
현재 제가 속한 팀에서는 졸업프로젝트로 '믿어방'이라는 서비스를 개발하고 있습니다.
믿어방은 사회초년생의 전월세계약을 더 쉽고, 편리하게 만들어주는 서비스입니다.
GPT 사용의 목적
해당 포스팅에서는 ChatGPT를 적용하여 현재 서비스의 기능을 개선해보고자 합니다.개선해보고자 하는 기능은 임대차계약서 특약 분석 기능입니다. (프로덕션에는 API를 사용하기 때문에 정확히는 gpt-3.5-turbo 모델을 사용합니다.)
해당 기능의 워크플로우는 다음과 같습니다.
- 사용자가 특약을 분석하고 싶은 임대차계약서의 사진을 찍어 업로드한다.
- 업로드된 사진에서 OCR 기술을 이용해 특약 문장을 추출한다.
- 추출된 특약 문장이 믿어방에서 사전에 구축한 52개의 특약 케이스중 무엇에 해당하는지 도출한다.
- 도출된 케이스에 기반하여 사용자에게 해당 특약과 관련된 설명과 분석레포트를 제공한다.
이때 3번 단계에서 사용자로 얻은 특약이 어떤 특약 케이스에 해당하는지 알기 위해 기존에는 KoNlpy를 이용한 형태소 추출과 TF-IDF 코사인 유사도 계산 방식을 사용하였습니다.
하지만 TF-IDF를 사용한 현재 방식에는 유의어와 패러프레이징된 문장을 고려하기 어렵다는 한계가 있습니다.
예를 들어 '차임'과 '월세'처럼 같은 뜻을 가지는 유의어들이 TF-IDF를 위한 데이터셋에 모두 포함되어 있지 않거나, 비슷한 맥락의 문장이라도 전혀 다른 형식과 구조로 작성되어 있을 수 있습니다.
그렇다면 이렇게 TF-IDF로도 잡아내지 못하는 유사한 문장들은 어떻게 처리하면 좋을까요?
프롬프트 작성 패턴 분석
우선 제대로된 프롬프트를 작성하여 질의하는 것이 원하는 답을 도출하기 위한 가장 이상적인 방법일 것입니다.
따라서 프롬프트의 작성 패턴을 공식화하여 원하는 답변을 ChatGPT로부터 얻어내고자 합니다.
프롬프트 작성 패턴 분석은 다음 논문을 참고하였습니다.
A Prompt Pattern Catalog to Enhance Prompt Engineering with ChatGPT
Jules White, Quchen Fu, Sam Hays, Michael Sandborn, Carlos Olea, Henry Gilbert,Ashraf Elnashar, Jesse Spencer-Smith, and Douglas C. Schmidt Department of Computer Science Vanderbilt University, Tennessee Nashville, TN, USA
A Prompt Pattern Catalog to Enhance Prompt Engineering with ChatGPT
목표
프롬프트 엔지니어링은 ChatGPT를 프로덕션에 적용하여 원하는 답변을 안정적으로 얻기 위해 필요합니다. 따라서 구체적인 프롬프트 예시에 집중하지 않고, 거시적으로 프롬프트 패턴을 식별하여 믿어방 서비스에 적용할 수 있는 프롬프트 패턴을 도출하고자 합니다.
프롬프트 패턴의 분류
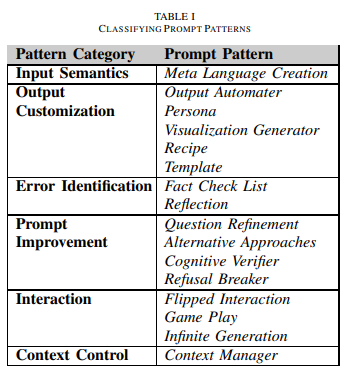
1. Input Semantics
LLM(Large Language Model)이 입력을 이해하는 방법과 입력을 출력 생성에 사용할 수 있는 것으로 변환하는 방법을 다룹니다
1) Meta Language Creation Pattern
- 의도
- LLM과 대화할 때 대체 언어를 통해 프롬프트를 생성합니다. 이 패턴의 목적은 사용자가 이 새로운 언어와 그 의미를 사용하여 향후 프롬프트를 작성할 수 있도록 LLM에게 대체 언어의 의미를 설명하는 것입니다.
- 적용
- 중요한 것은 명확한 표기법이나 약칭을 개발하는 것입니다.
- 아래 예시는 node와 edge를 나타내는 규칙을 정의하여 그래프를 설명하기 위한 표준화된 표기법을 설정합니다.
- 평가
- 해당 방식은 코드를 작성할 때 더 적합한 것으로 보입니다.
- 따라서 믿어방 서비스에는 적용이 어려울 듯합니다.

2. Output Customization
LLM에서 생성된 출력의 유형, 형식, 구조 또는 기타 속성을 제한하거나 조정하는 데 중점을 둡니다.
1) Output Automater Pattern
- 의도
- LLM이 출력 구조로 권장되는 모든 단계를 자동으로 수행할 수 있는 스크립트 또는 기타 자동화 아티팩트를 생성하도록 하는 것입니다.
- 적용
- 구조 :
1) automation이 생성되어야 하는 상황을 정의
2) LLM이 자동화를 수행하기 위해 출력해야 하는 출력 유형에 대한 구체적인 설명을 제공(자동화 아티팩트가 분명해야 한다.) (예시: a Python script)
- 예시

- 평가
- 모든 LLM 출력에서 오류가 발생할 수 있으므로 팩트 체크 리스트는 질문 세분화 패턴과 결합하는 등 다른 패턴과 결합하는 데 효과적인 패턴입니다.
- 업무 자동화에 적합한 방식이기 때문에 믿어방 서비스에는 적용이 어렵습니다.
2) Persona Pattern 🔥
- 의도
- LLM 출력이 특정 관점을 갖고 답하도록 합니다.
- 이 패턴의 목적은 LLM이 생성할 출력 유형과 초점을 맞출 세부 정보를 선택하는 데 도움이 되는 "페르소나"를 제공하는 것입니다.
- 적용
- 구조
- 구조

- 예시
“이제부터 보안 검토자 역할을 수행하십시오. 우리가 보는 모든 코드의 보안 세부사항에 주의를 기울이세요. 보안 검토자가 코드와 관련된 출력을 제공하세요.”

- 평가
- 부동산 계약에 대한 객관적인 답변을 얻어내기 위해
공인중개사또는변호사등의 페르소나를 설정하고 페르소나에 적합한 역할을 구체적으로 부여할 수 있습니다.
- 부동산 계약에 대한 객관적인 답변을 얻어내기 위해
3) Template Pattern 🔥
-
의도
LLM의 출력이 구조적으로 템플릿을 준수하도록 합니다. -
적용
-
구조

-
예시
"당신의 출력을 위한 템플릿을 제공하겠습니다. 대문자로 된 모든 것은 플레이스홀더(자리 표시자)입니다. 텍스트를 생성할 때, 제가 나열한 플레이스홀더 중 하나에 맞춰 넣어주세요. 제공한 서식과 전체 템플릿을 유지해주세요.https://myapi.com/NAME/profile/JOB에서제공한 것과 같습니다."
프롬프트가 제공된 후에 나타난 예시 대화는 다음과 같습니다.
User: "사람의 이름과 직함을 생성해주세요."
ChatGPT: "https://myapi.com/EmilyParker/profile/Software Engineer"
-

- 평가
- 템플릿 패턴을 적용하는 결과로 LLM의 출력이 필터링되어 사용자에게 유용할 수 있는 다른 출력이 제공되지 않을 수 있습니다.
- 🔥달리 말해 정량화된 답변이 제공되기 때문에 프로덕션에 적용하기에 적합합니다. 특히 믿어방의 경우 ChatGPT에서 일정한 패턴으로 답변을 제공받아야 하기 때문에 믿어방 서비스에 적용되는 모든 ChatGPT 프롬프트에 해당 프롬프트 패턴을 채택했습니다.
4) Visualization Generator Pattern
이미지 생성용. 믿어방 서비스에는 불필요하기 때문에 생략합니다.
5) Recipe Pattern 🔥
- 의도
- 사용자는 대체적으로 최종 목표가 무엇이고, 어떠한 요소(재료)가 프롬프트에 포함되어야 하는지 알고 있습니다. 하지만 최종 목표를 위한 구체적인 단계를 제대로 알고 있지 않을 수 있습니다.
- 따라서 LLM이 프롬프트에서 제시된 요소를 기반으로 최종 목표까지의 단계별 시퀀스를 출력하도록 합니다.
- 적용
- 구조

- 예시
"저는 애플리케이션을 클라우드에 배포하려고 합니다. 제 애플리케이션을 위한 필요한 종속성을 가상 머신에 설치해야 한다는 것을 알고 있습니다. 또한 AWS 계정 가입이 필요하다는 것도 알고 있습니다. 완전한 단계적 시퀀스를 제공해주세요. 빠진 단계를 채워주세요. 불필요한 단계를 식별해주세요.”
- 구조
- 평가
전월세계약은 수많은 작은 단계들의 연속입니다. 따라서 처음 전월세계약을 해보는 사회초년생에게는 세부적인 단계와 절차가 어렵게 느껴질 수 있습니다. 따라서 유저가 직접 현재 진행단계를 작성하고, 누락된 절차와 이후 진행되어야 하는 절차에 대해 물을 수 있을 것입니다. 하지만 전월세계약은 한국만의 방식과, 관행적으로 이뤄지는 절차를 포함하고 있습니다. 따라서 GPT만을 이용하여서는 만족할만한 답을 얻기 어렵다고 판단하였습니다.
3. Error Identification
LLM에서 생성된 출력의 오류를 식별하고 해결하는 데 중점을 둡니다.
사실 믿어방에서는 ChatGPT에 오류 식별 기능을 요구하지 않습니다. 가장 정제된 단일한 질문으로 최적의 답을 얻는 것이 이번 ChatGPT 적용의 목적입니다. 따라서 Error Identification에 해당되는 프롬프트 패턴은 배제하였습니다.
4. Prompt Improvement
입력 및 출력의 품질을 개선하는 데 중점을 둡니다.
1) Question Refinement Pattern
- 의도
- LLM이 항상 사용자가 원래 질문 대신 더 나은 질문을 할 수 있도록 제안합니다. 사용자가 정확한 답변을 얻기 위해 던질 수 있는 최적 질문을 찾는 데 도움을 줄 수 있습니다.
- LLM은 제공하는 답변에 대한 제한 사항을 명시하거나 보다 정확한 답변을 작성하는 데 도움이 되는 추가 정보를 요청합니다.
- 적용
- 구조
- LLM이 특정 범위 내에서 질문의 더 나은 버전을 제안하도록 요청 (모든 질문이 자동으로 다시 작성되거나 주어진 목표에 따라 수정되지 않도록 하기 위해 범위를 설정)
- (옵션) 제안된 더 나은 버전의 질문을 사용할지 여부를 물음 (개선된 질문을 복사/수정/입력할 필요없이 사용하도록 자동화하기 위함)
- 예시
지금부터 제가 질문을 할 때마다 software artifact의 보안 문제를 해결하기 위해 제가 대신 사용하고 있는 언어나 프레임워크의 보안 위험에 특정한 정보를 통합하는 질문의 더 나은 버전을 제안하고 질문을 대신 사용할지 여부를 묻습니다."
2) Refusal Breaker Pattern
경험적으로 보면 패턴을 적용하지 않아도 대부분 해당 패턴에서 얻고자 하는 형식의 답을 내놓았습니다. 따라서 자세한 설명은 생략합니다.
5. Interaction
사용자와 LLM 간의 상호 작용에 초점을 맞춥니다. 믿어방에서는 gpt3.5 turbo API를 사용하기 때문에 적용이 어렵습니다. Interaction으로 분류되는 프롬프트 패턴은 필요하지 않기 때문에 배제합니다.
결론
믿어방의 기능에 적용할 수 있는 유의미한 프롬프트 패턴은 다음과 같습니다.
1. Persona Pattern
2. Template Pattern
결론적으로 프롬프트 패턴을 정형화하는 것만으로는 일정하게 원하는 답변을 얻기 어려웠습니다. 특히 글의 맥락을 이해해야 답할 수 있는 문제에는 매우 취약했습니다.
NLU를 위한 ChatGPT
일단 이 문제를 해결하기 위한 해결책을 무작정 구글링하여 찾아보았습니다. 유의어 분석, 패러프레이징 문장 분석, 문장 유사도 등등의 키워드로 검색을 이어나가보죠.

결론적으로 우리가 현재 해결하고자 하는 문자는 자연어 이해(NLU, Natural Language Understanding 영역의 문제임을 알 수 있었습니다. 따라서 NLU 영역에서의 ChatGPT의 유효성을 검증하고, 퍼포먼스를 개선하는 방향을 이어서 찾아보고자 합니다.
NLP, NLG, 그리고 NLU?
그렇다면 NLU는 무엇일까요?
NLP는 많이 들어보셨을 것입니다. Natural Language Process로 말그대로 자연어처리를 일컫습니다.
이때 NLP는 NLU와 NLG로 나뉠 수 있습니다.
NLU(Natural Language Understanding)- 자연어의 의미를 모델이 이해하도록 하는 것입니다.
GLUE 벤치마크를 통해 성능을 체크합니다.
NLG(Natural Language Generation)- 자연어를 모델이 생성하도록 하는 것입니다.
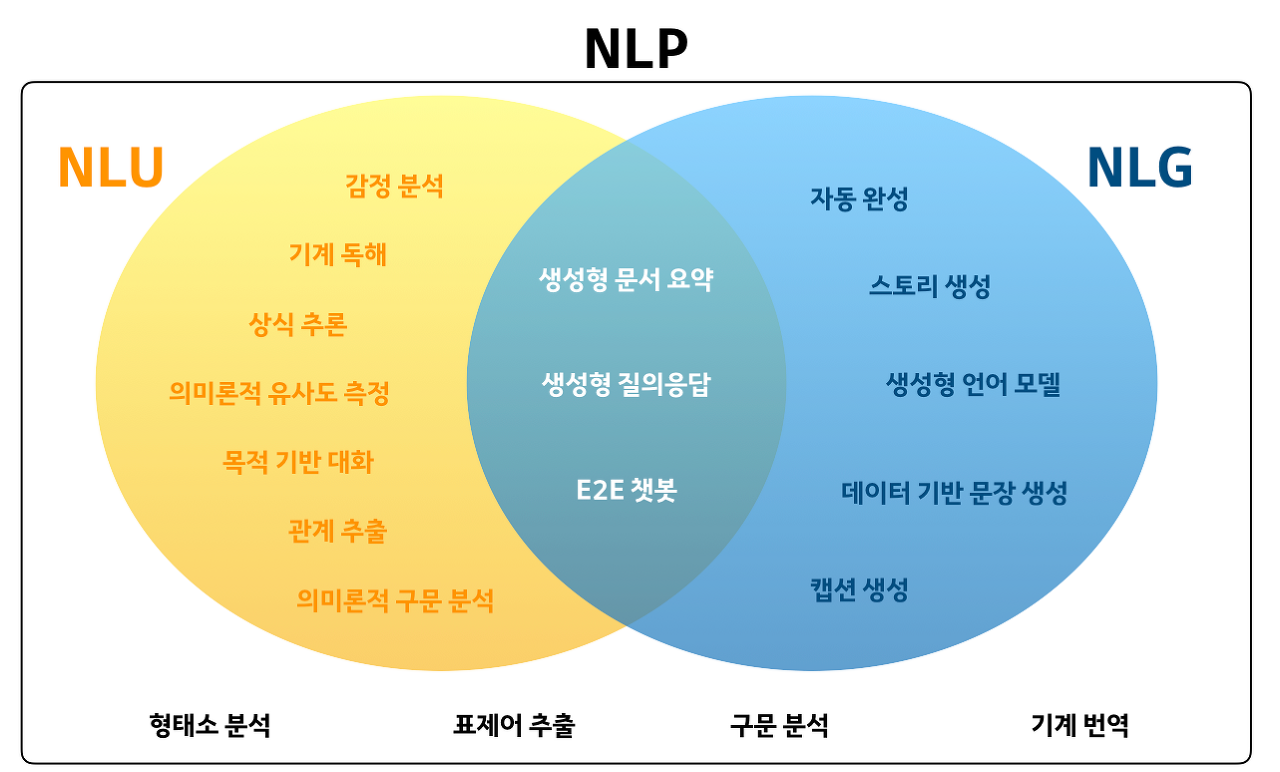
- 자연어를 모델이 생성하도록 하는 것입니다.
NLU 작업에서의 GPT
ChatGPT가 기존 LLM보다 생성 작업(NLG)에 뛰어나다는 것은 이미 널리 알려진 사실입니다.
하지만 ChatGPT가 자연어 이해(NLU) 작업에도 유효한가에 대한 증명은 여전히 불분명합니다.
따라서 다음 논문을 통해 그 문제에 대해 분석해보고자 합니다.
Can ChatGPT Understand Too?
A Comparative Study on ChatGPT and Fine-tuned BERT
(Qihuang Zhong, Liang Ding, Juhua Liu, Bo Du, Dacheng Tao)
https://arxiv.org/abs/2302.10198#
GPT의 NLU 작업 평가 방법
NLU에 대한 성능을 평가하기 위해 세가지 요소를 평가합니다.
- Inference task (자연어 추론)
- Paraphrase task (패러프레이징)
- Similarity task (유사성 판단)
모델 평가 목적으로 널리 사용되는 GLUE 벤치마크를 사용합니다.
- GLUE는 CoLA(언어수용 가능성), SST-2(감성분석), MRPC(패러프레이즈), STS-B(텍스트 유사성), QQP(질문 프레이즈), MNLI(텍스트 수반), QNLI(질문-답변 수반)과 같은 도전적이 NLU 작업으로 구성되어 있습니다.
- 평가를 위해, 정확도("Acc.") 측정 지표로 성능을 보고합니다. STS-B의 경우, Pearson and Spearman 상관관계("Pear./Spea.")를 사용하고, CoLA의 경우 Matthew 상관관계("Mcc.")를 사용하며, MRPC 및 QQP의 경우 additional F1 score를 사용합니다.
- dev set에서 클래스당 25개의 인스턴스를 무작위로 샘플링(STS-B는 균등 분포에서 50개의 인스턴스를 무작위 샘플링)하여 테스트 진행하였습니다.
GPT와 BERT 비교 결과
BERT 모델과 ChtatGPT를 비교한 결과, 아래 표에서 확인할 수 있듯이 자연어 추론 부분에서는 ChatGPT가 BERT 모델을 능가하는 성능을 보여줬습니다.
하지만 패러프레이즈와 텍스트 유사성 판단에서는 아래 자료와 같이 ChatGPT가 BERT 모델에 못 미치는 결과를 보여줬습니다. 좌측이 패러프레이징 능력을 나타내는 MRPC 테스트 결과, 우측이 유사성 판단 능력을 나타내는 테스트 결과입니다.
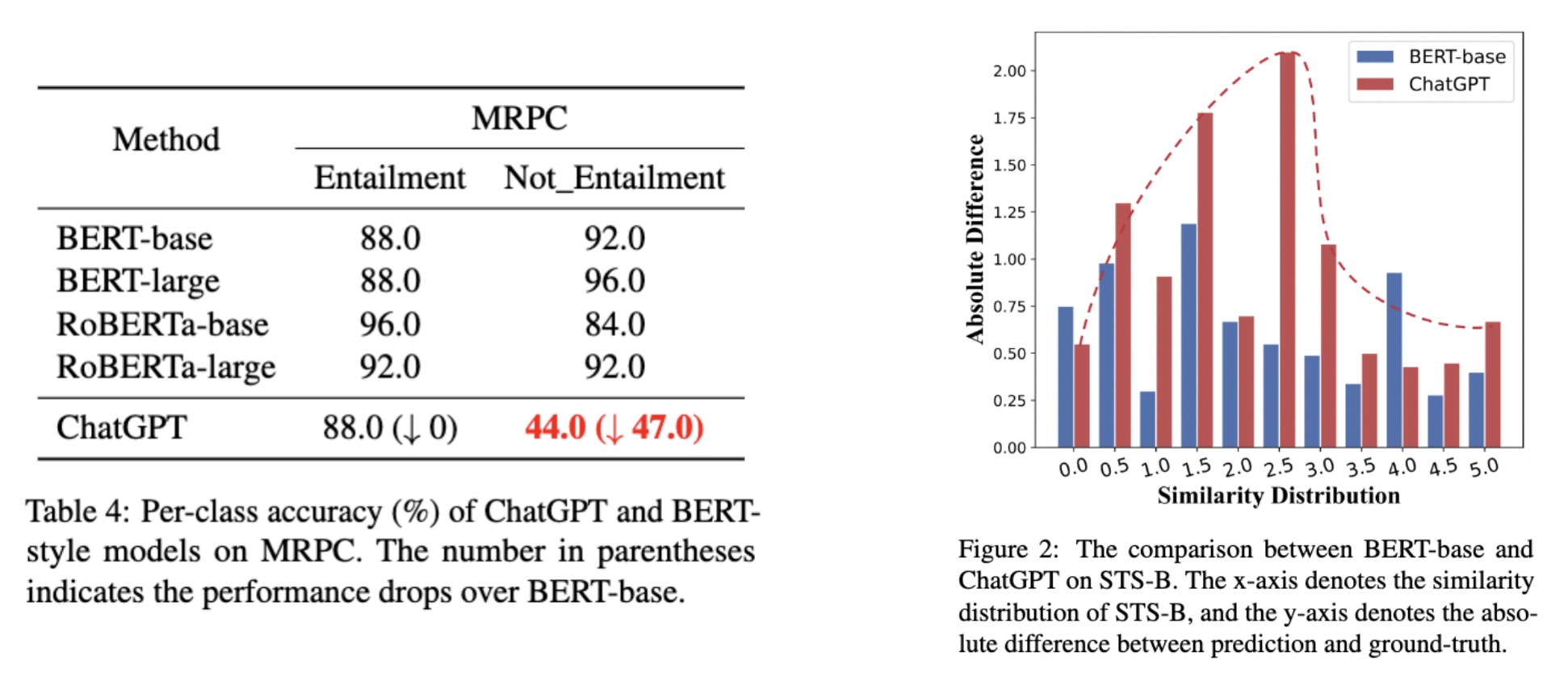
구체적인 예시를 통해 패러프레이징 능력을 확인해보겠습니다.프롬프트에서 제시한 두 문장의 주요한 차이는 “값”의 차이입니다.
하지만 ChatGPT는 대략적인 의미와 (값의 차이에서 오는)세밀한 의미 정보 간의 불일치를 파악하지 못하고 같은 semantic(의미)을 갖고 있다고 판단했습니다.

달리 말하면 ChatGPT가 세밀한 의미 정보를 추출하는 능력을 강화한다면 패러프레이징 성능의 향상으로 이어질 수 있습니다.
새로운 프롬프팅 전략 적용을 통한 개선
그렇다면 프롬프팅 전략을 달리하면 ChatGPT의 퍼포먼스를 향상시킬 수 있지 않을까요?
적용할 프롬프팅 전략은 다음과 같습니다.
1. Standard few-shot prompting
- “in-context learning”이라고도 불립니다.
- 몇가지 입력-출력 예시를 포함하여 프롬프트를 구성합니다.
- 예시를 통해 모델이 작업을 효과적으로 수행할 수 있게 합니다.
2. Manual few-shot CoT prompting
- Wei(Self-consistency improves chain of thought reasoning in language models, 2022) 등에 의해 제안되었습니다.
- 최종 답변을 단계적으로 출력하기 위한 중간 추론 단계를 프롬프트에 포함합니다.
3. Zero-shot CoT
- 간단하고 직관적인 템플릿 기반 프롬프팅을 사용하여 CoT 추론을 가능하게 합니다.
새로운 프롬프팅 전략 구축을 위한 분석
few-shot 프롬프팅 vs zero-shot 프롬프팅
앞서 제시된 새로운 프롬프팅 전략에서 few-shot 프롬프팅과 zero-shot 프롬프팅의 개념이 등장합니다.
shot(샷)은 "예제"로 이해하면 쉽습니다.
few-shot 프롬프팅 : 2개 이상의 예제를 제공합니다.
zero-shot 프롬프팅 : 모델에게 예제를 제공하지 않습니다.
CoT(Chain of Thought Prompting)
- 세계적 권위의 인공지능(AI) 학회 '뉴립스(NeurlIPS, 신경정보처리시스템학회) 2022’에 소개된 논문에서 처음으로 제안되었습니다.
Self-consistency improves chain of thought reasoning in language models
(Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, and Denny Zhou)Self-Consistency Improves Chain of Thought Reasoning in Language Models
- 질문을 바로 던지고 LLM으로부터 답변을 얻는 방법 대신 단계별 추론 예시를 LLM에게 제공합니다.
- 이를 통해 복잡한 추론을 여러 쉬운 단계들로 분해하는 추론 경로를 생성할 수 있게 하여 복잡한 추론 능력을 크게 향상시킵니다.

프롬프팅 전략별 적용 예시
앞서 언급한 shot의 개념과 CoT의 개념이 어떻게 적용되는지 확인할 수 있습니다.

새로운 프롬프팅 전략 테스트
1. 앞서 제시한 세가지 전략 모두 성능 향상에 기여했습니다.
특히 Manual few-shot CoT prompting 전략은 ChatGPT가 약세를 보였던 패러프레이징과 유사성 판단 작업에서 유의미한 개선을 보여줬습니다.(값이 높을수록 우수합니다.)
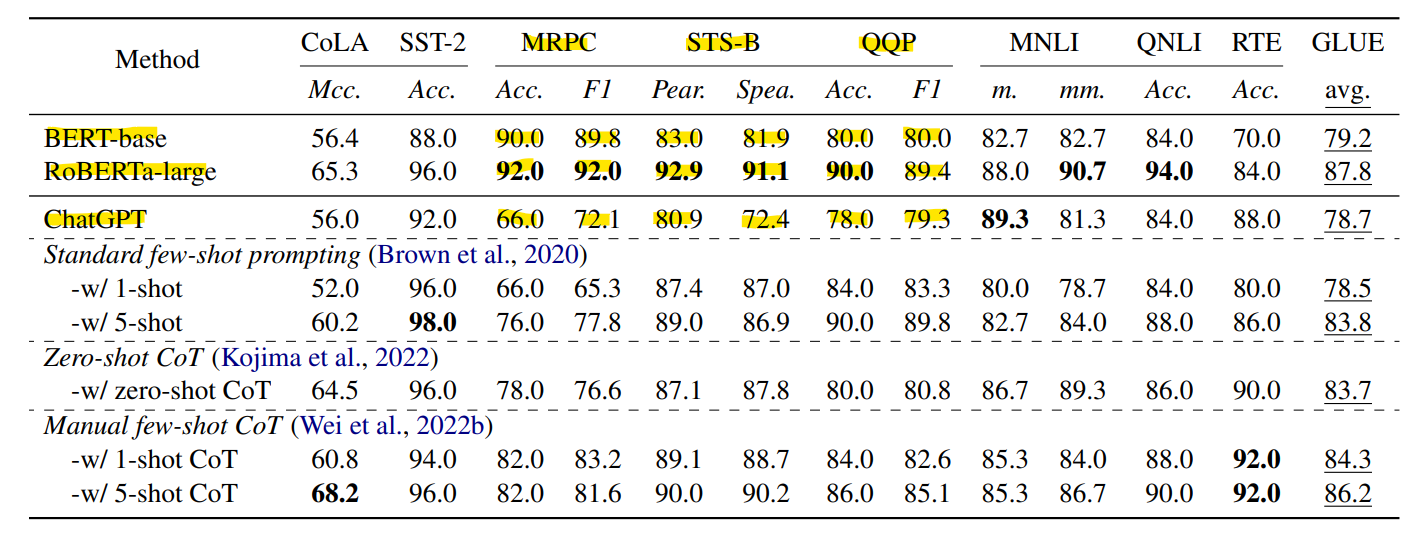
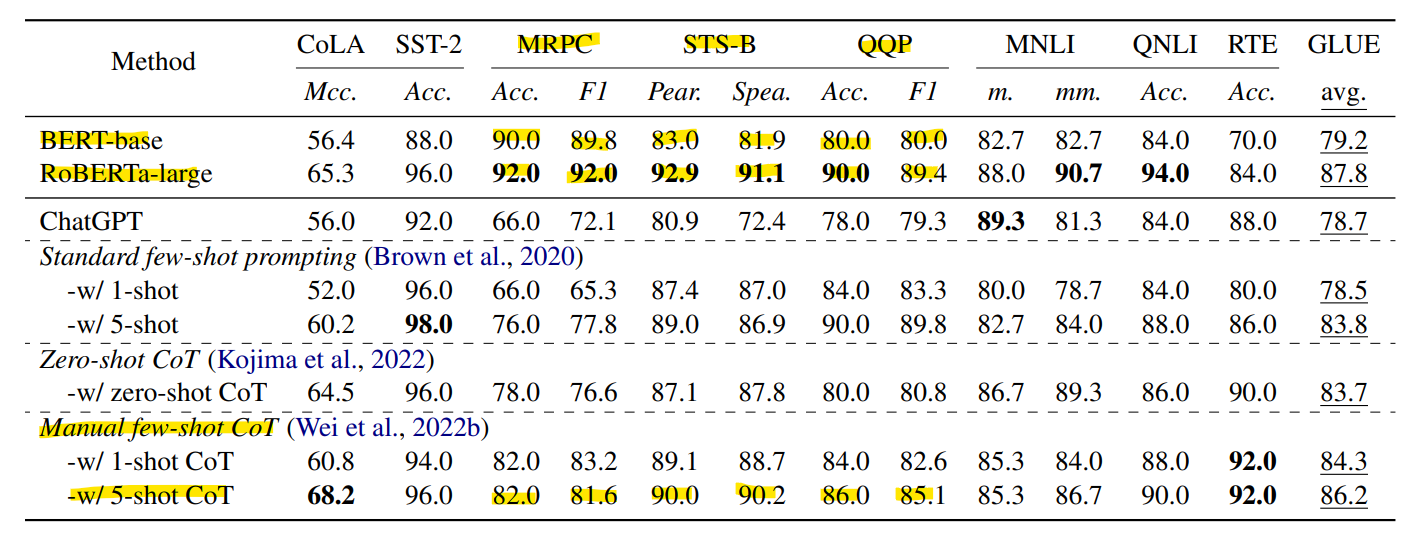
2. 1-shot 전략의 성능은 사용하는 예시에 매우 민감합니다.
: 예시가 하나 뿐이기 때문에 테스트 데이터간의 correlation에 크게 영향을 받기 때문입니다.
결론
- Manual few-shot CoT prompting 등의 방식으로 프롬프트를 개선하면, ChatGPT는 글로벌 최고 성능을 의미하는 SOTA(State-of-the-art) 수준의 모델들과 견줄만한 성능을 보여줬습니다.
- CoT 방식을 적용하여 ChatGPT로 하여금 단계별 추론을 유도하는 것이 성능 향상의 핵심인 것으로 보입니다.
- BERT 모델을 학습시킬만큼 충분한 데이터 확보가 어려울 경우, ChatGPT를 이용하여 자연어 이해(NLU) 작업을 실행할 수 있을 것으로 보입니다.
현재 믿어방 서비스에서는 다음과 같이 유사성 판단을 위해 few-shot CoT 프롬프팅을 적용한 프롬프트 엔지니어링 방법을 채택하였습니다.
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": f"Q: For the sentence pair '계약 연장은 계약 만기 3달 전까지 갱신 의사를 밝혀야만 가능하다.' and '계약 만기 5개월 전 까지 재계약 의사를 밝히지 않은 경우, 계약은 만료되는 것으로 간주한다.', do these two sentences have the same semantics?"},
{"role": "assistant", "content": " First, identify the key differences between the two sentences. Second, consider the impact of the difference in wording. Third, consider the overall meaning of the two sentences. Therefore, given that the two sentences convey the same general idea, despite the difference in wording, we can conclude that they have the same semantics. The answer (yes or no) is: yes."},
{"role": "user", "content": f"Q: For the sentence pair {st1} and {st2}, do these two sentences have the same semantics? The answer (yes or no) is: ____"}
],
temperature=0,
)단순히 두 문장 input이 유사한지를 묻는 프롬프트를 작성했을 때보다 더 나은 유사성 판단력을 보여주었습니다.
