🔥SQL 코드카타(1-10번)
파이썬 공부하면서 SQL을 차츰차츰 잊어가고 있는 듯하여
다시 SQL 코드카타 문제와 함께 sql 개념을 복습하기로 했다.
Level 1 (복습)
1번 문제 - 이름이 있는 동물의 아이디
출처 : https://school.programmers.co.kr/learn/courses/30/lessons/59407
풀이 : 동물 보호소에 들어온 동물 중 이름이 있는 동물의 ID를 조회하고 ID를 오름차순 정렬해야되기 때문에 IS NULL,과 ORDER BY, WHERE를 사용했다.

♦️개념 복습 :
SQL 실행 순서 : FROM > WHERE > GROUPBY > HAVING > SELECT > ORDERBY
-
IS NULL과 IS NOT NULL은 값인 NULL인행/NULL이 아닌 행을 찾을 때 사용한다.
🚨한가지 주의할 점은 = 또는 != 직접 비교할 수 없다는 점 유의! -
WHERE은 FROM 절에서 가져온 데이터 중 조건 만족하는 행만 필터링한다. NULL 값 비교할 때는 IS NULL 또는 IS NOT NULL 사용하고 그외에 다양한 비교 연산자, 논리연산자, 패턴 매칭 등의 연산자를 사용하여 필터링 가능하다.
🚨한가지 주의할 점은 SELECT 절에서 사용한 별칭으로 WHERE 절에 사용할 수 없는데 이는 WHERE절이 SELECT 문보다 먼저 실행되기 때문에! -
ORDER BY는 SQL 실행 순서 중 가장 마지막 순서로, select로 가져온 데이터를 정렬해준다. where 절로 필터링된 데이터에서만 작동하고 ASC(오름차순, 기본값) 또는 DESC(내림차순) 사용 가능하다!
2번 문제 - 역순 정렬하기
출처 : https://school.programmers.co.kr/learn/courses/30/lessons/59035
풀이 : 동물 보호소에 들어온 모든 동물의 이름과 보호 시작일 조회하고, 이 결과를 ANIMAL_ID 역순으로 보여줘야 되기 때문에 ORDER BY를 사용했다.

3번 문제 - 중복 제거하기
출처 : https://school.programmers.co.kr/learn/courses/30/lessons/59408
풀이 : 동물 보호소에 들어온 동물 이름이 몇 개인지 조회해야하는데, 단 이름이NULL인 경우는 집계하지 X, 중복된 이름은 하나로 쳐야되기 때문에 COUNT()함수와 DISTINCT 사용했다.

♦️개념 복습 :
-
count() 함수는 테이블에서 특정 열 또는 전체 행의 개수를 반환한다.
보통 count(*)하면 null 포함한 전체 행 개수를 반환하고, count(컬럼명)은 null 제외한 특정 컬럼의 값 개수를 반환하며, 이번 문제처럼 null값과 함께 중복을 제거한 특정 컬럼의 개수를 반환할 때는 COUNT(distinct 컬럼명)을 사용한다. -
distinct는 중복 제거하는 키워드로, 특정 컬럼에서 유니크한 값만 반환할 때 사용된다.
🚨주의할 점은 select 절에서만 사용할 수 있고, WHERE, GROUP BY, ORDER BY 등 다른 절에서는 직접 사용 불가하다.
🤔만약 select 절에 distinct를 쓰고 그 뒤에 컬럼명이 2개 이상이 온다면 어떤 값을 반환하게 될까?
👉distinct를 여러 컬럼들과 함께 사용하면 각 컬럼의 조합이 유일한 경우에만 중복이 제거된다고 한다. 즉, 개별 컬럼이 아니라 각 행의 전체 조합을 기준으로 중복 여부가 판단된다.
예를 들어
-
distinct restaurant_name(단일 컬럼)

=> restaurant_name 컬럼에서 중복 제거한 후, 유일한 값만 반환 -
distinct restaurant_name, cuisine_type(여러 컬럼)

(아래는 결과 중 일부 가져옴)

=> cuisine_type만 보면 중복(American, Indian)이 있지만, 각 행의 조합(restaurant_name + cuisine_type)이 다르면 중복으로 간주되지 않음
restaurantA - American
restaurantA - American 이런 조합이 2번 등장하는 경우에만 중복이 제거됨
즉, distinct로 여러 컬럼 지정하면 각 컬럼의 조합이 고유한 경우에만 한 번씩 출력된다는 거!
🚨또 한가지 주의할 점은 count(distinct 컬럼명)을 사용하면 null값을 제외시킨 중복 제거 값을 반환하기 때문에, 만약에 null값 포함한 상태로 중복 제거한 값을 반환하고 싶다 혹은 특정 값으로 대체해서 null 값 처리하고 싶다면 COALESCE()가 필요하다.
- coalesce()는 null값을 특정 값으로 변환하는 함수로, 여러 개의 인자를 받을 수 있고, 첫 번쨰 null이 아닌 값을 반환한다. 문법은 coalesce(컬럼, 기본값) 형태!
select distinct coalesce(category, '미분류') from products;
=> category 컬럼에서 중복값을 제거하되, null값을 '미분류' 변환하여 처리하라는 의미!
=> 여기서 🚨오해하면 안되는 게, 위에 쿼리문은 select로 조회할 때만 null을 '미분류'로 변환할 뿐이고, 테이블의 category 컬럼에 있는 null값이 실제로 '미분류'로 변경되지는 않는다는 점!
4번 문제 - 동물의 아이디와 이름
출처 : https://school.programmers.co.kr/learn/courses/30/lessons/59403
풀이 : 동물 보호소에 들어온 모든 동물의 아이디와 이름을 조회하되, 동물 아이디 순으로 조회해야 되기 때문에 order by 사용했다.

5번 문제 - 동물 수 구하기
출처 : https://school.programmers.co.kr/learn/courses/30/lessons/59406
풀이 : 동물 보호소에 동물이 몇 마리 들어왔는지를 조회해야 되기 때문에 count()함수를 사용했다.
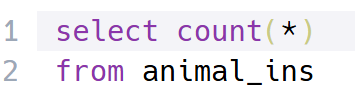
🤔만약 테이블 전체 행을 중복 제거하고 개수를 구하고 싶다면?
해볼 수 있는 방법이 서브쿼리를 활용하여 distinct를 먼저 적용한 후에 count(*)를 써줄 수가 있겠다.
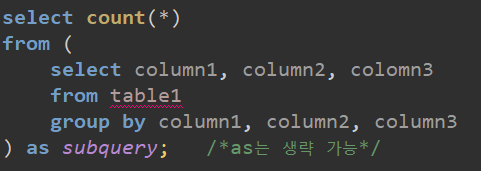
6번 문제 - 동명 동물 수 찾기
출처 : https://school.programmers.co.kr/learn/courses/30/lessons/59041
풀이 : 동물 보호소에 들어온 동물 중 이름이 두 번 이상 쓰인 동물의 이름과 해당 이름이 쓰인 횟수를 조회하는 쿼리문을 작성하고 결과를 이름 순으로 조회(단, 이름 없으면 집계에서 제외)해야 되기 때문에, 우선 이름 없는 동물 제외하고 이름 별 쓰인 횟수를 group by해서 그 결과가 2 이상인 것만 조회한 뒤 이름 순으로 조회하고자 where, count()와 group by 그리고 having을 사용했다.
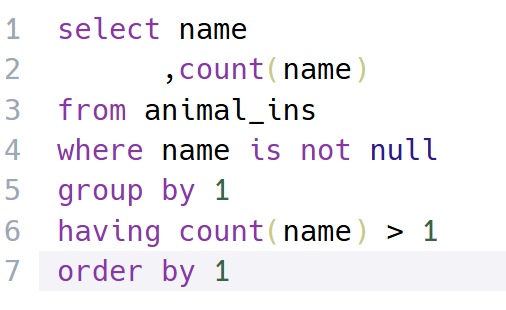
♦️개념 복습 :
-
count()는 집계함수로 group by를 사용되며 위에서 설명했듯이 개수를 반환해준다.
✔️집계 함수(Aggregate Function) : 여러 개의 행을 하나의 그룹으로 묶어서 요약된 값(총합,개수,평균 등)을 반환하는 함수
ex) count(), sum(), avg(), max(), min() -
집계 함수는 테이블 전체에서 단일 값(요약 값)만 반환하기 때문에 컬럼 그룹 별 결과를 보고 싶다면 group by를 꼭 사용해줘야 한다.
-
group by는 특정 컬럼을 기준으로 데이터를 그룹화하여 요약된 결과를 제공하는 기능을 한다. 집계 함수와 함께 사용해서 각 그룹별 데이터 분석이 가능하다.
-
having은 집계 함수 결과를 필터링할 때 사용된다.
where과의 차이를 보면, where은 개별 행을 필터링한다면, having은 그룹화된 데이터에서 필터링을 한다는 점이 있다!
7번 문제 - 아픈 동물 찾기
출처 : https://school.programmers.co.kr/learn/courses/30/lessons/59036
풀이 : 동물 보호소에 들어온 동물 중 아픈 동물의 아이디와 이름을 조회하고 그 결과를 아이디 순으로 조회해야 되기 때문에 where과 order by, =연산자를 사용했다. 아프다의 기준은 intake_condition 컬럼 값이 'sick'인 경우를 찾으면 된다!
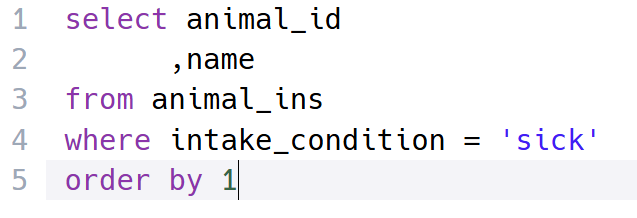
♦️개념 복습 :
- =연산자는 정확히 일치하는 값을 찾을 때 사용하는 비교연산자!
8번 문제 - 상위 n개 레코드
출처 : https://school.programmers.co.kr/learn/courses/30/lessons/59405
풀이 : 동물 보호소에 가장 먼저 들어온 동물의 이름을 조회해야되기 때문에 order by과 limit을 사용했다.
♦️개념 복습 :
- limit은 반환할 행의 개수를 제한하는 키워드로, 특히 대용량 데이터 조회할 때 성능 최적화 및 페이징 처리(이때는 offset과 함께 사용)에 유용하게 사용된다!
offset이랑 order by와 함께 자주 사용되고 이 문제에서는 order by랑 쓰였다.
9번 문제 - 최솟값 구하기
출처 :
https://school.programmers.co.kr/learn/courses/30/lessons/59038
풀이 : 동물 보호소에 가장 먼저 들어온 동물이 언제 들어왔는지를 조회해야 되기 때문에 min()을 사용했다.

♦️개념 복습 :
-min()은 최솟값을 찾는 집계함수로, 특정 컬럼에서 가장 작은 값을 반환하는데 사용된다. 숫자, 날짜, 문자열 모두에서 사용 가능하고, 이번 문제에서는 날짜에 사용했다. null값은 최소 값 비교에서 제외된다. 문자열 컬럼에서 최소 값 조회하는 경우에는 사전순으로 정렬되는데 문자열 컬럼에서의 최솟값이란 알파벳 순(A-Z)를 생각하면 된다.
10번 문제 - 어린 동물 찾기
출처 :
https://school.programmers.co.kr/learn/courses/30/lessons/59037
풀이 : 동물 보호소에 들어온 동물 중 젊은 동물의 아이디와 이름을 조회하되, 결과는 아이디 순으로 조회하기 위해 MIN()과 ORDER BY를 사용했다.
♦️개념 복습 :
- in 연산자는 =과 같은 비교연산자로, 여러 개의 값을 한번에 비교할 때 사용한다. not in을 사용하면 지정된 값들을 제외하고 가져온다. 이 문제에서 젊은 동물이란 intake_condition이 'Aged'가 아닌 모든 값에 해당하는 동물들을 조회해야 되기 떄문에 'aged'인 값을 제외하는 형태(not in)로 답을 구했다.
📰아티클 스터디
제목 : 양질의 데이터를 판별하는 5가지 방법 : 데이터 형식을 파악했는가?
출처 : https://yozm.wishket.com/magazine/detail/1107/
🔹요약
-데이터는 형식에 따라 정형 데이터와 비정형 데이터로 나뉜다.
-정형 데이터는 활용성 놓고 다양한 분석 기법 적용할 수 있는 반면, 비정형 데이터는 인공지능 기술에 주로 활용된다.
-정형데이터에서도 수치형 데이터가 분석 가능성이 높으며,
범주형 데이터는 활용성이 상대적으로 낮을 수 있다.
🔹핵심 포인트
-데이터 형식(정형/비정형)에 따라 분석 가능성이 달라진다.
👉 정형 데이터는 통계 분석, 머신러닝, 딥러닝 등 다양한 기법으로 활용 가능한 반면,
비정형 데이터는 AI 기술에 의존하는 경우가 많다.
-정형 데이터 안에서도 '범주형 vs 수치형 데이터'에 분석 방법이 다르다.
👉 범주형 데이터(명목 척도, 서열 척도) : 수학적 연산 어려움
수치형 데이터(동간 척도, 비율 척도) : 연산과 통계 분석 가능함
-비정형 데이터는 활용 방식이 제한적이지만 인공 지능을 통해 가치 창출이 가능하다.
EX) 이미지나 텍스트 -> 통계 분석 어렵지만, 딥러닝 기반의 인공지능 기술로 활용될 수 있음
-숫자로 변환 가능한 데이터일수록 분석 가능성이 높다.
👉 빅데이터 분석의 핵심은 결국 숫자를 다루는 것이므로,
비정형 데이터를 수치화 할 수 있다면 활용 가능성이 높아진다!
🔹핵심 개념 및 용어
-정형 데이터 : 미리 정의된 구조(행과 열)에 맞춰 저장된 데이터! (예: 데이터베이스, 엑셀)
-비정형 데이터 : 특정한 형식이 없는 데이터. (예:텍스트, 이미지, 동영상, 오디오)
-범주형 데이터 : 데이터가 특정 그룹이나 카테고리로 구분되는 데이터 (예: 성별, 직업, 국가 등)
-수치형 데이터 : 숫자로 표현되며 연산이 가능한 데이터 (예: 키, 몸무게, 가격)
-데이터 척도 : 데이터가 정의되고 분류되는 방식으로 명목 척도, 서열 척도, 등간 척도, 비율 척도로 구분됨
🔹개인 인사이트
아티클에서 정형 데이터 속에서도 ‘보통이다’, ‘매우 그렇다’ 같은 텍스트 형태가 저장될 수 있으며, 이는 미리 정해 놓은 구조가 있기 때문에 숫자로 변환할 수 있어서 사실상 수치 데이터와 같은 것으로 봐도 무방하다고 설명하고 있다. 이를 확장해서 생각해보면, 텍스트, 이미지, 음성 같은 비정형 데이터도 사실상 ‘보이지 않는 정형 데이터’일 가능성이 높다고 볼 수 있겠다고 생각했다. 결국 비정형 데이터도 적절한 수치화 과정을 거치면 구조화된 데이터처럼 활용할 수도 있을테고,즉 분석 대상이 될 수도 있으니까!
결국 우리가 어떤 데이터를 바라볼 때 단순히 ‘정형 데이터 vs. 비정형 데이터’라는 구분을 넘어서, 어떻게 데이터를 변환하여 정량적인 분석이 가능하게 만들 것인지 고민하는 것이 중요하겠다는 생각이 들었다.
🔹공통 인사이트
현재는 정형 데이터가 비정형 데이터보다 데이터 활용 가능성이 높지만,
비정형 데이터의 분석 방법이 발전함에 따라 시간이 갈 수록 데이터의 품질을 나누는 기준 중 하나인,
데이터 형태를 구분하는 것은 모호해질 것으로 생각된다.
범주형 데이터의 척도를 구분하는 것에 있어서 수학적 연산이 불가능한 척도의 한계 또한 줄어들 것으로 예상된다.
