오랜만이다. 문제 이해라도 하자.
(25.03.25)
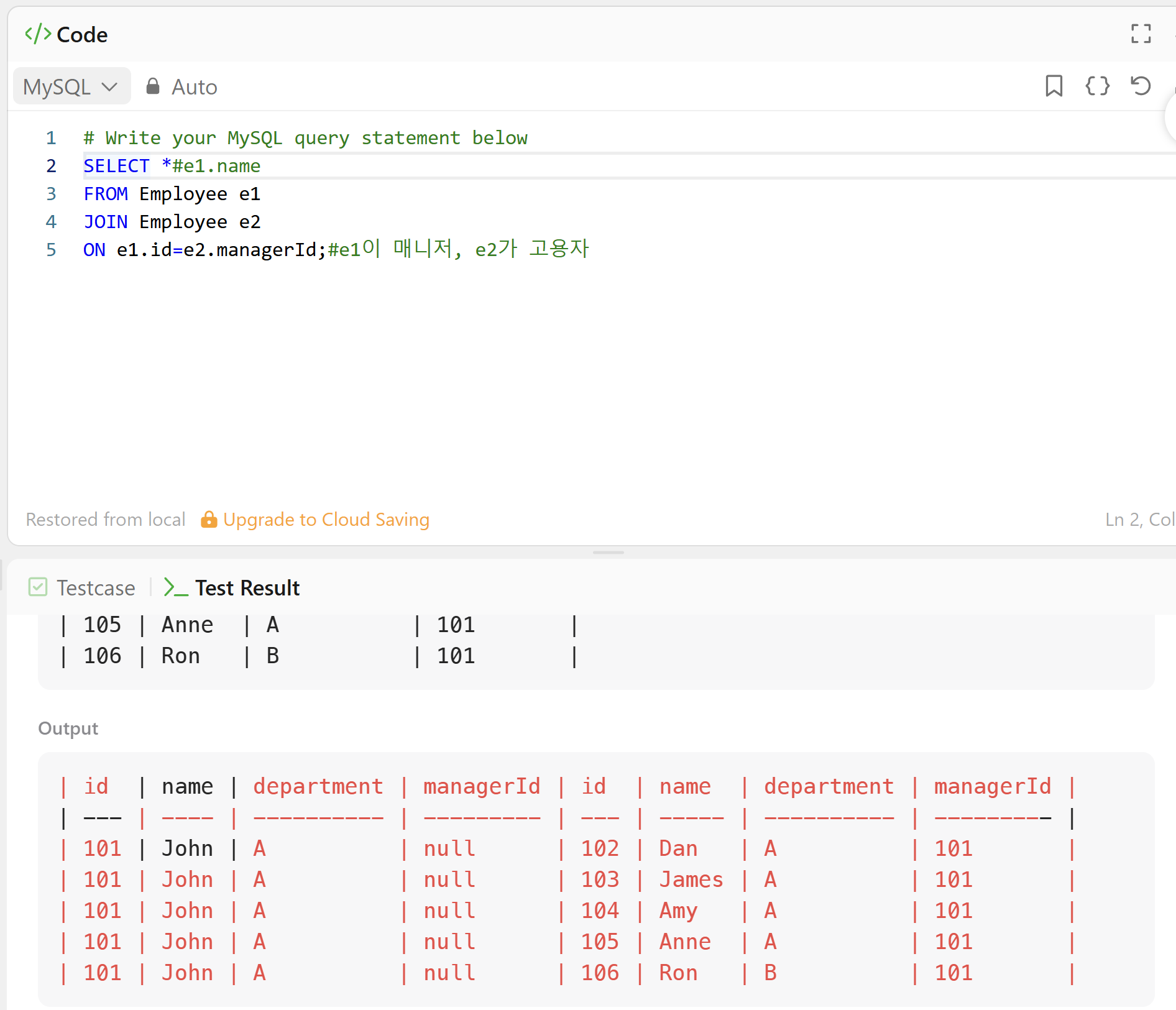
문제 이해
고용자는 매니저가 매칭되는데, 스스로는 자기 자신의 매니저가 될 수 없다.
최소 5방향 보고서를 가지는 매니저를 순서 상관없이 찾아라? 직속 부하가 5명 이상인 매니저 찾기
문제 접근
동등 조인과 id=manager에 해당하게끔 하여 매니저 정보를 뽑은 뒤, GROUP BY를 이용해 COUNT한 수를 WHERE에 이용해야하는데, SELECT문에 사용한 COUNT를 WHERE에 다시 사용할 수가 없어서 고민이다.. 우선 TDD 처럼 매니저가 가지는 직속부하 수를 확인하는 코드 없이 작성해서 제출해보았다.
SELECT e1.name
FROM Employee e1
JOIN Employee e2
ON e1.id=e2.managerId
GROUP BY e1.id;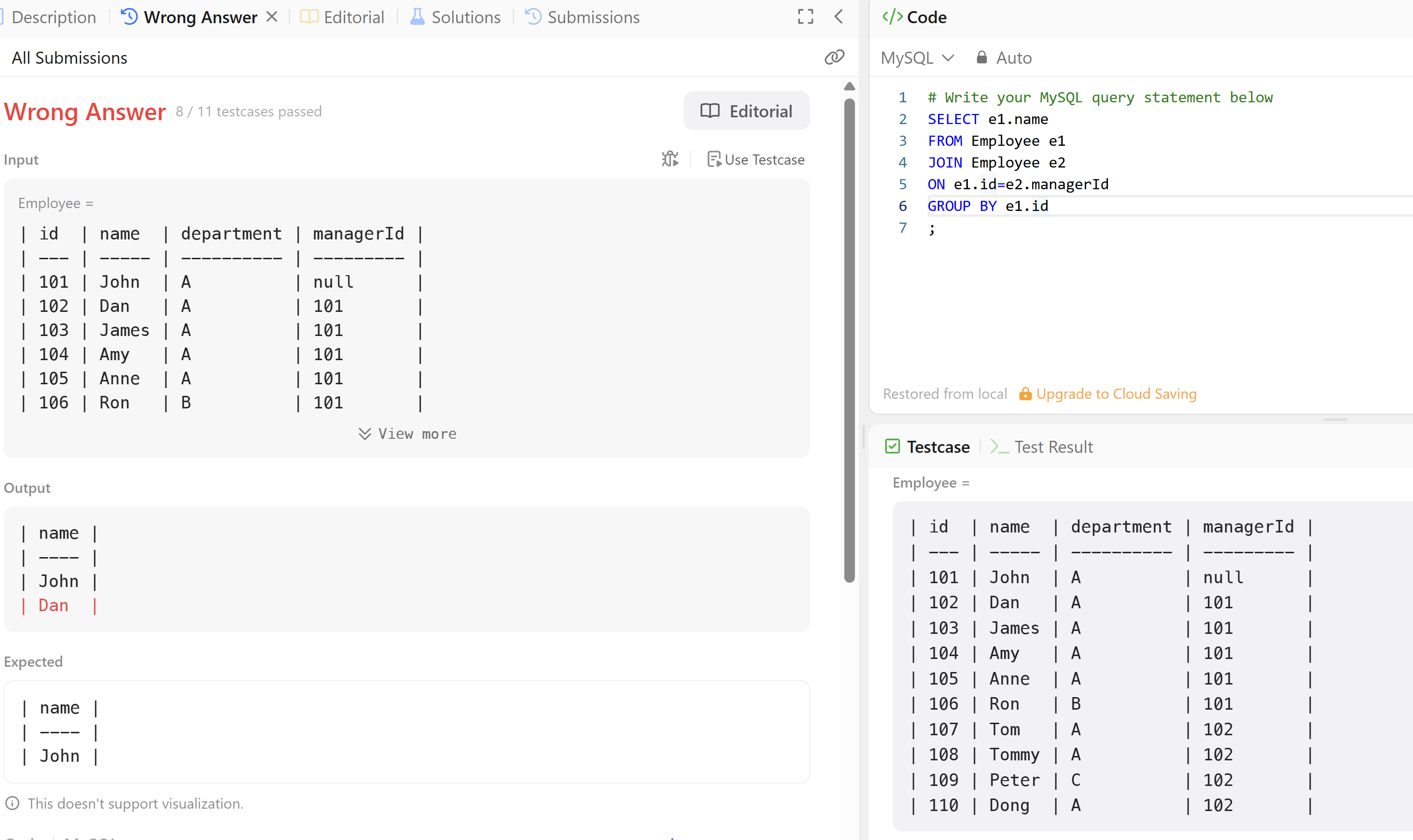
(25.07.09)
최대한 두뇌를 짜내봤다. 그런데 놀랍게도 이전에 한 결과랑 똑같네? 띠버깅만 해보자.
# Write your MySQL query statement below
#대충 관리직원 5명 이상인 매니저의 이름을 뽑아라 같은뎀
#일반적인 WHERE로는 어려워보이는데
#managerId 번호에 따른 매니저 이름과 언급 숫자 COUNT로 테이블을 만들어서 해당 숫자 가 5 이상인거 추출하면 될듯
# 힌트 1에 따라서 5이상 언급된 managerId를 먼저 모아보자.
SELECT name
FROM Employee as e3 JOIN (SELECT e1.id, COUNT(e1.id)
FROM Employee as e1 JOIN Employee as e2
ON e1.id = e2.managerId
GROUP BY e1.id) as e4
ON e3.id=e4.id;보니까 횟수 5 이상인거만 필터링하는 구문을 빠뜨렸다. 어디에 넣으면 좋을까?
# Write your MySQL query statement below
#대충 관리직원 5명 이상인 매니저의 이름을 뽑아라 같은뎀
#일반적인 WHERE로는 어려워보이는데
#managerId 번호에 따른 매니저 이름과 언급 숫자 COUNT로 테이블을 만들어서 해당 숫자 가 5 이상인거 추출하면 될듯
# 힌트 1에 따라서 5이상 언급된 managerId를 먼저 모아보자.
SELECT name
FROM Employee as e3 JOIN (SELECT e1.id, COUNT(e1.id) as num
FROM Employee as e1 JOIN Employee as e2
ON e1.id = e2.managerId
GROUP BY e1.id) as e4
ON e3.id=e4.id
WHERE e4.num>=5
;
조금 코드가 더럽지만 통과하였다. 최적화도 공부해보자.
아래는 GPT를 이용해 최적화한 쿼리이다.
-- 매니저 ID별 부하 직원 수를 세는 서브쿼리 작성
-- 조건: 부하 직원 수가 5명 이상인 경우만 추출
SELECT e1.name
FROM Employee AS e1
JOIN (
SELECT managerId
FROM Employee
WHERE managerId IS NOT NULL -- managerId가 존재하는 경우만 집계
GROUP BY managerId
HAVING COUNT(*) >= 5 -- 부하 직원이 5명 이상인 경우만
) AS sub
ON e1.id = sub.managerId; -- 매니저의 id와 sub쿼리의 managerId 매칭아하 HAVING은 GROUP한거의 조건이었지!
시간은 더 걸렸지만 유의미한 차이는 아닐 듯 하다.

이제 4학년!!!