르게 처리하는 특별한 객체라고 생각하면 됩니다.
객체와 다른 배열만의 특징은 다음과 같습니다.
-
인덱스(index)가 존재한다.
배열 인덱스는 무엇일까요? 그것은 제한된 범위가 있는 정수입니다.
JS 명세에 따르면, 배열은 2³²−1 개 까지의 아이템을 가질 수 있습니다.
따라서 배열 인덱스는 0 부터 2³²−2 까지의 범위에서만 인덱스로 유효한 정수 값입니다. -
길이(length) 정보를 가집니다.
length property는 마치 마법 같은 것이라고 할 수 있습니다.
배열에 아이템을 추가하면 length property는 저절로 늘어나기 때문입니다!
이 작업은 사실 엔진에서 자동으로 해주는 겁니다.const array = ['a', 'b']; array.length; // 2 array[2] = 'c'; array.length; // 3
JS 엔진에서 배열을 다루는 방법
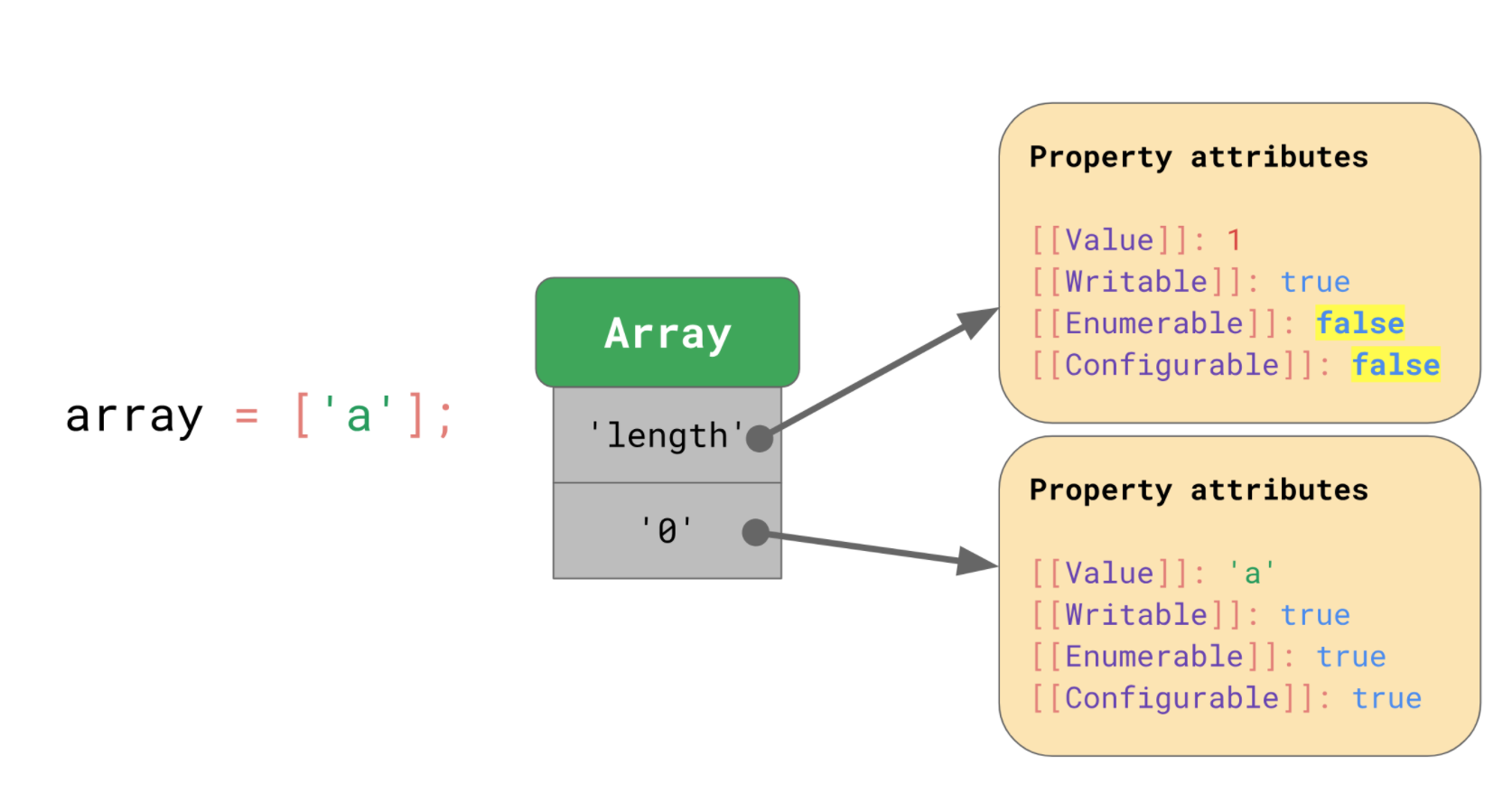
기본적으로 객체와 비슷합니다. 배열은 인덱스를 포함하여 모두 string 키를 가집니다.
아래 그림을 보면 인덱스인 '0' 은 'a'라는 값을 가지며, 값을 바꿀 수 있고(Writable), 열거 가능하고(Enumerable), 삭제 가능(Configurable) 합니다. 또 다른 프로퍼티인 length 의 값은 1이며, 값을 바꿀 수 있지만 열거와 삭제가 불가능 합니다.
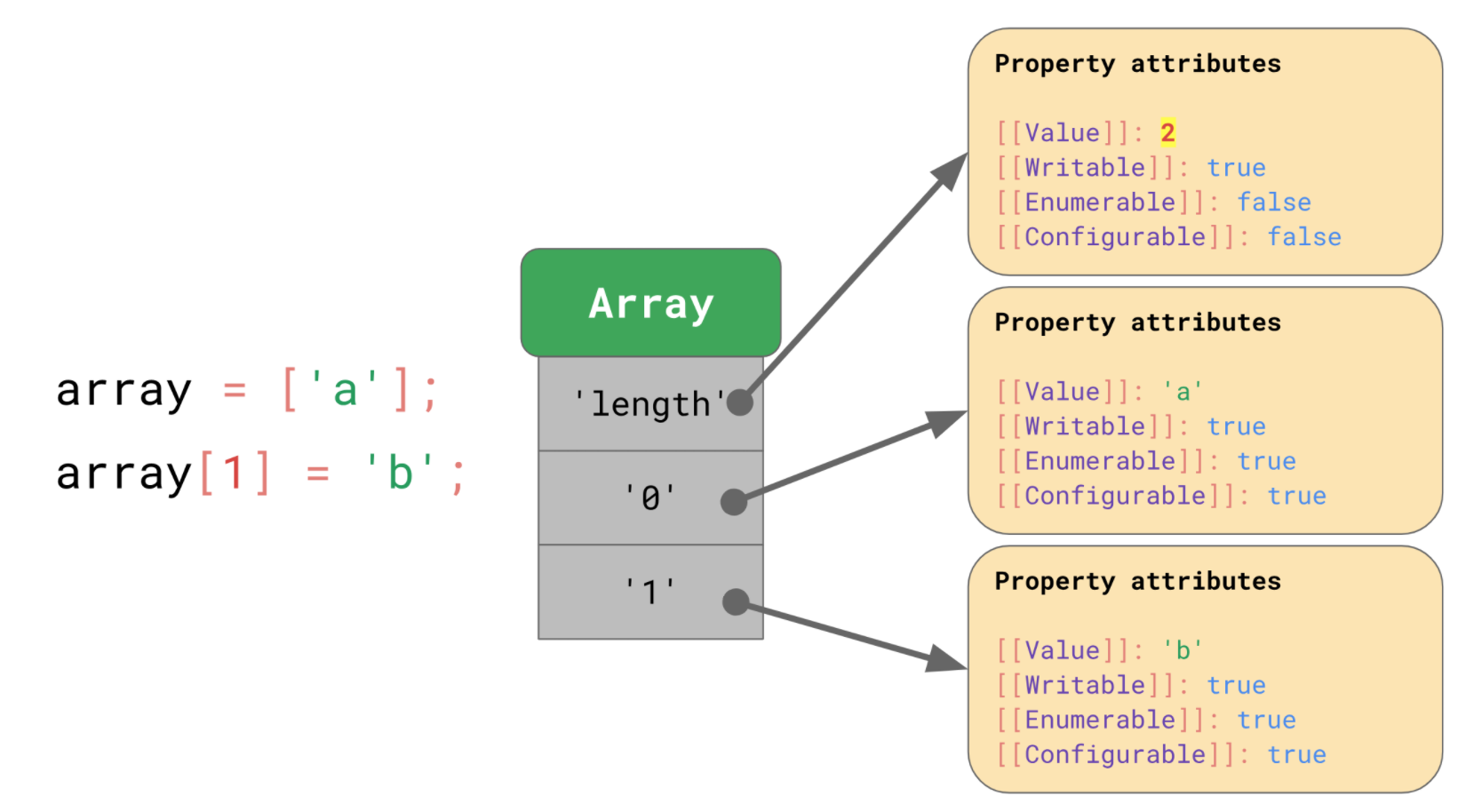
배열에 새로운 아이템을 추가하게 되면, JS엔진은 length의 속성 값 중 [[value]]를 자동으로 증가시킵니다.
엔진의 프로퍼티 접근 최적화
Shape
function logX(obj){
console.log(obj.x);
}
const obj1 = { x:1, y:2 };
const obj2 = { x:3, y:4 };
logX(obj1);
logX(obj2);
동일한 프로퍼티 x와 y를 string 키로 가지는 두 객체가 있습니다.
이를 객체의 모양(shapes)이 똑같다고 합니다.
함수 logX를 통해 두 객체 각각에서 같은 프로퍼티 x 에 접근한다고 합시다.
JS 엔진은 프로퍼티 접근 시에 모양이 같은 점을 이용하여 최적화를 합니다.
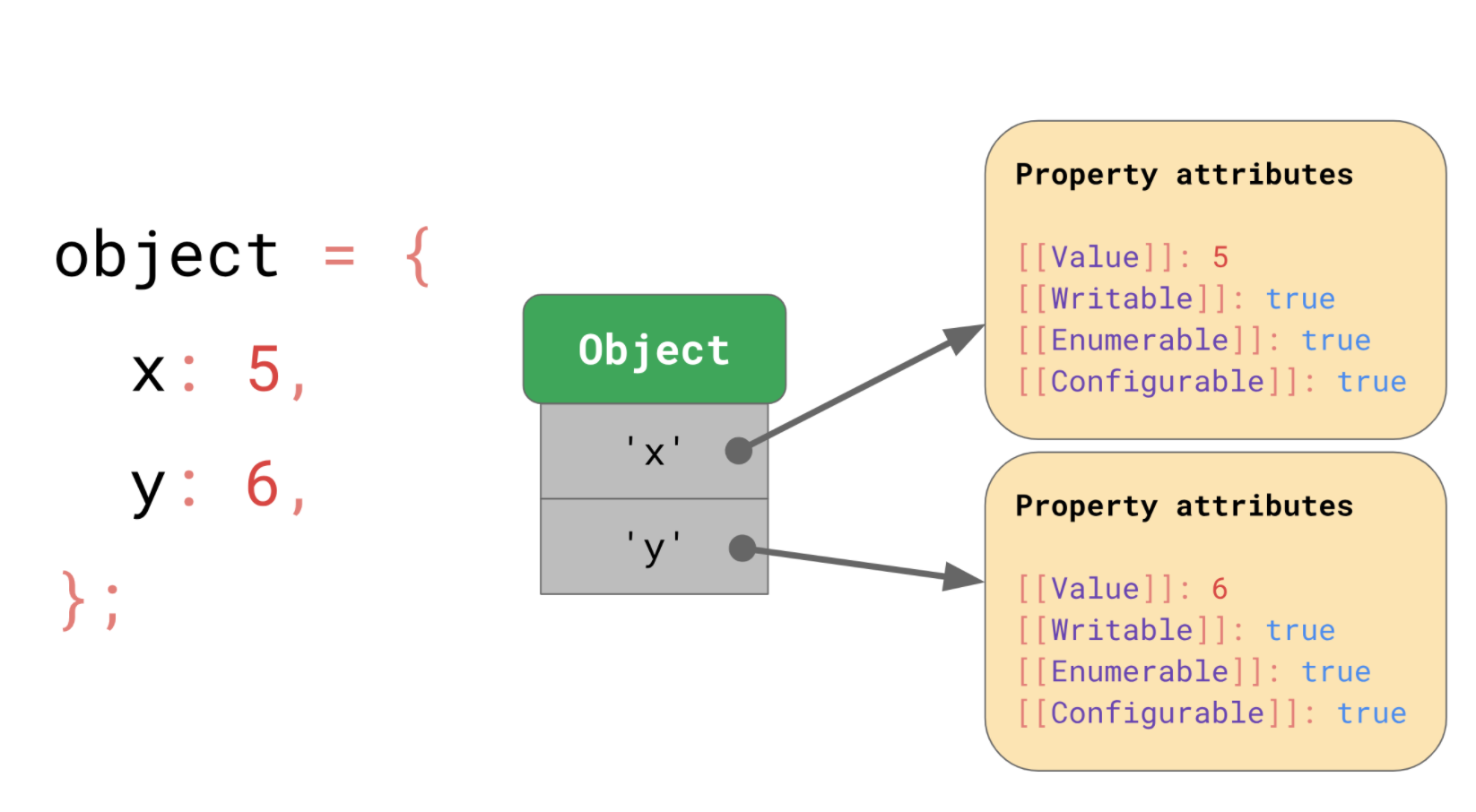
객체의 키 x, y는 각각의 속성 값(property attributes)을 가리킵니다. 예를 들어 x 프로퍼티에 접근하게 되면 JS엔진은 Object에서 x 키를 찾은 다음, 해당하는 속성 값을 불러오고 [[Value]] 값을 반환할 것입니다.
여기서 5와 6 같은 데이터는 어디에 저장될까요?
모든 객체 별로 정보를 저장하게 되면 낭비입니다. 만약 비슷한 모양의 객체가 더 많이 생긴다면, 그만큼의 중복할 발생할 것이고 필요없는 메모리 사용이 늘어나기 때문입니다.
그래서 JS 엔진은 직접 값을 저장하는 방법 대신 다음 방법을 사용합니다.
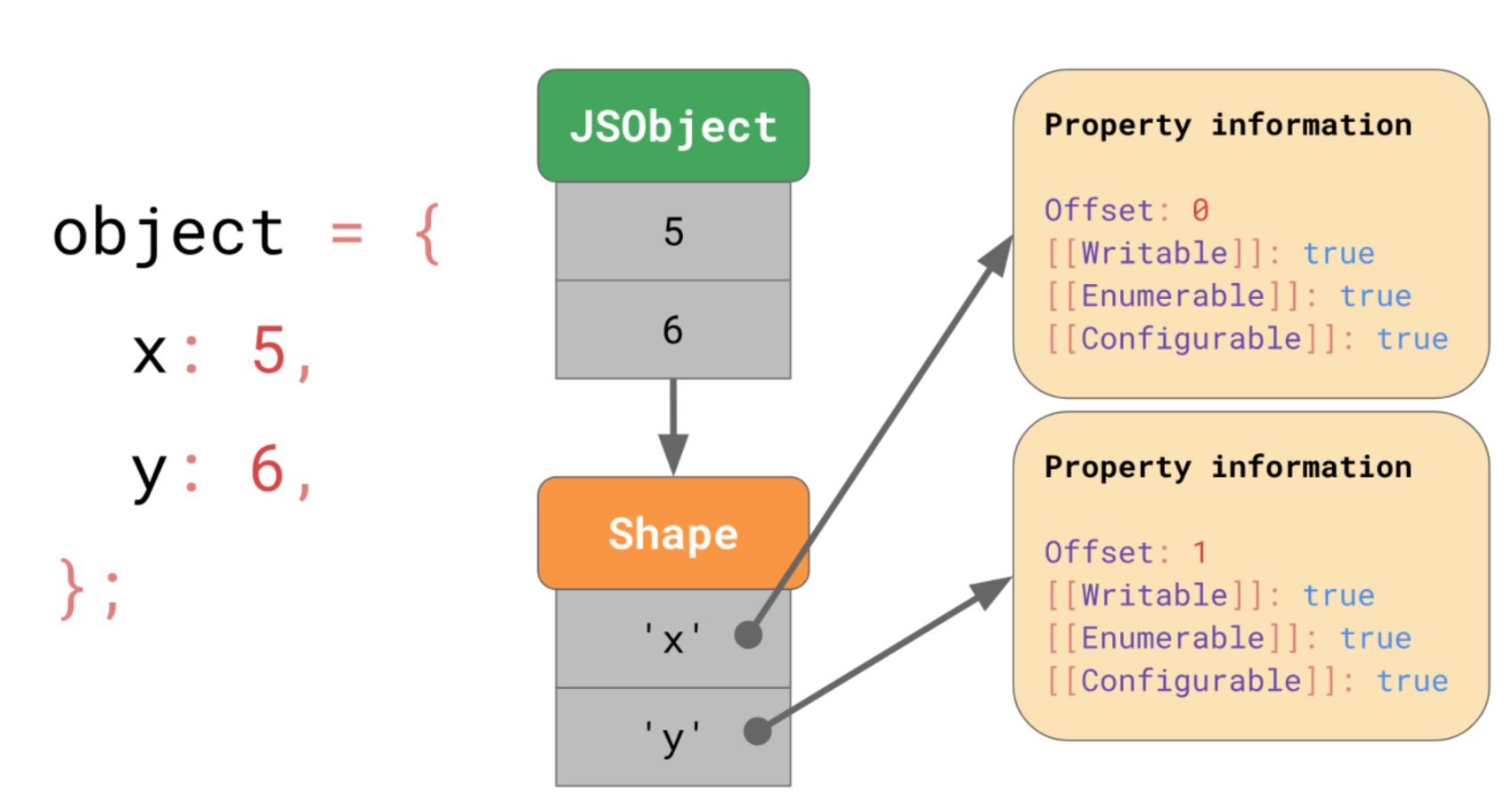
우선 엔진은 따로 Shape라는 곳에 프로퍼티 이름과 속성 값들을 저장합니다. 하지만 여기에 [[value]] 값 대신 JSObject의 어디에 값이 저장되어 있는지에 대한 정보인 Offset 을 Property information으로 가집니다.
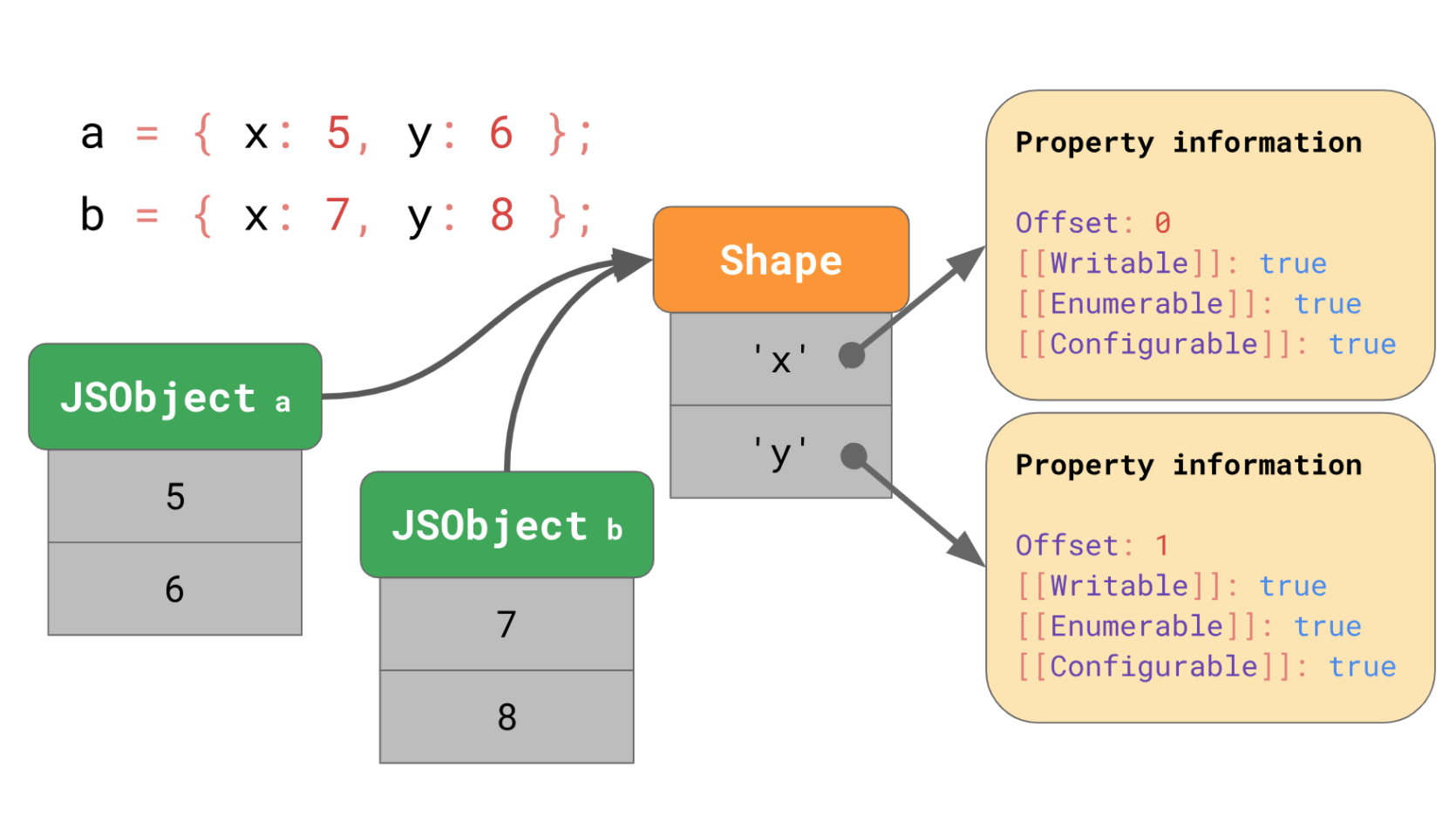
즉, 같은 모양을 가진 모든 JSObject는 동일한 Shape 인스턴스를 가리키게 됩니다.이제 각 객체에는 고유한 값만 저장되므로, 더 이상 중복되지 않습니다. 그리고 같은 모양으로 생긴 더 많은 오브젝트가 있다 하더라도 오로지 하나의 Shape만 존재합니다.
Shape의 정체
모든 JS엔진은 최적화를 위해 이 Shape를 사용하는데, 실제로 이것들을 Shape라고 부르지는 않습니다. 여기에 대해서 많은 연구가 존재하는데, 우리가 이제껏 Shape라고 불렀던 이것은 학술 용어로는 사실 Hidden Classes라고 부릅니다 (!!)
다양한 엔진과 논문에서의 명칭:
- Academic papers call them Hidden Classes (confusing w.r.t. JavaScript classes)
- V8 calls them Maps (confusing w.r.t. JavaScript
Maps) - Chakra calls them Types (confusing w.r.t. JavaScript’s dynamic types and
typeof) - JavaScriptCore calls them Structures
- SpiderMonkey calls them Shapes
혼란스럽겠지만, Structure 정도로 이해하면 편할 것입니다. 하지만 SpiderMonkey에서 부르는 방법처럼 그냥 Shape라고 생각해도 좋습니다.
Shape에 새로운 객체를 추가하기 (Transition chains)
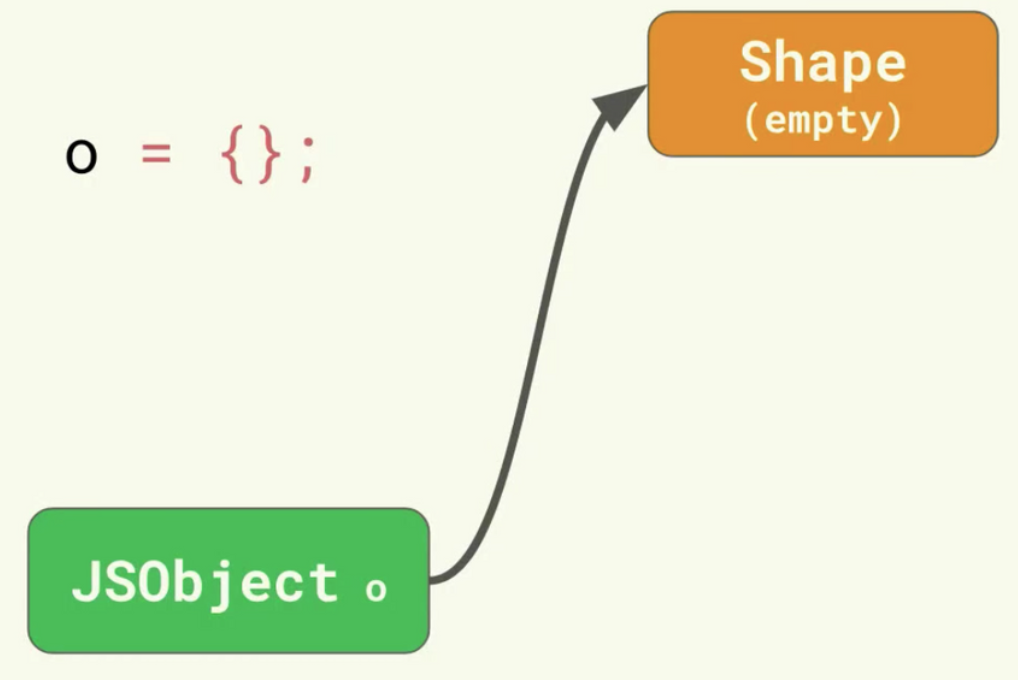
이런 Shape가 있다고 합시다.
const o = {};
o.x = 5;
o.y = 6;새로운 프로퍼티를 추가할 때, JS 엔진은 어떻게 새로운 Shape를 찾을까요?
JS 엔진은 내부에 transition chains라고 하는 Shape를 만듭니다.
먼저, 비어있는 객체인 o가 있으며, 이는 비어있는 Shape를 가리키고 있습니다.
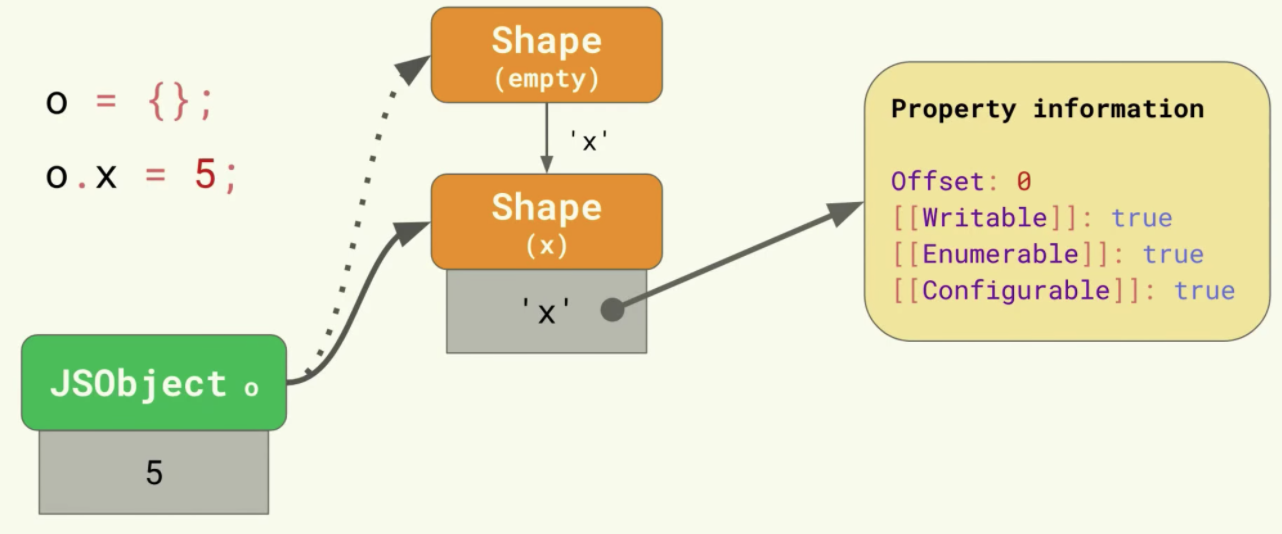
여기에 5라는 값을 가진 x라는 프로퍼티를 추가하게 되면, 비어있던 Shape에서 x를 프로퍼티로 갖고 있는 새로운 Shape로 이동(transition)하게 됩니다. 다음과 같이 JSObject의 값이 추가되고, offset은 0입니다.
새로운 프로퍼티 y를 추가해도 비슷하게 동작합니다. Shape(x,y)로 이동한 다음 값을 추가합니다.
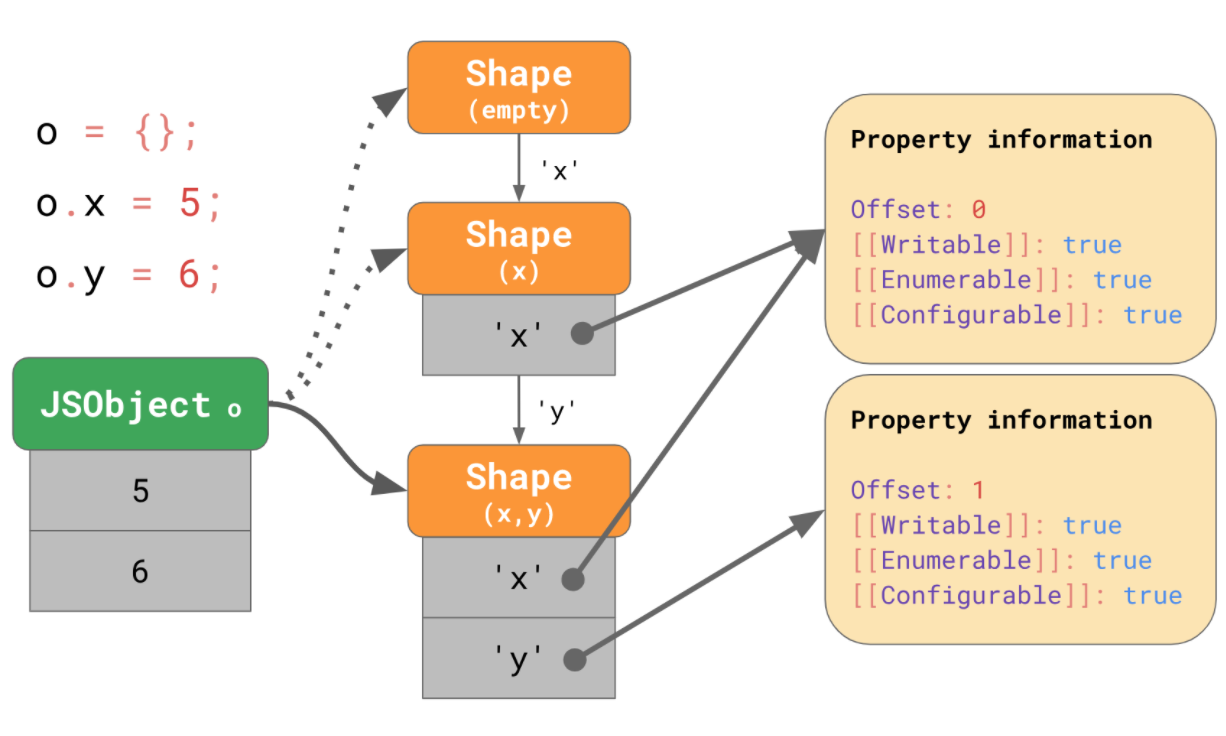
하지만 이런 방법을 모든 테이블에 항상 적용했다가는 많은 메모리 낭비를 일으키겠지요. 그래서 실제로 엔진은 이렇게 동작하지 않습니다.
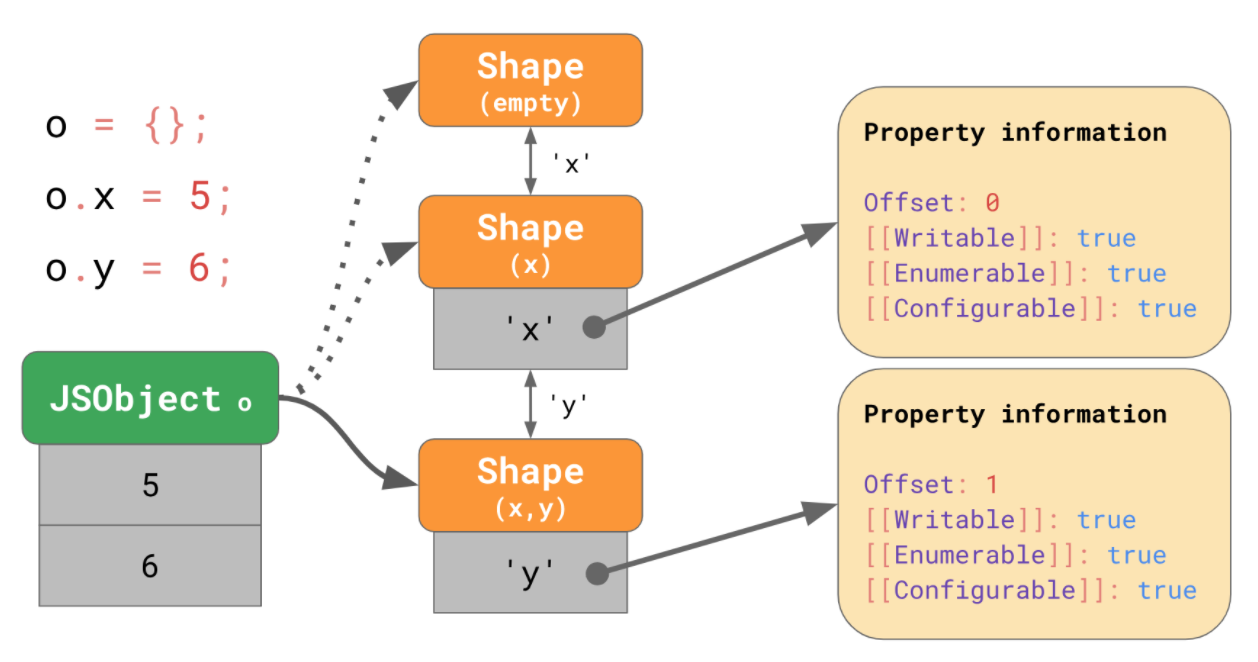
실제로 엔진에서 동작하는 방법
엔진은 추가되는 새로운 프로퍼티 정보를 저장하고, 이전 Shape로 가는 링크를 제공합니다. 만약 o.x를 찾을 때 값이 Shape(x,y) 에 없다면 이전의 Shape(x)에 가서 찾는 겁니다.
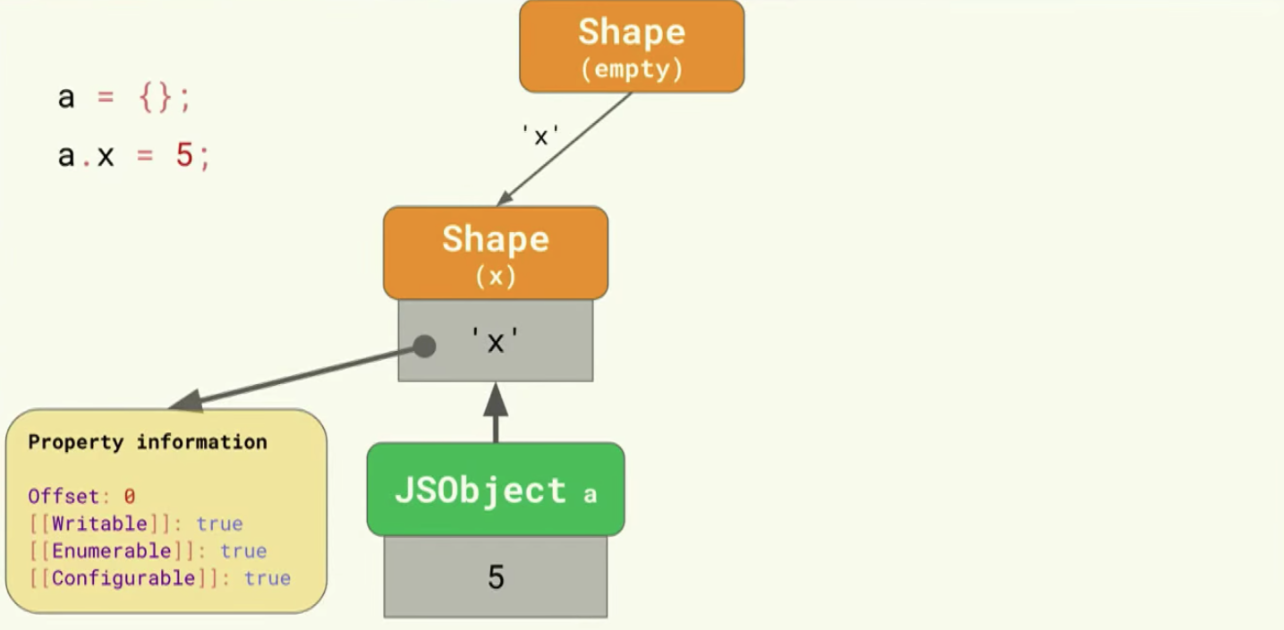
두 객체에서 동일한 Shape를 사용하는 경우 (Transition Tree)
만약에 두 객체에서 동일한 Shape 를 사용한다면 어떻게 될까요?
먼저 하나의 객체 a 에 x = 5 라는 값을 가진 프로퍼티가 있다고 합시다.
이번엔 객체 b에서 y라는 프로퍼티를 추가할 경우 Shape(empty)에서 가지를 뻗어 새로운 Shape(y) 를 만들게 됩니다. 결국 2개의 체인에 3개의 Shape를 가진 트리 체인이 생성됩니다.
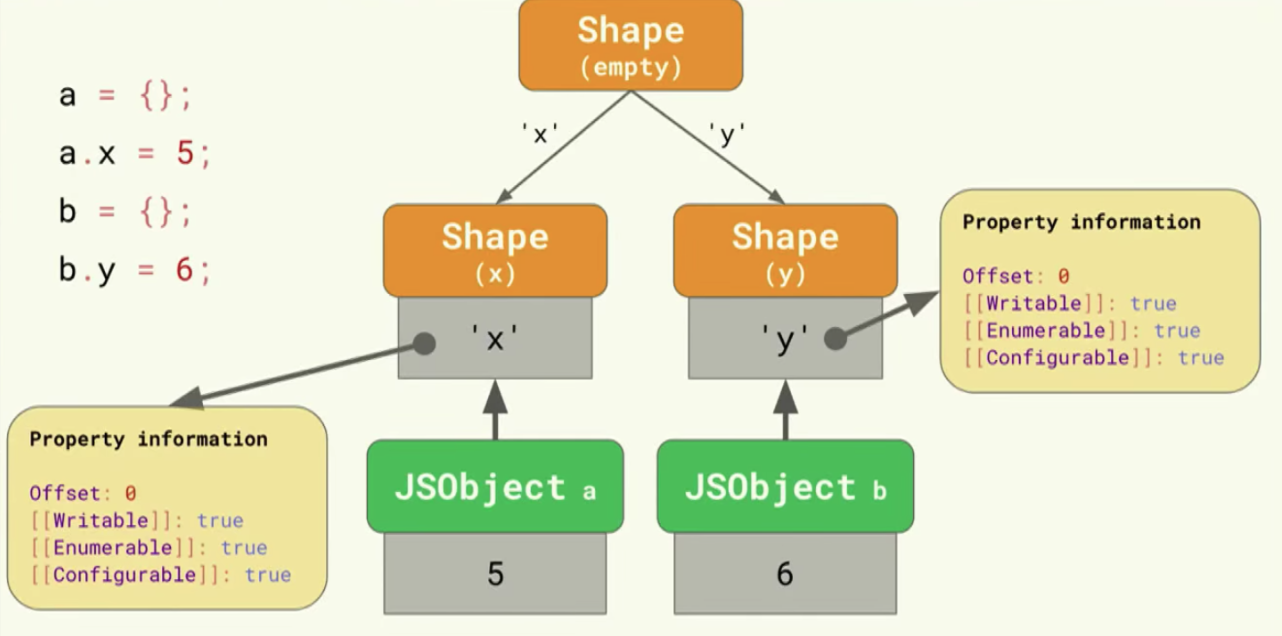
그렇다면 마치 java의 Object처럼 모든 객체의 트리를 거슬러 올라가면 무조건 Shape(empty)에 도달하는 걸까요?
꼭 그렇지는 않습니다.
const obj1 = {};
obj1.x = 6;
const ob2 = {x: 6};ojb2 와 같이, JS에서는 Object Literal을 사용하여 시작부터 프로퍼티를 갖고 생성하도록 할 수 있기 때문입니다. 따라서 Shape(empty)가 아닌, 서로 다른 Root Shape가 생성됩니다.
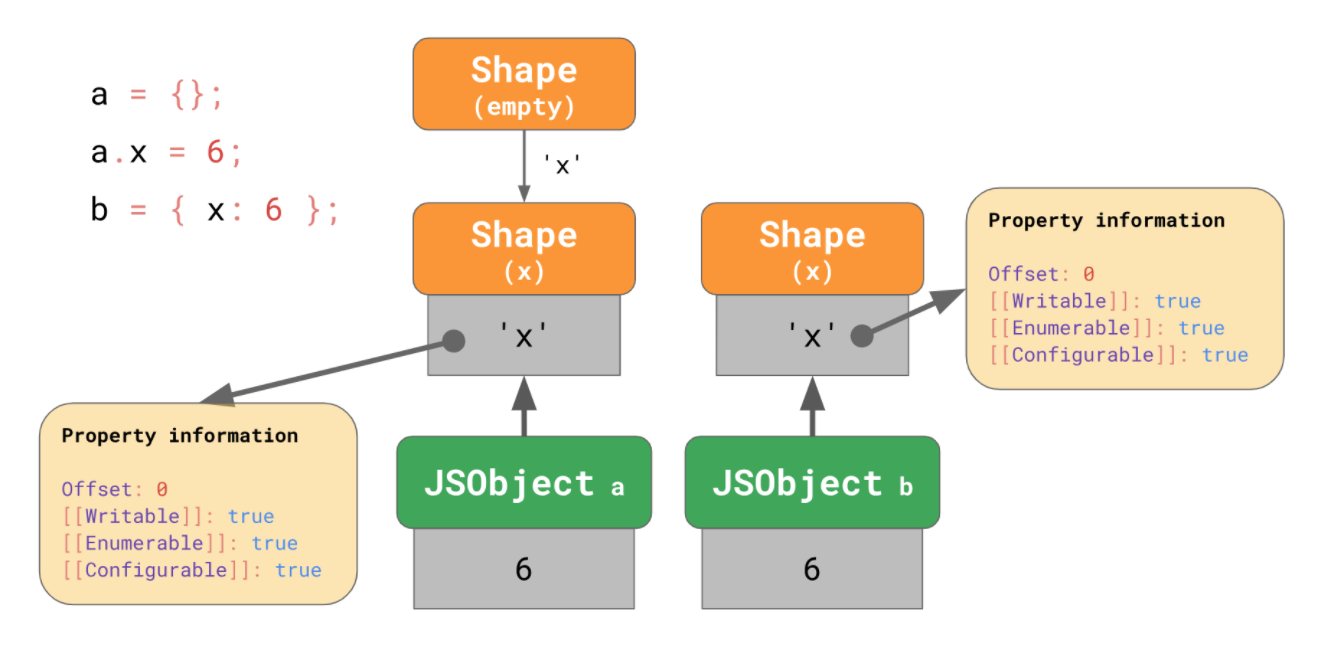
이 방법은 transition chain을 짧게 하고, 객체를 리터럴로부터 생성하여 보다 효율적입니다.
이번엔 이런 상황을 한번 봅시다. point는 x,y,z를 3차원 공간의 좌표로 가지는 객체입니다.
const point = {};
point.x = 4;
point.y = 5;
point.z = 6;앞서 배운 것에 따르면, 총 3개의 Shape가 메모리에 생성 될 것입니다. (empty Shape 제외)
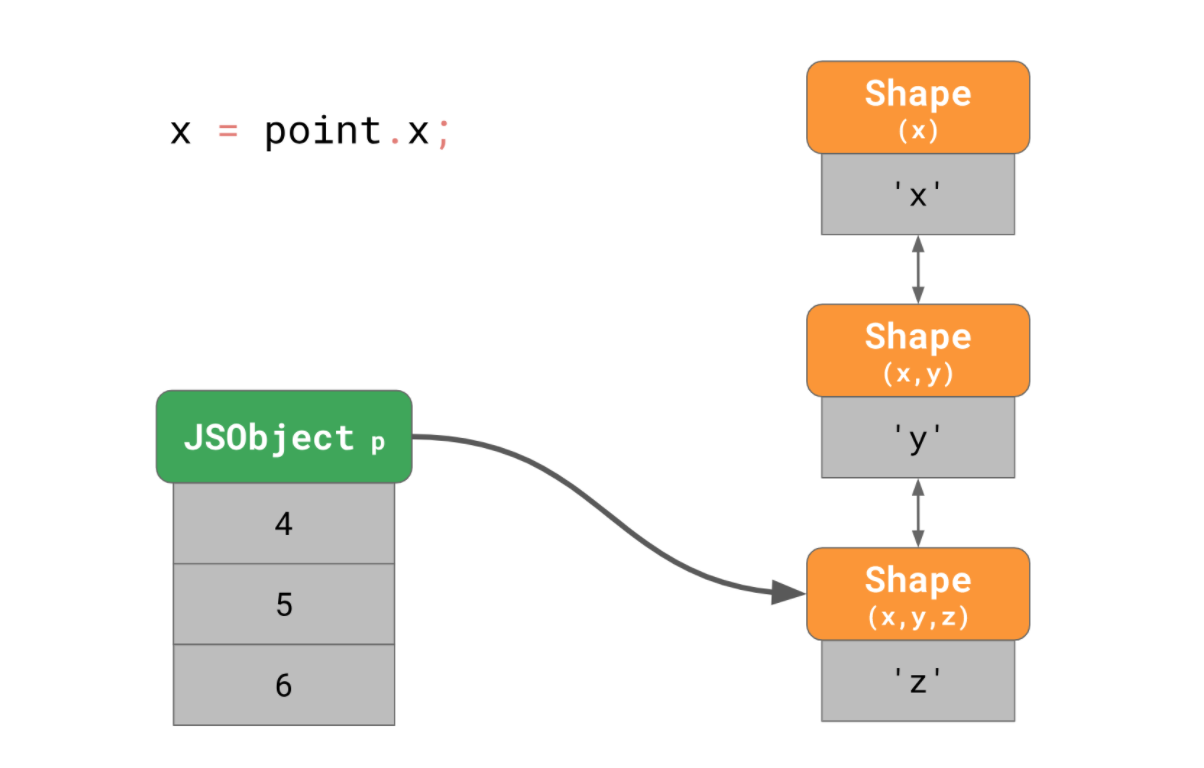
만약 이걸 사용하는 프로그램에서 x 프로퍼티에 접근한다고 하면, JS 엔진은 가장 마지막에 생성된 Shape(x,y,z)부터 링크드 리스트를 따라올라가 맨 위에 있을 x를 찾아야 합니다.
객체의 프로퍼티가 더 많을수록, 그리고 이 과정을 자주 반복한다면 프로그램은 상당히 느려질 것입니다.
그래서 JS 엔진은 탐색 속도를 높이기 위해 내부적으로 ShapeTable 이라는 자료구조를 추가합니다. 이는 딕셔너리 형태로, 각각의 Shape를 가리키는 프로퍼티 키를 저장하고 있습니다.
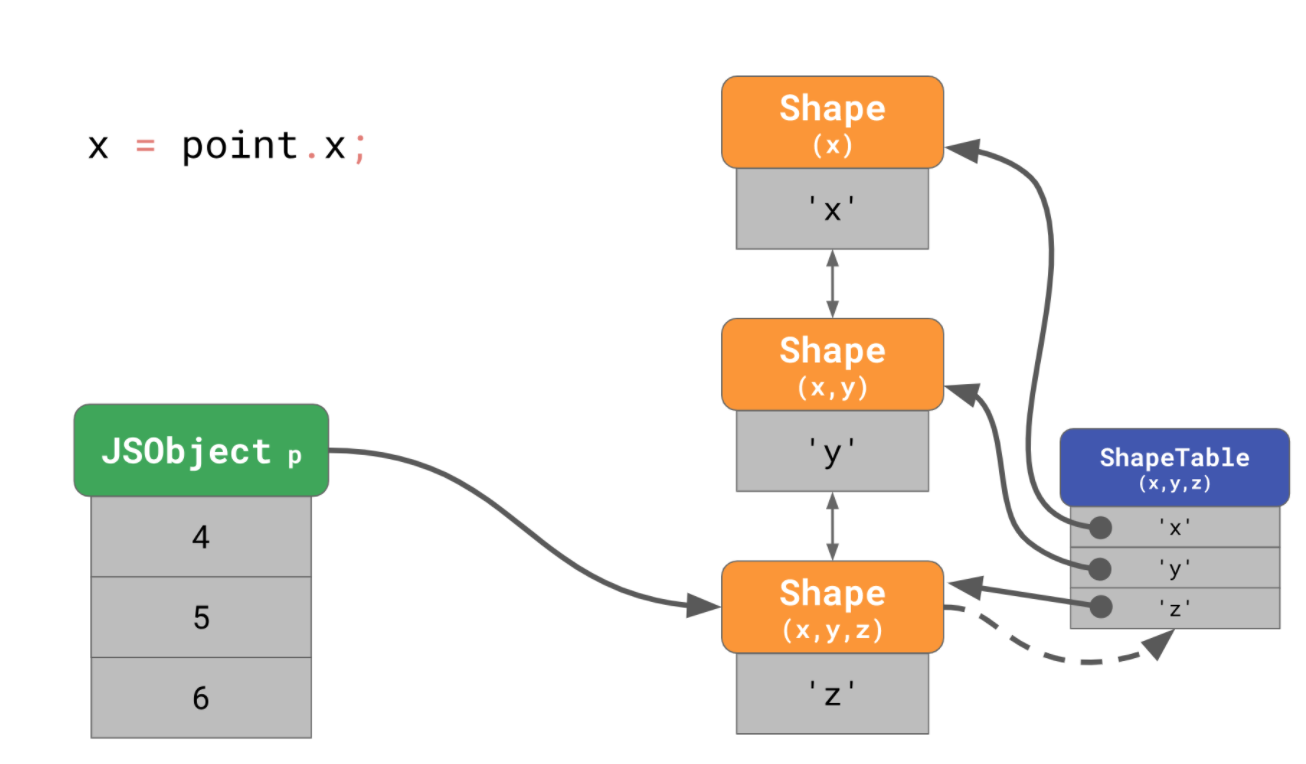
잠깐, 그럼 기껏 Shape가 나온 이유가 없는데요?
사실 엔진은 최적화를 위해 또 다른 방법인 Inline Cache(IC) 라는 것을 Shape에 적용합니다. Inline Cache에 대해서는 다음 포스트에서 알아보겠습니다.


흥미롭네요. 다음편 끊어가기가 드라마급인데요....