1. Introduction
Local forgery detail과 global subtle artifact를 효율적으로 찾아내자
- 기존 augmentation과정을 거쳐서 일반화 성능을 높이는 전략들은 computing cost가 크다는 단점이 있다.
- 이를 해결 하기 위해 LLM모델을 일부 사용해서 일반화 성능을 높인다
- 기존의 LLM 모델은 global feature에 집중하도록 훈련되어 있다. 이를 해결하는 모듈을 설계하자.
- 왜냐하면, 이 global feature에 집중하다보면 특정 method에 overfitting 되는 경향이 강해지기 때문임 - subtle artifact를 지나치는 경향이 있기 때문에
- LPG → GFD 로 모듈이 구성 됨
contribution point
- ViT를 가지고 와서 generalization 성능을 높이려고 함
- LPG : local Region에서 artifact를 참조
- SAM : deepfake detection에서 overfitting을 방지하는 새로운 augmentatin - Blending 비슷한 개념인듯
- GFD : 서로 다른 위조 방식을 섞어 새로운 위조 데이터를 합성 → 일반화 성능을 높이자
- DFG : domain gap을 완화하기 위해 서로 다른 위조 도메인 사이에 있도록 새로운 위조 데이터 생성 → 공통적인 위조의 본질적 특징 학습
- BFG : 기존 위조 domain 의 경계 밖으로 feature를 확장
- LPG와 GFD를 연결하는 방법 → loss function
1. Deepfake Detection
- Video level에서는 spatial, temporal artifact를 찾아야 한다.
- 보통, 시간적 정보와 공간적 정보를 결합하는 방식으로 진행되었지만 이는 새로운 위조 패턴에 적용하기 어렵다는 단점이 있다.
2. Deepfake Detection Using Synthetic Data
- 기존의 blending 방식들은 현실 세계에서 위조 양상을 모델링 하는데 문제가 있다.
- 이를 위해 forgery pattern을 다양하게 하도록 한다.
- forgery pattern 은 distribution base로 설계하여 보다 자연스러운 위조를 만든다.
3. Method
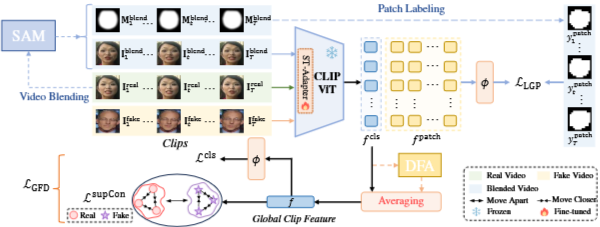
V∈RT×H×W×3 : Video clip
{ftcls,ft,ppatch}=E(V),t=1,…,T,p=1,…,P
ftcls∈RC,ft,ppatch∈RC
- 여기서 주의할 점 : Encoder가 비디오 전체에서 하나의 cls token을 뽑는게 아니라 frame 마다 class token을 뽑는 것임
- 또한 사용된 Encoder는 CLIP-ViT로 peft 기법을 도입하기 위해 ST-Adaper를 도입해야 함
2. Local Patch Guidance (LPG)
- 기존 dataset을 보면 real/fake에 대한 annotation은 되어 있으나 어느 패치에 위조가 가해졌는지는 나와있지 않다.
- 따라서, patch 단위로 정의된 gt가 없으므로 고전적인 supervised learning을 patch단위 학습에 사용할 수 없다.
- patch 단위로 위조를 추가하는 SAM 모듈을 추가해 patch 단위의 gt가 있는 위조 데이터를 새로 만들자!
Generating Patch-level Annotations
- SAM을 이용해서 fake vedio의 위조 영역(mask)를 추정하고 그 결과를 이용해서 P개의 patch 단위 label을 만든다.
- H×W의 frame이 있다면 Hp=PH,Wp=pW
PatchMaskScore(Mt,p)yt,ppatch=h=1∑Hpw=1∑WpI[Mt,p(h,w)>0]={1,0,if PatchMaskScore(Mt,p)≥θ,otherwise.
- 위 수식은 각 patch에 real/fake 값을 할당한다.
- frame t의 patch p안에서 SAM mask가 차지하는 비율을 계산한다.
- 이후 그 비율이 임계값 이상이면 해당 patch 를 fake로 labeling한다.
- 즉, yt,ppatch는 patch-level에서 얻어낸 pseudo GT 이다.
Learning Forgery Features at the Patch Level
- path-level annatation이 끝나면 patch feature ft,ppatch를 binary classifier ϕ에 통과시켜서 Probt,ppatch를 얻는다.
- 아래는 이 Probt,ppatch로 구하는 BCE Loss 이다.
LLGP=−T⋅P1∑t,p[yt,ppatch⋅log(Probt,ppatch)+(1−yt,ppatch)⋅log(1−Probt,ppatch)]
- BCE Loss 쓰면 overfitting이 생긴다는 논문이 있었던 거 같음... 새로운 함수를 고안해 보는 것도 좋을 듯?
- 여기서 Probt,ppatch는 patch feature로 얻어낸 것으로, 해당 patch 가 fake일 확률을 의미한다.
- 위 수식은 각 patch에 대해 loss를 계산해서 해당 patch 의 feature가 위조 신호를 잘 담도록 학습을 유도한다.
- self attention과정을 거치면 model이 patch token들을 참조하게 되면서 local 특징들을 잘 파악하게 된다.
SAM - spatial & temporal blending
1. Spatial artifact generating
- SBI 모듈을 확장한 것 - temporal 위조를 어떤 식으로 구현했나? 가 중요
- 아래와 같이 각 frame의 image를 아래와 같이 분리하고 blened frame을 생성
{It∣t=1,…,T}Itinner,ItouterItblend:vedio clip frame:얼굴을 기준으로 안쪽 프레임, 바깥 프레임=Mtblend⊙Itinner+(1−Mtblend)⊙Itouter
- 위의 수식은 얼굴이나 배경 영역에 SAM mask를 기준으로 위조를 더함 → patch-level pseudo label을 만듦.
2. Temporal Artifact Generating
- 연속된 T frame 동안에 일관된 위조 패턴을 유지하도록 함
- 기본 마스크를 하나 두고, 그 마스트에 대해 shape 을 변화시키거나 blur를 조금씩 일관된 규칙으로 가하면서 temporal artifact를 관찰하게 함
- 이 부분을 코드상으로 어떻게 구현했는지 확인이 필요함.. 논문에는 너무 생략돼서 써 있음
3. Global Forgery Diversification (GFD)
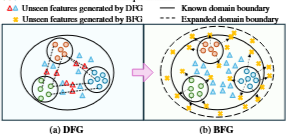
- 여기서 DFG는 이미 분류된 cluster 사이의 세모들을 만드는 과정이고, BFG는 경계 밖으로 밀려난 X 표시들을 포함하도록 바운더리를 넓히는 과정이다.
- ViT 기반의 model은 token간 연산 과정에서 local artifact에 overfitting 되는 경향이 있음.
- 이 부분은 그 bias를 줄이기 위해 고안 된 부분
Domain Feature Augmentation (DFA)
- 분포 특성을 이용하여 forgery pattern을 학습함
- T개의 연속 된 frame중 N개를 샘플링함 - 랜덤하게
μcσc=N⋅T1n=1∑Nt=1∑Tfn,t,ccls=N⋅T1n=1∑Nt=1∑T(fn,t,ccls−μc)2
- 위 수식에서 c는 각 frame에 대한 feature에서 몇 번째 element인지를 나타내는 것이다.
- 각 element 마다 평균과 분산이 계산되면 computing cost가 엄청 크지 않나..?
μcmixσcmix=λμc+(1−λ)μ~c,=λσc+(1−λ)σ~c.
- 여기서 tilde는 fake와 쌍을 이루는 true 영상의 mean과 variance 임
f^n,t,ccls=σcmix⋅(σcfn,t,ccls−μc)+μcmix
- 이것이 최종 cls feature의 각 element 값
- 여기서 말하는 domain bridge는 위조된 이미지 사이의 어딘가에 있는 또 다른 위조 이미지를 만드는 역할을 한다.
Global Clip Feature Representation
fv=T1∑t=1Tfv,tcls
- 각 비디오 클립에 대해 frame 수준의 class embedding을 평균내서 global feature를 계산한다.
Dedicated Training Objective
LGFD=Lcls+υLsupCon
- 학습 중에 모델은 원본 학습 비디오, SAM에서 생성한 비디오, 그리고 DFA에서 합성된 feature를 관찰한다.
- 이런 loss function의 구성이 real/fake를 잘 구분하면서도 새로운 유형의 forgery pattern에도 잘 일반화 된다.
1. Lcls - Cross Entropy Loss
Lcls=B1∑v=1BH(Probv,yv)
- Probv : sample v로부터 예측된 확률 - 이 확률이 나오는 모듈을 코드상으로 확인할 필요
- yv : ground truth label
2. LsupCon - Supervised Contrastive Loss
LsupConL(v,i)=B1v=1∑B−∣J(v)∣1i∈J(v)∑L(v,i)=log∑j∈J(v)∖{v}exp(fv⋅fj/τ)exp(fv⋅fi/τ)
- 여기서 동일한 class 아래 집합을 말하는 J(v)가 같은 real class, fake class 영상 인지 혹은 같은 사람이 찍힌 다른 위조 영상인건지 확인이 필요함
- 또한 최적의 τ 값을 얼마로 설정했는지 확인해 봐야 함
- 위 식은 각 vedio 에서의 평균적인 softmax함수를 모두 합한 것을 말함.
Model Optimization
Loverall=ωLLPG+Lcls+υLsupCon
