오늘 할일
1. 영상처리 직전공부
2. 인공지능 직전공부
3. 영상처리 교수님 연습문제 풀이 강의 듣기
오늘 한일
1. 영상처리 직전공부
[Chap07. 영역처리]



- 라플라시안, LoG, DoG, Canny방법
12. 2차 미분 연산을 수행하는 함수로 에지 검출을 수행하시오(2가지 함수 이상)
import numpy as np, cv2
image=cv2.imread("images/laplacian.jpg", cv2.IMREAD_GRAYSCALE)
if image is None:
raise Exception("영상파일 일기 오류")
#1. 라플라시안
mask1=[[0,1,0], [1,-4,1], [0,1,0]]
mask2=[[-1,-1,-1], [-1,8,-1], [-1,-1,-1]]
mask1=np.array(mask1, np.int16)
mask2=np.array(mask2, np.int16)
dst1=cv2.filter2D(image, cv2.CV_16S, mask1)
dst2=cv2.filter2D(image, cv2.CV_16S, mask2) #(이미지, 타입, 마스크)
dst3=cv2.Laplacian(image, cv2.CV_16S, 1) #(이미지, 타입, 커널크기)
cv2.imshow("image", image)
cv2.imshow("filter2D 4-direction", cv2.convertScaleAbs(dst1)) #절댓값
cv2.imshow("filter2D 8-direction", cv2.convertScaleAbs(dst2))
cv2.imshow("Laplacian_OpenCV", cv2.convertScaleAbs(dst3))
#2. LoG와 DoG
gaus=cv2.GaussianBlur(image, (7,7), 0, 0) #(이미지, 커널크기, sigmaX(X방향 표준편차), sigmaY) 표준편차 sigmaX까지는 0으로 써줘야함. 필수임
dst4=cv2.Laplacian(gaus, cv2.CV_16S, 7)
gaus1=cv2.GaussianBlur(image, (3,3), 0)
gaus2=cv2.GaussianBlur(image, (9,9), 0)
dst5=gaus1-gaus2
cv2.imshow("LoG", dst4.astype('uint8')) #LoG는 필수로 astype(‘uint8’)해야함
cv2.imshow('DoG', dst5)
#3. 캐니 에지
dst6=cv2.Canny(image, 100, 150) #(이미지, threshold1, threshold2) _for 이력 임계 처리
cv2.imshow("Canny", dst6)
cv2.waitKey(0)- 중앙값 필터링 구현
def median_filter(image, size):
rows, cols = image.shape[:2]
dst = np.zeros((rows, cols), np.uint8)
center = size // 2 #커널 사이즈의 중앙
for i in range(center, rows - center):
for j in range(center, cols – center): #커널 크기를 고려한 각 시작 인덱스
y1, y2 = i - center, i + center + 1 #커널중앙을 빼고 더하고+1(슬라이싱 시 드랍 고려)
x1, x2 = j - center, j + center + 1
mask = image[y1:y2, x1:x2].flatten() #커널에 해당하는 부분만 잘라 flatten
sort_mask = cv2.sort(mask, cv2.SORT_EVERY_COLUMN) #마스크의 모든 열들을 정렬한 뒤
dst[i, j] = sort_mask[sort_mask.size // 2] #마스크 크기의 중간에 위치하는 값을 목표 화소값으로 설정
return dst
med_img = median_filter(noise, 5) #블러링 결과 확인_중앙값 필터링은 노이즈에 강함- morphology함수(erode와 dilate의 차이)
16. 예제_7.4.1과 예제_7.4.2에서 구현한 침식 연산과 팽창 연산 함수 erode()와 dilate()는 소스 내용이 거의 동일하다. 두 함수를 참고하여 하나로 통일해서 morphology() 함수로 구현하시오.
import numpy as np, cv2
def morphology(img, mask, mode):
if mode != 'erode' and mode != 'dilate':
raise Exception("mode is only two 'erode', 'dilate'")
dst = np.zeros(img.shape, np.uint8)
if mask is None: #마스크를 지정하지 않았다면, 3x3크기의 1마스크를 생성(원래 4방향)
mask = np.ones((3, 3), np.uint8)
ycenter, xcenter = np.divmod(mask.shape[:2], 2)[0] #커널 중앙 값을 찾음. np.divmod는 몫과 나머지를 동시에 리턴하는데, 그냥 mask.shape[0]//2, mask.shape[1]//2과 동일함.
mcnt = cv2.countNonZero(mask) # for dilate #마스크에 1값의 개수를 세는 함수
for i in range(ycenter, img.shape[0] - ycenter):
for j in range(xcenter, img.shape[1] - xcenter):
y1, y2 = i - ycenter, i + ycenter + 1
x1, x2 = j - xcenter, j + xcenter + 1
roi = img[y1:y2, x1:x2] #관심 영역을 가져온 뒤
temp = cv2.bitwise_and(roi, mask) #마스킹을 수행
cnt = cv2.countNonZero(temp) #결과에서 관심영역의 1의 개수가
if mode == 'dilate': #(팽창) 마스크와 하나라도 같으면 1(맞는게 하나도 없으면)***
dst[i, j] = 0 if (cnt == 0) else 255
elif mode == 'erode': #(침식) 마스크와 모두 같으면 1(전부 맞았다면)***
dst[i, j] = 255 if (cnt == mcnt) else 0
return dst
image = cv2.imread('images/morph.jpg', cv2.IMREAD_GRAYSCALE)
if image is None:
raise Exception("영상파일 읽기 오류")
data = [0, 1, 0, 1, 1, 1, 0, 1, 0]
mask = np.array(data, np.uint8).reshape(3, 3)
th_img = cv2.threshold(image, 128, 255, cv2.THRESH_BINARY)[1] #모폴로지 연산은 이진화가 필수!!! (이미지, 최소임계값, 최대임계값, 리턴타입)_에서 [1]!!!
dst1 = morphology(th_img, mask, 'erode')
dst2 = morphology(th_img, mask, 'dilate')
cv2.imshow("image", image)
cv2.imshow("binary image", th_img)
cv2.imshow("erode", dst1)
cv2.imshow("dilate", dst2)
cv2.waitKey(0)
cv2.destroyAllWindows()- 차량번호판 인식(블러링->엣지검출->스레솔드(영상 이진화 함수)->모폴로지)
mask = np.ones((5, 17), np.uint8)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) #흑백으로 변환
gray = cv2.blur(gray, (5, 5)) #블러링
gray = cv2.Sobel(gray, cv2.CV_8U, 1, 0, 5) #(이미지, 출력영상데이터타입, x방향 미분차수(1차 혹은 2차..), y방향 미분차수, 커널크기)소벨마스크로 수평수직대각선 엣지검출
#gray = cv2.Canny(gray, 100, 150)#로는 해보니까 너무 엣지검출을 잘해서 차체도 나오네..
th_img = cv2.threshold(gray, 120, 255, cv2.THRESH_BINARY)[1] #영상 이진화
morph = cv2.morphologyEx(th_img, cv2.MORPH_CLOSE, mask) #(이미지, 침식or팽창, 마스크) cv2 모폴로지 연산[Chap08. 기하학처리]



- 평행이동 수행(순사상)
10. 원본 영상에 (50, 60) 좌표만큼 평행이동을 수행하는 프로그램을 작성하시오. 직접 translate()함수를 작성한 결과와 OpenCV 함수를 사용한 결과를 모두 표시하시오.**중요**
import numpy as np
import cv2
def contain(p, shape):
return 0 <= p[0] < shape[0] and 0 <= p[1] < shape[1]
def translate(img, pt): #기준점이 원점임.
dst=np.zeros(img.shape, img.dtype)
for i in range(img.shape[0]):
for j in range(img.shape[1]):
x, y=np.subtract((j,i), pt) #j가 x고 I가 y니까(x는 j. 좌표 순서 주의) 평행이동 수행
if contain((y,x), img.shape): #이미지 형태 안에 속하는 좌표인지(순서주의 y,x순서의 shape임.)
dst[i, j]=img[y, x] #y를 I에(i가 열 인덱스, y는 좌표)
return dst
image=cv2.imread("images/translate.jpg", cv2.IMREAD_GRAYSCALE)
if image is None:
raise Exception("영상파일 읽기 에러")
dst1=translate(image, (50, 60)) #방법 1
rows, cols=image.shape[0:2]
dx, dy=50, 60 #방법 2
matrix=np.float32([[1,0,dx], [0,1,dy]]) #평행이동 시 어파인 행렬_x살리고 y죽이고 dx만큼
dst2=cv2.warpAffine(image, matrix, (cols+dx, rows+dy)) #어파인 적용(원본, 어파인행렬, dsize)
cv2.imshow("image", image)
cv2.imshow("transted to (50, 60) by user function", dst1)
cv2.imshow("transted to (50, 60) by cv2 function", dst2)
cv2.waitKey(0)- 양선형 보간(수식적으로 생각하여 코드작성), 회전변환(라디안 변환, 회전변환_역변환수식, 회전시 중심점 맞추기 위해 평행이동 2번). 이 코드를 명암도영상이 아닌 컬러에서도 돌아가게 하려면 bilinear_value함수에서는 그냥 PT가져올 때 하나하나 접근해서 channel다 가져오고, rotation함수에서는 dst사이즈만 np.zero_list(img)로 맞추면 끝
11. 예제_8.5.1의 rotation() 함수를 이용해서 영상파일을 입력받아서 (100, 100) 좌표를 기준으로 30도 회전하도록 프로그램을 작성하시오.
1) 예제_8.5.1의 rotation() 함수를 이용하여 작성하시오.
2) 어파인 변환 행렬을 이용해서 작성하시오.
import numpy as np, math, cv2
def contain(p, shape): #범위 내에 속하는지
return 0 <= p[0] < shape[0] and 0 <= p[1] < shape[1]
def bilinear_value(img, pt):
x, y=np.int32(pt) #좌표 분해(보간을 원하는 위치)
if x >= img.shape[1]-1: #해당 좌표 기준으로 4개의 점으로 양선형 보간할 것이기에(좌상단, 우상단, 좌하단, 우하단)
x=x-1#여유공간이 있어야함(x+1좌표에 접근할 수 있어야 함)
if y >= img.shape[0]-1:
y=y-1
P1, P2, P3, P4=np.float32(img[y:y+2, x:x+2].flatten()) #좌표와 이미지 접근시 순서 유릐
alpha, beta=pt[1]-y, pt[0]-x #거리비율(P1, P3는 좌상단, 좌하단이기에 y대충 외우자!!! 왜냐하면 지금 부호의 논란이 있는데(실제 계산하면 alpha가 음수임) 근데 이건 상황에 따라 바뀔 수도 있으니 리턴 전에 np.clip(P, 0, 255)로 saturation연산을 통해 값을 정상범위로 해줄거임. 그냥 통일한 순서대로 뺴면 됨.)
M1=P1+alpha*(P3-P1) #중간의 화솟값 계산(1차보간)
M2=P2+alpha*(P4-P2)
P=M1+beta*(M2-M1) #최정의 화솟값 계산(2차보간)
return np.clip(P, 0, 255)
def rotation(img, degree, pt):
dst=np.zeros(img.shape[:2], img.dtype)
radian=(degree/180)*np.pi
sin, cos=np.sin(radian), np.cos(radian)
for i in range(img.shape[0]): #y
for j in range(img.shape[1]): #x임
jj, ii=np.subtract((j,i), pt) #중심 좌표로 평행이동(순사상)
y=-jj*sin+ii*cos #회전변환 적용(왜 역사상 공식이냐??) 몰라 회전 함수는 역사상공식임. -sin을 y가 가짐.
x=jj*cos+ii*sin
x, y=np.add((x,y), pt) #어라라 처음에 뺐던걸 다시 더해주네 아하!! 이거 rotation이 원점기준이 아닌 기준점 기준이니까, 위의 예제랑 달리 원점으로 pt를 원점처럼 취급하기 위해 처음에 subtract를 하고 변환 수행 후 다시 평행이동으로 복구하는거구나
if contain((y, x), img.shape):
dst[i,j]=bilinear_value(img, (x, y))
return dst
image=cv2.imread("images/rotate.jpg", cv2.IMREAD_GRAYSCALE)
if image is None:
raise Exception("영상파일 읽기 에러")
dst1=rotation(image, 30, (100, 100))
center, angle, scale, size=(100, 100), -30, 1, image.shape[::-1] #가장 size구하기 만만한 방법
rotation_matrix=cv2.getRotationMatrix2D(center, angle, scale)
dst2=cv2.warpAffine(image, rotation_matrix, size, cv2.INTER_LINEAR)
cv2.imshow("image", image)
cv2.imshow("rotation by user function", dst1)
cv2.imshow("rotation by cv2 function", dst2)
cv2.waitKey(0)- 직선 기울기만큼 보정(회전)할 때 필요한 기울기계산함수(p.s 도->라디안 공식: degree* (180/pi)
def calc_angle(pt1, pt2):
delta_x=pt2[0]-pt1[0]
delta_y=pt2[1]-pt1[1]
angle=np.arctan2(delta_y, delta_x)*(180/np.pi) #x값의 변위와 y값의 변위로 기울기를 구하는 공식(라디안도 잊지말기 180/pi곱하는거)
return angle- 좌우반전 flip함수(좌우반전은 direction인자가 1일 때이며, [-1, 0, w][0, 1, 0]으로 -x+w, y꼴로 만듬. 즉 y축기준 x값 반전 후 w만큼 평행이동.)
def flip(image, direction):
center = (image.shape[1] // 2, image.shape[0] // 2) #뒤집기를 affine으로 함.
angle = 180
scale = 1
size = image.shape[:2]
h, w = image.shape[:2]
if direction == 0: # 상하반전
flip1 = cv2.getRotationMatrix2D(center, angle, scale) #그냥 180도 회전
print(flip1)
return cv2.warpAffine(image, flip1, size, cv2.INTER_LINEAR) #양선형
elif direction == 1: # 좌우반전
flip2 = np.array([(-1.0, 0.0, w), (0.0, 1.0, 0.0)], dtype=np.float32) #중요! -x+w, y 인데, y축을 기준으로 이미지를 반전(-x)시킨 뒤 평행이동!
print(flip2)
temp = cv2.warpAffine(image, flip2, size, cv2.INTER_LINEAR)
flip3 = np.array([(1.0, 0.0, 0), (0.0, 1.0, 0)], dtype=np.float32)
print(flip3)
return cv2.warpAffine(temp, flip3, size, cv2.INTER_LINEAR)
else:
raise ValueError("direction인자가 잘못되었습니다. 0또는 1이어야합니다.")- draw_bar(img, pt, w, bars)함수 참고
radius = height // 4 #비율 암기?
background = np.ones((height, width, 3), dtype=np.uint8) * 255
def draw_bar(img, pt, w, bars): #이정도만 나올 듯. img위에 pt를 기준으로 폭 w길의의 바를 연속으로 bars개 만든다.
pt=np.array(pt, np.int32) #pt를 int형
for bar in bars: #bar 개수만큼
(x, y), h=pt, w*6 #pt 점에 높이는 폭의 6배로
cv2.rectangle(img, (x, y, w, h), (255, 255 ,255), -1) #꽉찬 사각형
if bar == 0: #만약 끊긴 원을 바란다면 중간에 하얀 사각형을 그려줌
y=y+radius//2-radius//12 #적절히 작은 크기로
x=x
h=radius//12
cv2.rectangle(img, (x,y,w,h), (0,0,0), -1)
pt+=(int(w*1.5), 0)#pt는 w의 0.5배의 간격을 두게끔 1.5배하여 갱신[chap10. 영상분할 및 특징처리]





- 허프변환 전체과정 구현
import numpy as np, cv2
import math
def accumulate(image, rho, theta):#1. 극좌표계 누적행렬구성
h,w=image.shape[:2]
rows, cols=(h+w)*2//rho, int(np.pi/theta)# h는 2*로우맥스/로우, w는 pi/세타
accumulate=np.zeros((rows, cols), np.int32)
sin_cos=[(np.sin(t*theta), np.cos(t*theta)) for t in range(cols)]#모든 cols(세타)에 대한 삼각함수값저장
pts=np.where(image>0)#이미지 중 값이 있는 좌표들을 찾아서
polars=np.dot(sin_cos, pts).T#극좌표계로 변환(허프변환)
polars=(polars/rho+rows/2).astype('int')#해상도 변경 및 위치조정(암기)
for row in polars:#모든 극좌표에 대해서
for t, r in enumerate(row):#t는 현재 theta값, 그에 대한 rho값
accumulate[r, t]+=1#누적은 y축이 rho, x축이 theta
return accumulate
def masking(accumulate, h, w, thersh):#(h, w마스크 크기) 4. 지역 최댓값 선정
rows, cols=accumulate.shape[:2]
dst=np.zeros(accumulate.shape, np.uint32)
for y in range(0, rows, h):#마스킹할거니까 마스크 크기간격으로 접근
for x in range(0, cols, w):
roi=accumulate[y:y+h, x:x+w]#마스킹 영역
_, max, _, (x0, y0)=cv2.minMaxLoc(roi) #min, max, minloc, maxloc을 반환_최댓값 선전
dst[y+y0, x+x0]=max#최댓값 만 대입한다
return dst
def select_lines(acc_dst, rho, theta, thresh):#5. 임계값 이상 직선 선별
rows=acc_dst.shape[0]
r, t=np.where(acc_dst>thresh)#엄청 자주쓰네. 로와 세타를 가져와서 #ㅇㅎ 직선 하나를 로우(수직거리), 세타(각도)로 나타낼 수 있고, 극좌표 누적행렬의 값은 하나의 직선이랬으니 극좌표누적행렬의 값들은 로우와 세타 2개로 나뉘어있는게 맞겠네.
rhos=((r-(rows/2))*rho)#해상도 변경(실제 수직거리 핸드메이드 계산)
radians=t*theta#잘 모르겠는데... 각도를 라디안으로 변환?(실제 세타 핸드메이드 계산)
values=acc_dst[r, t]# acc_dst의 값을 가져와서 #임계를 넘어서는 직선들의 값들을 가져와서
idx=np.argsort(values)[::-1]#긴 직선 순으로 솔트한 인덱스들 #정렬
lines=np.transpose([rhos, radians])#로와 라디안을 전치한 뒤 #로와 라디안을 전치(인덱스로 접근할건데 x,y를 직교좌표계로 변환하는거겠지)
lines=lines[idx, :]#해당하는 직선들을 선별한다...이건 암기해야할듯 ㅠㅠ#직선들을 정렬순서대로 재배치
return np.expand_dims(lines, axis=1) #차원을하나 더 만든 후 리턴
def houghLines(src, rho, theta, thresh):
acc_mat=accumulate(src, rho, theta) #극좌표 누적행렬구성에는 로, 세타가 필요
acc_dst=masking(acc_mat, 7, 3, thresh) #지역최댓값 구하기에는 마스크 사이즈와 임계값 필요
lines=select_lines(acc_dst, rho, theta, thresh) #선정을 위해서는 로우와 세타, 임계값 필요
return lines
def draw_houghLines(src, lines, nline): #설마 내겠어?
dst=cv2.cvtColor(src, cv2.COLOR_GRAY2BGR)
min_length=min(len(lines), nline)
for i in range(min_length): #극좌표를 다시 직교좌표로 바꾸는거이려나
rho, radian=lines[i, 0, 0:2]#수직거리, 각도
a, b=math.cos(radian), math.sin(radian)
pt=(a*rho, b*rho)
delta=(-1000*b, 1000*a)
pt1=np.add(pt, delta).astype('int')
pt2=np.subtract(pt, delta).astype('int')
cv2.line(dst, tuple(pt1), tuple(pt2), (0, 255, 0), 2, cv2.LINE_AA)
return dst
image=cv2.imread("images/hough.jpg", cv2.IMREAD_GRAYSCALE)
if image is None:
raise Exception("영상파일 읽기 에러")
blur=cv2.GaussianBlur(image, (5,5), 2,2) #블러링
canny=cv2.Canny(blur, 100, 200, 5) #엣지 검출(threshold1, threshold2, min_개수)
rho, theta=1, np.pi/180#임의 직선 하나 #기본 로와 세타 세팅은 1과 pi/180
lines1=houghLines(canny, rho, theta, 80)
lines2=cv2.HoughLines(canny, rho, theta, 80)
dst1=draw_houghLines(canny, lines1, 7)
dst2=draw_houghLines(canny, lines2, 7)
cv2.imshow("image", image)
cv2.imshow("canny", canny)
cv2.imshow("detected lines", dst1)
cv2.imshow("detected lines_OpenCV", dst2)
cv2.waitKey(0)- 해리스 코너 검출(응답 함수를 8방향으로 검사?, 참고로 비최대치 억제는 draw_corner함수에서 구현된다.)
12. 예제_10.2.1의 해리스 코너 검출에서 코너 응답 함수를 8방향으로 검사하여 결과를 표시하도록 소스를 수정하시오.
import numpy as np
import cv2
def put_string(frame, text, pt, value, color=(120, 200, 90)):
text += str(value)
shade = (pt[0] + 2, pt[1] + 2)
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(frame, text, shade, font, 0.7, (0, 0, 0), 2)
cv2.putText(frame, text, pt, font, 0.7, color, 2)
def cornerHarris(image, ksize, k): #이미지, 소벨마스크 커널사이즈, k는 0.04~0.06의 상수값
dx=cv2.Sobel(image, cv2.CV_32F, 1, 0, ksize) #수평 소벨 마스크(x방향)
dy=cv2.Sobel(image, cv2.CV_32F, 0, 1, ksize) #수직 수벨 마스크(y방향)
a=cv2.GaussianBlur(dx*dx, (5,5), 0) #dxdx, dydy, dxdy에 대한 가우시안 블러 a, b, c
b=cv2.GaussianBlur(dy*dy, (5,5), 0)
c=cv2.GaussianBlur(dx*dy, (5,5), 0)
corner=(a*b-c**2)-k*(a+b)**2 #코너 응답함수 계산(ab-c^2)-k(a+b)^2
return corner
def drawCorner(corner, image, thresh):
corner=cv2.normalize(corner, 0, 300, cv2.NORM_MINMAX, dtype=cv2.CV_8U)
pts=np.where(corner>thresh)
corners, (h, w)=[], corner.shape
for j, i in np.transpose(pts):
if 1<i<h-1 and 1<j<w-1:#
neighbor=corner[i-1:i+2, j-1:j+2].flatten()
#max=np.max(neighbor[1::2])
max=np.max(np.delete(neighbor, neighbor.size//2)) # 8방향!!
if corner[i, j]>=max:
corners.append((j,i))
for pt in corners:
cv2.circle(image, pt, 3, (0,230,0), -1)
print("임계값: %2d, 코너 개수: %2d"%(thresh, len(corners)))
return image
def onCornerHarris(thresh):
img1=drawCorner(corner1, np.copy(image), thresh)
img2=drawCorner(corner2, np.copy(image), thresh)
put_string(img1, "User", (10, 30), "")
put_string(img2, "OpenCV", (10, 30), "")
dst=cv2.repeat(img1, 1, 2)
dst[:, img1.shape[1]:, :]=img2
cv2.imshow("harris detect", dst)
image=cv2.imread("images/harris.jpg", cv2.IMREAD_COLOR)
if image is None:
raise Exception("영상파일 읽기 에러")
blockSize=4
apertureSize=3
k=0.04
thresh=2
gray=cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
corner1=cornerHarris(gray, apertureSize, k)
corner2=cv2.cornerHarris(gray, blockSize, apertureSize, k)
onCornerHarris(thresh)
cv2.createTrackbar("Thresh- place_middle함수(숫자를 가운데정렬)
def place_middle(number, new_size):
h, w = number.shape[:2] #이미지 크기
big = max(h, 1) #가능한 사이즈는 최소 1
square = np.full((big, big), 255, np.float32) #정사각형 제작(흰색)
dx, dy = np.subtract(big, (w, h)) // 2 #원하는 사이즈와 원래 사이즈의 차이 //2 구하기(옮겨야하는 너비)
#dx, dy = (big-w)//2, (big-h)//2
square[dy:dy + h, dx:dx + w] = number #원하는 위치에 number를 넣음
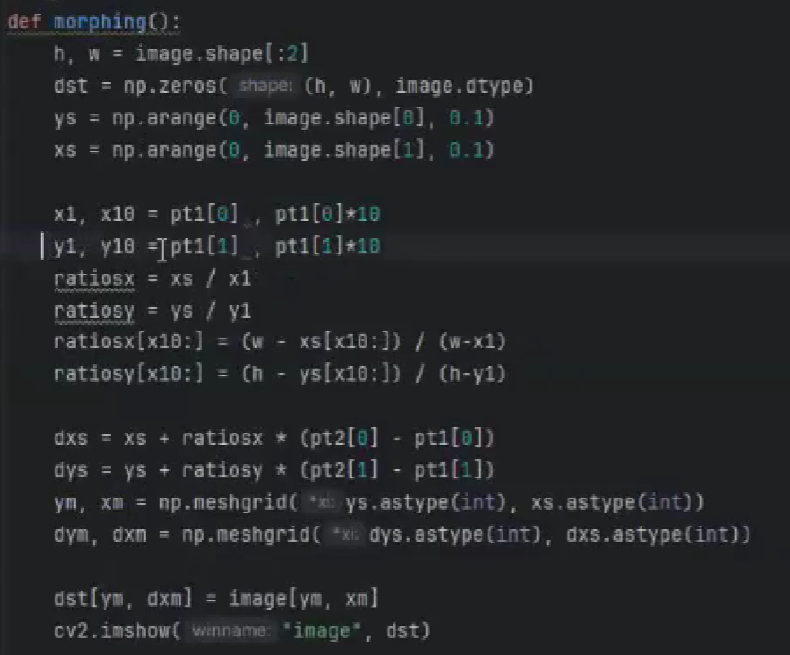
return cv2.resize(square, new_size).flatten() #square를 새로운 사이즈로 resize(확대가능)한 후 일렬로 반환(ML을 위해)- morphing함수 구현_중요 시험 문제는 아래가 실행되긴하는데 예제랑 조금 다르게 짠거라 깨지는 거를 해결해볼 시도를 못해서 교수님의 아래 강의 사진으로 대체. 그다음 깨지는 거 수정하라고 하면 그냥 0.01로만 바꾸고 *100으로만 수정하자.
def morphing():
h, w = image.shape[:2]
dst = np.zeros((h, w), image.dtype)
ys = np.arange(0, h, 1)
xs = np.arange(0, w, 1)
#x1 = pt1[0]
#x2 = pt2[0]
y1=pt1[1]
y2=pt2[1]
#ratios = xs / x1
#ratios[x1:] = (w - xs[x1:]) / (w - x1)
ratios=ys/y1
ratios[y1:]=(h-ys[y1:])/(h-y1)
#dxs = xs + ratios * (x2 - x1)
#dxs = np.clip(dxs, 0, w-1).astype(int) # Ensuring indices are within bounds
dys=ys+ratios*(y2-y1)
dys=np.clip(dys, 0, h-1).astype(int)
#ym, xm = np.meshgrid(ys, xs)
#_, dxm = np.meshgrid(ys, dxs)
xm, ym=np.meshgrid(xs, ys)
_, dym=np.meshgrid(xs, dys)
#dst[ym, dxm] = image[ym, xm]
dst[dym, xm]=image[ym, xm]
cv2.imshow("image", dst)10장 마지막 문제? 워핑을 너무 크게하면(크게 옮기면) 늘려진 부분이 일부 직선으로 깨져서 보이는데, 10.4.1의 13번째 줄 pt2[0]-pt[0]이 너무 커서 발생하는 현상이다. 이를 해결하기 위한 한가지 임시방편 방법은, 7번째 줄의 0.1(계산 때문에 했었음)을 0.01로 바꾸고 9번째 줄(x10에 *100을 곱)하면 줄은 안생긴다...?라는데 그냥 1로 해서 해결했다만... 한번실행해봐야겠네 ㅠㅠ
- 인공지능 개론
[Chap 07. MLP와 케라스 라이브러리]
*1. 경사하강법: 주어진 손실함수의 최솟값을 찾기 위해서 사용되는 최적화 알고리즘이다. w=w-lr*grad 옵티마이저 알고리즘이다.
2. 문제는 local minimum의 존재인데, 이를 optimizer(Adam, momentom)이 존재한다.
Regression(MSE), Classification(Binary Categorical cross_entropy, Spatial Categorical cross_entropy, softmax_활성화함수임)등의 손실함수만 알자.
3. 정리 (손실함수, 출력층 활성화함수, 출력층 개수)
*ㄴ회귀(MSE, X, , 1)
ㄴ이진분류(binary_crossentropy, sigmoid, 2),
ㄴ다중분류(categorical_crossentropy, softmax, class)
4. 몇개의 샘플을 처리한 뒤에 가중치를 업데이트 할 것인가?
ㄴ풀 배치 학습: 모든 훈련 샘플을 처리한 후에 가중치를 변경_자원을 많이 사용함(시간, 저장)
ㄴ온라인 학습(확률적 경사 하강법): 훈련 샘플 중에서 무작위로 하나를 골라 학습을 수행_잡음에 취약해짐
ㄴ미니배치 학습: 훈련 샘플을 작은 배치들로 분리시킨 후에, 하나의 배치가 끝날 때마다 학습을 수행한다._둘의 장점을 갖춰 빠르고 효율적이며 정확함
5. 하이퍼 매개변수: 개발자가 모델에 대해 임의로 결정하는 값(은닉층 수, 유닛의 수(출력층 개수), 학습률, 배치사이즈)_그리드 검색을 사용해서 최적값 찾음
6. 활성화 함수 시그모이드와 계단함수의 차이점은 미분가능성
7. 하이퍼파라미터 튜닝: 라이브러리 기본값, 수동검색, *그리드검색(변경하며 성능 측정), 랜덤 검색
[Chap 08. 심층 신경망]
1. 은닉층 앞단은 경계선(엣지)같은 저급 특징들을 추출하고, 뒷단은 코너와 같은 고급 특징들을 추출한다.
2. 기존의 sigmoid는 은닉층이 많을 때 아주 큰 양수나 음수가 입력되면, 출력이 포화되어 기울기가 0에 수렴하는 Gradient Vanishing문제가 있다. 이는 가중치와 바이어스 값이 효과적으로 업데이트 되지 못하는 문제이다. 이를 "일부" 해결하기 위해 ReLU(y=max(0,x)를 사용할 수 있다.
3. Softmax함수는 max함수의 소프트한 버전으로, 출력은 전적으로 최대 입력값에 의해 결정된다. 큰수는 더 커지고 작은수는 더 작아지는데 0.0~1.0의 확률값
*4. Cross-Entropy함수는 2개의 확률분포간의 거리를 측정하는 손실함수이다.
**5. 옵티마이저: 손실을 최소화하도록 학습을 수행하는 최적화 알고리즘
6. 가중치 초기화 시 0으로 주면 오차의 역전파가 되지 않고, 동일하게 설정하면 역전파 과정에서 같은 값으로 업데이트 되기에 균형 깨뜨리기가 중요하다.
고로 랜덤값으로 결정한다.
7. 범주형 데이터는 "female"등을 의미하며, 인코딩(정수, 원-핫, 워드임베딩)등이 필요하다.
**8. 언더피팅 방지: 데이터 증강 / 오버피팅 방지: 조기종료(손실증가시 조기종료하여 노이즈 학습 전에 멈춤), 가중치 규제(가중치 감쇠_손실함수에 가중치 절댓값만큼 비용 추가), 드롭아웃
9. DNN 심층신경망과 MLP 멀티레이어퍼셉트론의 차이점은 특징 추출 자체도 학습으로 진행한다는 것이다.
***10. 앙상블: N개의 동일한 딥러닝 신경망을 독립적으로 학습시킨 후에 마지막에 합친다. 성능을 분산시켜 과적합을 방지하고, 성능을 향상시킨다.**시험**
11. 과잉적합: 지나치게 훈련 데이터에 특화되어 일반화 성능이 떨어지는 것 / 과소적합: 신경망 모델이 너무 단순하거나, 규제가 많아 충분히 훈련되지 않는 것이다.(적절한 패턴을 학습하지 못함)
**12. DNN의 입력값은 -1.0과 1.0사이의 값으로 범위를 제한하는 데이터 정규화를 통해, 신경망이 각 입력 노드에 대한 최적의 매개변수를 빨리 습득하게 한다.
**11. L1 norm(가중치를 0으로), L2 norm(가중치를 0에 가깝게) 가중치 값이 너무 크면 판단이 어려워 지기에 가중치 값을 의도적으로 줄인다. ***시험***
13. 함수형 API는 Input과 Model이용하는거만 기억하면 쉬움
input=Input(shape=(8,))
hidden1=Dense(32, activation='relu')(inputs)
output=Dense(1, activation='relu')(hidden1)
model=Model(inputs=input, outputs=output)
[Chap 09. 컨볼루션 신경망]
1. 컨볼루션 신경망 유닛사이 연결패턴: 허벨 위젤이 시각피질에서 단순세포와 복합세포를 발견
2. 컨볼루션을 수행하면 영상의 어떤 특징을 뽑아낼 수 있기에 컨볼루션 수행 결과를 특징맵이라고 부른다. 필터를 미리 만드는게 아니라는게 기존 영상처리와의 차이점이다.
*2. 영상에 필터값을 곱하고 더해서 중앙값을 저장. 만약 ReLU까지 적용해야하면 음수인 경우엔 0으로
3. Stride가 k이면 출력은 1/k로 줄어듬.
4. 패딩은 가장자리에 커널을 적용하기 위해서 0이나 이웃 픽셀값으로 채우는 것을 의미. 이때 stride가 1이면 입출력 영상의 크기가 동일하다.
*5. 입력 6x6x3(컬러), stride=1, 필터크기 3x3x3, 필터개수 2개일 때 출력 특징 맵은? 4x4x2(마지막은 그냥 커널개수 따라서. 입력영상의 가로세로만 고려)
**6. 서브 샘플링(풀링)은 컨볼루션 연산 수행 직후에 두기도 하는데, 입력 데이터를 요약하여 크기를 줄이는 연산이다. 입력 데이터의 깊이(채널)은 변하지 않는다. 레이어의 크기가 작아져 계산이 빨라져 매개변수가 작아지기에 과잉적합을 방지하고, 물체의 공간이동에 대해 둔감해지게 한다.(이동해도 같은결과)
풀링레이어는 가중치가 없는 일반 연산이다! **웬만해서 크기 구하는거는 직접 그림그려서 해보자!!** **시험_풀링의 장점 3개_빠르고 오버피팅방지 공간이동(영상처리 용어로는 평행이동-불변)**
7. 윈도우 크기만큼 잘라서 주식 훈련 샘플 만들기
def make_sample(data, window): #윈도우 크기
train=[]
target=[]
for i in range(len(data)-window):
train.append(data[i:i+window])
target.append(data[i+window])
return np.array(train), np.array(target)
8. CNN 마지막엔 Dense레이어 2개를 보통 둔다.
9. 1DConv는 sliding_window느낌, 3DConv는 커널이 정육면체.
10.
def split_sequence(sequence, n_steps): #n_steps는 커널사이즈(1D Conv네).
X, y=list(), list()
for i in range(len(sequence)):
end_ix=i+n_steps
if end_ix>len(sequence)-1:
break
seq_x, seq_y=sequence[i:end_ix], sequence[end_ix]
X.append(seq_x)
y.append(seq_y)
return array(X), array(y)
*11. Conv신경망에서는 하위 레이어의 유닛(입력)들과 상위 레이어의 유닛(출력)들이 부분적으로 연결되어(커널사이즈만큼만) 있기에 복잡도가 낮아지고 과대적합에 빠지지 않는다.
12. 동물 시각 세포에서 받은 영감은, 시각 피질 뉴런들은 한정된 시야만을 보고, 부분적으로 겹치는 시야를 가진다는 것
[Chap10. 영상인식]
1. 전이학습: 하나의 문제에 대해 학습한 신경망의 모델과 가중치를, 새로운 문제에 적용하는 것_높은 정확도를 순식간에 얻을 수 있다. **시험**
*2. 전이학습과 파인튜닝의 차이점: 전이학습은 사전모델의 가중치 동결, 분류기를 추가하여 학습시킨다. 파인튜닝은 사전모델의 가중치를 고정하지 않고 일부 혹은 전체를 재학습하는 방법이다. 전이학습은 사전학습된 모델의 일반적인 특징을 사용해 새로운 작업에 빠르게 적용하는 것이 목적이고, 파인튜닝은 새로운 데이터셋에 대해 모델의 성능을 최적화하는 것이 목적이다.
*3. 전이학습이 가능한 이유: 모델의 앞부분에서는 일반적인 특징을 추출하고 뒷부분은 구체적인 특징을 추출하기에 일반적인 특성을 추출하는 데에 사용할 수있다.
4. 가중치 저장 시 저장되는 정보: 모델 아키텍처 구성, 가중치값, 모델컴파일정보, 옵티마이저와 현재상태
[Chap11. 순환 신경망]
순환신경망 쓰는 이유와 RNN CNN차이점(수식안냄), LSTM차이점, LSTM의 삭제 출력 입력 게이트 각각의 역활
1. 시간적인, 공간적인 순서가 있는 시계열(순차) 데이터에 표준 신경망를 사용하면 멀리 떨어진 과거의 데이터를 잘 기억하지 못하는 단점이 있다.
2. 피드 포워드 신경망: 데이터가 입력층에서 출력층으로만 전달되는 신경망. 정해진 길이의 입력밖에 받지 못한다는 단점이 있다.(ex 두단어만으로 다음단어)
3. 순환신경망의 기능: 가변길이입력, 장기의존성, 순서정보유지, 시퀀스전체의 파라미터 공유
*ㄴ이전의 피드 포워드 신경망은 입력에 의해서만 출력이 결정된 반면, 순환신경망은 입력과 이전의 상태를 함께 고려한다.
4. RNN의 한계: 기울기 소실로 인해 장기문맥을 기억하지 못한다.(장기 의존성 문제) 근거리 의존관계만 중시하게 된다. 역전파가 복잡해진다(이전상태고려)
5. LSTM의 구성: 새로운 입력을 조정하는 입력게이트, 어떤 정보를 출력시킬지(다음 은닉상태 결정) 결정하는 출력 게이트, 이전 시점의 입력을 얼마나 기억할 것인지를 결정하는삭제게이트로 구성된다.
6. RNN과 LSTM의 차이: RNN은 기울기 소실로 인해 비교적 근거리 상관관계만 고려하는 반면, LSTM은 장기의존성을 구현하여 긴 길이의 시계열 데이터를 처리할 수 있다.
[강조]
1. 손실함수: MSE(평균제곱오차), BinaryCrossentropy(이진 정답레이블과 예측레이블간 교차엔트로피 손실계산), CategoricalCrossentropy(여러 레이블 분류, 정답레이블은 원-핫 인코딩), SparseCategoricalCrossentropy(여러 레이블, 정답 레이블 정수인코딩)
2. 하이퍼 파라미터 튜닝이유: 모델의 구조와 기능을 직접 제어하여 최적의 결과를 위한 모델의 성능을 조정하기 위하여.
3. 기울기 폭주: 기울기가 점차 커지며 비정상적으로 커지는 것. 그래디언트 클리핑(임계치), 배치 정규화 등으로 해소
4. 원-핫 인코딩 이유: 레이블간 연관관계를 없애 독립적으로 손실을 계산하기 위함
5. 오비피팅방지: 드롭아웃, 가중치 규제, 조기종료, 데이터 증강?
6. 데이터 증강 이유: 소량의 훈련 데이터에서 다양한 훈련 데이터를 뽑아내기 위함. 데이터를 구하기 어려운 경우에 사용.
7. Conv와 Dense의 차이점은 인접한 값들간의 연관관계를 모두 고려한다는 것. MNIST를 flatten하면 위아래 인접픽셀의 관계표현 불가.\
*8. 영상처리와 CNN의 차이점: 필터의 값이 (라플라시안 엣지..) 결정되어 있어 어떤 특징을 추출하는지 알 수 있지만, CNN은 백지상태에서 출발하여 어떤 특징을 추출하는지 알 수 없다. **시험**
9. 패딩이 필요한 이유는 Conv시 가장자리의 픽셀의 값을 제대로 계산할 수 없기 때문이다.
10. 케라스 사용방법: 함수형, 시퀀스, 클래스
11. 풀링 역활 2가지: 매개변수 감소로 인한 계산속도 증가, 평행이동-불변
12. RNN CNN 차이점은 순서가 있는 데이터, 없는 데이터
13. RNN LSTM차이점은 근거리 의존관계를 중시, 장기의존성 구현(짧은 시계열 데이터 처리, 긴 시계열 데이터 처리)

이제 4학년!!!