스택과 큐는 배열에서 발전된 형태의 자료구조
구조는 비슷하지만 처리 방식이 다름.
스택과 큐의 핵심 이론
스택
삽입과 삭제 연산이 후입선출(LIFO : Last In First Out), FILO (First In Last Out))
Top 부분에서만 연산이 일어남
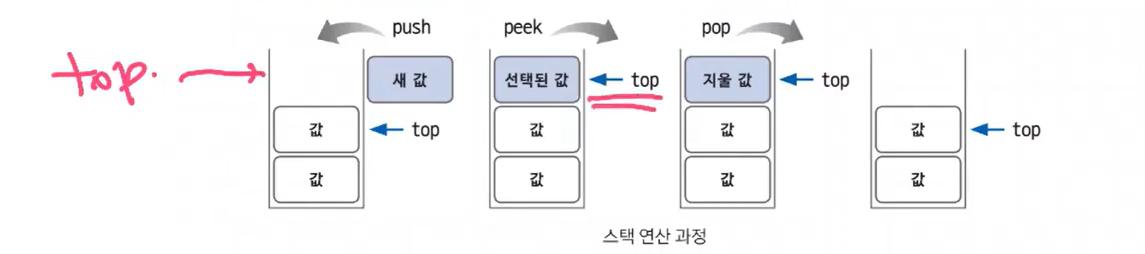
새 값이 스택에 들어가면 top이 새 값을 가리킴
스택에서 값을 빼낼 때 pop은 top이 가리키는 값을 스택에서 뺌
스택 용어
위치
- top : 삽입과 삭제가 일어나는 위치
연산
- push : top 위치에 새로운 데이터를 삽입
- pop : top 위치에 현재 있는 데이터를 삭제하고 확인 (빼낸 다음 확인)
- peek : top 위치에 현재 있는 데이터를 단순 확인
스택은 DFS, 백트래킹 종류에 효과적 → 재귀함수 알고리즘 원리와 일맥상통함.
스택은 응용문제로 나오기도 함.
원리만 잘 알아두기.
+) 추가
스택에서의 시간 복잡도
삽입 : O(1)
삭제 : O(1)
탐색 : O(n)
큐
선입선출(FIFO, First In First out)
삽입 삭제가 양방향.
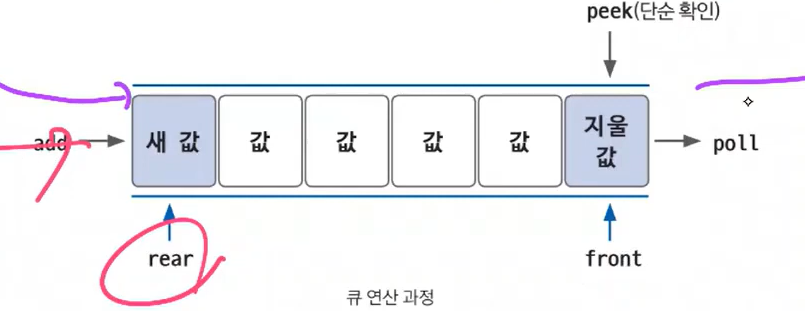
큐 용어
- rear : 큐에서 가장 마지막 끝 데이터를 가리키는 영역
- front : 큐에서 가장 앞의 데이터를 가리키는 영역
- add : rear 부분에 새로운 데이터를 삽입
- poll : front 부분에 있는 데이터를 삭제하고 확인(꺼내서 확인)
- peek : 큐의 맨 앞(front)에 있는 데이터를 확인
큐는 BFS에서 자주 사용
우선순위 큐
- 들어간 순서와 상관 없이 우선순위가 높은 데이터가 먼저 나오는 자료구조
- 큐 설정에 따라 front에 항상 최댓값 또는 최솟값이 위치함
- 일반적으로 힙을 이용해 구현하고, 힙은 트리 종류 중 하나
- 루트 자리에 있는 값이 항상 최댓값 or 최솟값인 건 맞지만 그 아래 노드들이 전부 다 정렬되어 있다고 볼 수는 없음
→ 뒤에 내용에서 더 자세히 나옴
+) 추가
큐에서의 시간 복잡도
삽입 : O(1)
삭제 : O(1)
탐색 : O(n)
스택, 큐 시간 복잡도 출처 : https://im-developer.tistory.com/121

기록하자