
강화학습은 에이전트가 보상을 최대화하는 방향으로 행동을 학습하는 알고리즘으로, 게임 분야에 활발하게 적용되고 있다.
초기에는 일인 게임인 Atari 게임을 대상으로 연구되었으나, 이후에는 상대와의 상호작용이 있는 게임인 Starcraft 2와 Dota 2에서도 적용되어 연구되었다.
아타리게임 (Seaquest)

출처 : https://www.retrogames.cz/play_221-Atari2600.php
Starcraft 2

출처 : https://www.youtube.com/watch?v=cUTMhmVh1qs
딥마인드사의 Alphastar의 경기
Dota 2

출처 : https://www.youtube.com/watch?v=-FoZAM9xqS4&t=164s
오픈ai사의 Five가 팀 OG와의 경기
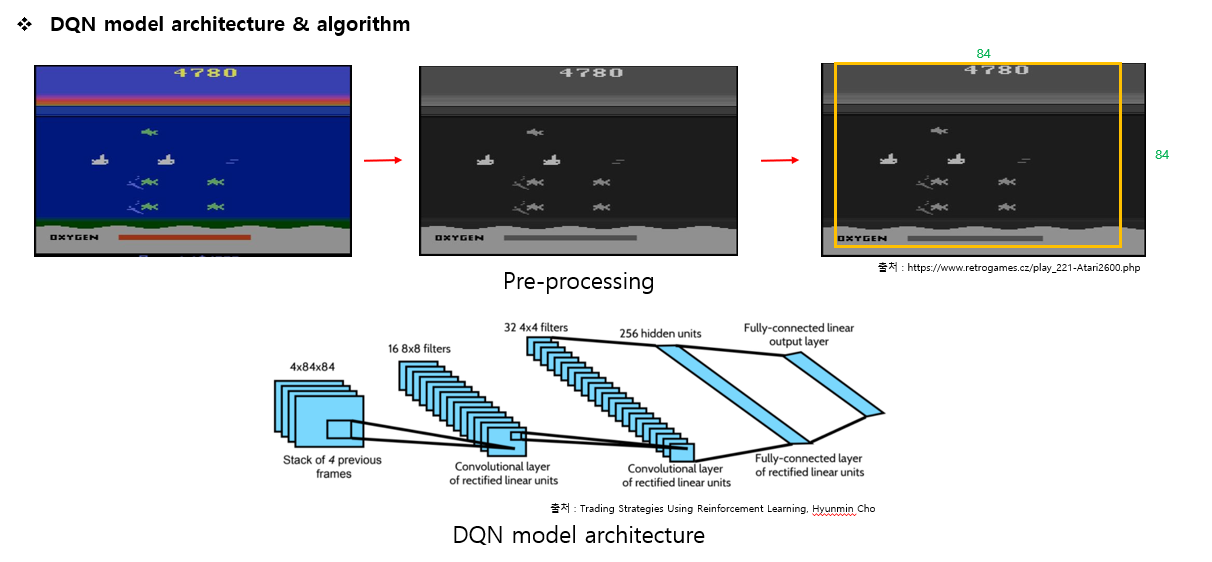
Q-learning알고리즘을 적용하기 전에 입력차원을 줄이기위해 RGB표현을 회색조로 변환한후 이미지를 다운 샘플링한후 재생영역을 캡쳐하는 이미지의 영역을 얻은 후 2D컴볼루션의 GPU구현을 이용해 딥Q학습의 알고리즘의 입력을 생성합니다.
생성된 84844이미지로 신경망에 대한 입력을 하고 완전히 연결된 선형레이어로 단일 출력을 만듭니다. 여러게임에서 찾아낸 유효한 액션의 수는 4~18개로 다양했습니다. 이렇게 훈련된 convolution네트워크를 DQN이라고 합니다.
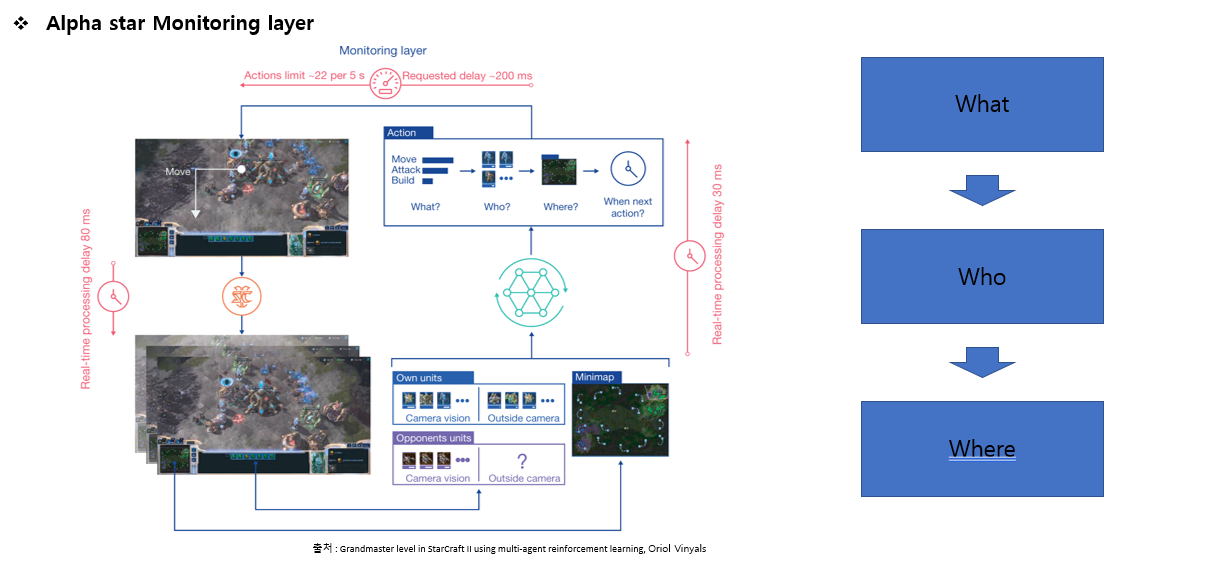
알파스타는 사람이 보는 화면을 통해서 게임의 정보를 받아들이고 행동을 합니다.
그림에서 보면 What? 은 어떤행동을 할지 정합니다. 유닛을 가지고 이동을 시킬지 공격을 시킬지 건물을 짓거나 자원을 캐는 행동을 하는 등의 행동을 정합니다. Who?은 what에서 정한 행동은 누가 수행할지를 정합니다. Where?는 어느 곳에 어떤행동을 수행할지 정합니다. 행동한후에 바뀌는 환경에 따라 다음 행동을 언제 할지 다시 정하는 것을 반복합니다.
그리고 여기에서 처리시간과 네트워크 딜레이 시간도 알파스타는 고려합니다.
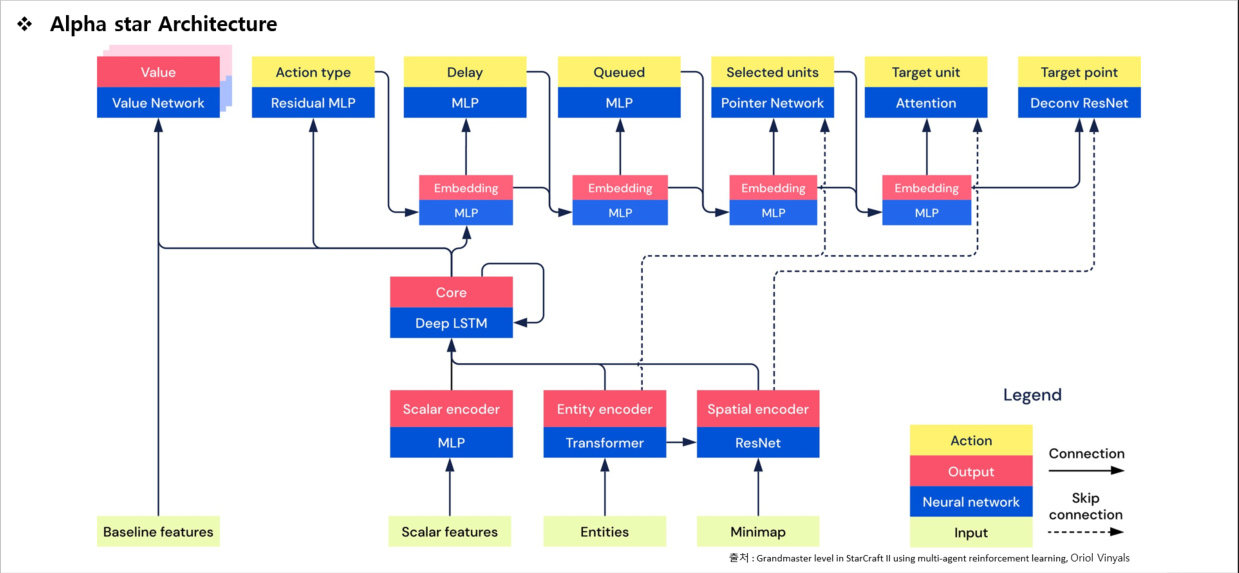
게임환경에서 관측정보와 게임을 플레이하면서 발생한 행동의 정보를 기반으로 이후 행동을 예측하고 선택합니다. 이를 이용해 현재의 상태를 모델링하고 미래를 예측하여 가치가 높은 행동으로 예측해 선택해 행동하며 플레이하면서 얻는 경험을 학습합니다.

아래쪽에서는 리플레이에서 샘플링된 출력과 인간의 행동을 KL다이버전스를 이용해 두 확률 분포간의 유사성을 측정해서 인간의 행동과 샘플링된 출력의 분포간의 차이를 지도학습을 이용해 만들어낸 매개변수를 최적화하여 에이전트를 업데이트 했습니다.
위쪽에서는 강화학습을 사람의 데이터 통계 z를 샘플링하는데 사용했습니다. 이를 KL loss와 결합된 강화학습인 (TD,V-trace,UPGO)를 통해 정책 및 값의 출력을 업데이트하기 위해 에이전트의 경험을 수집합니다.
이제 오른쪽 그림을 보시면 감독학습에 의해 초기화된 세개의 에이전트를 이후에 강화학습으로 훈련하고 이 에이전트들을 훈련하면서 에이전트의 복사본을 리그에 계속해서 추가해 현재의 에이전트와 과거의 에이전트들과 계속 상대하면서 훈련합니다. 그리고 exploiter 에이전트가 만들어진 모든 과거 에이전트와 대결해 훈련하고 메인 exploiter와 League exploiter를 새로 추가할 때 과거 에이전트로 추가할 수 있습니다.
(KL Loss는 두 확률 분포 간의 차이를 측정하여 모델의 학습을 이끌어내는 손실 함수. KLD Loss는 주로 확률 분포를 모델링하는 확률적 모델에서 사용되며, 두 확률 분포 간의 차이를 최소화하거나, 원하는 분포와 모델의 출력 분포 간의 차이를 규제하는 등의 목적으로 활용됩니다.)

에이전트는 게임 플레이 중에 앞에서 수집한 다양한 게임 상태를 입력으로 받아 정책을 통해 행동을 선택하고 게임을 진행합니다. ppo알고리즘을 업데이트하는데 에이전트의 행동에 따른 보상을 이용합니다.
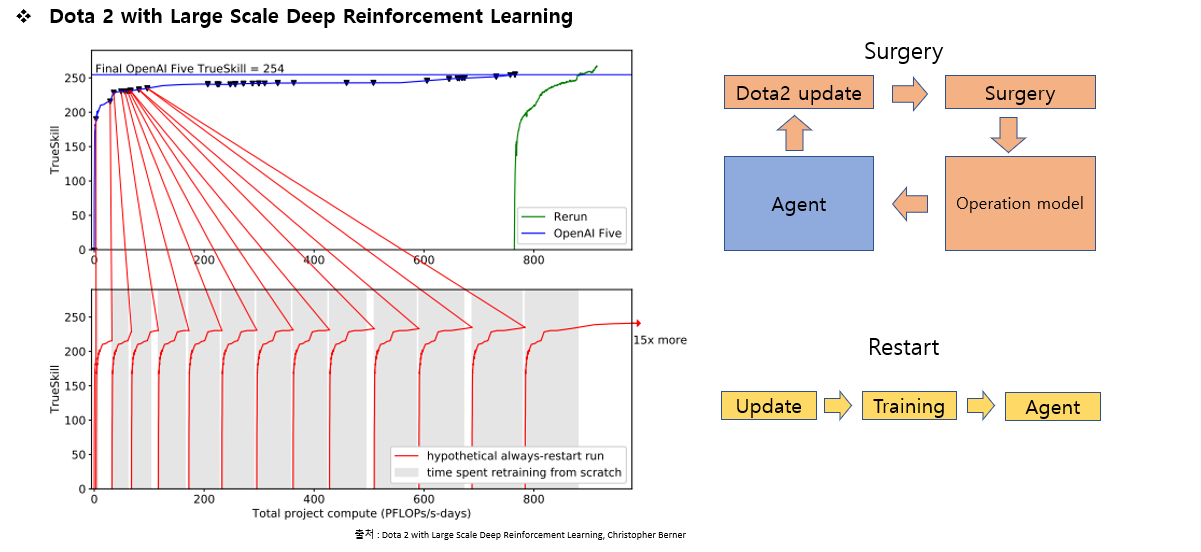
여기의 상단 패널은 오픈 에이아이 파이브의 훈련과정 전체를 보여줍니다.
점이 보이는 지점에서 surgery를 이용해 게임이 업데이트되어 환경이나 정책이 변경될때마다 계속해서 훈련을 진행 했고 성능의 저하 없이 훈련을 이어갔습니다. 마지막의 초록색 부분은 재시작을 한번 한 것을 볼 수 있습니다.
이때, 위쪽의 재시작은 그동안 모은 데이터를 기반으로 재시작을 해 수정한것이고 아래쪽은 업데이트가 될 때마다 다시 재시작을 했을 경우를 말합니다.

Stracraft 2의 Alpha Star과 Dota 2의 Five은 특정 게임에서 특정 맵과 변수를 영웅의 폭을 줄인 상태등의 제한된 환경에서 실험했다. 특정한 환경에서는 좋은 성능을 내고 사람들과 대결에서 승리를 거둬 좋은 성과를 내었지만 특정한 환경에서만 이용이 가능하다는 단점이 있다.
추후에는 같은 모델로 다른 게임을 플레이하거나 아케이드 같은 게임에서 다른 규칙의 게임도 스스로 강화학습을 이용해 대응해 플레이할 수 있는 모델에 대한 연구가 더 되면 좋겠습니다.
나중에는 더발전하면 정말 뛰어난 npc가 나와서 사람이 별로 없는 멀티플레이어 게임같은경우에도 상대가 없어서 못하는경우가 있는데 이런것들도 ai가 플레이해준다면 유저수가 적은 게임들도 계속 운영이 가능할거같다고 생각한다.
