조건절
WHERE 조건절에서 필터링 가능
- IS NULL - Null인 column을 필터링 해줌 (IS NOT NULL은 반대)
null 과 ‘’은 다른 값 - LIKE, wildcard(%,_)
-
LIKE - 문자열을 필터링 해주는 명령어. wildcard와 함께 씀
-
wildcard - _는 하나의 글자, %는 여러 개의 글자를 의미함 두 개를 혼합해서 사용해도 괜찮음.
예) WHERE name = '정약용'; WHERE name LIKE '정__'; // 정ㅇㅇ 인 이름이 전부 출력 WHERE name LIKE '정%'; // 정만 붙어 있으면 모두 출력. 글자수 상관 x
-
- IN - 특정 value값을 넣어서 걸러내고 싶을 때 사용. 타입 상관없이 숫자 넣어도 괜찮음. 괄호 내에 SQL문을 작성해서 자주 사용함. (NOT IN 은 반대)
이때 NULL은 해당 조건에 부합해도 노출 안되고 IS NULL 조건절을 사용해서 출력해주어야 한다.
예) 정약용, 이황 2명을 걸러내고 싶을때
WHERE name IN ('정약용', '이황');그룹화
같은 값을 가진 행(column)끼리 하나의 그룹으로 뭉치는 기능
내장함수와 함께 많이 사용
GROUP BY 기준 columnGROUP BY
-- FROM -> WHERE -> GROUP BY -> SELECT 순으로 실행.
-- 만약 정렬 조건이 붙으면 order이 마지막으로 실행.
SELECT 열, 집계함수
FROM 테이블
[WHERE 필터 조건]
GROUP BY 열
-- 예시 주소별 학생 평균 나이
SELECT address, AVG(age)
FROM students
GROUP BY address
-- 예시 결과
| address | avg |
| --- | --- |
| 경상남도 | 35.0000000000000000 |
| 서울특별시 | 33.5000000000000000 |
| 경기도 | 32.3333333333333333 |
| 경상북도 | 28.0000000000000000 |
| 전라북도 | 30.5000000000000000 |- GROUP BY 절은 FROM, WHERE절 뒤에 위치한다
- GROUP BY 절은 어떤 열을 기준으로 그룹화할 지 명시해야 한다.
- WHERE 절 실행 후 GROUP BY가 실행된다.
HAVING
GROUP BY 절에 의해 생성된 그룹 중에서 원하는 조건에 부합하는 그룹 만을 선택하는 구문
반드시 GROUP BY와 함께 써야함.
-- FROM -> WHERE -> GROUP BY -> HAVING -> SELECT 순으로 실행.
SELECT 열, 집계함수
FROM 테이블
[WHERE 필터 조건]
GROUP BY 열
HAVING 그룹 필터 조건
-- 예시 학생 수가 2명 이상인 주소만 조회하고 싶을 때
SELECT address, COUNT(*)
FROM students
GROUP BY address
HAVING COUNT(*) >= 2
-- 예시 결과
| address | count |
| --- | --- |
| 서울특별시 | 2 |
| 경기도 | 3 |
| 전라북도 | 2 |ORDER BY
ORDER BY 절에는 어떤 열을 기준으로 정렬할지 명시해야한다.
ASC : 오름차순 (별도 명시 하지 않으면 디폴트로 오름차순)
DESC : 내림차순
SELECT 열, 집계함수
FROM 테이블
[WHERE 필터 조건]
GROUP BY 열
HAVING 그룹 필터 조건
ORDER BY 열 [ASC | DESC]
-- 예시 나이가 많은 학생 TOP 3만 조회
SELECT *
FROM students
ORDER BY age DESC
LIMIT 3
-- 예시 결과
| name | age | address |
| --- | --- | --- |
| 박두진 | 36 | 경기도 |
| 한용운 | 35 | 경상남도 |
| 김광균 | 34 | 서울특별시 |JOIN, UNION
JOIN을 하기 위해선 테이블을 연결하기 위한 key가 있어야 하고 접점이 되는 데이터를 가지고 있어야한다.
두 개 이상의 테이블을 엮어야 원하는 결과가 나올 때 사용하는 것이 JOIN.
즉 테이블을 합칠 때 사용. 관계형 데이터베이스에서 필수
-- 예시) 기본 문법. 학생 테이블과 수업 테이블을 합치는데 공통된 키값을 연결
FROM students AS t1 JOIN classes AS t2
on t1.name = t2.nameJOIN
- column의 수가 늘어남
- 같은 키 값만 있으면 붙일 수 있음
UNION
- row의 수가 늘어남
- column의 정보가 같으면 안에 어떠한 것이 와도 붙일 수 있음
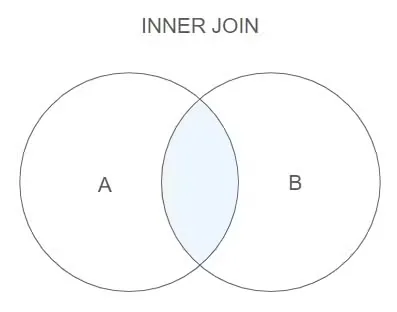
INNER JOIN
전, 후로 명시한 두 개의 테이블을 JOIN 한다는 의미.
교집합이 출력된다.
OUTER JOIN
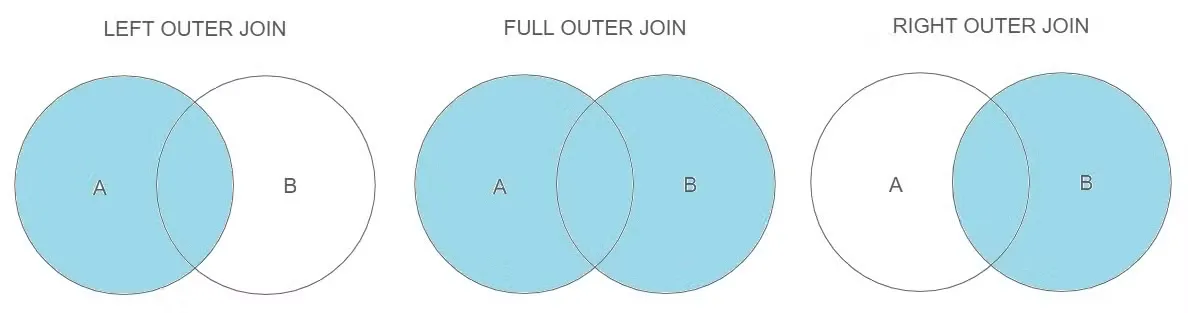
OUTER JOIN은 종류와 관계없이 두 테이블을 조인할 때 1개의 테이블에만 데이터가 있어도 결과가 나온다.
FULL OUTER JOIN - MySQL에서는 지원하지 않음.
LEFT OUTER JOIN - 왼쪽 테이블의 모든 값이 출력되는 조인
SELECT [열 목록]
FROM [LEFT 테이블] LEFT OUTER JOIN [RIGHT 테이블]
ON [조인 조건]
[WHERE 검색 조건]RIGHT OUTER JOIN - 오른쪽 테이블의 모든 값이 출력되는 조인
SELECT [열 목록]
FROM [LEFT 테이블] RIGHT OUTER JOIN [RIGHT 테이블]
ON [조인 조건]
[WHERE 검색 조건]UNION
SQL 실행 결과를 하나로 이어붙이는 형태
UNION은 테이블 사이에 관계성(1:1, 1:N …)이 없어도 사용할 수 있다.
-- UNION 의 기본 구문
[SQL 1]
UNION
[SQL 2];UNION 결합 조건
- [SQL 1]과 [SQL 2]의 열 개수가 같아야 한다
- [SQL 1]과 [SQL 2]의 열 이름이 같아야 한다
- [SQL 1]과 [SQL 2]의 각 열의 데이터 타입이 동일해야 한다.
UNION - 중복된 정보는 1개만 출력
UNION ALL - 중복된 정보도 모두 다 출력. 둘 중에 성능이 더 좋음.
-- UNION ALL 의 기본 구문
[SQL 1]
UNION ALL
[SQL 2];서브 쿼리
하나의 SQL문 안에 포함되어 있는 또 다른 SQL문을 의미한다.
최종 결과를 출력하는 쿼리를 메인 쿼리라고 한다면 메인 쿼리를 보조 역할을 하는 것이 서브 쿼리라고 할 수 있다.
스칼라 서브 쿼리
SELECT 절에서 사용하는 서브 쿼리
1개의 값만 리턴 해야 한다. 그렇지 않으면 1242 오류가 난다.
SELECT
name,
age,
(SELECT AVG(age) FROM students) AS avg_age -- 스칼라 서브 쿼리 생김새. 1개의 값.
FROM students
WHERE age < 30
-- 결과
| name | age | avg_age |
| --- | --- | --- |
| 이황 | 28 | 32.0000000000000000 |
| 정약용 | 29 | 32.0000000000000000 |위의 경우엔 한 개의 값이 여러 개로 출력된다.
CASE WHEN THEN ELSE END
SELECT
CASE
WHEN(조건 A) THEN A
WHEN(조건 B) THEN B
ELSE C
END AS 원하는 컬럼명
FROM TABLE;FROM 절에서 사용하는 서브 쿼리
SELECT * -- c.* , s.*
FROM
(
SELECT name, class_name
FROM classes
WHERE class_name IN ('데이터베이스', '알고리즘')
) as c
// 이떄 as c 뒤에 바로 JOIN students AS s ON c.name = s.name 이렇게 연결해서 사용도 가능
-- 결과
| name | class_name |
| --- | --- |
| 이황 | 데이터베이스 |
| 이황 | 알고리즘 |
| 정약용 | 데이터베이스 |
| 박지원 | 데이터베이스 |
| 김홍도 | 알고리즘 |
| 신윤복 | 알고리즘 |
| 김광균 | 데이터베이스 |
| 김광균 | 알고리즘 |FROM절의 서브 쿼리의 경우 서브 쿼리의 결과를 마치 가상의 테이블처럼 사용할 수 있다.
WHERE 절에서 사용하는 서브 쿼리
조건으로 사용 가능.
SELECT name, age, address
FROM students
WHERE name IN ( -- = WHERE name IN (알고리즘을 듣는 학생 목록)
SELECT name
FROM classes
WHERE class_name IN ('데이터베이스', '알고리즘')
)
// 만약 WHERE name = (서브 쿼리) 가 온다면 해당 서브 쿼리의 값이 1개여야 성립 가능하고 자주 사용하진 않는다.
-- 결과
| name | age | address |
| --- | --- | --- |
| 이황 | 28 | 경상북도 |
| 정약용 | 29 | 경기도 |
| 박지원 | 31 | 전라북도 |
| 김홍도 | 32 | 경기도 |
| 신윤복 | 33 | 서울특별시 |
| 김광균 | 34 | 서울특별시 |- 실습 코드
-- 240927 수업 ---------------------------------------------- use test_db; CREATE TABLE tmp ( id INT NOT NULL, name varchar(255) ); INSERT INTO tmp (id, name) VALUE (1, '민지'), (2, '해린'), (3, null), (4, '다니엘'), (5, '하니'), (6, '혜인'), (7, 'newjeans'); UPDATE tmp SET name = '' -- null 과 '' 은 다른 값 WHERE id = 3; -- IS NULL SELECT id, name FROM tmp WHERE name IS NULL; -- name IS NOT NULL -- LIKE, Wildcard SELECT id, name FROM tmp WHERE name LIKE '_지'; -- WHERE name LIKE '%지%' -- IN SELECT * FROM tmp WHERE name IN ('민지','newjeans') -- name NOT IN OR name IS NULL; -- GROUP BY SELECT address, count(*) FROM students GROUP BY address; -- Q1 나이가 30세 이상인 학생기준으로 그룹핑 SELECT address, count(*) FROM students WHERE age >= 30 GROUP BY address; -- Q2 같은 주소지에서 가장 나이가 많은 학생의 나이는> SELECT address, MAX(age) FROM students GROUP BY address; -- HAVING SELECT address, count(*) FROM students GROUP BY address HAVING count(*) > 1; SELECT address, count(*) FROM students GROUP BY address HAVING count(*) >= 2; -- ORDER BY SELECT address, count(*) AS cnt FROM students GROUP BY address ORDER BY cnt; -- 내림차순 / 오름차순 -- 정렬 기준(열) 다르게 (ORDER BY 다르게) -- LIMIT(row수 제한), OFFSET(시작 인덱스) 사용 SELECT address, name, age FROM students ORDER BY age DESC LIMIT 3 OFFSET 0; -- LIMIT : 출력될 row 갯수 제어. OFFSET : 몇번째 row부터 출력될지 제어, index라고 봐도 됨. SELECT address, name, age FROM students ORDER BY name desc LIMIT 5 OFFSET 1; SELECT address, count(*) AS cnt FROM students GROUP BY address ORDER BY cnt LIMIT 5 OFFSET 0; -- Q. 29세 이상인 학생들을 '주소'로 그룹핑하고 학생수가 3명 이상인 그룹만 출력해주세요. 단, 출력할 때 학생수가 적은 순서대로 정렬해주세요. -- FROM -> WHERE -> GROUP BY -> HAVING -> SELECT -> ORDER BY SELECT address, count(*) FROM students WHERE age >= 29 GROUP BY address HAVING count(*) >= 3 ORDER BY count(*) desc; -- students LEFT OUTER JOIN classes -- SELECT s.name, s.address, c.class_name SET SQL_SAFE_UPDATES = 0; DELETE FROM students WHERE name = '이황'; SELECT * FROM students AS s LEFT OUTER JOIN classes AS c ON s.name = c.name; SELECT * FROM students AS s RIGHT OUTER JOIN classes AS c ON s.name = c.name; -- RIGHT OUTER JOIN로 출력되되 이름은 한번만 SELECT s.age, s.address, c.name, c.class_name FROM students AS s RIGHT OUTER JOIN classes AS c ON s.name = c.name; -- UNION, UNION ALL SELECT name, age FROM students WHERE age < 30 UNION ALL SELECT name, age FROM students WHERE age < 32; -- scala sub query SELECT name, address, (SELECT CASE WHEN(age < 30) THEN '20대' ELSE '30대' END AS '나이' FROM students b WHERE b.name = a.name -- 해당 구문이 없으면 여러개의 값을 리턴해서 오류남 ) FROM students a; -- FROM 절에 들어가는 sub query SELECT * -- c.* , s.* FROM ( SELECT name, class_name FROM classes WHERE class_name IN ('데이터베이스', '알고리즘') ) as c INNER JOIN students AS s ON c.name = s.name; SELECT * -- c.* , s.* FROM ( SELECT name, class_name FROM classes WHERE class_name IN ('데이터베이스', '알고리즘') ) as c JOIN students AS s ON c.name = s.name; SELECT * -- = SELECT * FORM classes WHERE class_name IN('데이터베이스', '자료구조', '알고리즘') FROM ( SELECT name, class_name -- = * FROM classes WHERE class_name IN ('데이터베이스', '자료구조', '알고리즘') ) AS C; -- SQL문에서 조건문 작성하는 방법 : CASE WHEN THEN ELSE END SELECT name, address, CASE WHEN(age < 30) THEN '20대' WHEN(age < 40) THEN '30대' ELSE '...' END AS '나이' FROM students; -- 서브쿼리 말고 JOIN 쿼리로 작성, '데이터베이스', '알고리즘' 수강하는 학생 목록 (name, age, address) SELECT S.name, S.age, S.address FROM students AS S JOIN classes AS C on S.name = C.name WHERE class_name IN ('데이터베이스', '알고리즘');
