(24.09.10)
이전에 파악은 해둔 문제이다( https://velog.io/@gogogi313/Today-I-Learned-6j31r52x ) LeetCode를 TIL에 정리하다보니 가독성이 떨어지는 듯 해서 이제는 TIL보다는 시리즈물로 차곡차곡 정리를 시작해보려고 한다.
ab/cd=4 의 관계를 해결할 수 있으면 모든 로직을 해결할 수 있는 좋은 예시로 보인다.
ab=4cd로 간단히 표현할 수도 있지만, 모든 정보를 위해서는 a=4cd/b, b=4cd/a, c=ab/4c, d=ab/4c로 표현하는 것이 좋다. 이렇게 저장하는 것 까지는 쉽지만 다른 정보, 예를 들면 c=8b 같은 정보와 연립하는 것이 쉽지 않아 보인다. 이 문제의 주요 포인트는 어떤 방식으로 저장해야 여러 정보들을 연립하기 쉬운가? 로 보인다.
이를 위해선 모든 관계를 lookup table처럼 a=, b= 으로 표현하는 방법보다는 queries에서 우리에게 요구하는 값에서부터 역으로 접근하는 것은 어떨까? 예를 들어 queries에서 ["a", "c"]를 물어보았다면 a/c의 값이 궁금한 것이고 equations에서 a와 c와 관련된 모든 식을 DFS처럼 가져오는 것이다. 이러한 방법은 가져오는 과정도 복잡하고 후에 연립하는 과정도 복잡해보인다. 어떻게 해야 이 문제를 정말 쉽게 해결할 수 있을까?
예시를 통해 규칙성을 발견해보자.
예시를 보던 중 버블정렬의 접근방식을 이용하여 모든 관계식을 담을 수 있는 방법이 떠올랐다. a=2b가 db에 존재할 때 b=3c라는 정보가 새로 들어오면 db를 전부 확인하며 b가 들어가 있는 관계식에 b=3c를 넣어 새로운 식을 db에 추가해주는 것이다. 이런 방식이라면 a=4abc같은 연결된 관계만 처리하면 db에 저장하는 것은 해결이 된다.
a=2b는 a=2b이자, b=a/2이다. 이런 관계를 표현하기 위해 하나의 식을 두개의 식으로 나누어 저장하게 되면 공간효율성이 떨어진다. 고로 a~z열과 a~z행을 가지는 lookup table을 만들고 원소에 list를 두어 a와 b사이의 관계를 표현하는 여러 식을 3차원 구조로 저장하면 공간효율성을 확보할 수 있다. 다만 원소에 a=2b로만 저장할 것인지 a=2b, b=a/2로 저장할 것인지는 고민이 더 필요해보인다.
우선 -1이 나오는 구할 수 없는 조건 중 하나로 db에 없는 문자를 물어보는 경우가 있겠다. 기억해두자.
아니면 색다른 방법으로 "bc"/"cd"=5의 정보가 들어왔을 때 String 연산자 오버로딩을 통해 "b"/"d"=5가 되버리면 어떨까? 그렇다면 모든 문자를 b=5d꼴로 표현이 가능하고 queries에서 입력된 문제를 빠르게 계산할 수 있어 보인다. 그렇다면 연산자 오버로딩이 아니더라도 별도의 함수를 만들어서 equations을 약분하는 기능이 중요해보인다.
이정도 파악을 했으니 시작해보자. 저장은 2차원으로, equations은 최대한 약분해서 저장, queries는 저장한 공간에 문자가 존재하는지 부터 파악하며 나아가보자.
만약 equations 에 ab ab가 value에 1이 들어와서 ab=1*ab꼴의 함정카드를 숨겨둔다면..? 일단 배제.
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
class Solution {
private Map<String, String> db=new HashMap<>();
private void parse_equation(List<String> equation, double value){
if(equation.size()!=2)
throw new NumberFormatException("equation의 원소가 2개가 아닙니다.");
StringBuilder eq1=new StringBuilder(equation.get(0));
StringBuilder eq2=new StringBuilder(equation.get(1));
//문자약분처리
for(int i=0; i<eq1.length(); i++){
for(int j=0; j<eq2.length(); j++){
//문자처리
if(eq1.substring(i,i+1).equals(eq2.substring(j,j+1))){
eq1.deleteCharAt(i);
eq2.deleteCharAt(j);
i--; j--;//(현재 위치가 사라지로 shift되기에 다시 검사가 필요하기에 --)
}
}
}
db.put(eq1.toString(), value+eq2.toString());
//eq1=value*eq2정보 존재
}
private double calc_query(List<String> query){
if(query.size()!=2)
throw new NumberFormatException("equation의 원소가 2개가 아닙니다.");
StringBuilder query1=new StringBuilder(query.get(0));
StringBuilder query2 =new StringBuilder(query.get(1));
//문자약분처리
for(int i=0; i<query1.length(); i++){
for(int j = 0; j< query2.length(); j++){
//문자처리
if(query1.substring(i,i+1).equals(query2.substring(j,j+1))){
query1.deleteCharAt(i);
query2.deleteCharAt(j);
i--; j--;//(현재 위치가 사라지로 shift되기에 다시 검사가 필요하기에 --)
}
}
}
return 0.0;
}
public double[] calcEquation(List<List<String>> equations, double[] values, List<List<String>> queries) {
double[] result=new double[queries.size()];
for(int i=0; i<equations.size(); i++){
parse_equation(equations.get(i), values[i]);
}
for(int i=0; i<queries.size(); i++){
calc_query(queries.get(i));
}
return result;
}
public static void main(String[] args){
Solution solution=new Solution();
//example1 준비
List<List<String>> equations= new ArrayList<>();
double[] values=new double[1];
List<List<String>> queries=new ArrayList<>();
solution.calcEquation(equations, values, queries);
}
}초기 코드를 작성했으나, 코드가 너무 길고 parse_equation에서 문자 약분만 진행한 상태로 정보를 db에 넣기 때문에 후에 calc_query에서 활용하기 어렵다고 결론지었다. 현재의 접근법을 철회한다.
새로운 접근법이 생각났는데, equation을 key로 value를 value로 갖는 map을 만든 후, 저장하면서 equation의 역순도 map에 넣어 lookup table을 구축, queries를 키로갖으면 그 값을 리턴하는 방식을 시도해보았다.
class Solution {
private List<String> abbreviation(List<String> equation){
StringBuilder eq1=new StringBuilder(equation.get(0));
StringBuilder eq2=new StringBuilder(equation.get(1));
//문자약분처리
for(int i=0; i<eq1.length(); i++){
for(int j=0; j<eq2.length(); j++){
//문자처리
if(eq1.substring(i,i+1).equals(eq2.substring(j,j+1))){
eq1.deleteCharAt(i);
eq2.deleteCharAt(j);
i--; j--;//(현재 위치가 사라지로 shift되기에 다시 검사가 필요하기에 --)
}
}
}
//재활용
equation.set(0, eq1.toString());
equation.set(1, eq2.toString());
return equation;
}
public double[] calcEquation(List<List<String>> equations, double[] values, List<List<String>> queries) {
//equations순회하며 동일한건 제거
//그대로 db에 넣으면서 거꾸로 value도 넣음
//queries에 db에 있으면 value를 리턴
Map<List<String>, Double> db=new HashMap();
for(int i=0; i<equations.size(); i++){
List<String> simple_equation=abbreviation(equations.get(i));
db.put(simple_equation, values[i]);
List<String> reverse_equation=new ArrayList<>();
reverse_equation.add(simple_equation.get(1));
reverse_equation.add(simple_equation.get(0));
db.put(reverse_equation, 1/values[i]);
}
double[] result=new double[queries.size()];
for(int i=0; i<queries.size(); i++){
if(db.containsKey(queries.get(i)))
result[i]=db.get(queries.get(i));
else
result[i]=-1;
}
return result;
}
}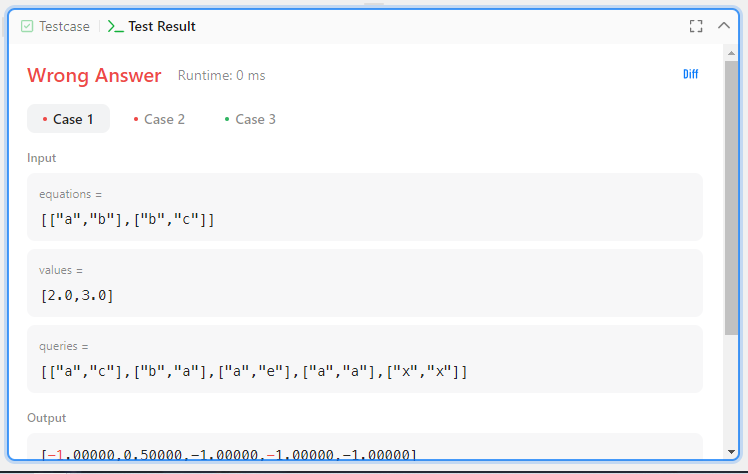
뭐라도 하나 맞출 수 있었다. 보완해야할 점을 알 수 있었는데 우선 연립을 고려하지 않았고 a, a가 입력되었을 때 equations에 사용된 값이라면 1을, 사용되지 않은 값이라면 0이어서 0/0일 수도 있기에 -1을 반환하는 로직이 필요하다.
(24.09.11)
한번에 완벽한 아이디어를 생각해내기 어려운 문제이기 때문에 TDD 방식으로 접근하는 것이 좋아보인다. 현재 기본 testcase3개 중 3번만 통과했는데, 오늘은 1번 통과를 목표로 해보자.
query에 같은 문자가 있다면, db에서 존재 유무만 판단해서 1또는 -1만 리턴하면 된다.
이를 위해 아래와 같은 코드를 추가하였다.
//동일한 전항과 후항을 갖을 경우 처리를 위해 db에 저장.
List<String> preceding_duplicated_equation=new ArrayList<>();
preceding_duplicated_equation.add(simple_equation.get(0));
preceding_duplicated_equation.add(simple_equation.get(0));
db.put(preceding_duplicated_equation, 1.0);
List<String> consequent_duplicated_equation=new ArrayList<>();
consequent_duplicated_equation.add(simple_equation.get(1));
consequent_duplicated_equation.add(simple_equation.get(1));
db.put(consequent_duplicated_equation, -1.0);이제 testcase 1번의 해결을 위해서는 연립을 구현해야만 한다. 이를 해결하기 위해 저장된 db를 훑으며, 전항과 후항끼리 같은 equation을 찾아 새로운 연립 관계를 만들어내는 코드를 추가하기로 했다. 다만, 이때 새로이 만들어진 항과 또 기존의 항의 연립관계가 존재할 수 있기에 bubble sort처럼 새로운 연립관계가 발견되지 않을 때 까지 이중 for문을 돌리겠다.
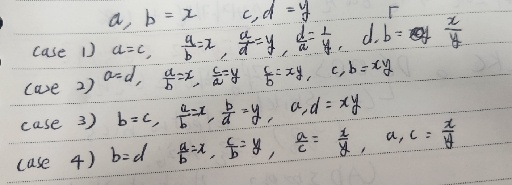
class Solution {
private List<String> abbreviation(List<String> equation){
StringBuilder eq1=new StringBuilder(equation.get(0));
StringBuilder eq2=new StringBuilder(equation.get(1));
//문자약분처리
for(int i=0; i<eq1.length(); i++){
for(int j=0; j<eq2.length(); j++){
//문자처리
if(eq1.substring(i,i+1).equals(eq2.substring(j,j+1))){
eq1.deleteCharAt(i);
eq2.deleteCharAt(j);
i--; j--;//(현재 위치가 사라지로 shift되기에 다시 검사가 필요하기에 --)
}
}
}
//재활용
equation.set(0, eq1.toString());
equation.set(1, eq2.toString());
return equation;
}
public double[] calcEquation(List<List<String>> equations, double[] values, List<List<String>> queries) {
//equations순회하며 동일한건 제거
//그대로 db에 넣으면서 거꾸로 value도 넣음
//queries에 db에 있으면 value를 리턴
Map<List<String>, Double> db=new HashMap();
for(int i=0; i<equations.size(); i++){
//equation과 동일한 query인 경우의 처리를 위해 약분한 결과와 그 역을 db에 저장
List<String> simple_equation=abbreviation(equations.get(i));
db.put(simple_equation, values[i]);//equation을 db에 저장
List<String> reverse_equation=new ArrayList<>();
reverse_equation.add(simple_equation.get(1));
reverse_equation.add(simple_equation.get(0));
db.put(reverse_equation, 1/values[i]);//역순 equation을 db에 저장
}
//연립을 위해 동일한 항을 가지는 항을 찾아 나머지 두개를 이용하여, 연립 항 정보를 찾아 db에 넣는다.
Map<List<String>, Double> new_db=new HashMap<>();
for(Map.Entry<List<String>, Double> eq1 : db.entrySet()){
for(Map.Entry<List<String>, Double> eq2 : db.entrySet()){
if(eq1.equals(eq2))
continue;
List<String> new_equation=new ArrayList<>();
List<String> rev_new_equation=new ArrayList<>();
double new_value=-1.0, rev_new_value=-1.0;
if(eq1.getKey().get(0).equals(eq2.getKey().get(0))){//case 1
new_equation.add(eq2.getKey().get(1));
new_equation.add(eq1.getKey().get(1));
new_value=eq1.getValue()/eq2.getValue();
rev_new_equation.add(eq1.getKey().get(1));
rev_new_equation.add(eq2.getKey().get(1));
rev_new_value=1/new_value;
} else if(eq1.getKey().get(0).equals(eq2.getKey().get(1))){//case2
new_equation.add(eq2.getKey().get(0));
new_equation.add(eq1.getKey().get(1));
new_value=eq1.getValue()*eq2.getValue();
rev_new_equation.add(eq1.getKey().get(1));
rev_new_equation.add(eq2.getKey().get(0));
rev_new_value=1/new_value;
} else if(eq1.getKey().get(1).equals(eq2.getKey().get(0))){//case3
new_equation.add(eq1.getKey().get(0));
new_equation.add(eq2.getKey().get(1));
new_value=eq1.getValue()/eq2.getValue();
rev_new_equation.add(eq2.getKey().get(1));
rev_new_equation.add(eq1.getKey().get(0));
rev_new_value=1/new_value;
} else if(eq1.getKey().get(1).equals(eq2.getKey().get(1))){//case4
new_equation.add(eq1.getKey().get(0));
new_equation.add(eq2.getKey().get(0));
new_value=eq1.getValue()/eq2.getValue();
rev_new_equation.add(eq2.getKey().get(0));
rev_new_equation.add(eq1.getKey().get(0));
rev_new_value=1/new_value;
}
new_db.put(new_equation, new_value);
new_db.put(rev_new_equation, rev_new_value);
}
}
db.putAll(new_db);
for(int i=0; i<equations.size(); i++){
//동일한 전항과 후항을 갖을 경우 처리를 위해 db에 저장.
List<String> simple_equation=abbreviation(equations.get(i));
List<String> preceding_duplicated_equation=new ArrayList<>();
preceding_duplicated_equation.add(simple_equation.get(0));
preceding_duplicated_equation.add(simple_equation.get(0));
db.put(preceding_duplicated_equation, 1.0);
List<String> consequent_duplicated_equation=new ArrayList<>();
consequent_duplicated_equation.add(simple_equation.get(1));
consequent_duplicated_equation.add(simple_equation.get(1));
db.put(consequent_duplicated_equation, -1.0);
}
double[] result=new double[queries.size()];
for(int i=0; i<queries.size(); i++){
//db에 query식이 그대로 들어가 있는지 확인
if(db.containsKey(queries.get(i)))
result[i]=db.get(queries.get(i));
else
result[i]=-1;
}
return result;
}
}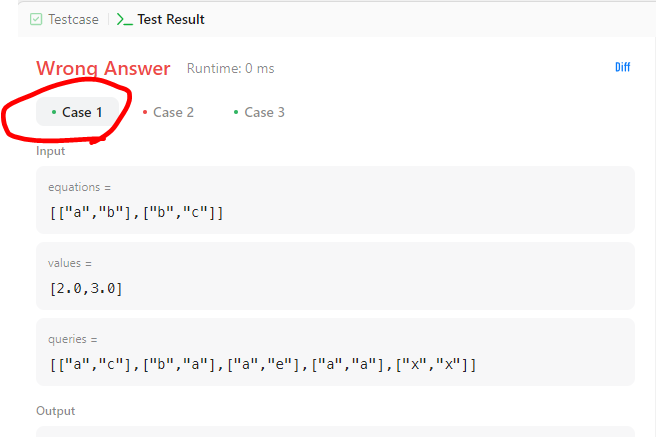
testcase 1번을 통과하였다. testcase 2번은 다음과 같이 equations과 queries가 두글자 이상인 경우이다.
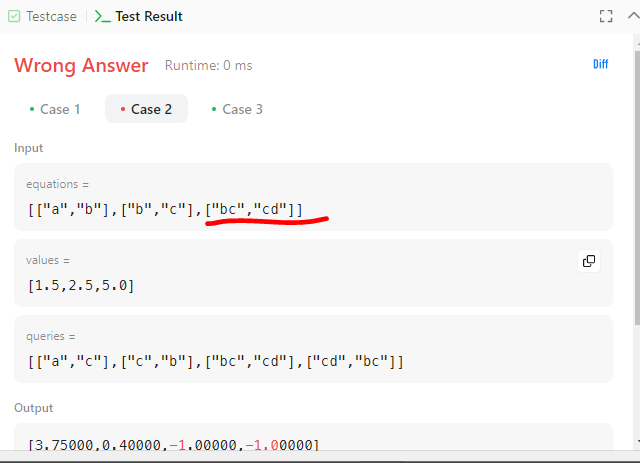
그러나 TDD방식으로 접근해보면, Case2번은 queries를 동일항만 약분해주면 된다. 기존에 만들어둔 abbreviation함수를 적용하자.
double[] result=new double[queries.size()];
for(int i=0; i<queries.size(); i++){
//db에 query식이 그대로 들어가 있는지 확인
if(db.containsKey(queries.get(i)))
result[i]=db.get(queries.get(i));
else if(db.containsKey(abbreviation(queries.get(i))))
result[i]=db.get(abbreviation(queries.get(i)));
else
result[i]=-1;
}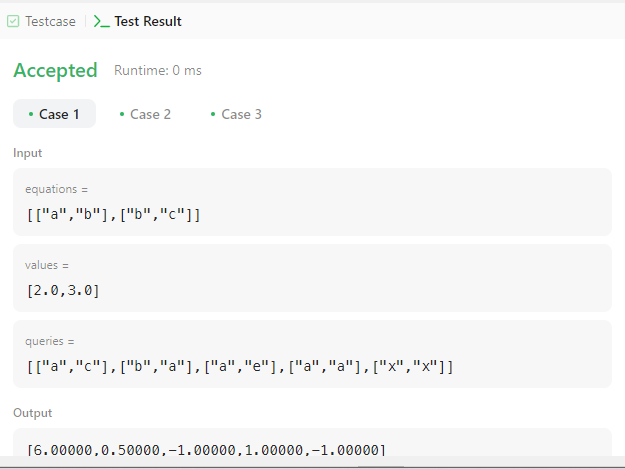
기본 Case는 모두 통과했다. 이제 제출해보자.
(24.09.12)
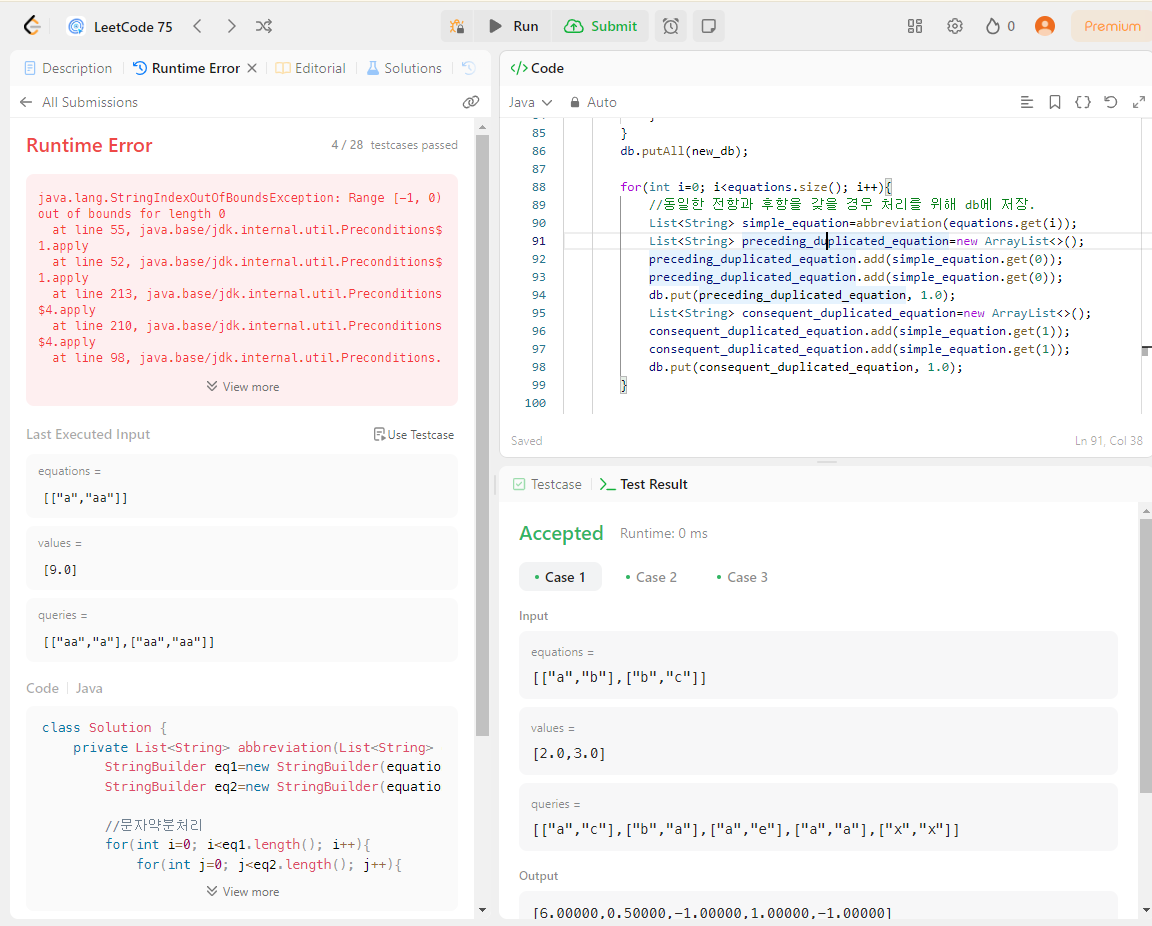
오늘의 목표는 case 4번 equation= "a", "aa", value=9.0을 해결해보도록 하자.
이건 db에 특별한걸 저장하기보다, abbreviation이 제대로 이루어 졌다면 "1", "a"가 되었을 텐데 먼저 확인해보자. 오류는 StringIndexOutOfBoundsException이고 최초 equations를 abbreviation할 때, 문자를 삭제하여 equation의 "a"가 ""가 되어 에러가 발생하는 것으로 보인다. 만약 ""가 될 경우 "1"을 넣어주도록 abbreviation()의 코드를 추가해주자.
하지만 다른 오류를 발견했는데, 약분 후 equation 1과 2의 index indicator를 -1하니 이중 for문 내부에서 ++되는 타이밍이 달라 index위치 -1에 접근하여 오류가 발생했다.
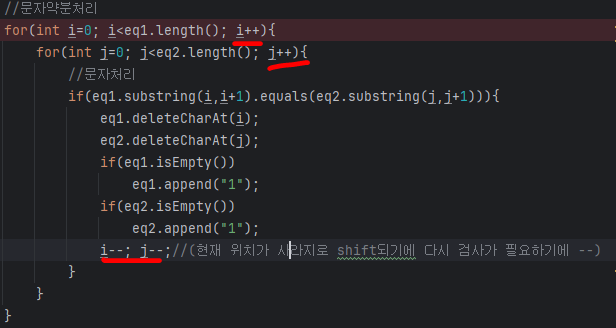
이를 해결하기 위해 db 기본값으로 equation 1,1 value 1.0을 넣고 abbreviation()함수에 분모 분자가 같은 값인 경우 1, 1로 세팅시켜 해결하였다.
문제는 앞서 시도했던 case 1번에서 오류가 발생하였다.
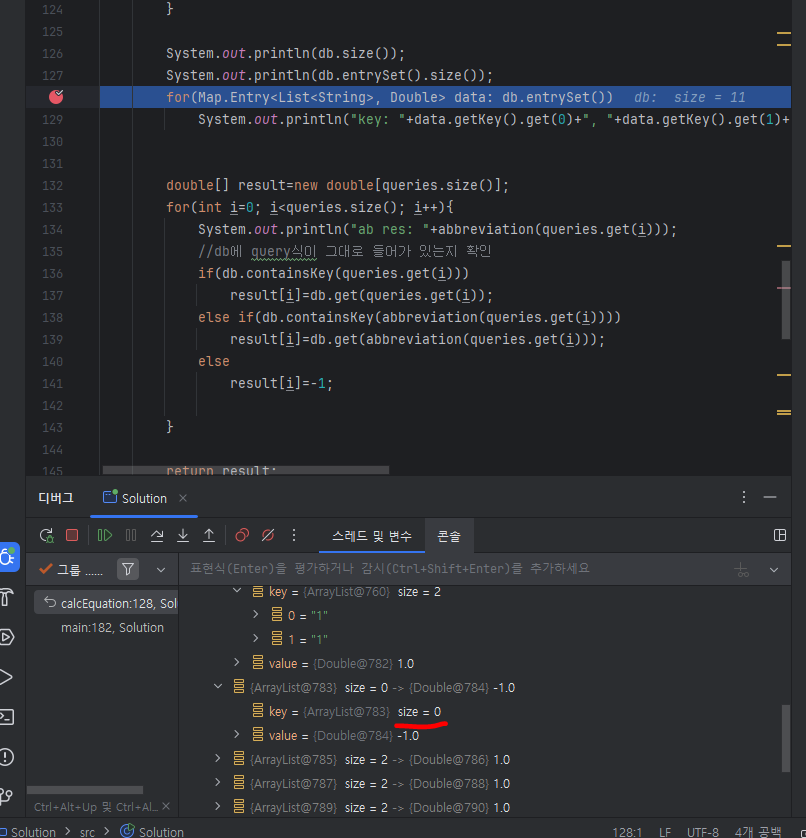
DB에 null을 key로 가지고 -1을 value로 가지는 값이 들어간 것이 포착되었다. 이것은 연립 과정에서의 기본값이다. 연립할 값이 하나도 없는 equation의 경우에도 db에 데이터를 넣는 코드가 if문 밖에 있기에 들어간 것으로 보인다. db문을 if안에 각각 넣어주자.
case 1에서 또 문제가 발생했는데, queries abbreviation을 진행하며 db에 존재하지 않는 값을 1로 약분해버려 0일 수도 있는 미지수 x, x에 대해 1을 반환하는 오류를 발견하였다.
이를 해결하기 위해 equation에서 사용한 문자들을 set에 넣었고, query에서 이상한거 포함하면 -1하게 수정하였다.
class Solution {
private List<String> abbreviation(List<String> equation){
StringBuilder eq1=new StringBuilder(equation.get(0));
StringBuilder eq2=new StringBuilder(equation.get(1));
//문자약분처리
for(int i=0; i<eq1.length() && !eq1.toString().equals("1"); i++){
for(int j=0; j<eq2.length() && !eq2.toString().equals("1"); j++){
//삭제 후 음수 인덱스가 되는것 방지
if(i<0) i=0;
if(j<0) j=0;
//같은 값을 가질 때
if(eq1.toString().contentEquals(eq2)){
eq1.delete(0, eq1.length());
eq2.delete(0, eq2.length());
eq1.append("1");
eq2.append("1");
break;
}
//문자처리
if(eq1.substring(i,i+1).equals(eq2.substring(j,j+1))){
eq1.deleteCharAt(i);
eq2.deleteCharAt(j);
if(eq1.isEmpty())
eq1.append("1");
if(eq2.isEmpty())
eq2.append("1");
i--; j--;//(현재 위치가 사라지로 shift되기에 다시 검사가 필요하기에 --)
}
}
}
//재활용
equation.set(0, eq1.toString());
equation.set(1, eq2.toString());
return equation;
}
public double[] calcEquation(List<List<String>> equations, double[] values, List<List<String>> queries) {
//equations순회하며 동일한건 제거
//그대로 db에 넣으면서 거꾸로 value도 넣음
//queries에 db에 있으면 value를 리턴
Map<List<String>, Double> db=new HashMap();
//기본값 저장
List<String> default_data=new ArrayList<>();
default_data.add("1"); default_data.add("1");
db.put(default_data, 1.0);
Set<Character> used_chars=new HashSet<>();
for(int i=0; i<equations.size(); i++){
for(char c: equations.get(i).get(0).toCharArray()){
used_chars.add(c);
}
for(char c: equations.get(i).get(1).toCharArray()){
used_chars.add(c);
}
//equation과 동일한 query인 경우의 처리를 위해 약분한 결과와 그 역을 db에 저장
List<String> simple_equation=abbreviation(equations.get(i));
db.put(simple_equation, values[i]);//equation을 db에 저장
List<String> reverse_equation=new ArrayList<>();
reverse_equation.add(simple_equation.get(1));
reverse_equation.add(simple_equation.get(0));
db.put(reverse_equation, 1/values[i]);//역순 equation을 db에 저장
}
System.out.println(db.size());
//연립을 위해 동일한 항을 가지는 항을 찾아 나머지 두개를 이용하여, 연립 항 정보를 찾아 db에 넣는다.
Map<List<String>, Double> new_db=new HashMap<>();
for(Map.Entry<List<String>, Double> eq1 : db.entrySet()){
for(Map.Entry<List<String>, Double> eq2 : db.entrySet()){
if(eq1.equals(eq2))
continue;
List<String> new_equation=new ArrayList<>();
List<String> rev_new_equation=new ArrayList<>();
double new_value=-1.0, rev_new_value=-1.0;
System.out.println(eq1.getKey().get(0)+", "+eq1.getKey().get(1)+", "+eq2.getKey().get(0)+", "+eq2.getKey().get(1));
if(eq1.getKey().get(0).equals(eq2.getKey().get(0))){//case 1
new_equation.add(eq2.getKey().get(1));
new_equation.add(eq1.getKey().get(1));
new_value=eq1.getValue()/eq2.getValue();
rev_new_equation.add(eq1.getKey().get(1));
rev_new_equation.add(eq2.getKey().get(1));
rev_new_value=1/new_value;
new_db.put(new_equation, new_value);
new_db.put(rev_new_equation, rev_new_value);
} else if(eq1.getKey().get(0).equals(eq2.getKey().get(1))){//case2
new_equation.add(eq2.getKey().get(0));
new_equation.add(eq1.getKey().get(1));
new_value=eq1.getValue()*eq2.getValue();
rev_new_equation.add(eq1.getKey().get(1));
rev_new_equation.add(eq2.getKey().get(0));
rev_new_value=1/new_value;
new_db.put(new_equation, new_value);
new_db.put(rev_new_equation, rev_new_value);
} else if(eq1.getKey().get(1).equals(eq2.getKey().get(0))){//case3
new_equation.add(eq1.getKey().get(0));
new_equation.add(eq2.getKey().get(1));
new_value=eq1.getValue()/eq2.getValue();
rev_new_equation.add(eq2.getKey().get(1));
rev_new_equation.add(eq1.getKey().get(0));
rev_new_value=1/new_value;
new_db.put(new_equation, new_value);
new_db.put(rev_new_equation, rev_new_value);
} else if(eq1.getKey().get(1).equals(eq2.getKey().get(1))){//case4
new_equation.add(eq1.getKey().get(0));
new_equation.add(eq2.getKey().get(0));
new_value=eq1.getValue()/eq2.getValue();
rev_new_equation.add(eq2.getKey().get(0));
rev_new_equation.add(eq1.getKey().get(0));
rev_new_value=1/new_value;
new_db.put(new_equation, new_value);
new_db.put(rev_new_equation, rev_new_value);
}
}
}
db.putAll(new_db);
System.out.println(db.size());
System.out.println(db.entrySet().size());
for(Map.Entry<List<String>, Double> data: db.entrySet())
System.out.println("key: "+data.getKey().get(0)+", "+data.getKey().get(1)+" / value: "+data.getValue());
double[] result=new double[queries.size()];
for(int i=0; i<queries.size(); i++){
boolean is_err=false;
for(char c: queries.get(i).get(0).toCharArray()){
if(!used_chars.contains(c)){
is_err=true;
break;
}
}
for(char c: queries.get(i).get(1).toCharArray()){
if(!used_chars.contains(c)){
is_err=true;
break;
}
}
if(is_err) {
result[i] = -1;
continue;
}
System.out.println("ab res: "+abbreviation(queries.get(i)));
//db에 query식이 그대로 들어가 있는지 확인
if(db.containsKey(queries.get(i)))
result[i]=db.get(queries.get(i));
else if(db.containsKey(abbreviation(queries.get(i))))
result[i]=db.get(abbreviation(queries.get(i)));
else
result[i]=-1;
}
return result;
}
}
머나먼 길을 떠나기 전에 최적화를 진행하며 쉬어가자.
(24.09.13)
불필요한 if구문을 제거한 것 과 주석으로 정리한 것 외에 큰 흐름은 건드리지 않으며 최적화를 진행했다.
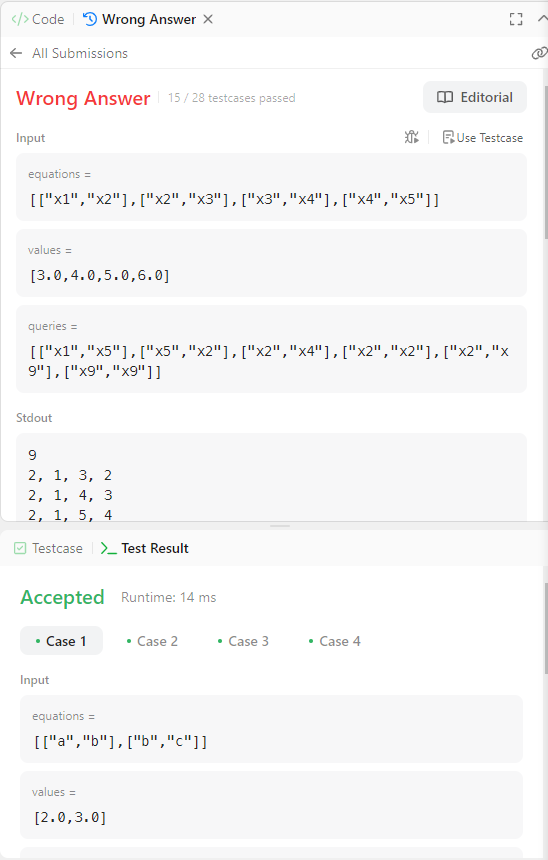
15번 테스트 케이스를 보면, 문자가 아닌 숫자가 등장하는데 예시는 아래와 같다.
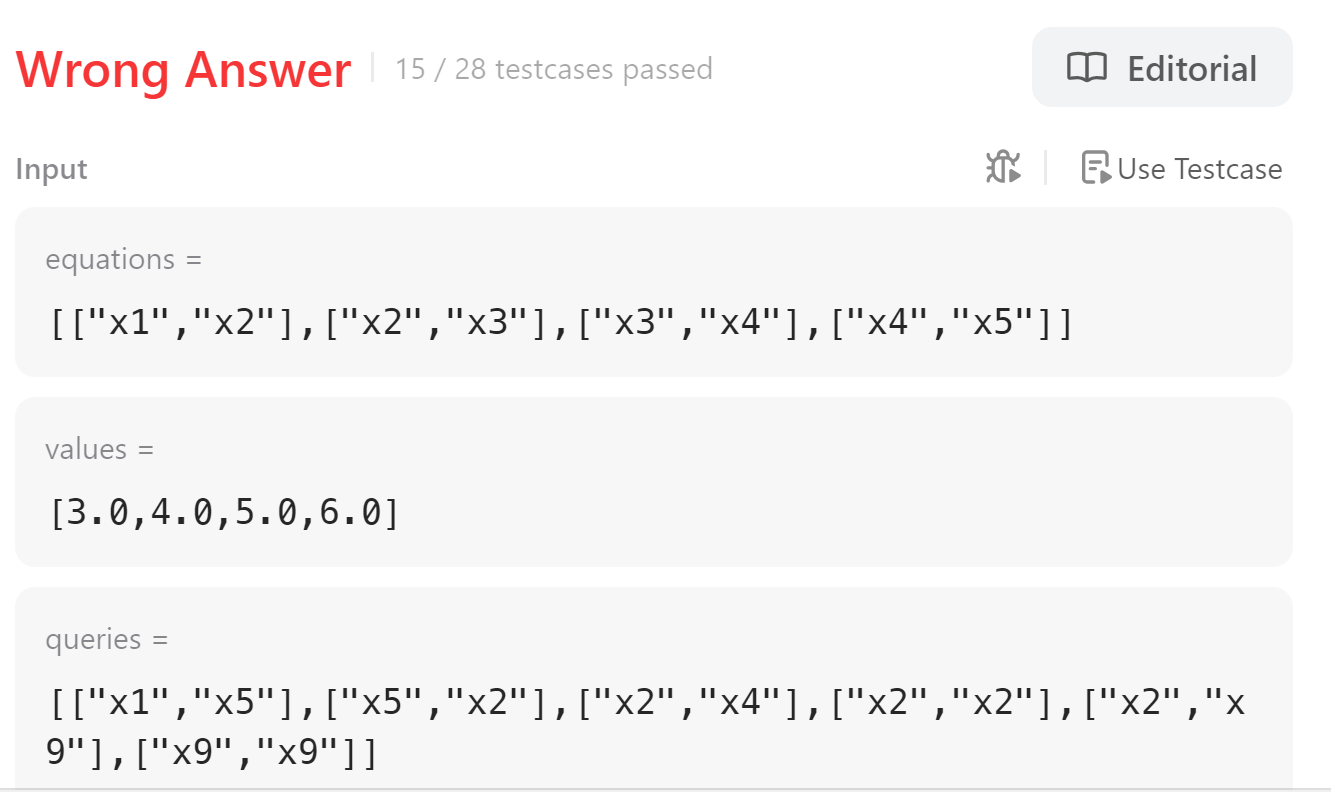
위의 형식으로 equation이 들어오는 것은 생각하지 못했는데, 숫자가 등장하면 앞선 문자의 계수가아닌 이름으로 취급하는 것이 좋아보인다. 다행히도 현재 로직이 char단위가 아닌 String단위가 아니라 db에 저장하는 부분에서 숫자가 나올 시 전꺼랑 붙여주는 로직을 추가해보려했는데, 아예 약분을 수행하지 않는 방법을 테스트해봤다. 하지만 Case 15는 여전히 해결되지 않았다.
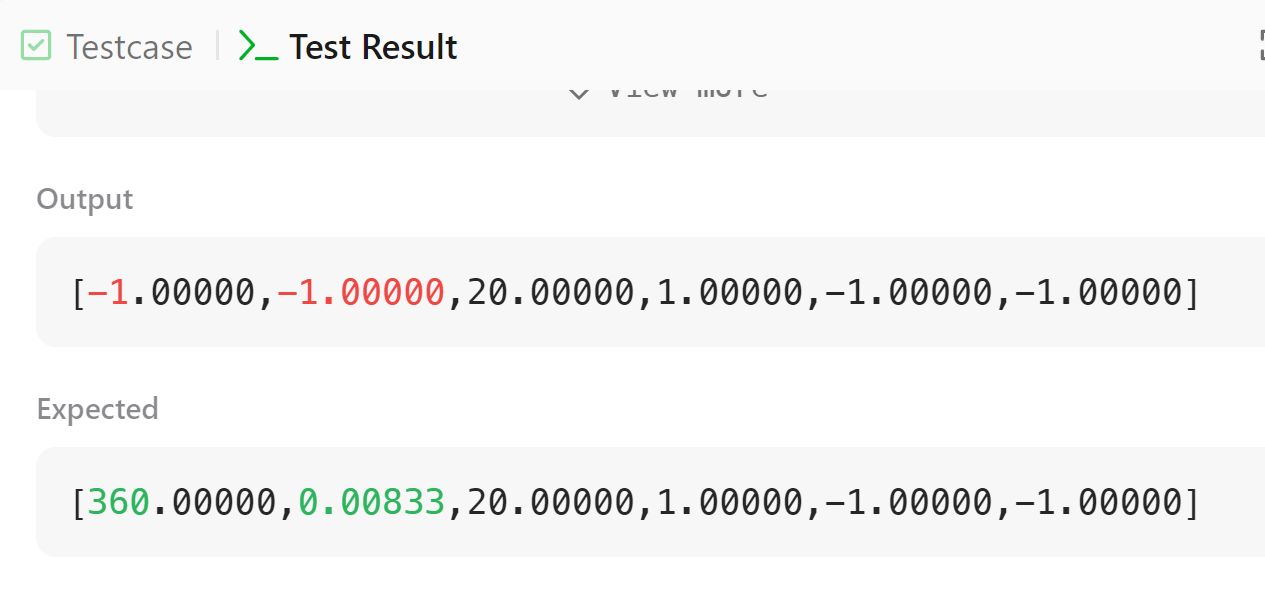
문제는 에러가 아닌 첫 equation에서 사용한 문자와 마지막 equation에서 사용한 문자의 연립이 제대로 되지 않은 듯 보인다. 디버거를 통해 확인해보았더니, 약분을 하지 않고 db에 저장이 x1이 통째로 잘 들어갔는데 연립 식에서 일부 연립 관계가 누락된 것을 확인하였다. 이는 연립으로 계산한 식을 new_db로 따로 분리했기에 db에 저장된 내용으로만 연립되는 1차원 적인 문제가 발생한 것으로 보인다. db와 new_db를 분리시킨 이유는 최초에 전체를 for문으로 묶어 버블정렬 처리할 계획이었기에 이에 따른 무한루프를 막기 위함이었는데, 전체를 for문처럼 묶지 않았기에(필요한 연립만을 수행하는 최소의 연산을 위해) new_db와 db를 분리하지 않고 연립식을 db에 넣어보겠다.
그러자 기존에 사용한 for문이 db.length()를 기반으로 작동되기에 오류가 발생하였고, 결국 전체를 for 루프로 묶어서 bubble처럼 시도하게 되었다.
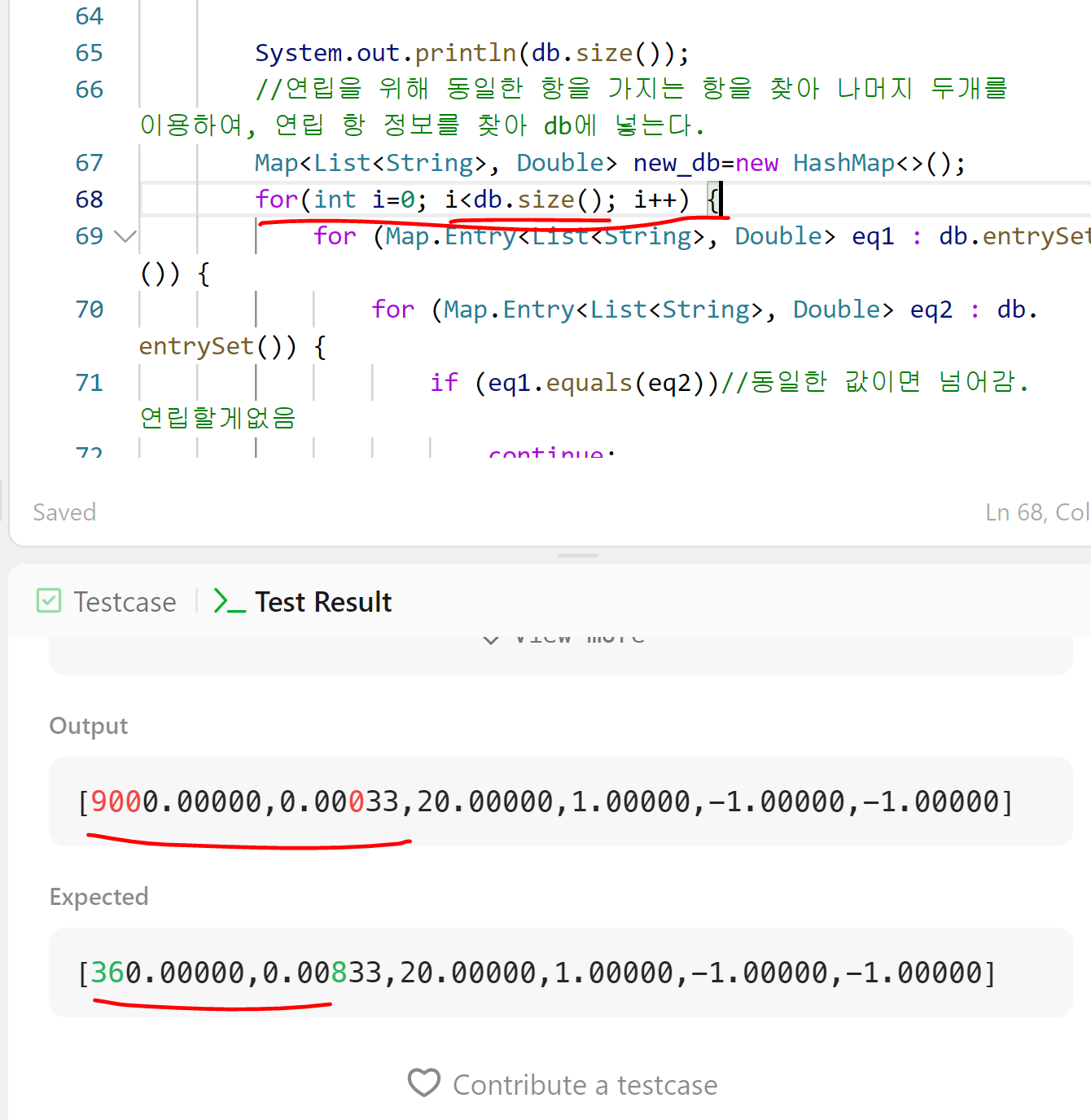
결과를 보니 작동은 잘 되었는데, 계산수식이 잘못된 것 같다. 검토해보니 연립을 위한 4가지 case 중 3번째 케이스가 코드에 잘못 구현되어있었다. b/a=x, b/a=y에서 a/d=xy인데 코드상으로 x/y로 *가 /로 작성되어있었다.
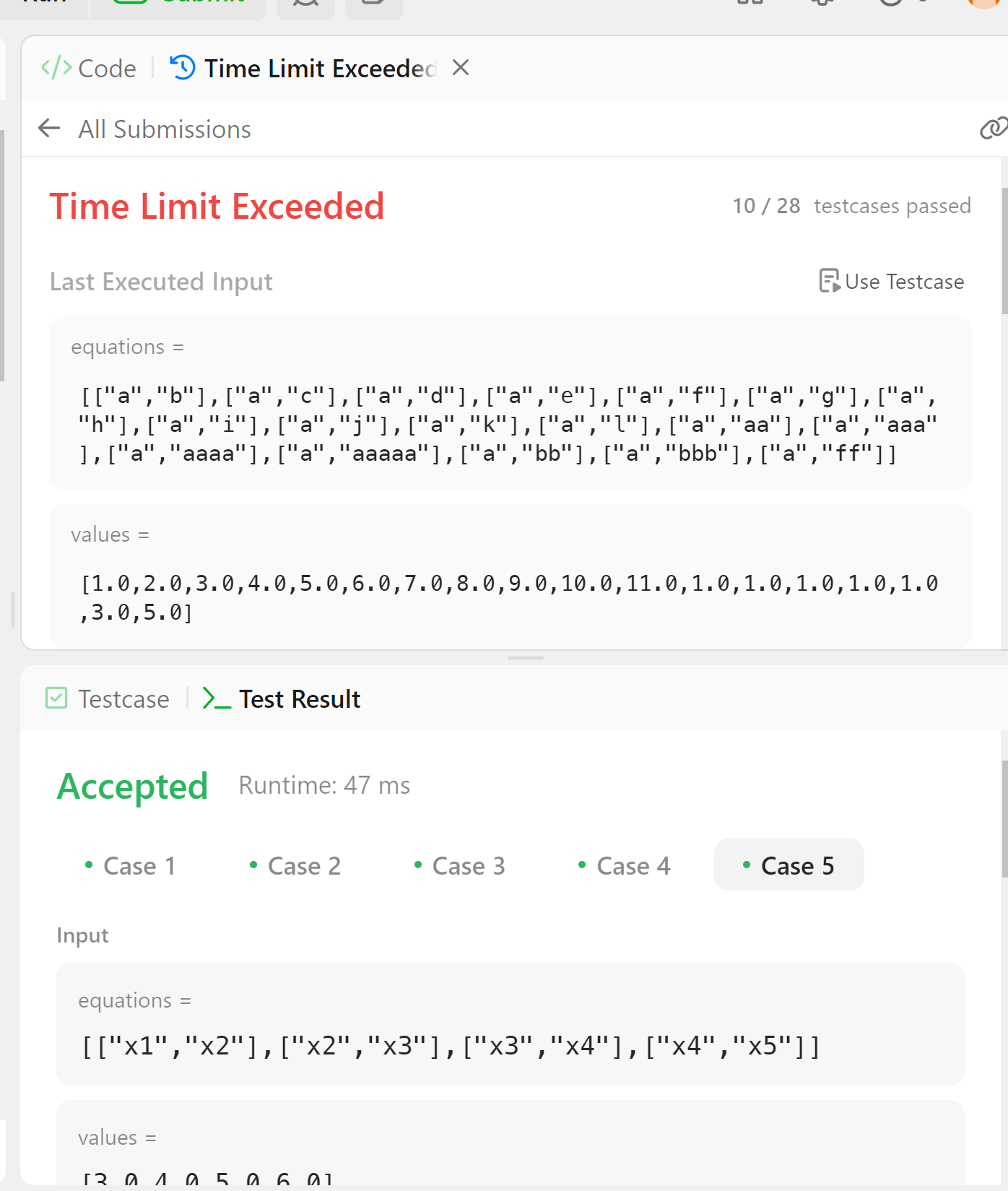
그러자 이번에는 testcase 10번에서 TLE에러가 발생하였다.
추가된 bubble같은 for문이 문제인데 해결하기위해 이를 없애니 깊은 연립에 대한 계산처리가 수행되지 않았다. bubble 순회의 횟수를 2회로 고정하니, 24/28 테스트케이스까지 진행할 수 있었다. 이는 값 오류로 적은 순회의 횟수로 인한 것으로 보인다.
(24.09.20)
횟수를 3회로 올려 24/28에서 25/28까지 향상시킬 수 있었지만 그 이상으로 넘어가지 못했다. 논리 오류가 발생한 듯 보인다.
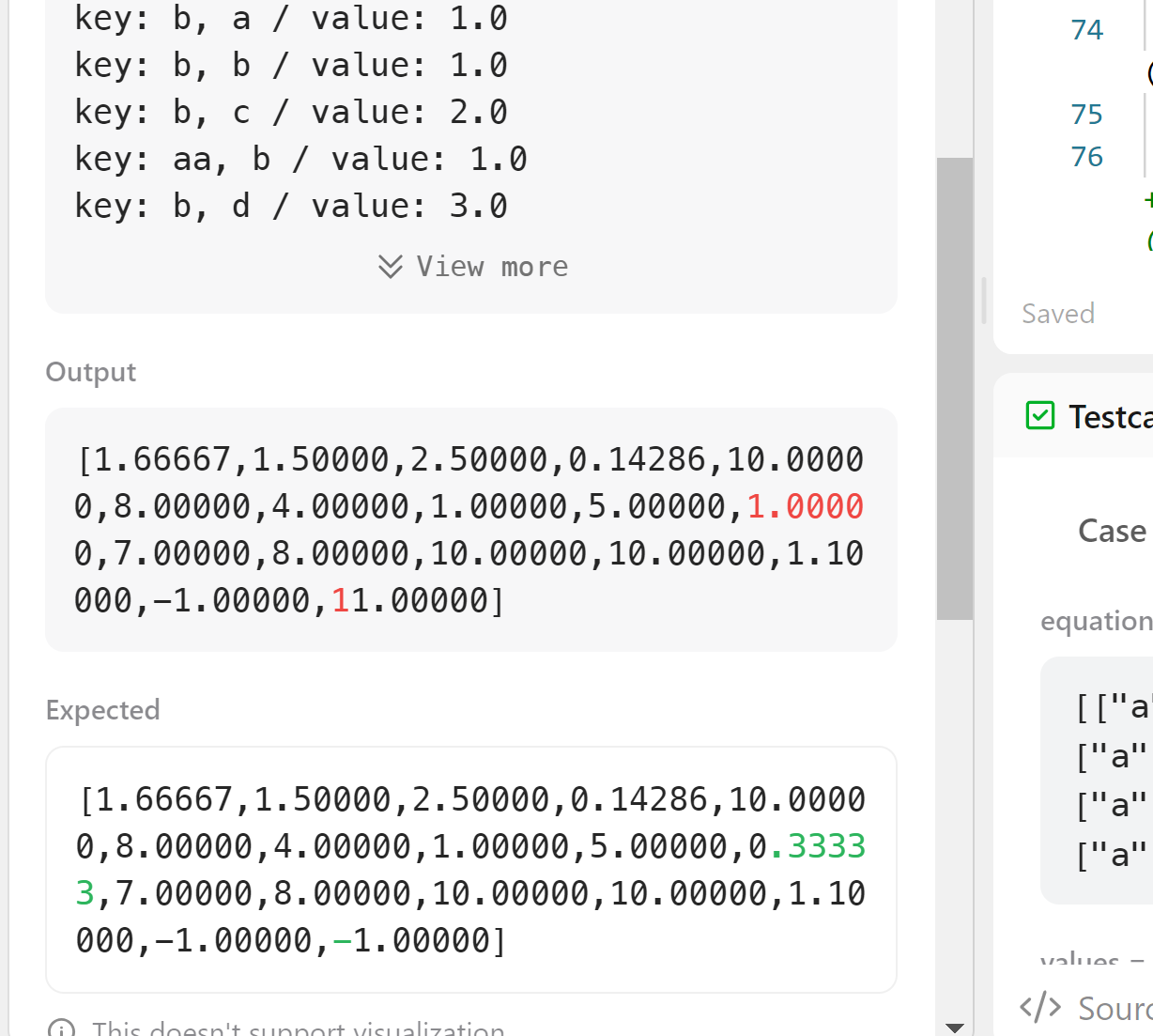
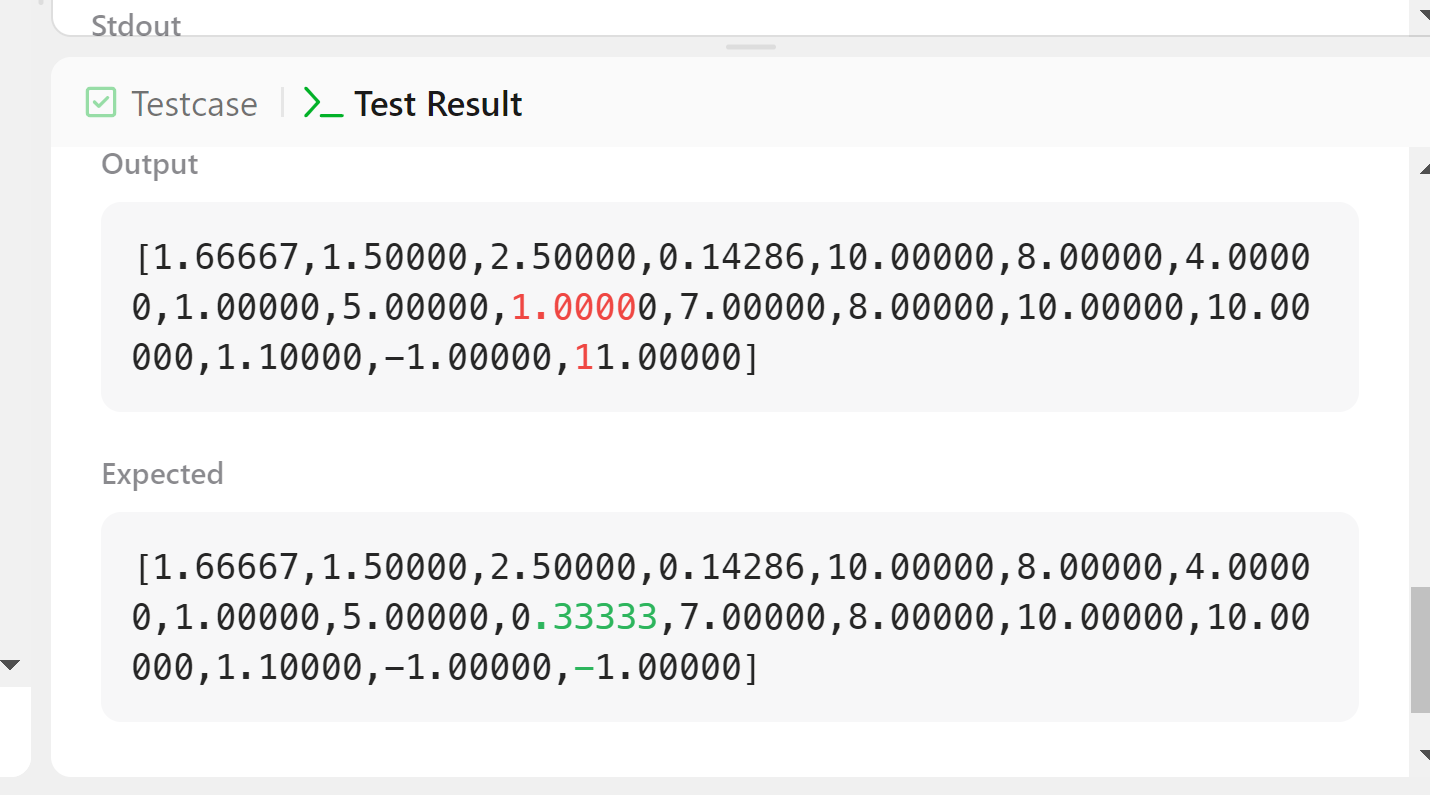
값이 출력되야 하는 것이 1로 나오기로 했고, -1로 처리해야하는걸 11로 값이 나오기도 했다.
우선 0.33이 1로 잘못 나온 query는 "bbb", "bb"이고, -1이 11로 잘못 나온 query는 "l", "ll"이었다. 이는 약분을 비활성화 시킨 탓으로 보인다. 하지만 이전에 약분을 비활성화 시킨 이유가 x1 x2와 같은 방식의 equation입력 때문이었기에 equation에서의 약분은 불가능하고.. query에서도 x1 x2의 입력이 올 수 있기에 불가능한데.. 숫자가 없는 경우에만 활성화를 시키면 될 듯 하다. 아예 abbreviation함수에서 숫자가 있다면 입력을 그대로 반환하게끔 수정하였다. 그 결과 26/28까지 진행할 수 있었다.
문제를 발견했다. 26번 테스트의 오류가 발생하는 query가 "l", "ll"인데 equation에 "a", "l"이 11.0이고 "a", "aa"가 1.0이었다. 그렇다면 1/"a"=1이고 "a"=1이다. 1/"l"=11이고 "l"=1/11이다. 1/"l"=11이다. 고로 위 query는 11인데 26 테스트는 이를 -1로 판단했다. equation에 "l"이 분모로 들어간 값이 존재한다는건 이미 0이 아님이 증명된 것인데 왜 -1로 판단했는지 이해할 수 없다.
다른 부분을 보자. "bbb", "bb" query에서 나는 1을 계산했지만 정답은 0.333이다. equation에서 "a", "bb"는 1.0이다. 위에서 "a"=1임을 계산했으니 "b"또한 1이된다. query "bbb", "bb"는 "b"기에 0.33이 아닌 1이 되어야한다.
고로 이 테스트 케이스는 잘못되었다.
그러나 discussion에서 충격적인 글을 보게되었다.
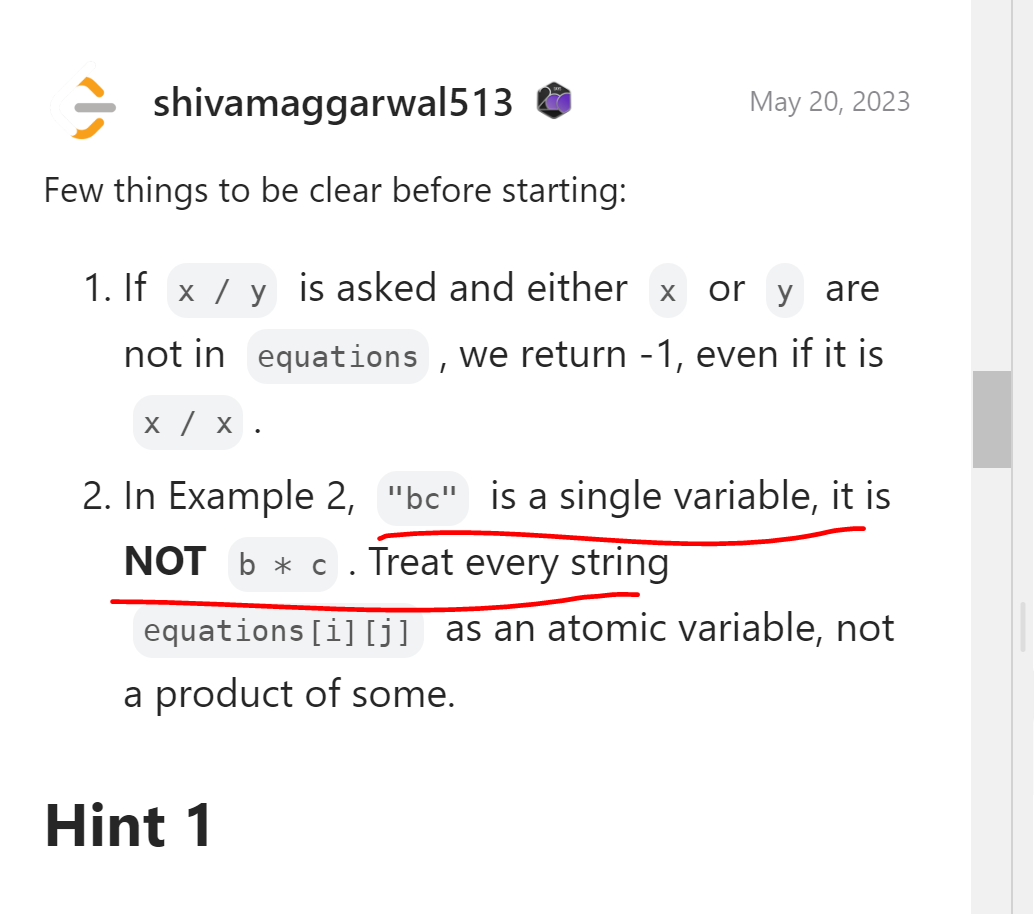
이런 내용을 줄거면 문제에 넣어야지 왜 discussion에 넣었을까? 이 사실을 알고보니 정말 간단한 문제였다. 또한 이러한 내용을 거를 testcase 26번까지 가서야 넣었다는 것을 코더를 농락하려는 취지로밖에 보이지 않는다.
(24.09.24)
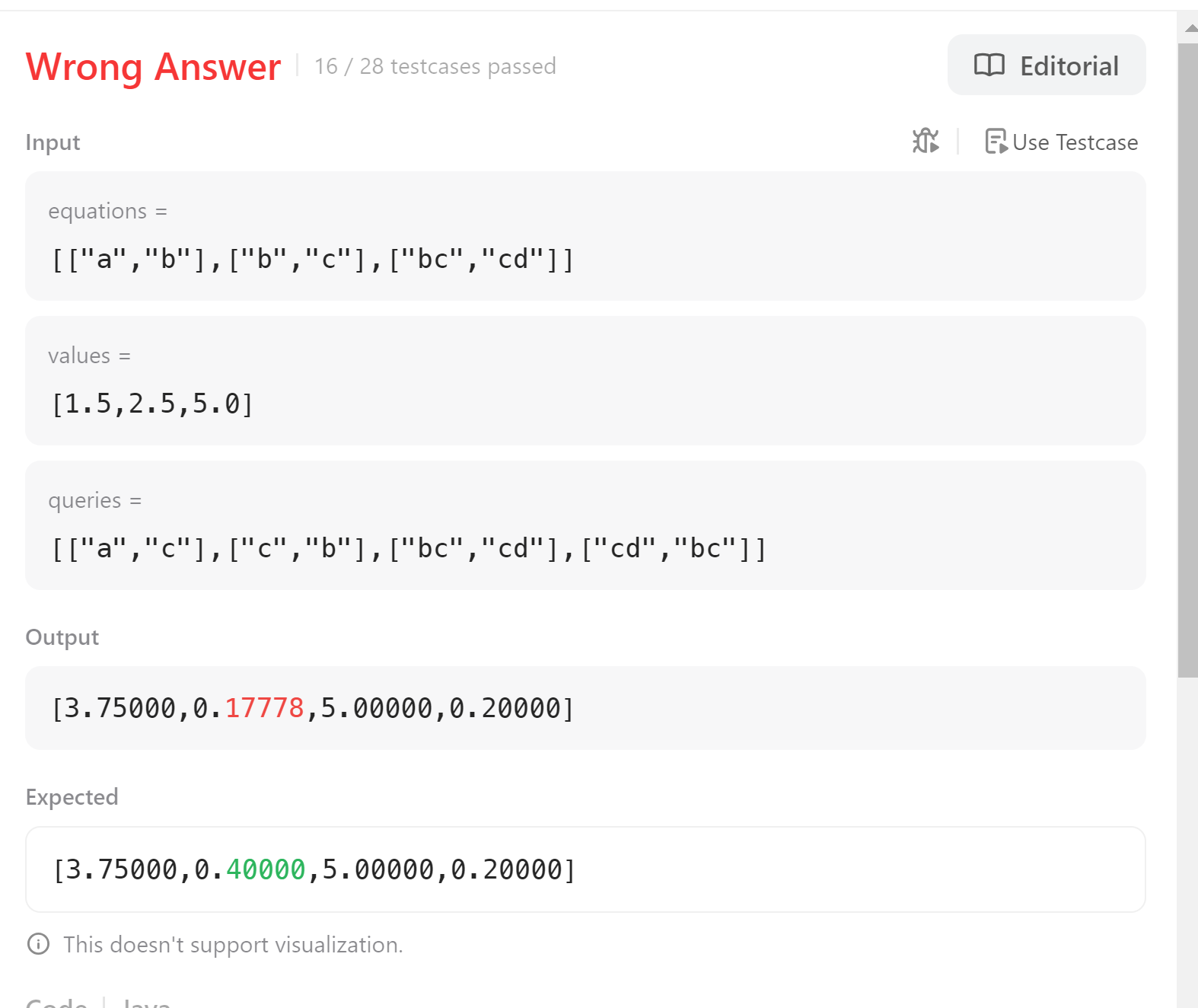
문제가 되는 항목을 보면 b/c=2.5, b=2.5c이고, c/b=0.4인데 0.17778이 나오는 오류를 확인할 수 있다. 디버깅을 해보니 최초 db 생성 시 제대로 값이 들어가 있는 것을 확인할 수 있다.
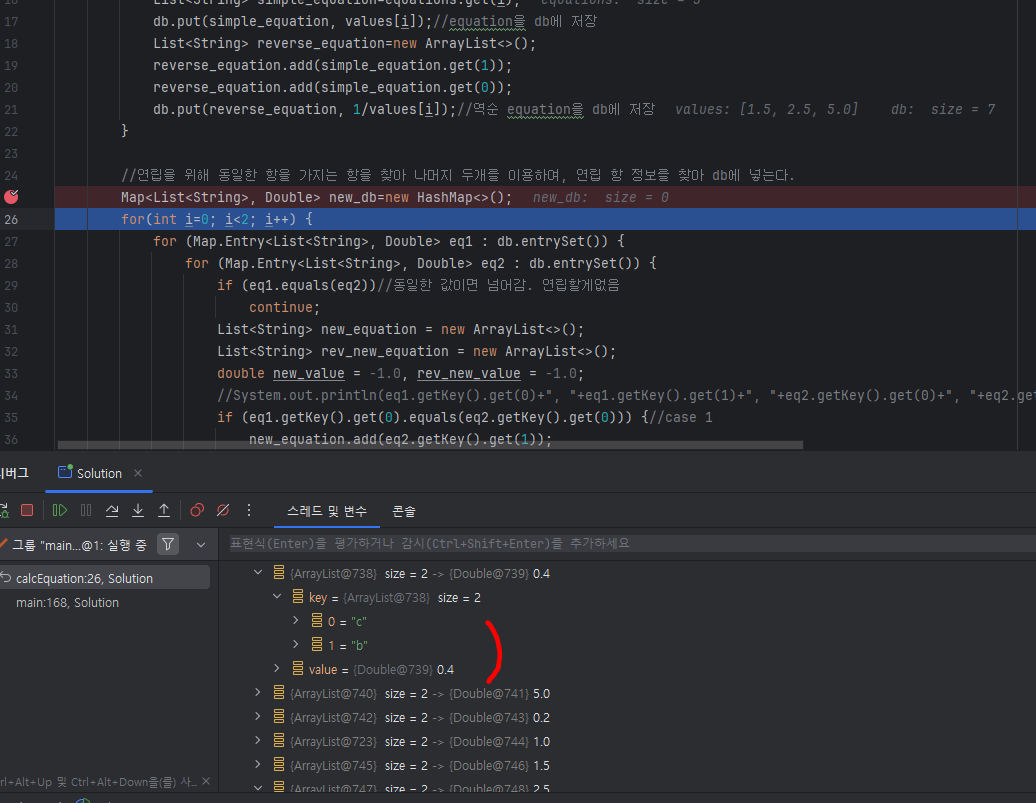
문제는 연립과정에서 발생했는데, 새로이 만들어진 식이 기존에 db에 존재하는 equation이라면 put하지 않게끔 예외처리를 해주자.
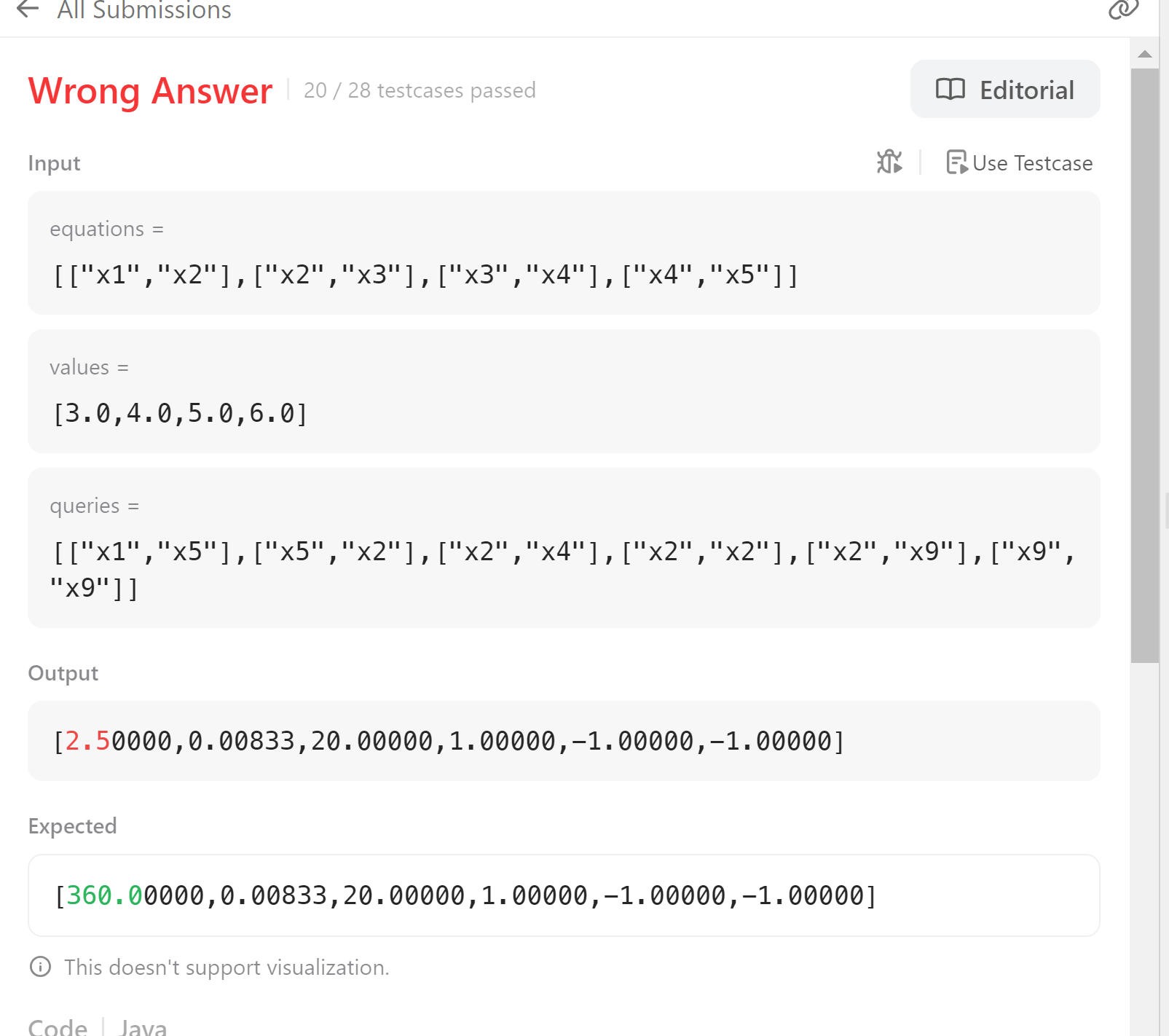
단순 계산 문제가 틀렸다. 이 문제는 위에서 겪었던 문제로 코드를 뒤엎으며 이전의 코드를 가져오며 수정이 누락된 부분이 있었다. case4가지 경우 중 3번째의 값 계산을 *를 /로 잘못되어있었기에 이를 수정했다.
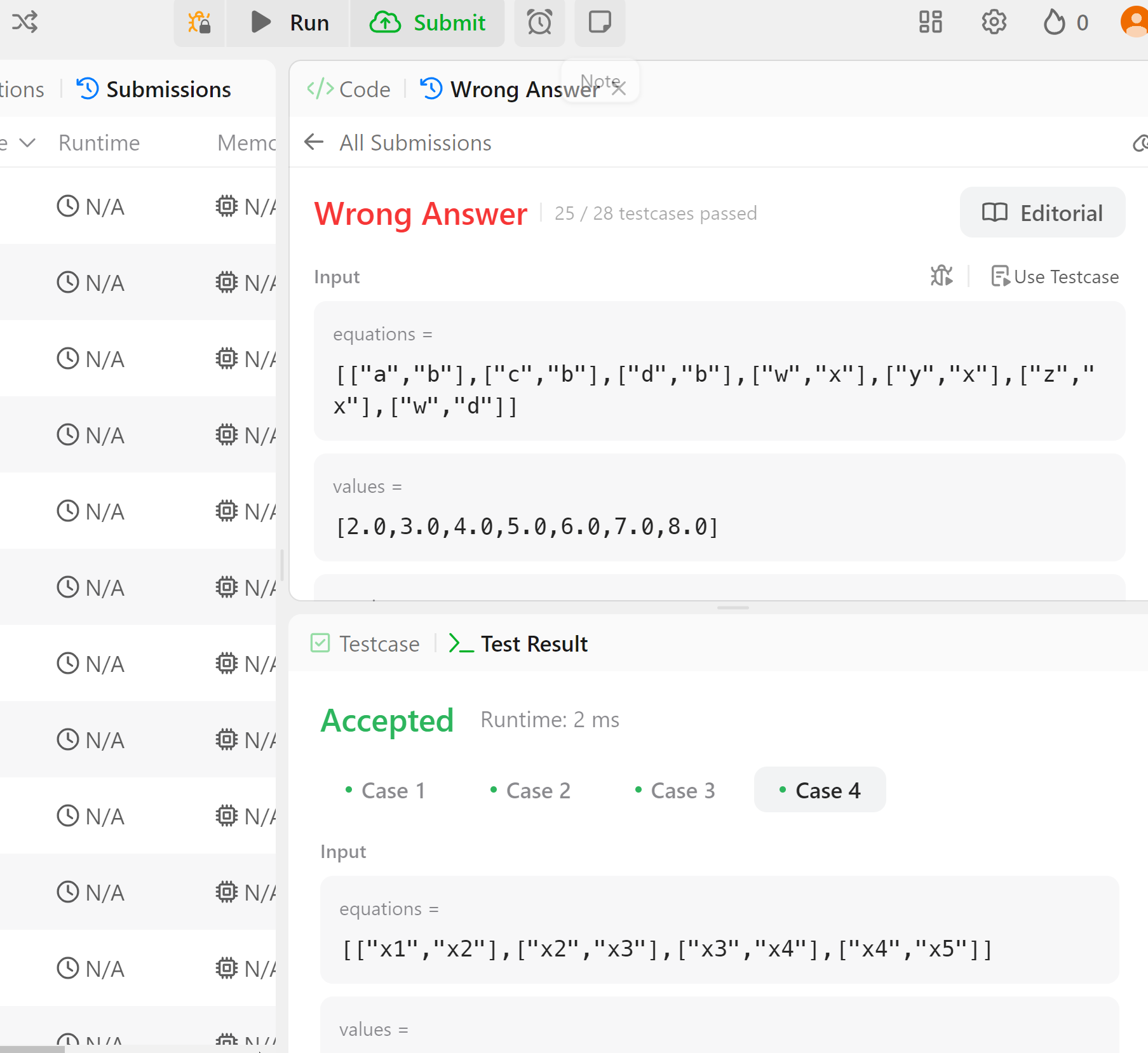
값을 계산할 수 있는데 -1을 리턴하였다. 연립이 부족한 것 같아 횟수를 3회로 늘려주었다.
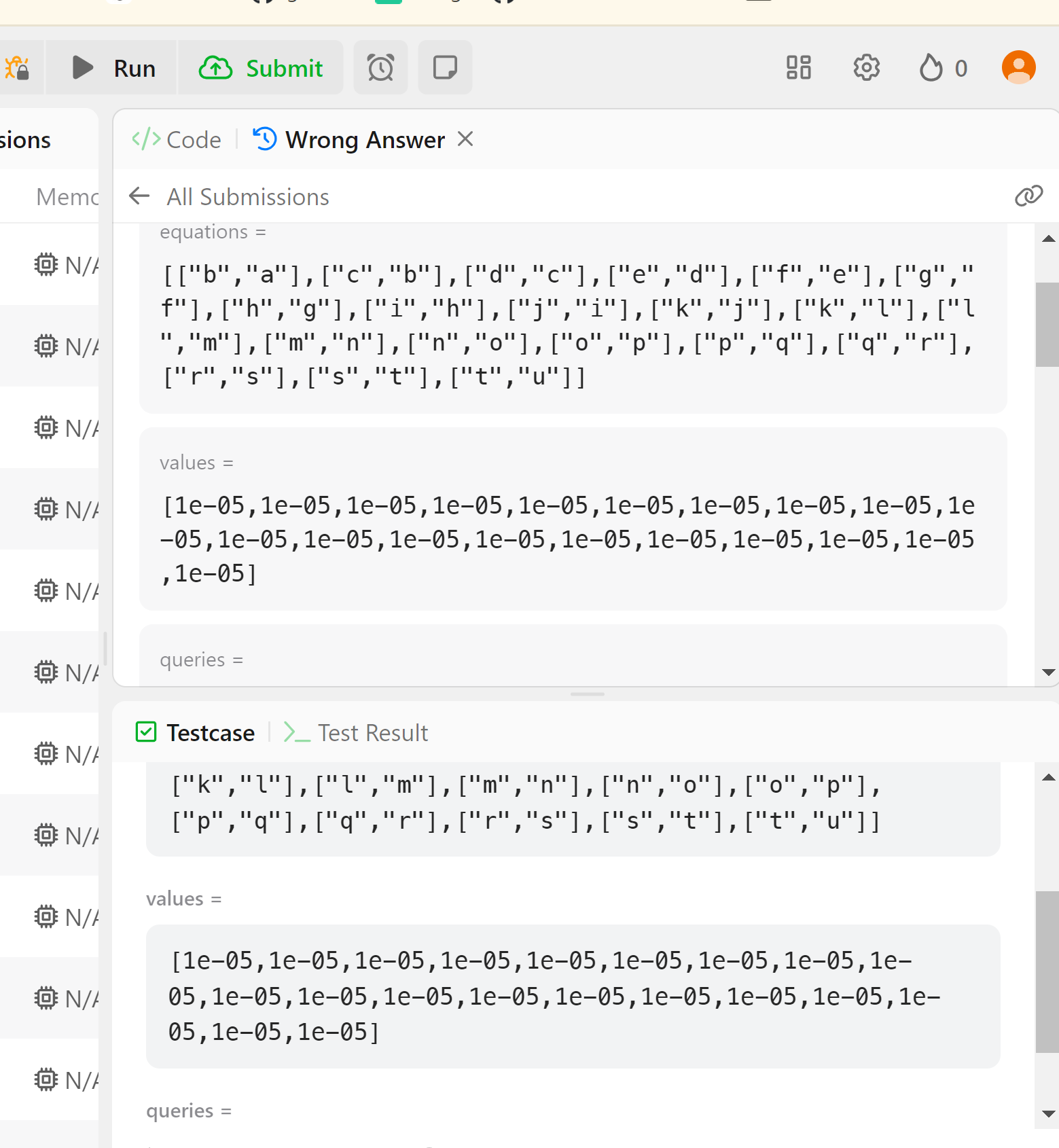
도대체 얼마나 더러워지려고 하는거냐..
연립 횟수를 5회로 늘려주었다.
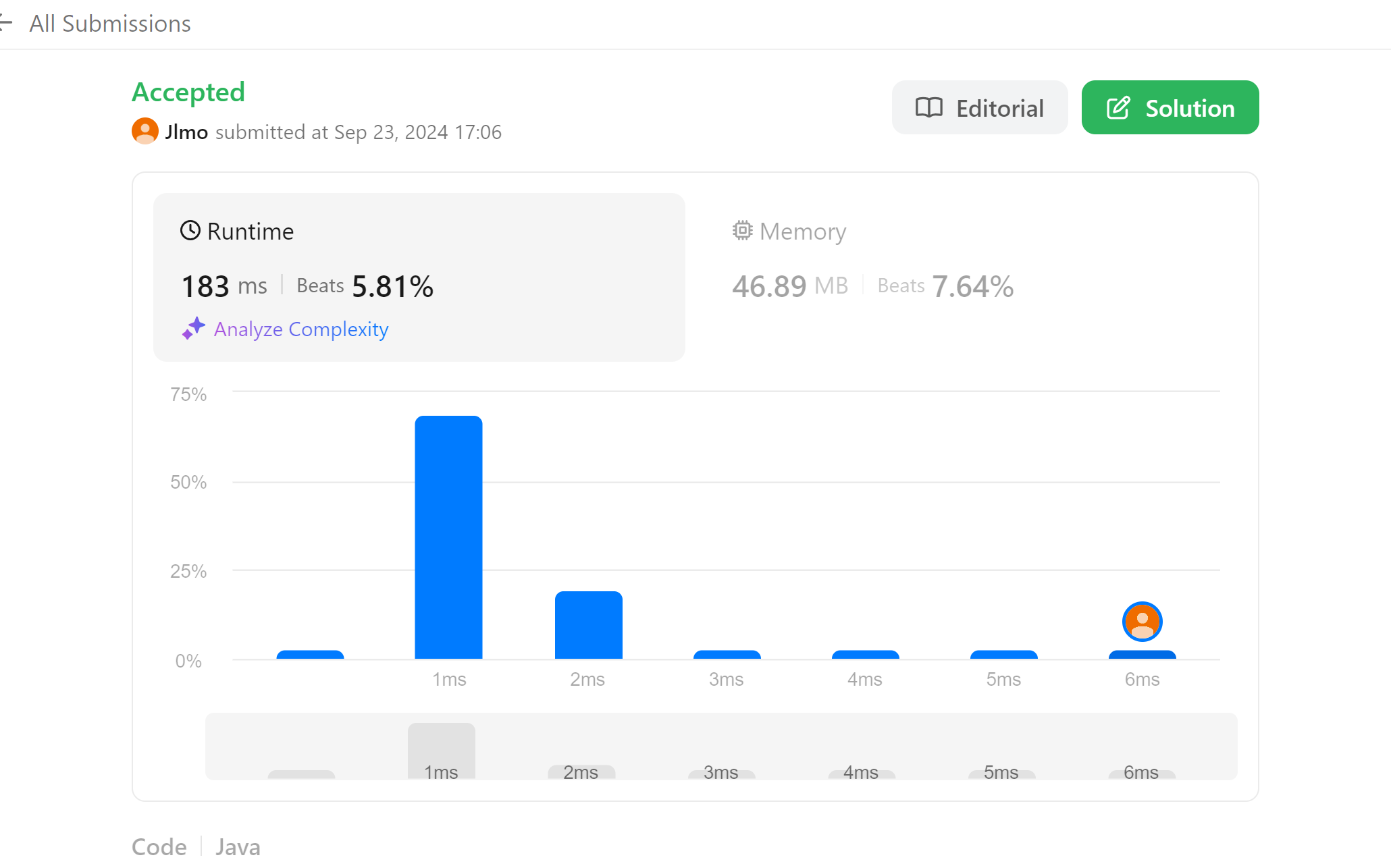
다시 마주하고 싶지 않은 문제지만, 설명이 부족했던거지 문제 케이스 자체의 핸들링은 어렵지 않았다.
조만간 최적화를 진행해야겠다.
(24.09.24)
1차 최적화로 역순을 따로 저장하지 않고 queries처리 부분에 역순을 비교하는 방식으로 바꾸고, db에 있는 a, a와 db에 없는 x, x를 구분하기 위해 used_char를 다시 도입하였다.
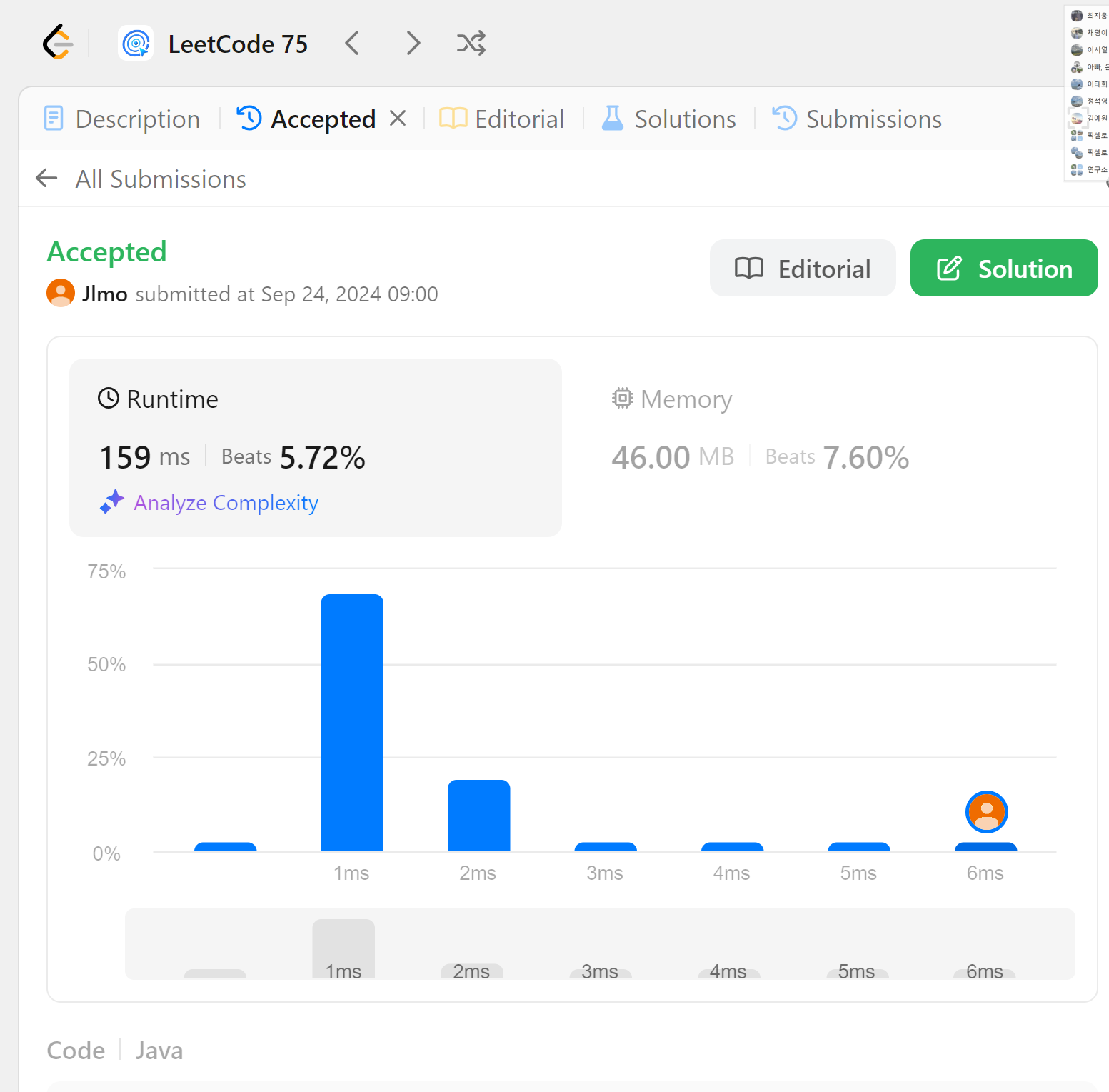
아주 약간의 최적화가 진행되기는 했지만, 드라마틱한 변화는 코드의 로직을 그대로 유지한 것이기에 일어나지 않았다.
(24.09.29)
1ms를 기록한 모범 답안의 코드를 분석해보자.
class Solution {
double ans = -1;
public double[] calcEquation(List<List<String>> equations, double[] values, List<List<String>> queries) {
Map<String, List<Node>> graph = new HashMap<>(); // 2. 특정 문자에 대해 Node리스트를 가지는 Map을 생성한다.
int n = equations.size();
for(int i=0; i<n; ++i){
if(graph.get(equations.get(i).get(0)) == null){// 3. 모든 equation에 대해 첫 원소가 graph에 없다면 추가한다.
graph.put(equations.get(i).get(0), new ArrayList<>());
}
graph.get(equations.get(i).get(0)).add(new Node(equations.get(i).get(1), values[i]));// 4. 첫 원소가 저장된 map의 원소로 두번째 원소와 첫원소/두원소의 값을 Node형태로 저장한다 (따로 계산 없이 문제에서 주어진 조건 그대로 저장_ {elem1, {elem2, val}} 느낌)
if(graph.get(equations.get(i).get(1)) == null){ // 5. 두번째 원소가 graph에 없다면 추가한다.
graph.put(equations.get(i).get(1), new ArrayList<>());
}
graph.get(equations.get(i).get(1)).add(new Node(equations.get(i).get(0), 1/values[i])); // 6. 이전과 순서가 바뀌었으므로 1/val 꼴로 추가해준다. (역순도 추가해준다고 생각하면 될 듯)
}
double[] res = new double[queries.size()];
for(int i=0; i<queries.size(); ++i){ // 7. 구해야할 값인 쿼리값에 대해 DFS를 수행할건데, 기본 원리는 더이상 타고 갈 게 없을 때 까지 dfs를 돌려 연관된 관계들을 하나하나 비교하는 것이다.
ans = -1; //8. 초기화(못찾았을 경우 -1 처리를 해야함)
dfs(graph, queries.get(i).get(0), queries.get(i).get(1), 1, new HashSet<>());// 9. 탐색 대상인 그래프, 첫원소, 두원소, dfs에 사용할 set을 건네준다.
res[i] = ans;
}
return res;
}
private void dfs(Map<String, List<Node>> graph, String s, String target, double value, Set<String> set){
if(graph.get(s) == null || set.contains(s)){ // 10. 이미 방문한 노드이거나, 그래프에 없는 값일 경우 탐색 종료
return;
}
set.add(s); // 11. 방문 처리
if(s.equals(target)){ // 12. 첫 원소와 두 원소가 동일하다면, ans의 값은 value로 대입하고 탐색 종료. 왜냐면 저장할 때 a, {b, v}꼴로 저장했기에 굳이 연산할 필요 없이 쿼리에 있는 a, {b, }에 매칭되는 v를 반환하면 됨.
ans = value;
return;
}
for(Node i:graph.get(s)){// 13. 첫 원소와 두 원소가 다르다면 첫 원소에 대응되는 모든 노드들에 대하여
dfs(graph, i.var, target, value*i.val, set); // 14. dfs를 수행하는데, 이때의 값은 이전의 value와 노드의 value의 곱이다. **핵심**
}
}
class Node {// 1. 문자열 별 값을 저장하는 Node 클래스를 생성한다.
String var;
double val;
public Node(String var, double val){
this.var = var;
this.val = val;
}
}
}전반적인 원리는 equation에 들어온 순서 그대로 a, {b, v}꼴로 저장한다는 점과, query값에 대해 graph를 타고가는 과정에서 dfs를 사용한다는 점이다. 여기서 중요한 핵심 포인트는 Graph를 Map<String, List>꼴로 표현했다는 점이다. 이 모양은 그래프를 전부 표현하지 못하지만 이를 사용하는 과정에서 특정 원소와 연관된 List들을 다시 Graph에서 찾으며 순회한다면, 최소의 공간 복잡도로 그래프를 구현해낼 수 있다.(중복 불가) 또한 나는 a, {b, v} 꼴의 데이터를 a/b=v꼴로 변환하여 직관적으로 코딩한 반면 이 코드에서는 문제에서 주어진 equation 규칙과 구해내야하는 query의 형식(규칙)이 동일하기에 a/b=v꼴로 변환하는 것이 아닌 문제에서 주어진 순서 그대로를 사용했다는 점이 인상깊었다. 이해하고 가독성 높은 코드를 구현해 내는 것은 a/b=v일 지라도 문제를 한단계 더 간단하게 보아 불필요한 연산을 없앤 것이다. 이를 위해 Node 클래스를 설계하였다. 마지막으로 인상깊은 점은 DFS를 다시 수행하는데에 값 계산처리이다.
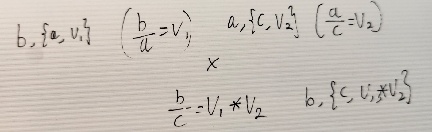
참 잘 짠 코드같다. 최소한의 공간복잡도와 시간복잡도를 위해 Graph를 Node를 리스트로 가지는 Map으로 간단히 구현하고 순회하는 로직으로 완전히 Graph를 구현한 것도 놀라운데, 다음 노드로 넘어갈 때의 값 계산이 군더더기 없이 깔끔하다. 정말 오랜만에 보는 깔끔한 문제같다.
위에 많은 시도들을 수행하며 이 문제를 더럽게 느낀 부분이 정말 많았는데, DFS를 적용하는 관점으로 생각해보니 군더더기 없이 깔끔하게 풀이되는 것이 현대미술을 감상하는 듯한 느낌까지 든다.
