글로 다룰 생각까지는 없었지만 흥미로운 주제라고 생각하여 실험진행 현황과 결과를 수시로 업데이트 할 예정이다. 작성완료
해당 논제를 다루게 된 배경은 아래와 같다.
식품영약학과 학우가 카톡방에서 mouse와 rat실험 해부를 다르게 구분하는 것이 궁금해서 차이를 물어보았고, rat이 더 큰 쥐라는 것을 알아 컴공스럽게 rat>mouse? 지식++: 지식--;라는 c언어 명령어를 작성해보았다. 그 후 성능을 고려해서 전위표현식으로 바꾸는게 좋겠다는 얘기를 했는데, 컴파일러를 거치면 성능이 똑같다는 얘기가 나왔다.
이후 operator overloading에 관련해서 불필요한 객체가 하나 더 생성된다는 말을 했고
후위연산자가 단독으로 사용될 시 컴파일러에 의하여 최적화된다는 의견을 듣게되었다.
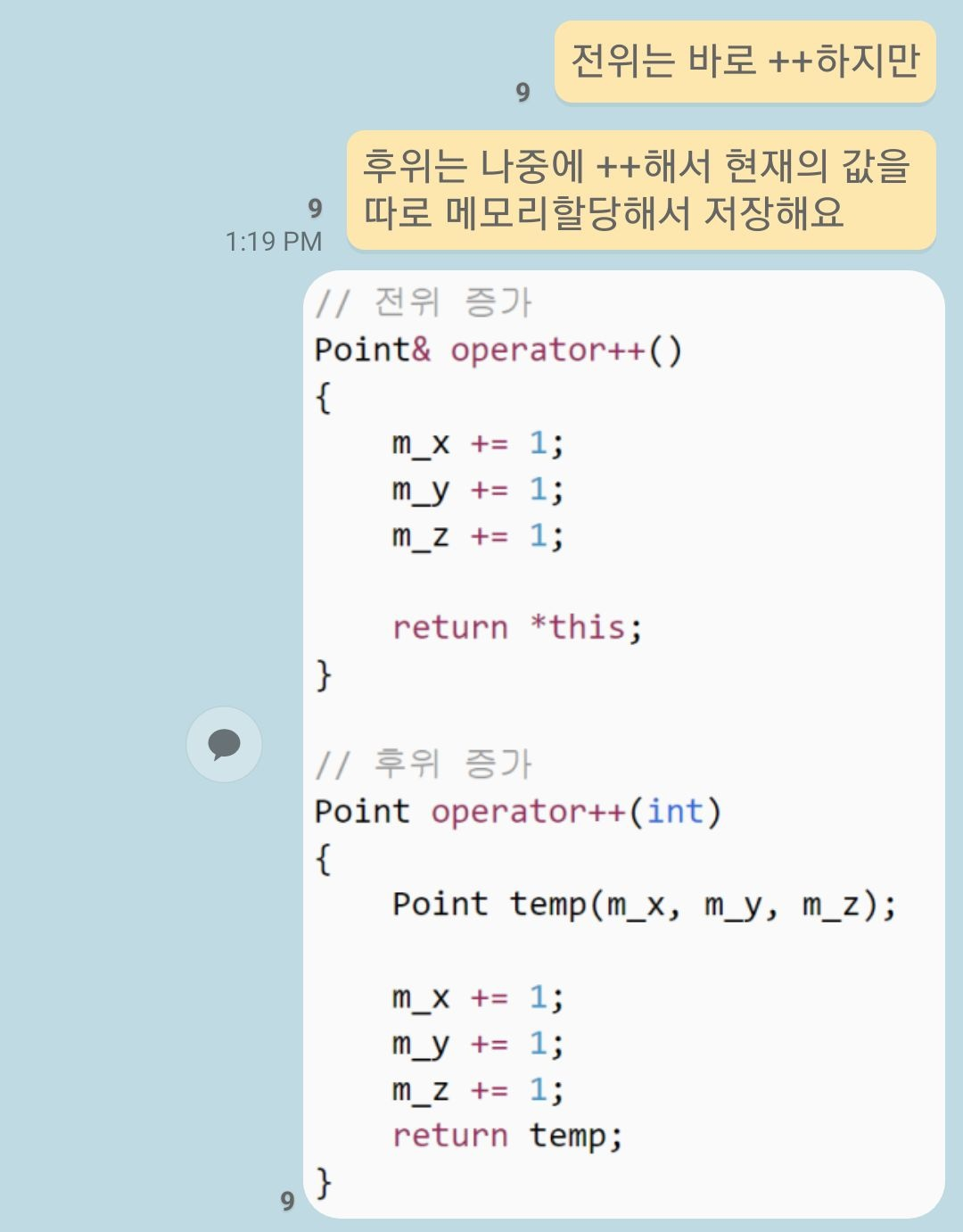
즉, 후위연산은 현재의 값을 저장해야하기에 추가적인 공간이 사용되는 것은 맞지만, 이를 컴파일러가 알아서 최적화하여 단독으로 사용된 경우(전위와 후위가 크게 상관없는 반복문같은) 후위연산자를 전위연산자로 변경해준다는 얘기였다.
실제로 변경이 되는지 궁금하여 Ubuntu 22.04.2 LTS환경에서 아래와 같은 짧은 코드를 작성해보았다.
1. pre.c
#include <stdio.h>
int main() {
int mouse = 1, rat = 2;
int knowledge = 1;
printf("%d", mouse < rat ? ++knowledge : --knowledge);
return 0;
}- post.c
#include <stdio.h>
int main() {
int mouse = 1, rat = 2;
int knowledge = 1;
printf("%d\n", mouse < rat ? knowledge++ : knowledge--);
return 0;
}그 후 목적코드를 확인하기 위해 아래와 같은 코드로 .s파일을 생성하여 두 목적코드를 비교해보았다.
gcc --save-temps pre.c
gcc --save-temps post.c그 결과로 a-post.i a-post.s a-pre.o a.out post.c pre.c a-post.o a-pre.i a-pre.s post pre의 파일들이 생겨났고 어셈블리 코드를 확인할 수 있는 a-pre.s와 a-post.s를 비교해보았다.
3. a-post.c
.file "post.c"
.text
.section .rodata
.LC0:
.string "%d"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
endbr64
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
subq $16, %rsp
movl $1, -12(%rbp)
movl $2, -8(%rbp)
movl $1, -4(%rbp)
movl -12(%rbp), %eax
cmpl -8(%rbp), %eax
jge .L2
movl -4(%rbp), %eax
leal 1(%rax), %edx
movl %edx, -4(%rbp)
jmp .L3
.L2:
movl -4(%rbp), %eax
leal -1(%rax), %edx
movl %edx, -4(%rbp)
.L3:
movl %eax, %esi
leaq .LC0(%rip), %rax
movq %rax, %rdi
movl $0, %eax
call printf@PLT
movl $0, %eax
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0"
.section .note.GNU-stack,"",@progbits
.section .note.gnu.property,"a"
.align 8
.long 1f - 0f
.long 4f - 1f
.long 5
0:
.string "GNU"
1:
.align 8
.long 0xc0000002
.long 3f - 2f
2:
.long 0x3
3:
.align 8
4:- a-pre.s
.file "pre.c"
.text
.section .rodata
.LC0:
.string "%d"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
endbr64
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
subq $16, %rsp
movl $1, -12(%rbp)
movl $2, -8(%rbp)
movl $1, -4(%rbp)
movl -12(%rbp), %eax
cmpl -8(%rbp), %eax
jge .L2
addl $1, -4(%rbp)
movl -4(%rbp), %eax
jmp .L3
.L2:
subl $1, -4(%rbp)
movl -4(%rbp), %eax
.L3:
movl %eax, %esi
leaq .LC0(%rip), %rax
movq %rax, %rdi
movl $0, %eax
call printf@PLT
movl $0, %eax
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0"
.section .note.GNU-stack,"",@progbits
.section .note.gnu.property,"a"
.align 8
.long 1f - 0f
.long 4f - 1f
.long 5
0:
.string "GNU"
1:
.align 8
.long 0xc0000002
.long 3f - 2f
2:
.long 0x3
3:
.align 8
4:둘의 어셈블리 코드 차이는 아래의 표시한 부분과 같다.
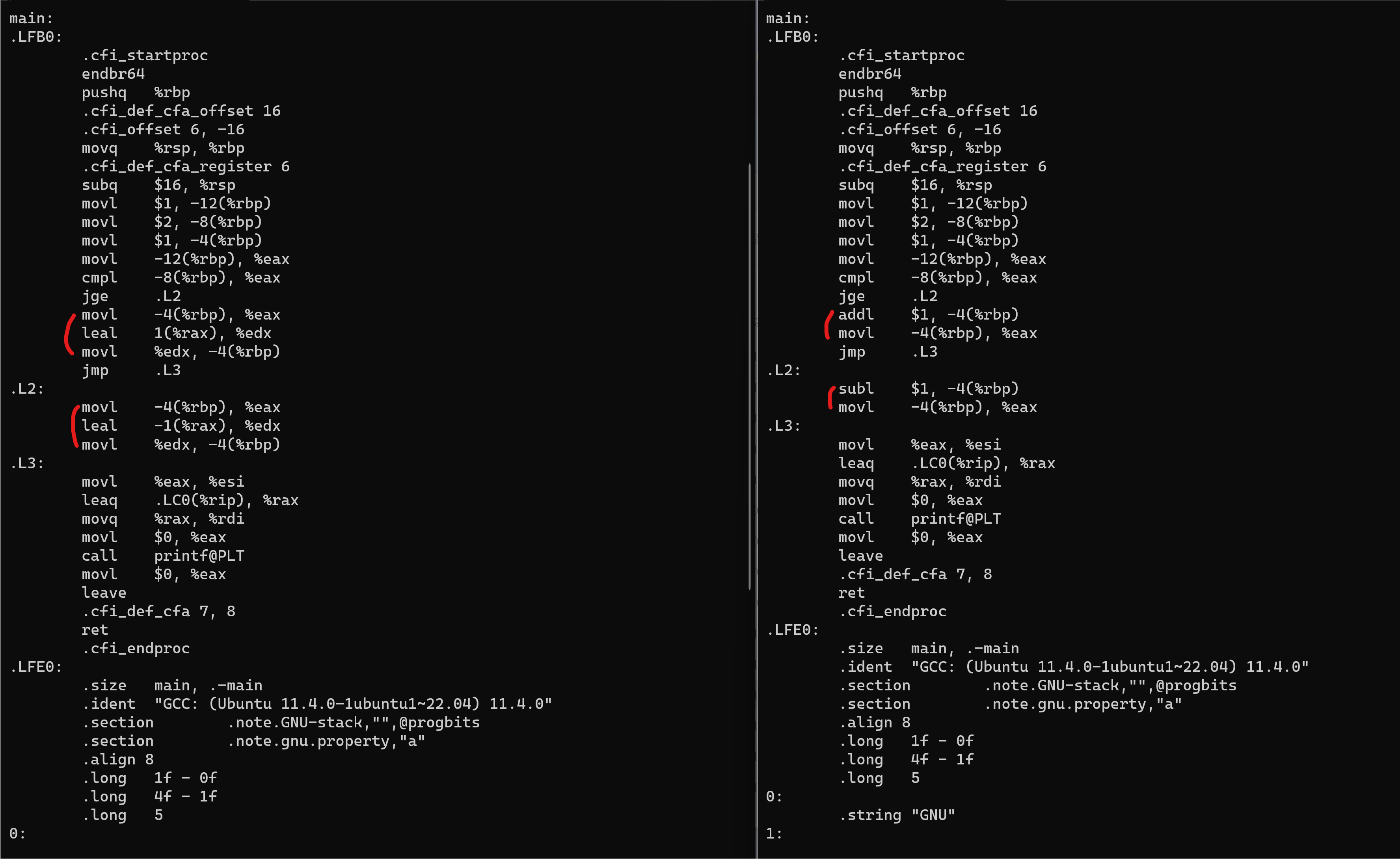
위의 짧은 논쟁의 결론으로 후위 연산자가 단독으로 사용될 때 컴파일러가 최적화를 진행하여 후위연산자가 전위연산자로 바뀐다 라는 결론을 내렸는데, 정말 단순한 코드임에도 불구하고 코드의 다른 부분을 발견하였다.
해당 부분에 대해 다른 의견을 들어보고자 학교 동기들 톡방에 물어보았다. 그 결과 컴파일러의 최적화 레벨에 따라 다를 것 같다고 적절한 최적화 레벨을 찾아보라는 조언을 얻었다.
조언내용대로 컴파일러 최적화 레벨별로 어셈블리 코드의 변화를 실험해보고, 더불어 실행속도도 유의미한 수치가 나올지는 모르겠지만(너무 빨리 끝나서..) 같이 측정해보기로 했다. 해당 결과를 추후 추가할 예정이다.
또한 처음 컴파일러 단에서 최적화된다는 의견을 준 분과 대화내용을 토대로 추가적으로 생각해보면, 우선 프로그램 실행과정을 보면 컴파일러가 목적코드로 컴파일 할 떄, 해당 목적코드를 실행할 때로 나뉜다. 목적코드는 기계어로 1대1대응을 시켜주는 것이 전부라 컴파일러 단에서의 최적화만 고려하면 될 듯하다. 그런데 해당 전위와 후위식을 컴파일러 단에서 어떻게 최적화가 되는지에 대한 지식이 부족하기에 오토마타와 컴파일러관련 강의를 들어보라는 조언을 들었다. 최적화시 인라인함수로 바꾸는지도 궁금. 컴파일러 공부하면서 어떤 경우에 인라인함수로 변경하는지도 알아보면 좋을 듯 하다
앞으로의 실험계획은 다음과 같다.
gcc 최적화 레벨 별 어셈블리 코드 및 속도비교
gcc버전별 분석
어셈블리 코드분석(왜 inc가 없는가->-1과 1을 공통적으로 add하려는것인가?)
오토마타와 컴파일러에서 컴파일러 최적화 관련 공부, 그 후 계획수립
(2023.11.16 추가)
gcc 최적화 레벨 별 목적코드를 비교해볼 예정이다.
root@jimo:~/operation# gcc --version
gcc (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0
Copyright (C) 2021 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.비교해볼 gcc의 최적화 옵션은 아래와 같다.
1. -O0 최적화를 진행하지 않는다
2. -O1 코드 크기와 실행시간 감소
3. -O2 메모리 공간과 속도 희생 없이 최적화
4. -O3 인라인 함수와 레지스터 최적화 추가진행
5. -Ofast 다음의 옵션들과 같다. -O3 -ffast-math -no-protect-arens -fstatck-arrays
코드비교
1.
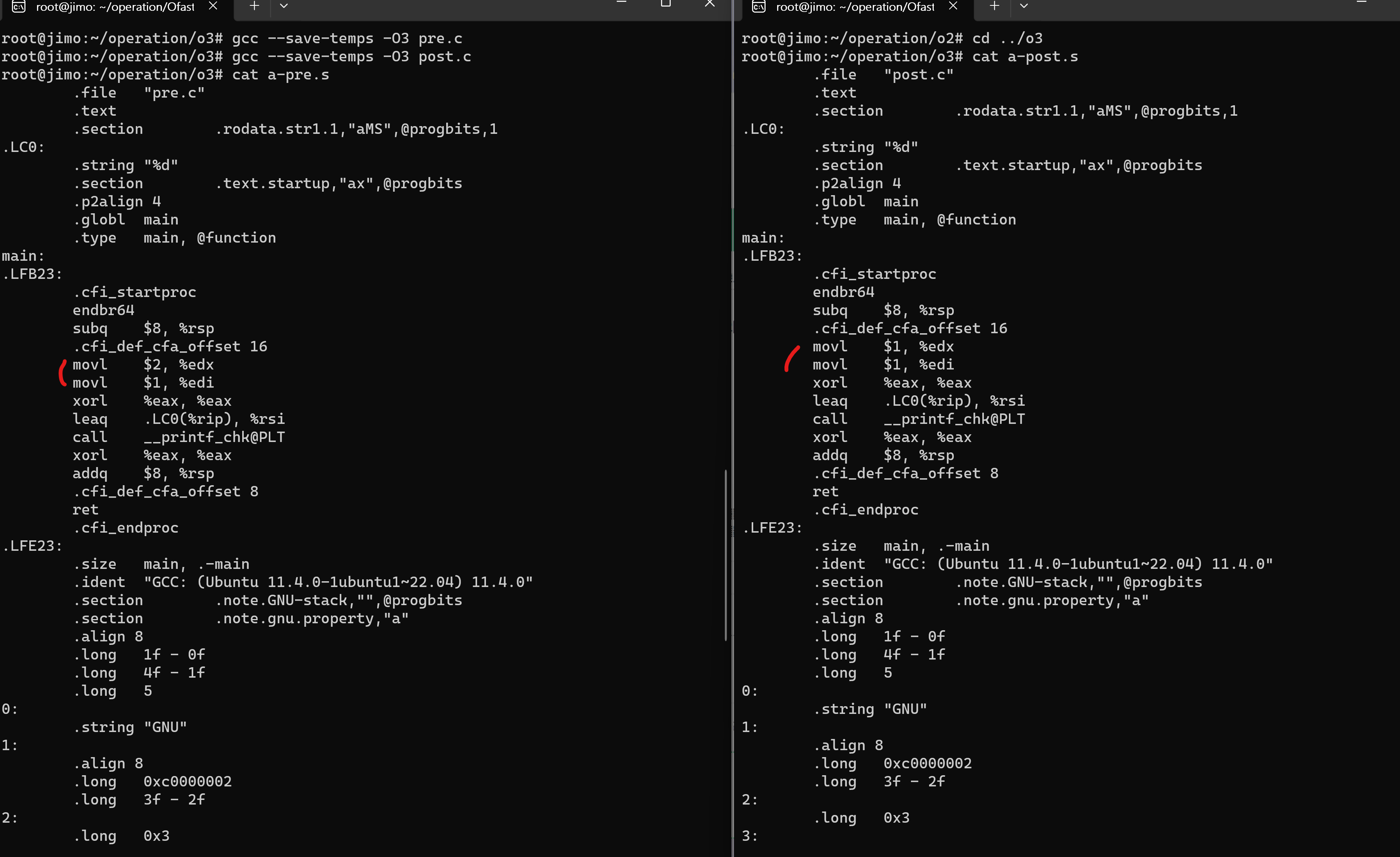
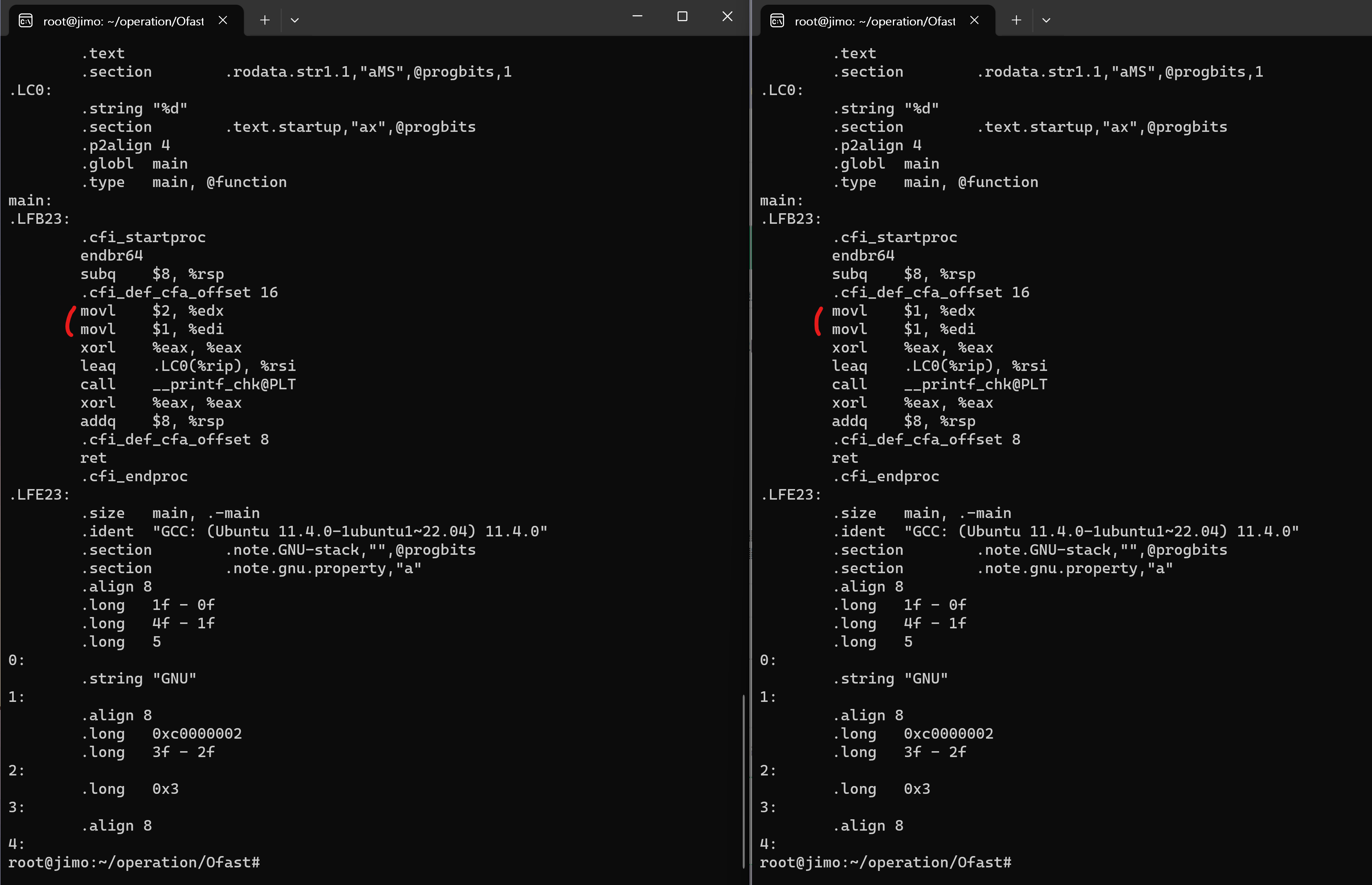
결과: gcc 최적화 버전 -O0, -O1, -O2, -O3, -Ofast모두 전위 연산자와 후위 연산자의 목적코드 차이점이 발견되었다. -O2, -O3, -Ofast는 같은 목적코드를 생성하였다.
분석:
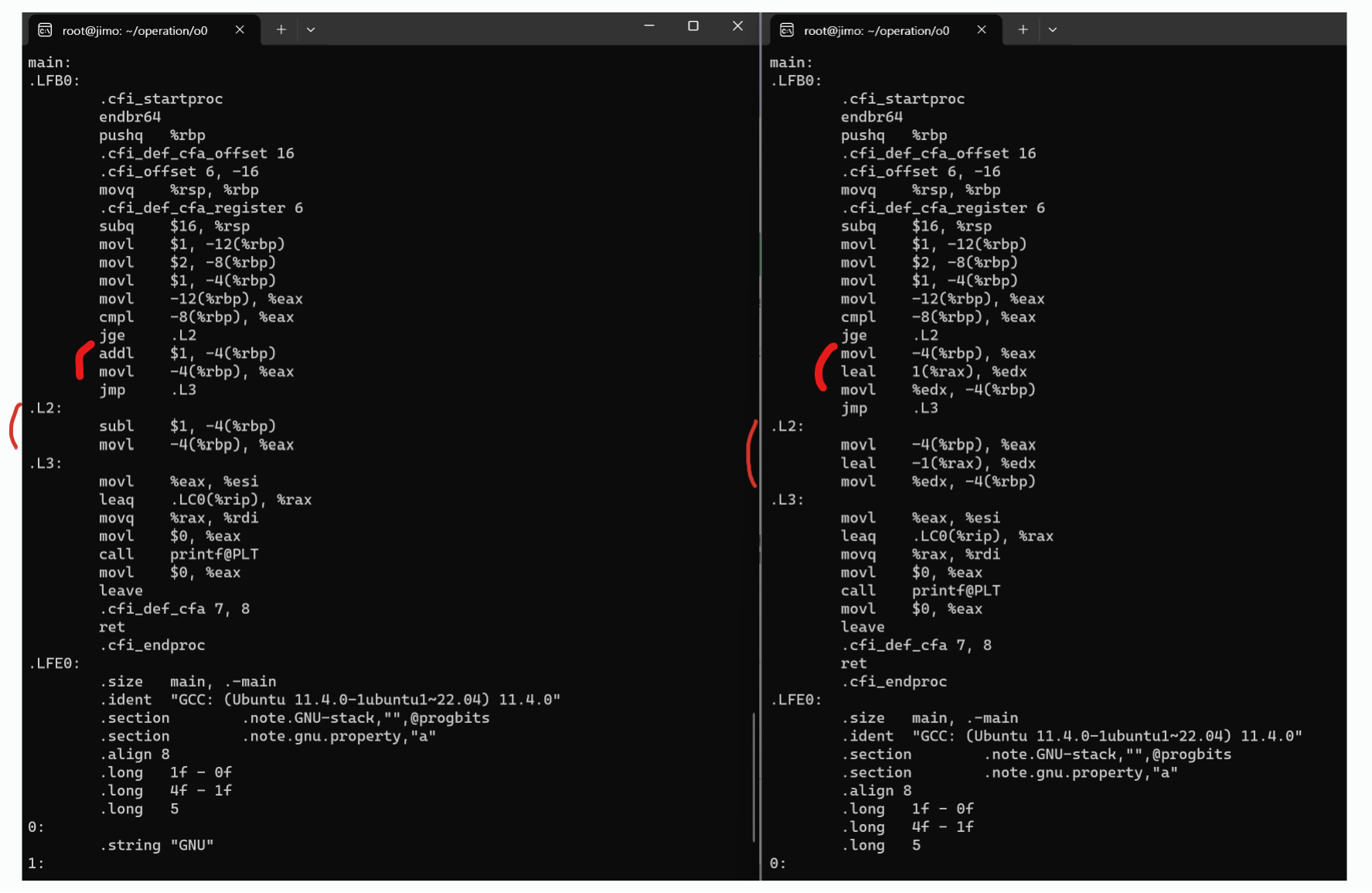
1. -O0
기본 코드에서 값의 비교가 참인 경우 ++를, 거짓인 경우 --를 수행하게 하였기에
cmpl -8(%rbp), %eax
jge .L2에서 비교 부분을 처리한 것을 알 수 있다. .L2로 빠지지 않은 아래의 가산부분을 보면 post.s에서 pre.s에서와 달리 추가적으로 edx를 사용하여 값을 처리함을 볼 수 있다.
pre.s의 .L2:
subl $1, -4(%rbp)
movl -4(%rbp), %eaxpost.s의 .L2:
movl -4(%rbp), %eax
leal -1(%rax), %edx
movl %edx, -4(%rbp)2. -O1
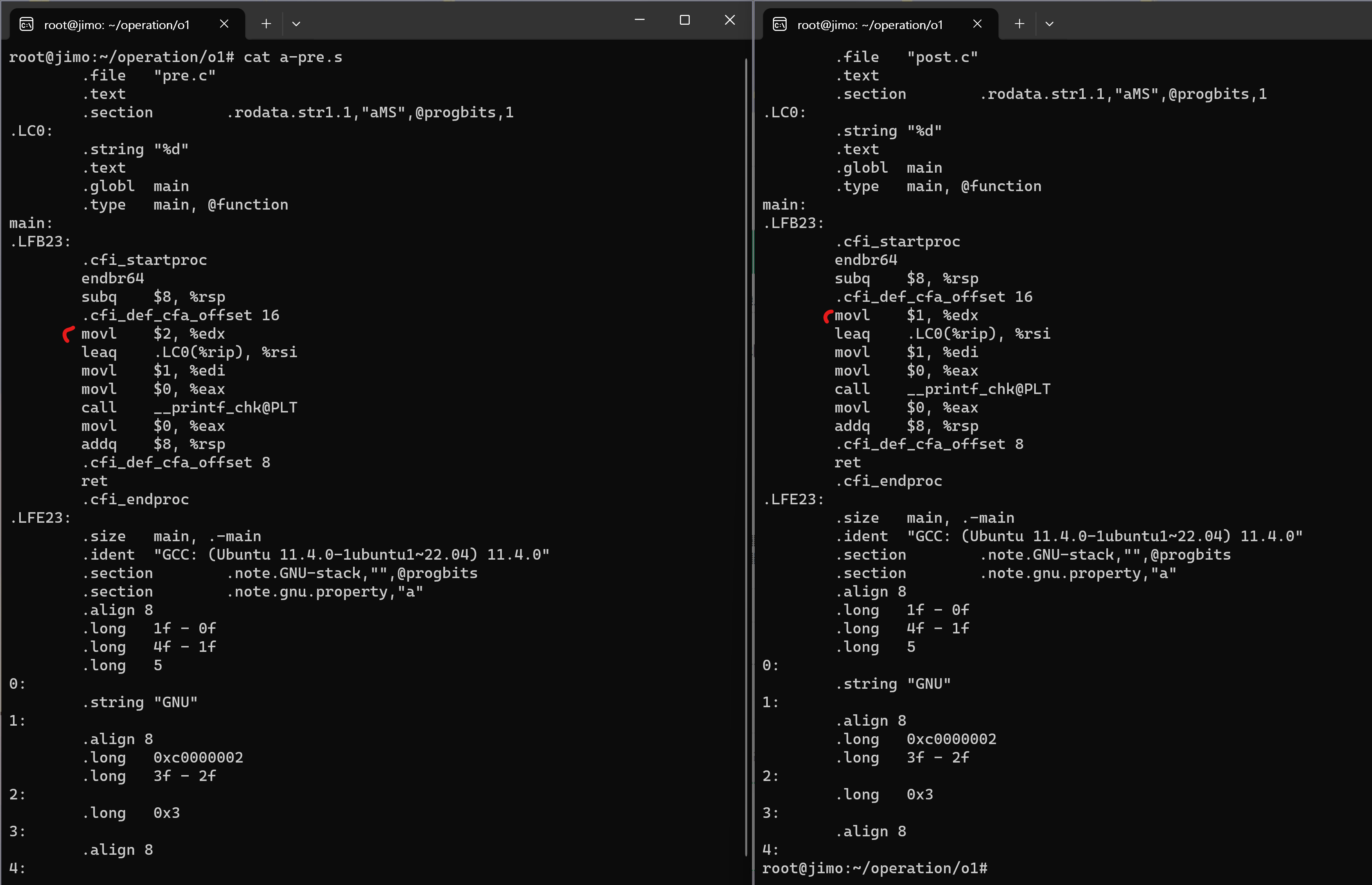
차이점은 pre.s는
movl $2, %edx; 2값을
leaq .LC0(%rip), %rsipost.s는
movl $1, %edx; 1값을
leaq .LC0(%rip), %rsiprintf 호출 시 인자값으로 전달해주는 것을 볼 수 있다. 즉, 실제로 ++이 이루어지는 과정은 생략되어 계산된 값만 코드에 들어가있다.
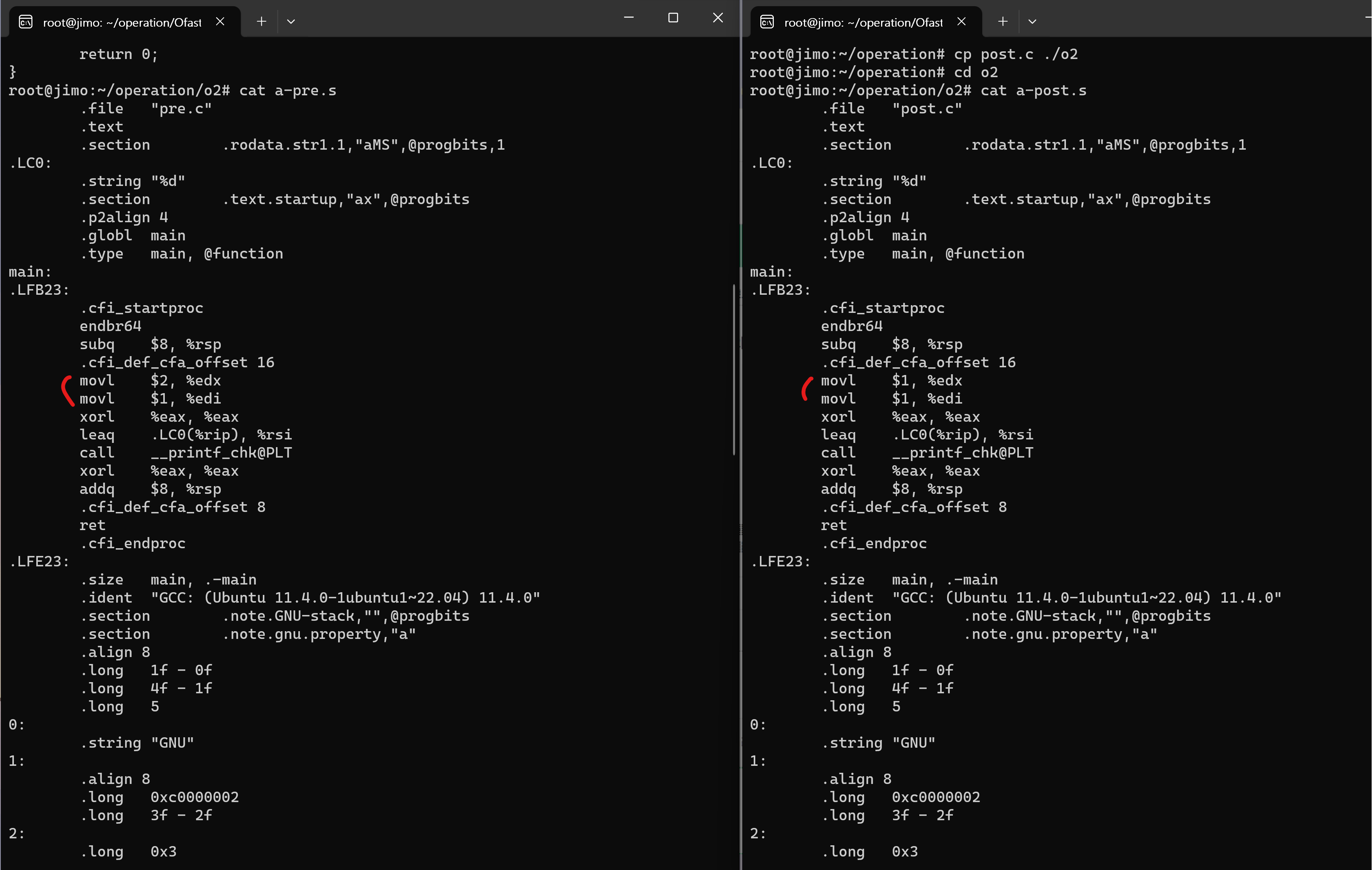
3. -O2, -O3, -Ofast
-O1과 포맷만 다를 뿐 같은 차이점을 가지고 있다.
pre.s는
movl $2, %edx
movl $1, %edipost.s는
movl $1, %edx
movl $1, %edi를 수행한다. 마찬가지로 ++이 이루어지는 과정은 생략되어 계산된 값만 코드에 들어가있다.
즉, gcc 기본 최적화 레벨 0보다 높은 1이상인 코드에서 전위 후위와 구분없이 이미 계산된 값이 목적코드에 들어가있었다.
결론:
gcc 컴파일러의 기본 최적화 레벨에서 전위 연산자와 후위 연산자의 차이가 있었고, 최적화 레벨을 높인 -O1이상의 레벨에서는 차이가 없었다. 실험을 시작하게 된 배경이었던 가정인 "후위 연산자가 단독으로 사용될 때 컴파일러가 최적화를 진행하여 후위연산자가 전위연산자로 바뀐다"는 gcc 11.4.0 컴파일 시 일반적인 상황(최적화 레벨을 별도로 설정하지 않은 상황)에서 옳지 않다.
결론을 보완하면 "후위 연산자와 전위 연산자는 기본 컴파일 시 차이가 있고, 컴파일 레벨 -O1이상에서는 계산된 값이 목적코드에 삽입되어 차이가 없다."
하지만 이렇게 결론내면 찝찝하기에 다른 컴파일러들에서는 어떤 최적화 레벨을 기본적으로 사용하고있는지도 추가 조사해보았다.
1_ Visual Studio
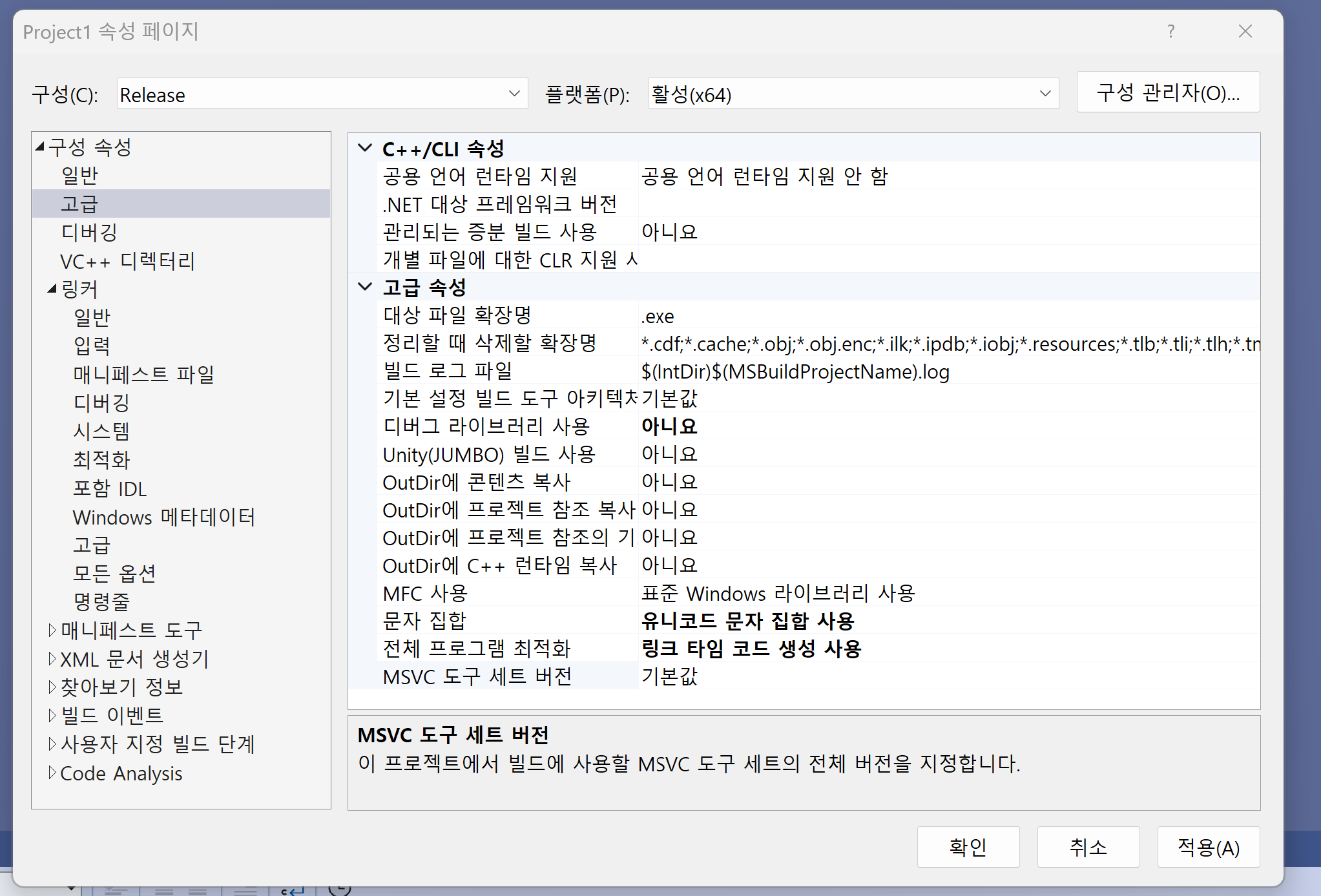
전체 프로그램 최적화 기본 옵션으로 링크 타임 코드 생성을 사용한다. 링커의 최적화 부분을 보자.
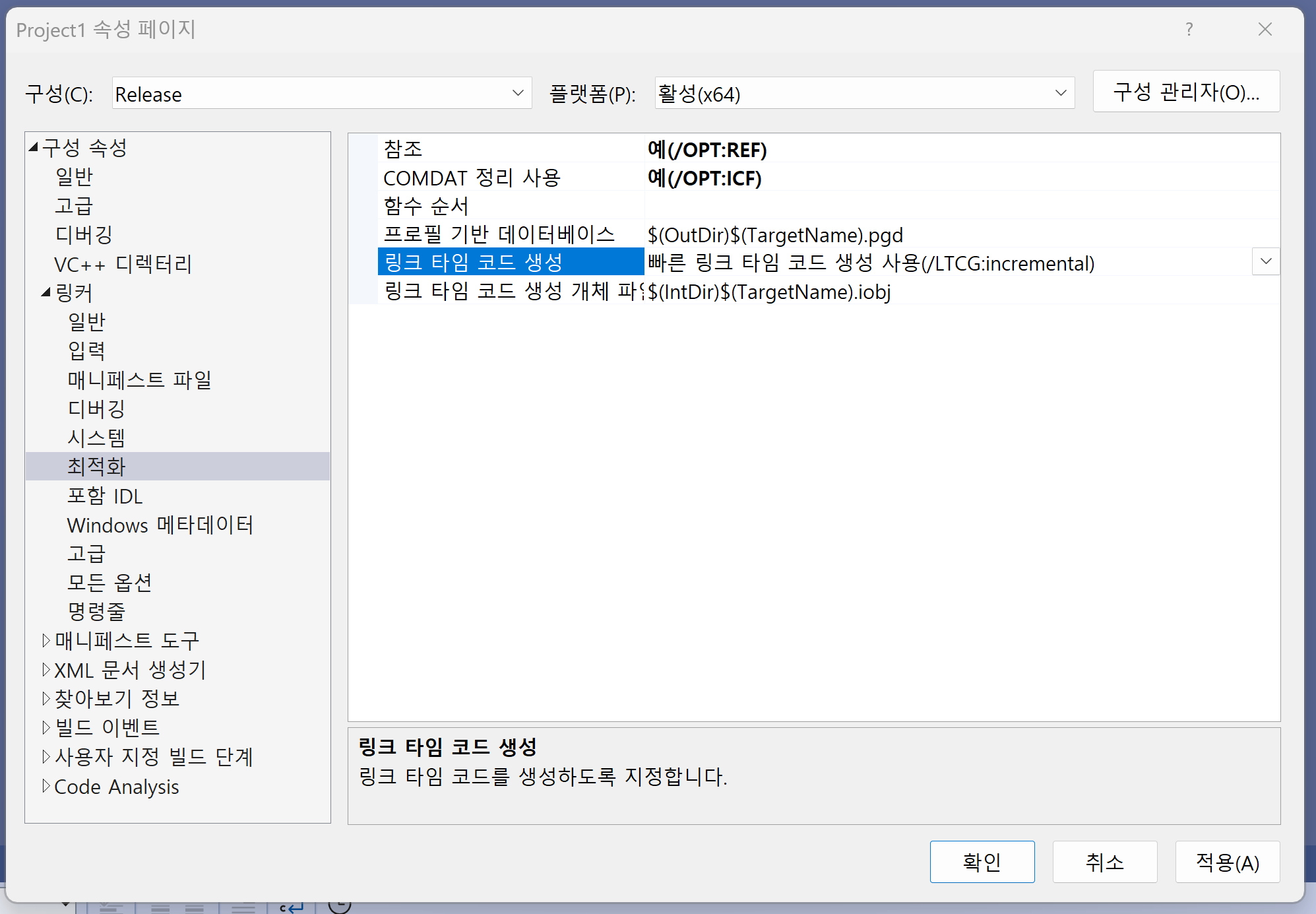
위 사진의 /LTCG:incremental옵션은 링킹시간, 빌드시간, 디스크 사용률을 개선하는 링커 최적화 옵션이다. 최적화 레벨을 사용하기위해서는 -Ox꼴의 옵션을 추가로 설정해줄 수 있다. 그리고 디버깅 모드에서의 최적화 옵션은 최적화를 수행하지 않는 -O0이 기본으로 세팅되어있다.
즉, VS에서의 기본 최적화는 링커 최적화만 수행한다.
VS의 디버깅->창->디스어셈블러를 이용해 기본 설정으로 asm코드를 보았다.
1-1. 전위 연산자
printf("%d\n", mouse < rat ? ++knowledge : --knowledge);
00007FF7DCBB1890 mov eax,dword ptr [rat]
00007FF7DCBB1893 cmp dword ptr [mouse],eax
00007FF7DCBB1896 jge main+4Bh (07FF7DCBB18ABh)
00007FF7DCBB1898 mov eax,dword ptr [knowledge]
00007FF7DCBB189B inc eax 1-2. 후위 연산자
printf("%d\n", mouse < rat ? knowledge++ : knowledge--);
00007FF6A2D51890 mov eax,dword ptr [rat]
00007FF6A2D51893 cmp dword ptr [mouse],eax
00007FF6A2D51896 jge main+4Bh (07FF6A2D518ABh)
00007FF6A2D51898 mov eax,dword ptr [knowledge]
00007FF6A2D5189B mov dword ptr [rbp+114h],eax
00007FF6A2D518A1 mov eax,dword ptr [knowledge]
00007FF6A2D518A4 inc eax Visual Studio에서 실제 컴파일러 기본 최적화 옵션대로, 링킹 최적화 외에 코드 최적화는 진행되지 않는다. 후위의 경우 값을 담기 위해 ptr [rbp+114h]를 추가적으로 사용한 것을 확인할 수 있다.
2_ Dev C++
컴파일러 옵션으로 -Ox를 수동으로 설정해야만 최적화가 진행된다.
https://sourceforge.net/p/dev-cpp/discussion/48211/thread/cf82e542/
참고:
이전에 계획했던 gcc 버전별 분석과 전위&후위 속도측정은 하지 않았다. -O0~--03은 gcc 모든 버전에서 지원하는 기능이고, -Ofast만 gcc 4.7++에서 지원하는 옵션이기에 버전별 차이는 없다고 보았다. 속도 측정은 전위와 후위의 속도 차이가 현재의 간단한 프로그램 코드에서는 유의미한 값이 나오지 않는다고 보았다. 즉, 실험은 추가로 진행하지 않고 종결한다.
목적 코드들
1-1. O0/pre.s
root@jimo:~/operation/o0# gcc --save-temps -O0 pre.c
root@jimo:~/operation/o0# cat a-pre.s
.file "pre.c"
.text
.section .rodata
.LC0:
.string "%d"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
endbr64
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
subq $16, %rsp
movl $1, -12(%rbp)
movl $2, -8(%rbp)
movl $1, -4(%rbp)
movl -12(%rbp), %eax
cmpl -8(%rbp), %eax
jge .L2
addl $1, -4(%rbp)
movl -4(%rbp), %eax
jmp .L3
.L2:
subl $1, -4(%rbp)
movl -4(%rbp), %eax
.L3:
movl %eax, %esi
leaq .LC0(%rip), %rax
movq %rax, %rdi
movl $0, %eax
call printf@PLT
movl $0, %eax
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0"
.section .note.GNU-stack,"",@progbits
.section .note.gnu.property,"a"
.align 8
.long 1f - 0f
.long 4f - 1f
.long 5
0:
.string "GNU"
1:
.align 8
.long 0xc0000002
.long 3f - 2f
2:
.long 0x3
3:
.align 8
4:1-2. O0/post.s
root@jimo:~/operation/o0# gcc --save-temps -O0 post.c
root@jimo:~/operation/o0# cat a-post.s
.file "post.c"
.text
.section .rodata
.LC0:
.string "%d"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
endbr64
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
subq $16, %rsp
movl $1, -12(%rbp)
movl $2, -8(%rbp)
movl $1, -4(%rbp)
movl -12(%rbp), %eax
cmpl -8(%rbp), %eax
jge .L2
movl -4(%rbp), %eax
leal 1(%rax), %edx
movl %edx, -4(%rbp)
jmp .L3
.L2:
movl -4(%rbp), %eax
leal -1(%rax), %edx
movl %edx, -4(%rbp)
.L3:
movl %eax, %esi
leaq .LC0(%rip), %rax
movq %rax, %rdi
movl $0, %eax
call printf@PLT
movl $0, %eax
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0"
.section .note.GNU-stack,"",@progbits
.section .note.gnu.property,"a"
.align 8
.long 1f - 0f
.long 4f - 1f
.long 5
0:
.string "GNU"
1:
.align 8
.long 0xc0000002
.long 3f - 2f
2:
.long 0x3
3:
.align 8
4:2-1. O1/pre.s
root@jimo:~/operation/o1# gcc --save-temps -O1 pre.c
root@jimo:~/operation/o1# cat a-pre.s
.file "pre.c"
.text
.section .rodata.str1.1,"aMS",@progbits,1
.LC0:
.string "%d"
.text
.globl main
.type main, @function
main:
.LFB23:
.cfi_startproc
endbr64
subq $8, %rsp
.cfi_def_cfa_offset 16
movl $2, %edx
leaq .LC0(%rip), %rsi
movl $1, %edi
movl $0, %eax
call __printf_chk@PLT
movl $0, %eax
addq $8, %rsp
.cfi_def_cfa_offset 8
ret
.cfi_endproc
.LFE23:
.size main, .-main
.ident "GCC: (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0"
.section .note.GNU-stack,"",@progbits
.section .note.gnu.property,"a"
.align 8
.long 1f - 0f
.long 4f - 1f
.long 5
0:
.string "GNU"
1:
.align 8
.long 0xc0000002
.long 3f - 2f
2:
.long 0x3
3:
.align 8
4:2-2. O1/post.s
root@jimo:~/operation/o1# gcc --save-temps -O1 post.c
root@jimo:~/operation/o1# cat a-post.s
.file "post.c"
.text
.section .rodata.str1.1,"aMS",@progbits,1
.LC0:
.string "%d"
.text
.globl main
.type main, @function
main:
.LFB23:
.cfi_startproc
endbr64
subq $8, %rsp
.cfi_def_cfa_offset 16
movl $1, %edx
leaq .LC0(%rip), %rsi
movl $1, %edi
movl $0, %eax
call __printf_chk@PLT
movl $0, %eax
addq $8, %rsp
.cfi_def_cfa_offset 8
ret
.cfi_endproc
.LFE23:
.size main, .-main
.ident "GCC: (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0"
.section .note.GNU-stack,"",@progbits
.section .note.gnu.property,"a"
.align 8
.long 1f - 0f
.long 4f - 1f
.long 5
0:
.string "GNU"
1:
.align 8
.long 0xc0000002
.long 3f - 2f
2:
.long 0x3
3:
.align 8
4:3-1. O2/pre.s
root@jimo:~/operation/o2# gcc --save-temps -O2 pre.c
root@jimo:~/operation/o2# cat a-pre.s
.file "pre.c"
.text
.section .rodata.str1.1,"aMS",@progbits,1
.LC0:
.string "%d"
.section .text.startup,"ax",@progbits
.p2align 4
.globl main
.type main, @function
main:
.LFB23:
.cfi_startproc
endbr64
subq $8, %rsp
.cfi_def_cfa_offset 16
movl $2, %edx
movl $1, %edi
xorl %eax, %eax
leaq .LC0(%rip), %rsi
call __printf_chk@PLT
xorl %eax, %eax
addq $8, %rsp
.cfi_def_cfa_offset 8
ret
.cfi_endproc
.LFE23:
.size main, .-main
.ident "GCC: (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0"
.section .note.GNU-stack,"",@progbits
.section .note.gnu.property,"a"
.align 8
.long 1f - 0f
.long 4f - 1f
.long 5
0:
.string "GNU"
1:
.align 8
.long 0xc0000002
.long 3f - 2f
2:
.long 0x3
3:
.align 8
4:3-2. 02/post.s
root@jimo:~/operation/o2# gcc --save-temps -O2 post.c
root@jimo:~/operation/o2# cat a-post.s
.file "post.c"
.text
.section .rodata.str1.1,"aMS",@progbits,1
.LC0:
.string "%d"
.section .text.startup,"ax",@progbits
.p2align 4
.globl main
.type main, @function
main:
.LFB23:
.cfi_startproc
endbr64
subq $8, %rsp
.cfi_def_cfa_offset 16
movl $1, %edx
movl $1, %edi
xorl %eax, %eax
leaq .LC0(%rip), %rsi
call __printf_chk@PLT
xorl %eax, %eax
addq $8, %rsp
.cfi_def_cfa_offset 8
ret
.cfi_endproc
.LFE23:
.size main, .-main
.ident "GCC: (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0"
.section .note.GNU-stack,"",@progbits
.section .note.gnu.property,"a"
.align 8
.long 1f - 0f
.long 4f - 1f
.long 5
0:
.string "GNU"
1:
.align 8
.long 0xc0000002
.long 3f - 2f
2:
.long 0x3
3:
.align 8
4:4-1. O3/pre.s
root@jimo:~/operation/o3# gcc --save-temps -O3 pre.c
root@jimo:~/operation/o3# cat a-pre.s
.file "pre.c"
.text
.section .rodata.str1.1,"aMS",@progbits,1
.LC0:
.string "%d"
.section .text.startup,"ax",@progbits
.p2align 4
.globl main
.type main, @function
main:
.LFB23:
.cfi_startproc
endbr64
subq $8, %rsp
.cfi_def_cfa_offset 16
movl $2, %edx
movl $1, %edi
xorl %eax, %eax
leaq .LC0(%rip), %rsi
call __printf_chk@PLT
xorl %eax, %eax
addq $8, %rsp
.cfi_def_cfa_offset 8
ret
.cfi_endproc
.LFE23:
.size main, .-main
.ident "GCC: (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0"
.section .note.GNU-stack,"",@progbits
.section .note.gnu.property,"a"
.align 8
.long 1f - 0f
.long 4f - 1f
.long 5
0:
.string "GNU"
1:
.align 8
.long 0xc0000002
.long 3f - 2f
2:
.long 0x3
3:
.align 8
4:4-2. O3/post.s
root@jimo:~/operation/o3# gcc --save-temps -O3 post.c
root@jimo:~/operation/o3# cat a-post.s
.file "post.c"
.text
.section .rodata.str1.1,"aMS",@progbits,1
.LC0:
.string "%d"
.section .text.startup,"ax",@progbits
.p2align 4
.globl main
.type main, @function
main:
.LFB23:
.cfi_startproc
endbr64
subq $8, %rsp
.cfi_def_cfa_offset 16
movl $1, %edx
movl $1, %edi
xorl %eax, %eax
leaq .LC0(%rip), %rsi
call __printf_chk@PLT
xorl %eax, %eax
addq $8, %rsp
.cfi_def_cfa_offset 8
ret
.cfi_endproc
.LFE23:
.size main, .-main
.ident "GCC: (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0"
.section .note.GNU-stack,"",@progbits
.section .note.gnu.property,"a"
.align 8
.long 1f - 0f
.long 4f - 1f
.long 5
0:
.string "GNU"
1:
.align 8
.long 0xc0000002
.long 3f - 2f
2:
.long 0x3
3:
.align 8
4:5-1. Ofast/pre.s
root@jimo:~/operation/Ofast# gcc --save-temps -Ofast pre.c
root@jimo:~/operation/Ofast# cat a-pre.s
.file "pre.c"
.text
.section .rodata.str1.1,"aMS",@progbits,1
.LC0:
.string "%d"
.section .text.startup,"ax",@progbits
.p2align 4
.globl main
.type main, @function
main:
.LFB23:
.cfi_startproc
endbr64
subq $8, %rsp
.cfi_def_cfa_offset 16
movl $2, %edx
movl $1, %edi
xorl %eax, %eax
leaq .LC0(%rip), %rsi
call __printf_chk@PLT
xorl %eax, %eax
addq $8, %rsp
.cfi_def_cfa_offset 8
ret
.cfi_endproc
.LFE23:
.size main, .-main
.ident "GCC: (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0"
.section .note.GNU-stack,"",@progbits
.section .note.gnu.property,"a"
.align 8
.long 1f - 0f
.long 4f - 1f
.long 5
0:
.string "GNU"
1:
.align 8
.long 0xc0000002
.long 3f - 2f
2:
.long 0x3
3:
.align 8
4:5-2. Ofast/post.s
root@jimo:~/operation/Ofast# gcc --save-temps -Ofast post.c
root@jimo:~/operation/Ofast# cat a-post.s
.file "post.c"
.text
.section .rodata.str1.1,"aMS",@progbits,1
.LC0:
.string "%d"
.section .text.startup,"ax",@progbits
.p2align 4
.globl main
.type main, @function
main:
.LFB23:
.cfi_startproc
endbr64
subq $8, %rsp
.cfi_def_cfa_offset 16
movl $1, %edx
movl $1, %edi
xorl %eax, %eax
leaq .LC0(%rip), %rsi
call __printf_chk@PLT
xorl %eax, %eax
addq $8, %rsp
.cfi_def_cfa_offset 8
ret
.cfi_endproc
.LFE23:
.size main, .-main
.ident "GCC: (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0"
.section .note.GNU-stack,"",@progbits
.section .note.gnu.property,"a"
.align 8
.long 1f - 0f
.long 4f - 1f
.long 5
0:
.string "GNU"
1:
.align 8
.long 0xc0000002
.long 3f - 2f
2:
.long 0x3
3:
.align 8
4:참고
전위와 후위 의견논쟁 https://gpgstudy.com/forum/viewtopic.php?t=20146
gcc 목적코드 출력 https://marcokhan.tistory.com/108
추가로 알아볼 오토마타 기본 개념 https://brunch.co.kr/@toughrogrammer/11
Visual Studio 디버깅모드와 활성모드에서의 최적화 수준 차이 https://learn.microsoft.com/ko-kr/cpp/build/working-with-project-properties?view=msvc-170
Visual Studio LTCG및 최적화 레벨 https://learn.microsoft.com/ko-kr/cpp/build/reference/ltcg-link-time-code-generation?view=msvc-170
