DCL
SQL
- DML
- DDL
- DCL - 데이터베이스의 권한에 대한 내용, 트랜잭션을 관리하는 명령어도 포함 (트랜잭션은 따로 TCL이라고도 함)
DCL을 사용하는 이유
- 데이터베이스를 다룰 수 있는 권한을 부여하거나 박탈한다.
- 트랜잭션(Transaction)을 관리한다. 트랜잭션이란 하나의 기능을 수행하기 위한 하나의 논리적인 작업 단위이다. 은행 프로세스에서 많이 사용한다. → 코드 실행 중 하나의 작업이라도 문제가 생겼을 때 전체 기능이 작동하지 않는 것이 트랜잭션.
DCL 구문
| GRANT | 권한 부여 |
|---|---|
| REVOKE | 권한 박탈 |
| COMMIT | 트랜잭션 적용 (트랜잭션 성공처리) |
| ROLLBACK | 트랜잭션 취소, 복구 (트랜잭션 실패처리) |
GRANT, REVOKE
root - 모든 관리자 권한을 가진 user. 즉 관리자 계정
(postgresql은 postgres으로 명칭이 조금 다름.)
계정(사용자)마다 권한을 부여할수도 빼앗을수도 있다.
명령어로 바로 cmd에 입력하여 컴퓨터에 명령을 내리는 방식 CLI
workbench에 적어서 작업하는 방식 GUI
REVOKE
REVOKE [권한] ON [권한을 박탈할 테이블명] FROM [권한을 박탈할 사용자]@호스트명
-- 테이블명에 *.*을 쓰면 모든 테이블에 해당함.
-- PUBLIC은 모든 사용자. 이때 모든 사용자에 권한을 박탈하면 해당 테이블에 접근 가능한 계정은 root
-- 권한을 여러개로 적을 땐 콤마로 구분.-------GRANT
CREATE USER [사용자명] IDENTIFIED BY '1234'
GRANT [권한] ON [테이블명] TO [권한을 받을 사용자]GRANT, REVOKE에서 부여하고 박탈할 수 있는 권한의 종류
이외에 DROP, CREATE 등 도 사용할 수 있음
실무에선 Infra 개발자와 어플리케이션 개발자가 나누어져있다면 분업화가 잘 되어있어 해당 내용을 사용하진 않지만 DB에 직접 INSERT나 UPDATE를 해야한다면 Infra개발자가 작업함. 어플리케이션 개발자는 자바에서 컨트롤.
| SELECT | 조회 권한 |
|---|---|
| UPDATE | 수정 권한 |
| INSERT | 삽입 권한 |
| DELETE | 삭제 권한 |
| ALL | 모든 권한 |
해당 버튼 해제하면 사용자 수동 커밋 모드
수동 커밋 모드일 경우 해당 인스턴스에만 적용되기 때문에 조금 더 마음을 안정적으로 작업할 수 있다.
자동 모드일 경우 begin, end, commit 생략해서 사용.
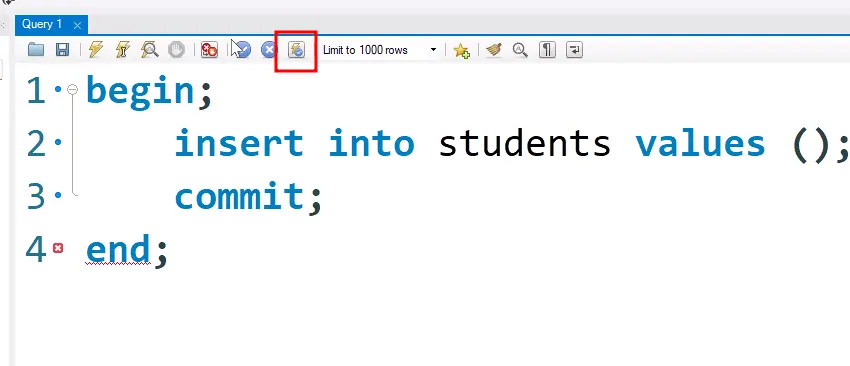
자동 커밋 모드와 수동 커밋 모드의 차이
DDM : 사용자 수동 커밋
DDL : 사용자 자동 커밋
수동 커밋 모드에서는 rollback으로 원상 복구가 가능한데 자동 커밋 모드에서는 안됨.
-- 해당 구문의 사용이
COMMIT;
ROLLBACK;
-- 의미 없음 (DDL) 자동 커밋.
DROP TABLE [테이블명];
TRUNCATE TABLE [테이블명];
ALTER TABLE [테이블명];
-- 의미 있음 (DML) 사용자 커밋.
DELETE FROM [테이블명]- 수동 커밋 모드 테스트
-- students 테이블 데이터 1 추가 -- 커밋이 안된 상태에서 2번 세션에서 select * from students -- 커밋이 안된 데이터는 해당 세션에선 확인할 수 있지만 다른 세션에서 조회 불가능. use test_db; INSERT INTO students VALUES ('hong', 10, '서울'); INSERT INTO students VALUES ('jang', 10, '부산'); SELECT * FROM students; COMMIT;-- 같은 테이블을 사용하고 있어도 세션 1에서 데이터를 추가하고 커밋을 하지 않으면 해당 세션에서 확인 불가능. use test_db; SELECT * FROM students;
COMMIT, ROLLBACK
- 트랜잭션 실습 코드
-- Transaction - 은행 '송금기능' -- 사전 작업 '계좌' 테이블 생성. CREATE TABLE 이 자동 커밋이라 다른 세션에서 확인 가능 CREATE TABLE accounts ( name VARCHAR(100) NOT NULL, balance INT DEFAULT 0 ); INSERT INTO accounts VALUES ('A', 10000); INSERT INTO accounts VALUES ('B', 10000); SELECT * FROM accounts; -- A -> B 5000원 -- 1. A계좌에서 5000원 차감 -- 2. B계좌에서 5000원 추가 BEGIN; -- 하나의 기준점. 생략도 가능. UPDATE accounts SET balance = balance - 5000 WHERE name = 'A'; UPDATE accounts SET balance = balance + 5000 WHERE name = 'B'; ROLLBACK; -- commit(작업 완료)/rollback(원복)
데이터 모델링과 ERD
정규화 (Normalization)
데이터베이스 정규화는 데이터의 구조를 최적화하는 과정. 데이터 중복을 최소화하는데 목적이 있다.
테이블 구조를 효율화하는 과정.
데이터를 핸들링 해주어야 할 때 정규화를 한다.
정규화의 장점
- 일관성
- 정규화된 테이블은 각 테이블이 하나의 목적을 가지고 있기 떄문에 서 쉽게 관리 가능.
- 데이터를 수정하거나 삭제할 때 오류가 발생할 가능성이 줄어들고, 데이터의 일관성을 유지하기가 더 쉬워짐.
- 유연성
- 데이터 구조를 변경하거나 새로운 요구 사항을 쉽게 수용할 수 있다.
- 새로운 속성이나 테이블을 추가하는데 더 유연하며, 변경 사항이 다른 부분에 미치는 영향을 최소화한다.
- 저장 공간 최적화
- 정규화로 저장 공간을 효율적으로 사용할 수 있고 중복 데이터가 제거되므로 데이터 크기를 줄일 수 있고, 저장 공간과 관련된 비용도 절감할 수 있음.
즉, 데이터 관리가 쉬워지고, 새로운 요구 사항에 유연하게 대응할 수 있고, 저장 공간의 비용을 절감하기 위해 정규화를 사용한다고 할 수 있다.
제 1 정규화 (1NF)
각 열이 하나의 값을 가지게 하는 과정.
- 예시 원본 데이터
정규화된 데이터주문번호 제품명 제품구성 1 노트북 CPU, RAM, SSD 2 스마트폰 CPU, RAM, 배터리 3 스마트워치 CPU, 배터리 주문번호 제품명 제품구성 1 노트북 CPU 1 노트북 RAM 1 노트북 SSD 2 스마트폰 CPU 2 스마트폰 RAM 2 스마트폰 배터리 3 스마트워치 CPU 3 스마트워치 배터리
제 2 정규화 (2NF)
제 2 정규화는 테이블의 비주요 속성이 기본키에 대해 완전 함수 종속되도록 하는 것이다. 즉 모든 열이 기본키(primary key)에 의존해야 한다는 것.
현재 테이블의 주제와 관련없는 칼럼을 다른 테이블로 분리하는 작업.
- 예시 원본 데이터
정규화된 데이터주문번호 제품명 제조사 1 노트북 삼성전자 2 스마트폰 엘지전자 3 스마트워치 애플 -
주문 테이블
주문번호 제품명 1 노트북 2 스마트폰 3 스마트워치 -
제품 테이블
제품명 제조사 노트북 삼성전자 스마트폰 엘지전자 스마트워치 애플
-
제 3 정규화 (3NF)
제2 정규화를 완료한 테이블에서 이행적 함수 종속성을 제거하는 과정.
이행적 함수 종속이란 A -> B 종속, B -> C 종속, A -> C 종속인 관계
즉, 일반 컬럼에만 종속된 컬럼은 다른 테이블로 빼는 것
각 테이블이 하나의 주제를 가지게끔 분리.
- 예시 원본 데이터
정규화된 데이터 주문 테이블주문번호 고객명 주소 제품명 제품 카테고리 1 오르미 서울 노트북 전자제품 2 내리미 부산 스마트폰 전자제품 3 하늘별 제주 카메라 전자제품
제품 테이블주문번호 고객명 제품명 1 오르미 노트북 2 내리미 스마트폰 3 하늘별 카메라
고객 테이블제품명 제품 카테고리 노트북 전자제품 스마트폰 전자제품 카메라 전자제품 고객명 주소 오르미 서울 내리미 부산 하늘별 제주
좋은 설계란 데이터를 효율적으로 처리하는 것.
역정규화
Join이 너무 많아지는 DB 설계와 쿼리는 요청을 처리하는 시간을 증가시키는 문제가 있기 떄문에 모든 주요 Entity를 분리하는 것이 좋은 것이 아니라 DB의 전반적인 성능을 향상시킬 수 있는 구조화 과정을 거치는 것이 필요하다.
역정규화는 중복을 허용하며 Entity를 다시 통합하거나 분할하여 정규화 과정을 통해 도출된 DB 구조를 재조정하는 과정이다.
데이터 모델링
데이터 모델링이란 데이터베이스를 구축하기 위해 데이터의 구조와 관계를 시각적으로 표현하는 것.
데이터 모델링의 단계
- 요구사항 분석
- 개념적 모델링
- 논리적 모델링
- 물리적 모델링
- 테이블을 만들고 직접적인 데이터를 날리는 단계.
개념적 모델링
비즈니스 요구 사항을 파악하고 이를 데이터 모델로 표현하는 단계.
데이터를 의미 있는 단위로 분류하고 관계를 정의.

회색의 사각형은 개체(테이블)를 의미하고, 파랑색의 마름모는 관계를 의미한다. 회원 정보와 주문 정보는 주문이라는 관계를 가지고 있음을 확인할 수 있다.
논리적 모델링
개념적 모델을 기반으로 데이터의 구조와 관계를 구체화하는 단계.
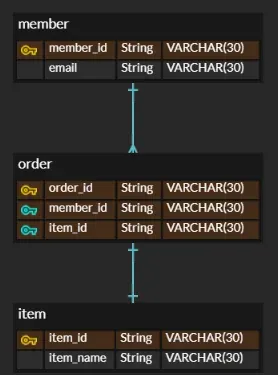
개념적 모델링보다 논리적 모델링에서 구체화된 부분
- 각 테이블의 필드 정보
- 테이블 간의 관계 (1:1, 1:N, N:M)
물리적 모델링
논리적 모델링을 기반으로 실제 데이터베이스로 구현하는 단계.
시각적으로 표현했던 모델을 SQL문을 통해 실제 테이블로 만든다.
데이터 모델링 과정 정리
- 요구 사항이 무엇인지 분석
- 요구 사항을 충족하기 위해 필요한 데이터를 정하고, 그들의 관계를 설정하는 개념적 모델링
- 개념적 모델을 구체적인 표로 만드는 논리적 모델링
- 실제 데이터베이스 테이블로 만드는 물리적 모델링
ERD
Entity-Relationship Diagram(개체-관계 다이어그램)의 약자
개체(Entity) 간의 관계(Relationship)를 시각적으로 표현할 때 사용
개념적 모델을 기반으로 데이터의 구조와 관계를 구체화하는 단계이다.
논리적 모델링의 방법 중 하나
ERD의 구성 요소
Entity(개채), Attribute(속성), Relationship (관계) 세 개로 이루어져 있음
1. 개체(Entity)
개체는 고유하게 식별할 수 있는 사물, 개념, 사건 등 의미
개체는 데이터베이스에서 테이블로 표현된다.
개체 예) 사용자, 제품, 주문…
2. 속성(Attribute)
속성은 개체의 특징이나 성질을 나타내고 하나의 개체는 여러 개의 속성을 가질 수 있다.
속성은 데이터베이스에서 테이블의 column(열)로 표현된다.
속성의 예) 학생 개체의 속성으로는 학번, 이름, 주소 …
3. 관계(Relationship)
관계는 개체 간의 연결
관계에는 일대일(1:1), 일대다(1:N), 다대다(N:M) 유형이 있다.
1:1의 예시 - 학생과 신체정보
1:N의 예시 - 학생과 취미
N:M의 예시 - TV와 제조업체
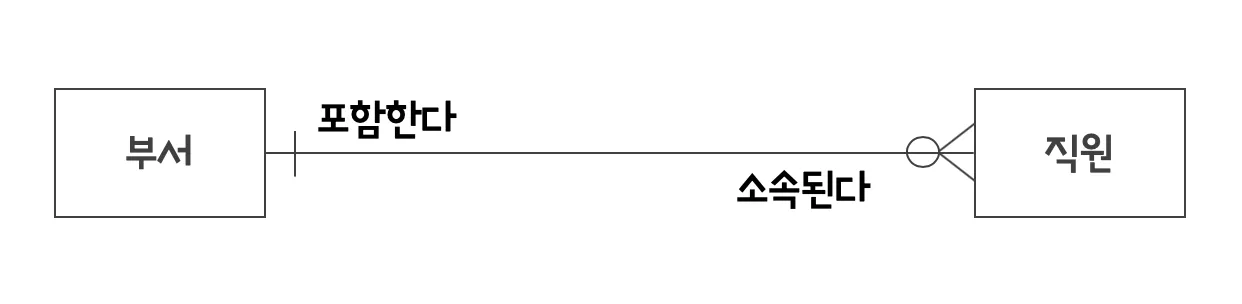
까마귀발 표기법
관계의 다(n)을 나타내기 위해 까마귀 발을 사용하기 떄문에 때떄로 까마귀 발모델(Crow’s Foot Model)이라 부른다.
까마귀발 기호
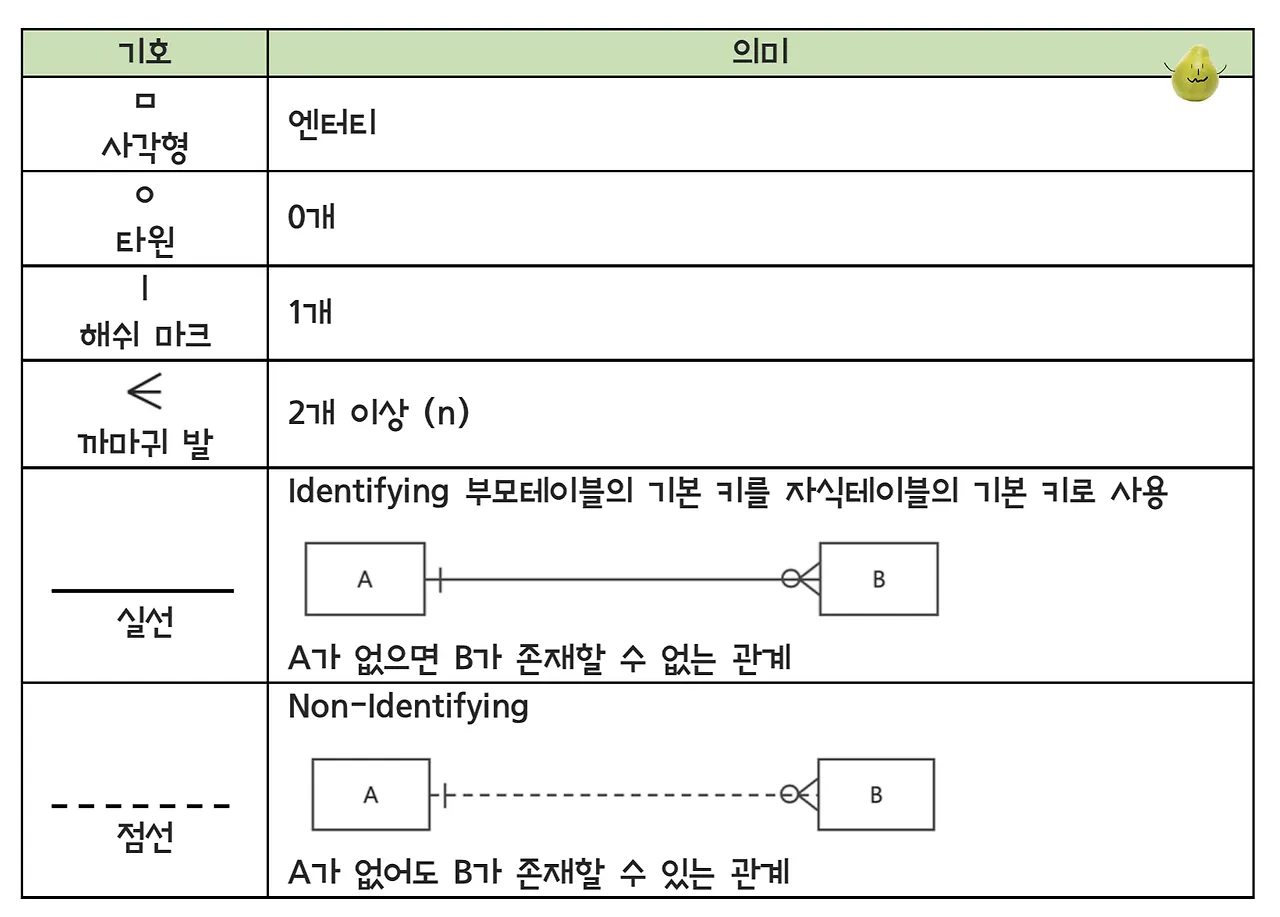
까마귀발 관계

하나의 A는 하나의 B로 구성되어 있다.

하나의 A는 0 또는 하나의 B로 구성되어 있다.

하나의 A는 두 개 이상의 B로 구성되어 있다.

하나의 A는 하나 이상의 B로 구성되어 있다.

하나의 A는 0,1,또는 그 이상의 B로 구성되어 있다.

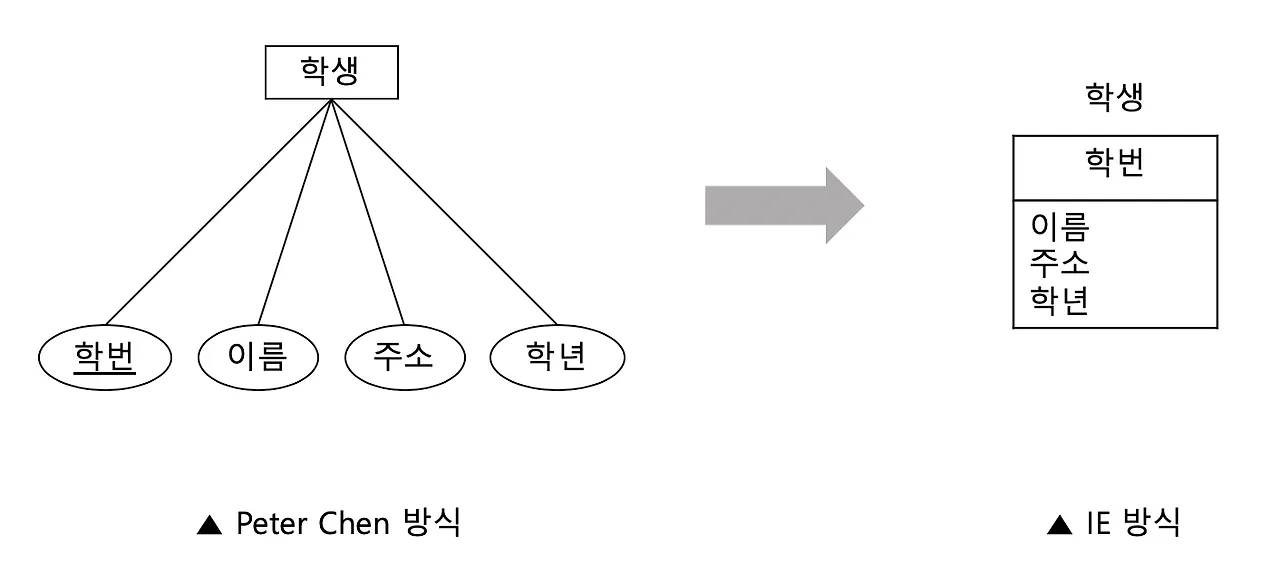
→ IE/Crow’s Foot 방식에서는 개체 타입과 속성을 표(직사각형)으로 표현하며, 개체 이름을 표 위에 작성하고 식별자를 첫번째 행에 작성한다.
ERD 표기법을 이용하여 모델링 작업 순서
- 개체를 작성후 적절하게 배치한다.
- 개체간 관계를 설정한다
- 기본 키로 속성이 상속되는 식별자 관계를 설정한다.
- 중복되는 관계가 있으면 안된다.
- Circle 관계가 발생하면 안된다
- 관계명을 기술한다.
- 현재형을 사용한다.
- 지나치게 포괄적인 용어는 사용하지 않는다.
- IE/Crow’s 표기법에서는 링크마다 각각의 관계를 기술한다.
- 관계의 참여도와 관계의 필수 여부를 기술한다.
ERD를 그려볼 수 있는 웹 사이트
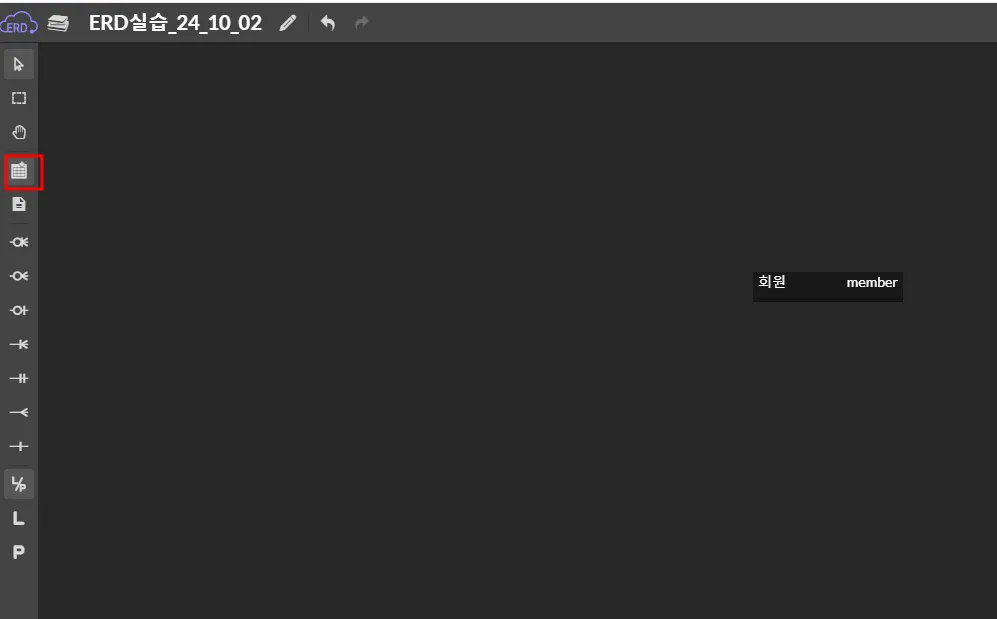
새로운 엔티티 추가

노란색 - PK 컬럼 , 파란색 - 일반 컬럼
-
데일리 퀴즈

까마귀 발 출처
