Longhorn 이란,,
kubernetes 클러스터를 위해 Rancher labs에서 개발한 가볍고 안정적이며 강력한 분산 블록 스토리지 시스템 입니다.
longhorn은 컨테이너와 마이크로 서비스를 사용하여 분산 블록 스토리지를 구현하며, 각 block device volume에 대한 전용 longhorn Engine를 만들고 다수의 노드에 저장된 여러 복제본에 걸쳐 volume을 복제하여 동기화 합니다.
Longhorn Engine(storage controller)와 복제본은 쿠버네티스를 사용하여 자체적으로 오케스트레이션 됩니다.
Longhorn을 사용하면 다음과 같은 작업을 수행할 수 있습니다:
Kubernetes 클러스터에서 분산 상태 저장 애플리케이션을 위한 영구 스토리지로 Longhorn 볼륨을 사용할 수 있습니다.
블록 스토리지를 Longhorn 볼륨으로 분할하여 클라우드 제공업체와 상관없이 Kubernetes 볼륨을 사용할 수 있습니다.
블록 스토리지를 여러 노드와 데이터 센터에 걸쳐 복제하여 가용성을 높일 수 있습니다.
NFS나 AWS S3 같은 외부 스토리지에 백업 데이터를 저장할 수 있습니다.
크로스 클러스터 재해 복구 볼륨을 생성하여 주요 Kubernetes 클러스터의 데이터를 두 번째 Kubernetes 클러스터의 백업에서 신속히 복구할 수 있습니다.
볼륨의 주기적인 스냅샷을 예약하고 NFS 또는 S3 호환 보조 스토리지에 주기적인 백업을 예약할 수 있습니다.
백업에서 볼륨을 복구할 수 있습니다.
영구 볼륨을 중단하지 않고 Longhorn을 업그레이드할 수 있습니다.
Longhorn은 독립형 UI를 제공하며, Helm, kubectl 또는 Rancher 앱 카탈로그를 통해 설치할 수 있습니다.
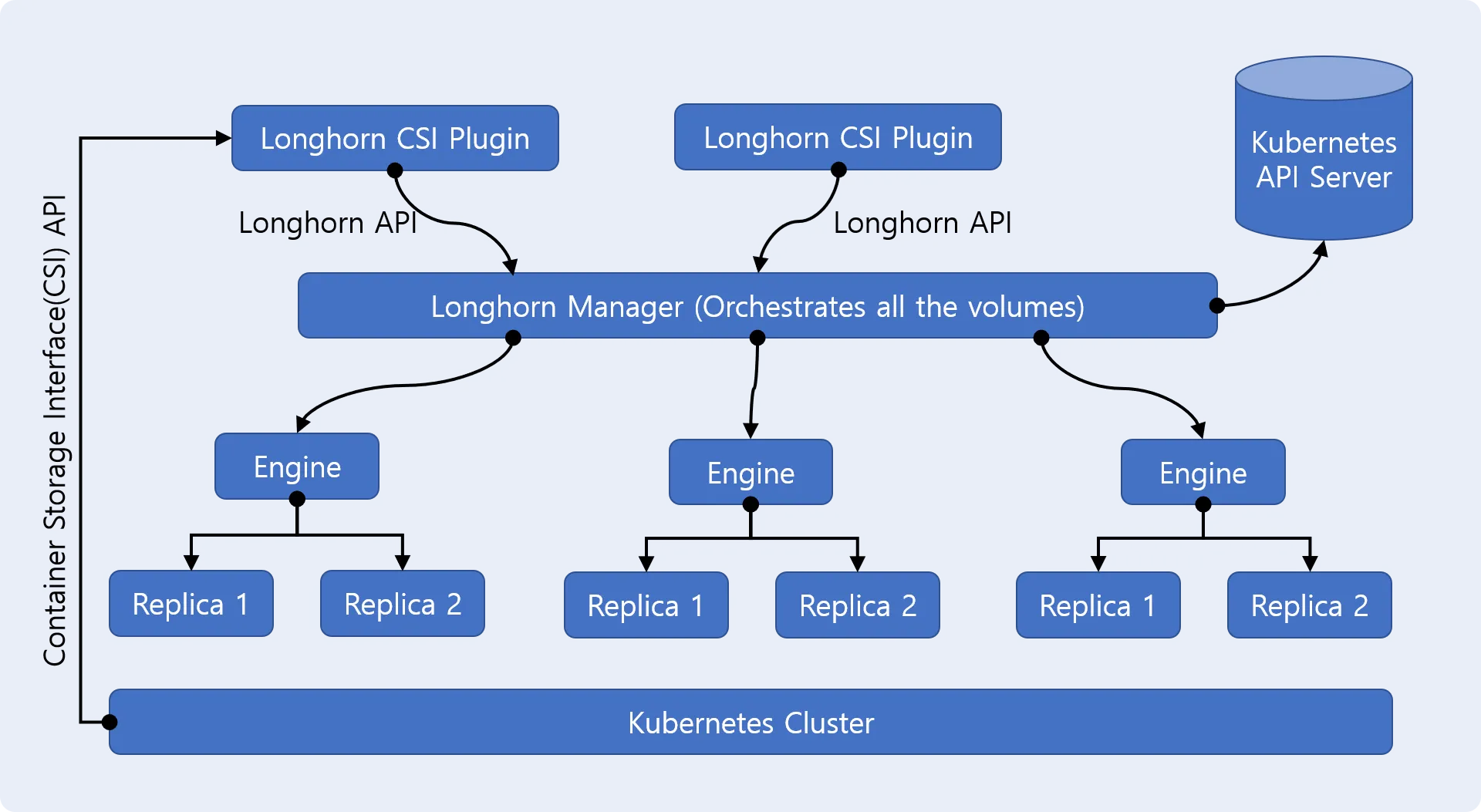
Longhorn Architecture
Longhorn은 Kubernetes에서 실행되는 분산 블록 스토리지 시스템으로, 애플리케이션에 높은 가용성과 안정성을 제공하기 위해 설계되었습니다. 각 요소는 컨테이너 기반으로 동작하며 Kubernetes와 깊은 통합을 이루고 있습니다.
Longhorn Engine(Storage Controller)
Longhorn Engine은 data plane에 해당 하는 Storage Controller이며 항상 Longhorn 볼륨을 사용하는 Pod와 동일한 노드에서 실행 됩니다.
다중 노드에 저장된 여러 복제복(replica)에서 볼륨을 동시에 복제하며, Engine과 복제본들(replicas)은 쿠버네티스에 의해 오케스트레이션 됩니다.
특징
- 각 Longhorn 볼륨에 대해 실행되는 컨트롤러입니다.
- 실제 데이터 읽기/쓰기 요청을 처리합니다.
- 데이터의 복제본 간 동기화를 담당합니다.
- 장애 발생 시 복제본 재구성 및 복구 작업을 수행합니다.
아래의 아키텍처를 보면,
- 각 Pod와 Longhorn 볼륨들이 3개의 인스턴스와 함께 있으며,
- 각 볼륨은 Longhorn Engine이라는 Storage Controller가 Linux 프로세스로 실행 됩니다.
- 각 Longhorn 볼륨에는 두 개의 복제본(replica)이 있으며 각 복제본(replica) 또한 Linux 프로세스 입니다.
- 아키텍처의 화살표는 볼륨 → Engine → 복제본 → 인스턴스(노드) 및 디스크 간의 read/write 데이터 흐름 입니다.
- 각 볼륨들은 개별적인 Longhorn Engine이 생성 되기 때문에 하나의 Engine(또는 storage controller)에 장애가 발생하더라도 다른 볼륨의 기능에는 영향을 미치지 않습니다.

Longhorn Manager
Longhorn Manager는 control plane의 역할을 하며, Longhorn API를 사용하여 volume 생성 요청에 따른 Engine을 생성 하고 volume을 관리 등의 작업을 수행 합니다.
특징
- Longhorn의 핵심 컨트롤러 역할을 합니다.
- 각 Kubernetes 노드에서 실행되며, 볼륨의 상태를 모니터링하고 필요한 작업(예: 복제본 생성/삭제, 백업 관리)을 수행합니다.
- 사용자와의 인터페이스 역할을 하며, Longhorn UI 및 CLI를 통해 요청을 처리합니다.
아래의 아키텍처를 보면,
- DaemonSet으로 각 nodes에 Longhorn Manager Pod 있으며,
- Kubernetes 클러스터에서 볼륨 생성 및 관리를 담당하고, UI와 쿠버네티스 볼륨 plugin에서 API 호출을 처리 합니다.
- Longhorn Manager에 볼륨 생성을 요청하면 볼륨이 연결된 인스턴스(노드)에 Longhorn Engine을 생성하고 복제본(replica)이 배치될 각 노드에 복제본(replica)을 생성하게 됩니다.
- 스토리지의 최대 가용성을 보장하려면 복제본(replica)은 전용 호스트에 배치하는 것을 권장합니다.
Replicas의 읽기/쓰기 작동 방식
Longhorn의 복제본(replica)으로 부터 데이터를 읽기/쓰기에 대한 작동 방식을 알아 보겠습니다.
데이터를 복제본에서 읽을 때 라이브 데이터(Live Data)가 있으면 해당 데이터를 사용하고, 만약 데이터가 없을 경우 최신 snapshot에서 데이터를 가져오게 됩니다.
최신 snapshot에도 데이터가 없다면 다음으로 오래된 snapshot으로 부터 읽는 식으로 데이터를 가져오게 됩니다.
특징
- 데이터를 저장하는 실제 스토리지 유닛입니다.
- 각 볼륨의 복제본은 Kubernetes 노드의 디스크에 저장됩니다.
- 여러 노드에 분산되어 데이터 복제 및 고가용성을 제공합니다.
읽기 인덱스가 가장 최근 데이터를 보유하고 있는 스냅샷을 추적하는 방법
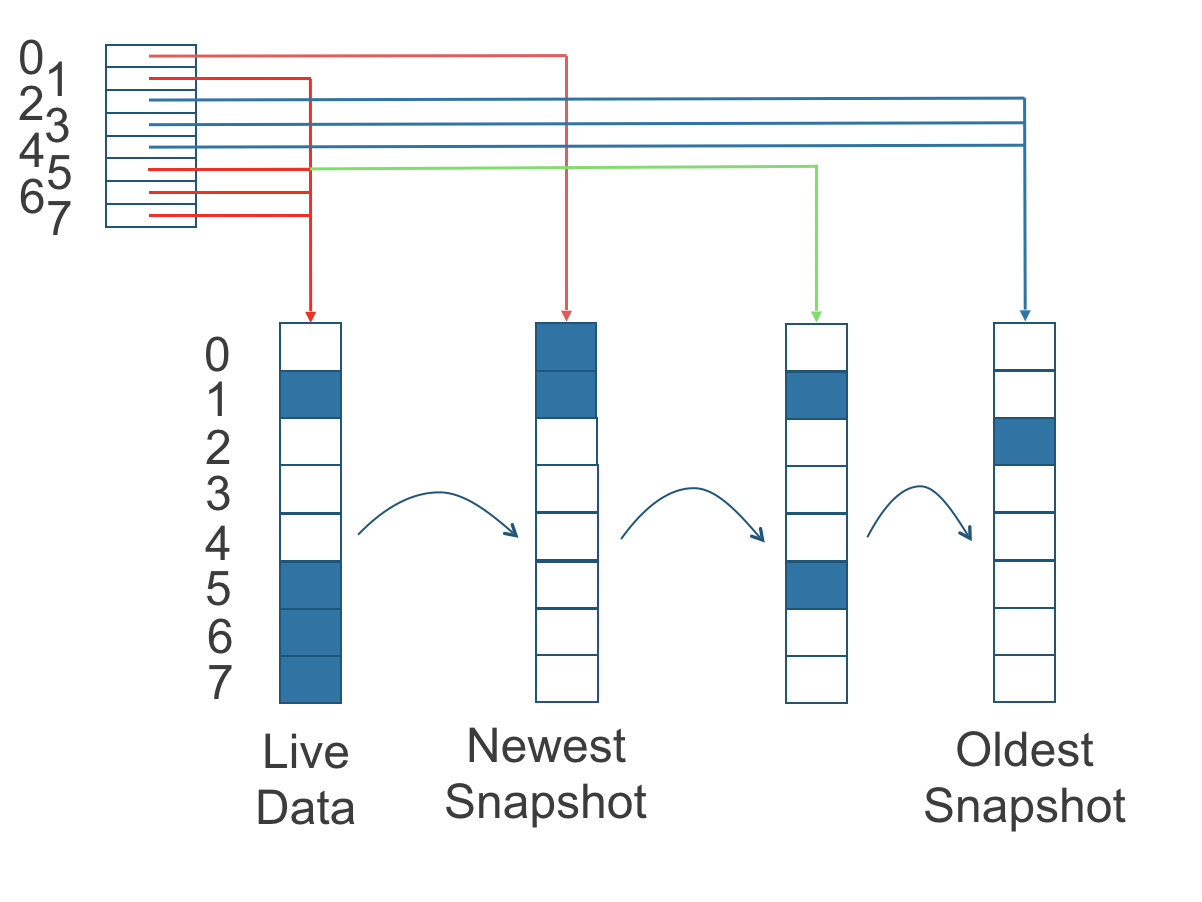
| 인덱스 | 읽기 데이터 출처 |
|---|---|
| 0 | 최신 스냅샷 |
| 1 | 라이브 데이터 |
| 2 | 가장 오래된 스냅샷 |
| 3 | 가장 오래된 스냅샷 |
| 4 | 가장 오래된 스냅샷 |
| 5 | 라이브 데이터 |
| 6 | 라이브 데이터 |
| 7 | 라이브 데이터 |
참고 :
https://longhorn.io/
https://awx.notion.site/Introduction-to-Longhorn-974fcd62047541429bbe3d5aed1c32e2
