지금은 어노테이션 기반이 보편적이며, 최근에는 xml 기반의 설정 방식은 잘 사용하지 않는다.
하지만 여전히 많은 레거시 프로젝트가 xml로 되어 있으므로, xml을 이용한 Bean 등록 방식을 알고 있는 것이 좋다.
또한, xml 방식은 컴파일 없이 Bean 설정 정보를 변경할 수 있다는 장점이 있다.
1. 스프링 Bean 등록 방법
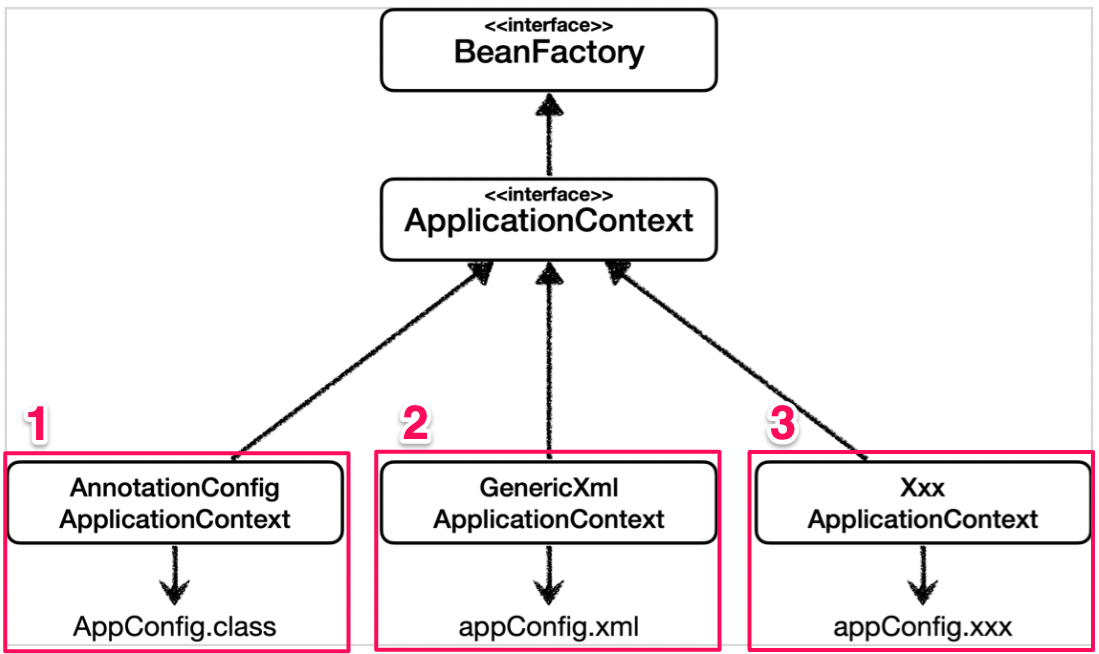
스프링 컨테이너는 다양한 형식으로 스프링 Bean을 등록할 수 있도록 설계 되어 있다.
Bean 등록은 주로 1, 2번의 방식을 주로 사용한다.
1. 어노테이션 기반의 자바 코드를 이용한 방식
2. xml 파일을 이용한 방식
필요할 경우, 직접 설정 파일을 만드는 방식(3)도 가능하다.
어노테이션 기반 자바 코드 설정 방식
- 현재 가장 많이 사용하는 방식으로,
new AnnotationConfigApplicationContext("설정할 클래스 이름".class)를 이용하여 설정할 클래스를 파라미터에 넣어주면 된다.
2. xml 설정 방식
어노테이션 기반의 자바 코드 설정 방식에서는 ApplicationContext의 구현체로 AnnotationConfigApplicationContext를 사용하지만,
xml 방식에서는 GenericXmlApplicationContext 구현체를 사용한다.
Xml을 이용한 Bean 등록
public class XmlAppContext {
@Test
void xmlAppContext() {
ApplicationContext ac = new GenericXmlApplicationContext("AppConfig.xml");
MemberService memberService = ac.getBean("memberService", MemberService.class);
Assertions.assertThat(memberService).isInstanceOf(MemberService.class);
}
}3. BeanFactory와 생명주기 관리
스프링을 사용하는 대부분의 개발자는 이미 만들어진 ApplicationContext를 통해 Bean을 주입받고 사용한다.
하지만 "스프링이 내부적으로 어떤 방식으로 객체를 생성하고 의존성을 주입하는지",
그리고 "Bean의 생명주기를 어떻게 관리하는지"를 이해하기 위해 직접 구현해보았다.
최소한의 DI 컨테이너 구현
SimpleBeanFactory
- XML 파일(
beans.xml)을 파싱하여<bean>정보를 읽고 - 클래스 이름을 기반으로 객체를 생성하며
constructor-arg를 이용해 생성자 주입을 수행- Bean ID를 기준으로 객체를 Map에 저장하고
- 필요할 때
getBean()으로 꺼내쓸 수 있도록 구성
public class SimpleBeanFactory {
private final Map<String, Object> beanMap = new HashMap<>(); // Bean 인스턴스 저장
private final Map<String, Class<?>> classMap = new HashMap<>(); // Bean 클래스 저장
// XML 경로를 받아 BeanFactory 초기화
public SimpleBeanFactory(String xmlPath) {
try {
Document doc = parseXml(xmlPath); // XML 경로 파싱
NodeList beans = doc.getElementsByTagName("bean"); // Bean 노드 리스트 가져오기
preloadBeanClasses(beans); // Bean 클래스 미리 로드
createBeanInstances(beans); // Bean 인스턴스 생성 및 주입
registerShutdownHook(); // 소멸 콜백 등록
} catch (Exception e) {
throw new RuntimeException("BeanFactory 초기화 실패", e);
}
}
... 이후 생략
}Bean 생명주기 관리 구현
스프링은 단순히 객체를 생성하고 주입하는 것을 넘어서,
Bean이 생성되고 소멸될 때까지의 전 과정을 관리할 수 있도록 한다.
| 단계 | 구현 방식 | 설명 |
|---|---|---|
| 생성자 호출 | newInstance() | 객체를 메모리에 생성 |
| 의존성 주입 | constructor-arg 해석 → 생성자 호출 | 다른 Bean을 주입 |
| 초기화 콜백 | InitializingBean.afterPropertiesSet() | Bean 생성 후 1회 실행 |
| 이름 주입 | BeanNameAware.setBeanName() | 자신의 Bean ID 주입 |
| 소멸 콜백 | DisposableBean.destroy() | 애플리케이션 종료 시 자원 정리 |
// 1. 생성자 호출
Object instance = clazz.getDeclaredConstructor().newInstance();
// 2. 의존성 주입 (constructor-arg)
Constructor<?> constructor = clazz.getConstructor(dependency.getClass());
instance = constructor.newInstance(dependency);
// 3. 이름 주입
if (instance instanceof BeanNameAware aware) {
aware.setBeanName(id);
}
// 4. 초기화 콜백
if (instance instanceof InitializingBean init) {
init.afterPropertiesSet();
}
beanMap.put(id, instance);
...
// 5. 소멸 콜백 등록
Runtime.getRuntime().addShutdownHook(new Thread(() -> {
for (Object bean : beanMap.values()) {
if (bean instanceof DisposableBean disposable) {
disposable.destroy();
}
}
}));실제 스프링에서는 이 과정을 어노테이션 기반으로 더 간결하게 제공한다.
@PostConstruct→ 초기화 메서드 호출@PreDestroy→ 소멸 전 후처리 메서드 호출
4. Spring의 DI는 정말 결합도를 낮추는가?
DI(Dependency Injection)는 느슨한 결합을 만들어준다.
하지만 직접 DI 컨테이너를 만들고
Spring의 Bean 등록 방식과 의존성 주입 구조를 살펴보면서
오히려 구조를 강하게 고정시키는 연결 고리가 되고 있는 건 아닌지? 라는 생각이 들었다.
DI의 이상적인 정의
- 객체 간의 직접적인 생성/연결을 외부로 분리하고
- 주입을 통해 필요한 의존성을 넣어주는 방식
이렇게 하면,
- 하나의 객체가 다른 객체의 구현에 의존하지 않고
- 인터페이스에만 의존하게 되어
- 테스트가 용이하고 재사용성이 높아진다.
즉, 결합도는 낮아지고 유연성은 올라간다.
하지만
Spring에서는 대부분 다음과 같은 방식으로 주입한다:
@RequiredArgsConstructor
@Service
public class OrderService {
private final MemberService memberService;
private final DiscountPolicy discountPolicy;
}여기서 객체 간의 관계는 DI로 분리되었지만,
실제로는 @Component, @Bean, @Configuration 등을 통해
전체 Bean 네트워크가 컨테이너에 의해 명시적으로 고정된다.
- 어떤 객체가 어떤 객체를 써야 하는지
- 언제, 어떤 방식으로 생성되는지
→ 스프링 컨테이너가 모두 알고 있다.
즉, "결합을 코드에서 뺐을 뿐, 전체 시스템 구조는 고정되어 있다."
결합도 vs 명시성
| 개념 | 장점 | 단점 |
|---|---|---|
| 느슨한 결합 | 모듈 간 유연성, 테스트 용이 | 구조 파악 어려움, 추적성 부족 |
| 명시적 결합 | 구조 예측 가능, 명확한 책임 | 구조 변경 어려움, 재사용성 낮음 |
실제로 우리는 다음과 같은 상황에 부딪힌다.
- 테스트 코드를 짤 때는 느슨한 결합이 유리하다. (Mock, Stub 등 주입 가능)
- 운영 환경에서는 명확한 연결 관계가 없으면 디버깅이 어려워진다.
- 프로젝트가 커질수록 Bean 관계가 보이지 않으면 구조 불투명성이 문제가 된다.
직접 DI 컨테이너를 구현하고 느낀 점
우리가 직접 SimpleBeanFactory를 만들며 느낀 것은
"결합도를 낮추는 것" 보다
"결합을 설계하고 추적 가능하게 만드는 것"이 더 중요할 수 있다
스프링은 단지 결합을 제거하는 것이 아니라
컨테이너 내부로 결합 관계를 옮기고, 이를
- 라이프사이클 관리
- AOP 적용
- 트랜잭션 제어
등과 유기적으로 통합할 수 있도록 설계했다.
결론
Spring의 DI는 단순히 결합을 없애주는 것이 아니라,
결합을 컨트롤 가능한 방식으로 설계하는 것라고 볼 수 있다.
