(25.08.17)
무한문제풀기 오답1회(7문항)
- TOP(3) WITH TIES 이름, 성적 ORDER BY~
- LTRIM은 왼쪽에서만 특정 문자열을 지움. SUBSTR은 index 1부터 셈.
- 주식별자는 엔티티의 개체를 유일하게 식별되며 논리적모델링에서 결정되어야함, 내부식별자는 하나의 엔티티에서만 의미가짐, 인조식별자는 주식별자 대체가능한 인공키
- 복잡한 SQL 선지는 차이점 위주로 소거법. 기본적인 문법조차 지키지 않는 선지가 많음
- 데이터 모델링의 3요소는 Things, Attributes, Relationships
- SELECT (스칼라 서브쿼리) FROM (인라인 뷰) WHERE a.col=(서브쿼리). 큰 의미로 모두 서브쿼리임
- REGEXP_SUBSTR('대상', '규칙', 1, 1, NULL, 4) FROM DUAL에서 (DUAL은 계산 시 임시사용)
(25.08.20)
모의고사(50문제)

- 왜 가능성이 보이냐?????????? 우선 데이터 모델링의 이해는 과락 턱걸이. SQL 기본 및 활용 오답은 내일 진행하는 것으로.
오답 1) 데이터 모델링의 이해
- 성능고려 데이터 모델링의 순서: 정규화->DB용량산정->트랜잭션유형파악->반정규화->조정->검증
- 엔티티 관계 체크사항: 관계연결규칙, 정보조합, 연관규칙
- 롤백은 순서대로(FIFOxFILOo)
- 관계의 가수성(1:1, 1:n)은 관계차수
- 정규화: 원자, 부분키x, 이행적종속x, 다치종속x, 조인종속x
- 속성은 엔티티를 설명하는 구성요소
조인 정리
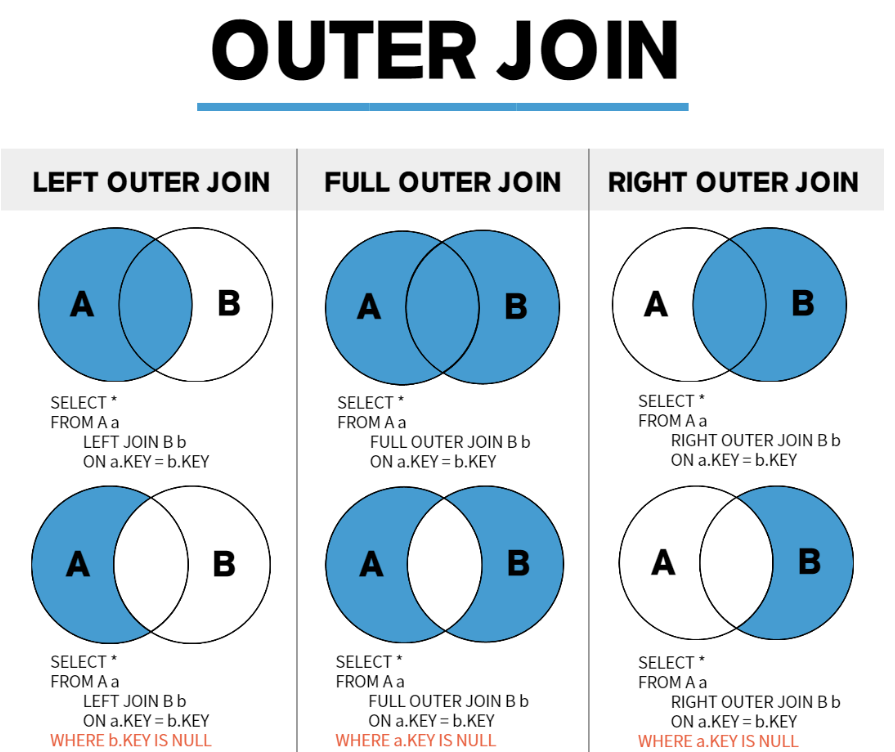

UNION [DISTINCT, ALL] 기본은 중복제거. 수직결합
(25.08.20)
개념보강용
- 집합연산자 INTERSECT는 교집합
(25.08.22)
유튜브 기출문제 풀이 1회
- 식별자 분류: 대표성여부(주,보조) PK?FK?(내부,외부) 단일속성(단일,복합) 대체여부(본질,인조)
- 주식별자 기준: 유일성, 최소성, 불변성, 존재성(꼭 입력 값)
- 반정규화 절차: 대상을 찾고-> (파티셔닝, 인덱스) 다른 방법을 검토-> 반정규화 적용
- ERD 에서 O은 그게 없을 수도 있다!

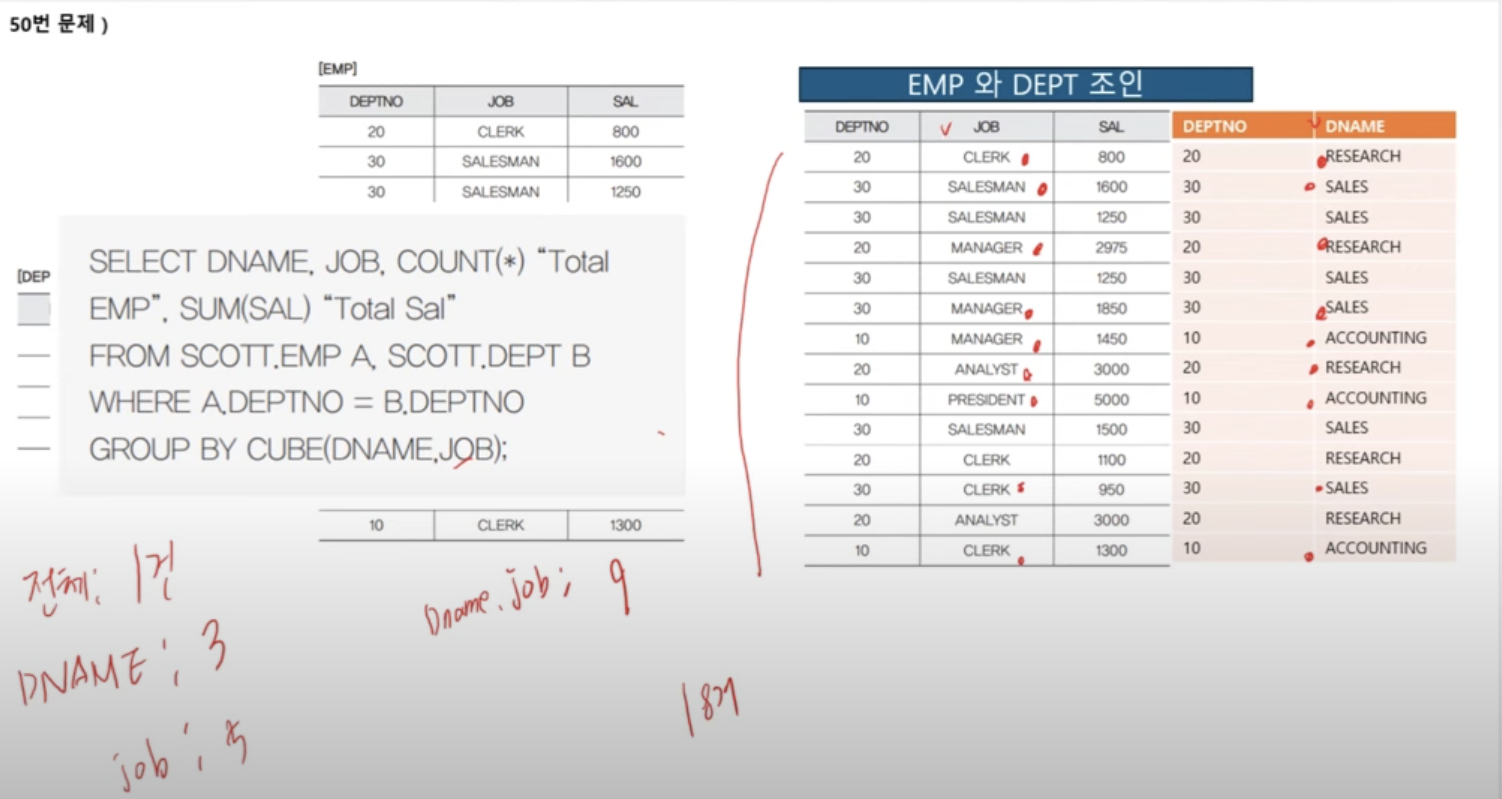
- GROUP BY CUBE(A, B)는 모든그룹바이경우, ROLLUP은 합계&소계. 정렬가능. CUBE가 젤 저성능
- COUNT(*)는 행개수, COUNT(A)는 NULL제외 개수
- 트랜잭션 특징: ACID(Atom, Consis, Isola, Durab)
- left outer join이면 left join하고 left기준 남은거 붙이고 우측 null처리
- RN은 랭크인데 12 113이러면 파티션이 있는거. 기준값이 근처에 있음.
DENSE_RANK는 123 - SAVEPOINT T1은 ROLLBACK TO로 할 수 있으며 변수개념이기에 덮어쓰기 가능
- SQL만 AUTO COMMIT이라 ORACLE은 DML직접커밋해야하는데, SQL AUTO COMMIT을 끄면 전부 직접해야함(원래 DML은 둘 다 자동커밋) == 롤백하면 DML DDL사라짐
- 비슷한 조인에서 같은결과 찾으라고 하면 T1 123 T2 234로 ㄱㄱ
- UNION 기본은 중복제거
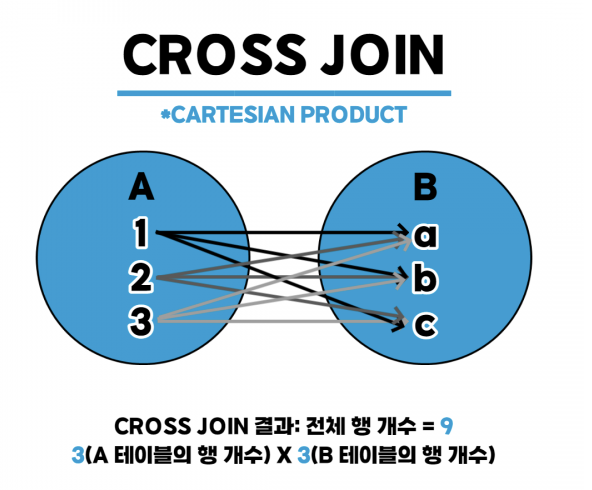
- CROSS JOIN은 조건없이 모든 경우 n*m
- LIKE 문법은 대소문자구문함. K%는 K로 시작(%는 0개이상), K_은 단일자
- 테이블명은 영어랑 _$#만 사용가능
- ROUND(숫자, m)에서 m은 소수점 m자리까지 반올림. 즉 몇자까지 소수표현할지
- INSERT 시 VALUES()에는 모든 값 입력해야함
- DELETE 시 FROM을 생략해도 됨. 그럼 전체 데이터를 지우는 거로 DROP과 다름.
- ORDER BY 시 숫자를 쓰면 SELECT절에 사용한 n번째 데이터 기준 정렬을 의미.
- ORDER BY 시 ORCALE은 NULL을 큰값으로, SQL은 작은값으로 취급. 글자수로 비교하면 될듯
- ORDER BY는 기본 ASC임 (DESC)
- 조인 시 따로 FROM표기 없이 WHERE에 A.N1 BETWEEN B.N1 AND B.N2은 비동등조인으로 그냥 모든 경우의 수(CROSS JOIN)
- AVG 시 NULL은 제외. WHERE에서도 제외.
- SQL 집합연산자 UNION ALL 중복포함합집합, UNION 합집합, MINUS & EXCEPT 차집합, INTERSECT 교집합
- Window Function(SUM, MIN, ..., OVER PARTITION BY == GROUP BY): 튜닝x, 범위지정가능(RANGE & ROWS BETWEEN 여기에 PREc나 Follo는 -n1 ~+n2)
- GROUP BY에 NULL값도 분류함
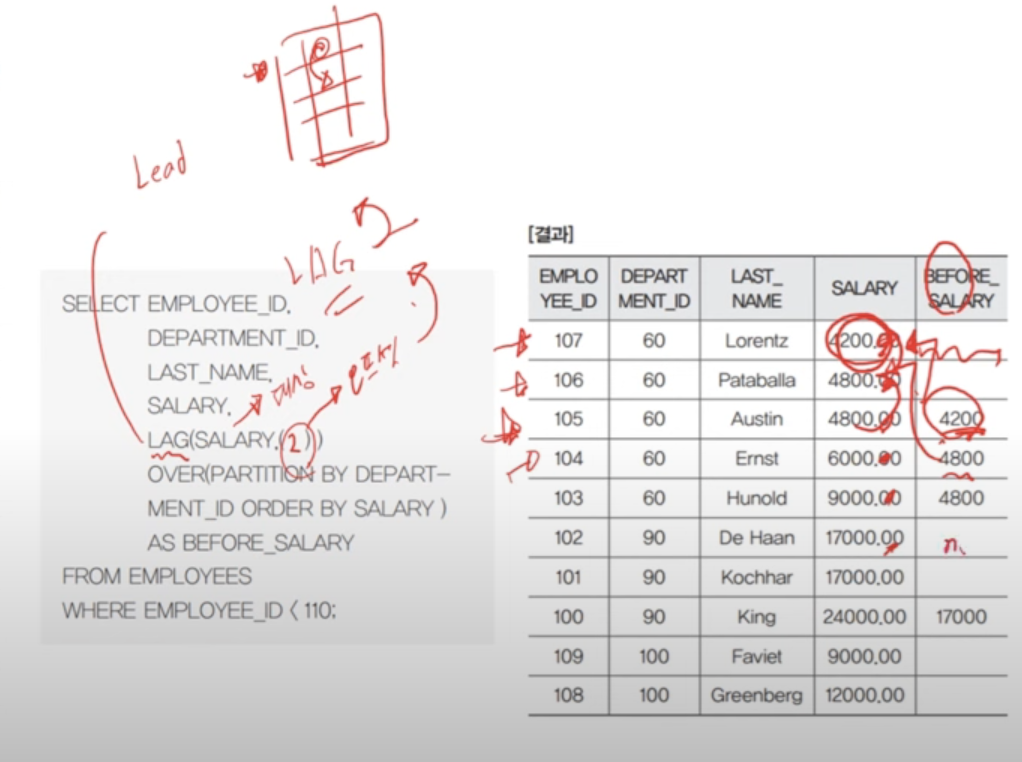
- 윈도우 함수에서 LEAD는 내 위 데이터(default 1), LAG는 내 아래 데이터. 즉 몇칸 shift됐는지 확인하면 됨. 인자 하나 더 주면 null일 떄 넣을거
- 원격조인(GRANT)제거 반정규화기법: 중복테이블 추가(원격없이 그냥 접근하게 복사접근)
- NULL에 계산을 하면 NULL임
- CUBE결과 행수세라고 하면 전체1+단일개수+단일개수+둘단일조합개수
유튜브 기출문제 풀이 2회
- 파티션(논리에 따라 수평분할) RANGE, HASH, LIST(항목 직접 지정)
- 속성의 특징: 기본, 설계(일련번호_인조), 파생(집계)
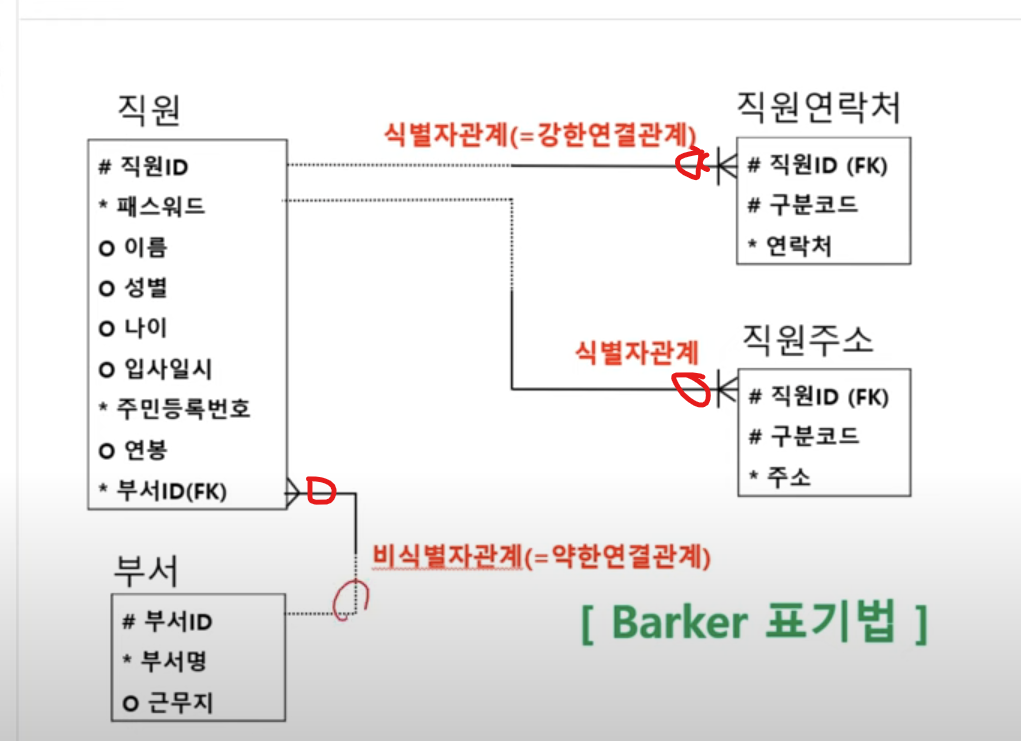
- 비식별관계: 약한연결관계 FK가 PK가 아니라 속성으로 들어갈 떄 점선표현.
- IE표기말고 Barker표기에서는 #이 PK. 그리고 선택인 O표기가 진한선으로 표기(반대쪽은 점선)
- 정규화: 1원자 2부분종속 3이행종속 BCNF결정자제거 4다치종속 5조인속성 - 엔티티 종류: 기본엔터티(고객)<---- 중심엔티티(주문)------>행위엔티티(주문이력)
- 데이터베이스 모델링 단계: 개념(ERD, 추상)->논리(속성,관계, 재사용성, 정규화)->물리(성능, 저장)
- 엔티티는 속성2개이상, 인스턴스2개이상
- 메인쿼리: 젤바깥, (중첩)서브워키: 메인안에 WHERE , 스칼라서브쿼리: 반환1개(avg, SELECT안의 쿼리, order by불가), 인라인 뷰: FROM 뒤(ORDER BY 가능)
- 메인쿼리는 서브쿼리 컬럼 쓸 수 없음. - 다중행 서브쿼리 함수 IN, ANY, ALL, EXISTS
- ORDER BY 뒤 ROLLUP은 뭘 할건지임. CUBE는 4개경우였고 그 중 뭘 할건지.. 같은 내용은 삭제함
- ROLLUP관련해서 꼭 참고. null은 무시. null없으면 전체 포함 9:00~
- SQL 실행순서: FROM WHERE GROUPBY HAVING SELECT ORDERBY
- 오라클은 DDL만 오토커밋. 즉 INSERT하면 commit해야 반영.
- DDL(CREATE, DROP, ALTER, TRUNCATE), DML(SELECT, INSERT, DELETE, UPDATE), DCL(GRANT, REVOKE, COMMIT, ROLLBACK)
- TRANSACTION안에 TRANSACTION이면 두번째껀 무시
- PL/SQL은(Presedure Language)절차적이며 DECLARE CURSOR 변수이름 IS (SQL)

~22:35(11~20)
(25.08.23)
- 상위 4개 뽑는건 오라클으론 WHERE ROWNUM<=4, SQL은 SELECT TOP(4). 여기서 WITH TIES가 들어가면 동점도 같이 뽑아줌. ORDER BY 필수! 기준이 있어야 하니
- REGEX에서 []은 집합 중 아무거나..
- ORDER BY N1 ROWS BETWEEN 1 PRE.. AND 1 FLOW
- SQL은 비절차적언어지만, 프로시저나 PL/SQL같은 경우 절차
- ANSI 표준이 우리가 사용하는거.
여기부턴 이동하면서 보자

이제 4학년!!!