유니코드(Unicode)
유니코드는 어떻게 생겨났을까?
옛날옛적, 컴퓨터가 처음 세상에 나왔을 때, 영어와 몇가지 특수문자만 활용이 되었고, 이런 적은 문자를 컴퓨터에 저장하기 위해서 1byte(8bit)면 충분했다.(0~255) - ASCII 문자
시간이 흘러, 다른 국가의 언어들이 활용되었고, 해당 국가의 사람은 자신의 언어를 표시하고 싶어졌다. 그래서 1byte안에 임의대로 영어 대신에 자신의 나라 문자를 할당하여 사용하게 되었다. - 문자열셋의 춘추전국시대...
그러다, 인터넷이 발전되며 다른 나라 사람의 홈페이지를 들어갔더니 글자가 와장창 깨지는 상황이 발생한다. 호환이 되지 않는 것이다. 그리하여, 국제적으로 전세계 모든 언어를 표시할 수 있는 표준코드를 만들기로 하였다.
이것이 바로 유니코드(unicode)이다.
- 유니코드 : 전 세계의 모든 문자를 컴퓨터에서 일관되게 표현하고 다룰 수 있도록 설계된 산업 표준 (글자와 코드가 1:1로 매핑되어있는 표준화된 테이블이라고 생각하면 쉽다)
- 유니코드의 목적 : 현존하는 문자 인코딩 방법들을 모두 유니코드로 교체하고프다(호환합시다!)
- 유니코드 형태 : U+0000~U+007F는 로마자 기본, U+AC00~U+D7AF 한글 음절 등 U+숫자 형태로 이루어져있다. U+10FFFF까지만 이용(10진법으로는 1,114,111)
- 유니코드의 역사 : 1988년 초안이 출판된 이후로, 포함되는 문자가 점점 늘어 가고있다. 자료를 확인해보니 2021년 9월22일 14.0버전이 나왔고, 159개의 언어종류(144,697개의 문자)가 포함되어있다.(열심히 유니코드의 세계화를 이루어나가는중...긍차긍차)
참고로, 한글 ‘가’는 유니코드로 ‘U+AC00’이다. 왜냐고요? 약속입니다.
UTF(Unicode Transformation Format)
유니코드를 통해서 문자를 나타내는 코드는 정의되었다. 즉, 각 문자마다 인덱스가 정해졌다. 그럼 이 코드를 컴퓨터에 어떤 방식으로 저장할 것인가?
❓ 이미 문자를 숫자로 나타낸 유니코드 표가 있는데, 왜 이 숫자를 컴퓨터에 저장할 때 또 변환해야할까?
❗ 자리 수를 얼마나 할당하느냐에 따라 유니코드를 7bit씩 혹은, 1byte씩 차지하도록 할 수도 있다. 그런데 이렇게 하면 표현 가능한 갯수가 한계가 있으므로, 앞에 0을 더채워서 4byte씩 통일해서 할당할 수도 있다. 근데 4byte로 통일하면, 문서의 크기가 커진다... 어떻게 해야 호환도 잘되고, 용량도 적게 만들 수 있을까? 유니코드의 숫자를 컴퓨터에 어떻게 효과적으로 할당해서 0,1로 표현할지 결정하는 인코딩 방식이 필요하다.
UTF-8은 왜 널리 사용되는가?
똑똑한 사람들이 인코딩하는 규칙을 정했는데, 그 중 한가지 방법이 UTF-8 방식이다. (UCS-2,UCS-4,UTF-32,UTF-16,UTF-8 등이 있음)
문자마다 적절한 바이트 수를 차지하도록 해서 다른 방식들보다 일반적으로 적은 용량을 쓰면서도 호환문제가 적은 UTF-8이 전세계적으로 가장 널리 사용된다.
UTF-8은 어떻게 적은 메모리로 다양한 문자를 표현하는가?
유니코드는 거의 세계 모든 언어를 포함하지만, 대부분의 글자는 2Byte(U+0000~U+FFFF)를 사용해야해서, 알파벳 (기존 1byte만을 활용할 수 있었음)을 사용하는 문서에서는 데이터 양이 2배, 많게는 3배가 된다.
따라서 UTF-8에서는 2byte 혹은 3byte였던 유니코드에서 어떤 문자는 1byte로, 어떤 문자는 4byte로... 가변적인 길이로 문자를 인코딩한다.
똑똑한 사람들이라면? 전세계적으로 자주 활용되는 문자들(영어,숫자 등)을 1byte로 만들고, 잘사용되지 않는 특수문자나 고대문자 등은 4byte쪽으로 인코딩 할것같은데, 실제로 맞다.
UTF-8의 핵심 아이디어는, 자주 활용되지 않는 문자에게는 패널티를, 자주 활용되는 문자는 어드벤티지를 준다는 것이다.(메모리로서) 이 방법을 통해 호환성을 높히면서도 적은 용량을 활용할 수 있게 되었다.
참고로, 'a'는 1byte이고, '가'는 3byte이다. 왜냐고요? 약속입니다..
- UTF-8은 8bit(1byte) 단위로 인코딩
- UTF-8은 1byte부터 4byte까지 가변 바이트를 활용하여 유니코드 인코딩
그럼 어떤 문자가 1byte, 어떤문자가 2byte,3byte,4byte일까?
먼저 등록된 (Unicode가 앞선, 세계화 목적인 유니코드에 빨리 등록되었다는 건 전세계에서 공통적으로 자주 활용된다는 의미와 일맥상통할듯) 영어와 숫자같은 문자는 1byte , 시간상 뒤에 등록된 문자는 4byte와 같이 차별적(?) 혹은 가변적으로 할당하는 방법을 택했다.
아래 표에 이미 다 약속되어있다.
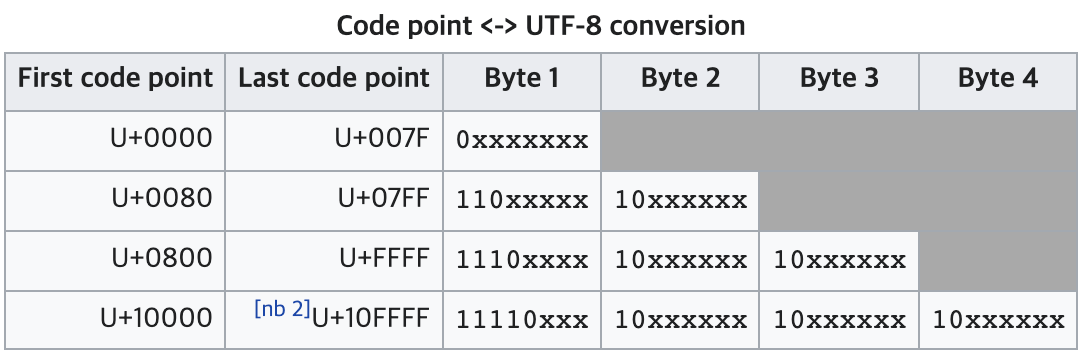 출처 : https://en.wikipedia.org/wiki/UTF-8
출처 : https://en.wikipedia.org/wiki/UTF-8
위와 같이, 유니코드의 범위에 따라 UTF8 인코딩의 바이트 갯수가 정해진다.
그래서 어떻게 인코딩이 되나요?
위의 표를 참고하여, 아래 예시를 보면 UTF8인코딩 방식을 쉽게 이해할 수 있다.
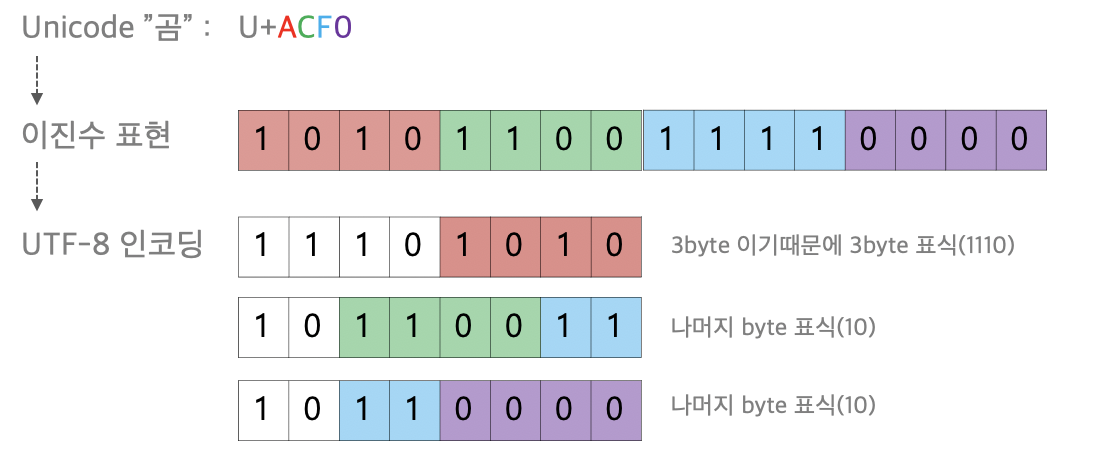
위의 예시를 보면, 곰은 U+ACF0이므로 , 표상 3바이트 범위에 속한다. 3바이트 작성법은 위에 표에도 잘 나와있듯이, 1110xxxx/10xxxxxx/10xxxxxx로 그대로 받아적으면 된다.
이 경우엔, "a"는 U+0061이므로, 1바이트 범위에 속하며, 1바이트의 표시형식을 참고하여 다음과 같이 인코딩 된다.
- 가변길이 구분짓기 위해 첫바이트에 표식 : 1byte는 0으로 시작, 2byte는 110으로 시작하고, 3byte는 1110으로 시작,4byte는 11110으로 시작,나머지 byte는 10으로 시작(왜냐고요? 약속입니다.)
이런 가변 바이트 길이를 선언하기 위해 꽤 많은 비트를 잡아먹고도 2,097,151까지 인코딩할 수 있기 때문에 4바이트만으로도 충분하고도 남는다. 그래서인지 인터넷 사이트에서 가장 많이 쓰이는 인코딩방법이다.
한글은 3바이트 구간에 존재한다. 그래서 한글로 작성된 파일의 경우 파일 크기가 최대 1.5배로 늘어난다. 다만 웹 페이지나 XML 같은 소스코드류의 파일의 경우 한글과 다수의 로마자가 섞여 있기 때문에 EUC-KR로 작성된 파일을 UTF-8로 변환해도 파일 크기가 크게 늘어나지는 않는다. 오히려 UTF-16에서 UTF-8로 변환하면 데이터 크기가 줄어드는데, 한글은 2바이트가 3바이트가 되지만, 로마자는 2바이트가 1바이트로 줄어들기 때문( 통계 )
UTF-16은 다음에....추가로 적어보아야겠다....
내용에 오류가 있다면, 알려주시면 감사합니다.