하루뒤에 온다 해놓고, 푹 쉬고 와버렸다,,
바로 시작하자.
제목이 C언어 입문 with 자료구조인 이유는, 두 책 같은 얘기를 하기 때문이다. Linked List 이야기를 하는데, C언어 입문에서 간단하게 이론을 익히고 ( 더 쉽게 설명해준다. ) 자료구조 책에서 다시 한번 익히고, 조금 더 심층적으로 들어가보는 구조로 복습을 할 거다.
C언어 입문, 18-5
우리는 동적 할당의 장점 중 하나가 "프로그램 실행 중 데이터를 저장할 크기를 입력받아 변경할 수 있다" 였다. 물론 정적 할당에 비해 좋기는 하지만, 여전히 단점은 있다.
만약 물품 금액을 입력하여 합산하는 계산기를 만들고 싶다고 가정하자. 만약 이걸 지금까지 배운 "동적 할당"으로만 프로그램을 만들면, "물품 개수"를 입력 받고 그 개수대로만 금액을 입력할 수 있다. 만약 5개를 입력하면, 5개의 금액인 만원, 이만원, 삼만원, 만원, 사천원. 이렇게만 입력할 수 있다는 거다.
그런데 일반적으로 계산기를 쓴다고 하면 "몇 개의 숫자를 사용할 것"인지는 일일히 묻지 않고, 알아서 "="을 입력하면 그 전까지 입력받은 숫자 계산들을 알아서 해주는 식이다. (이 문단을 A라고 한다)
앞선 동적 할당에서는 이런게 안되었던 이유가, 할당된 주소를 저장할 포인터 변수가 1개밖에 없었기 때문이다.
그래서 이걸 효율적으로 여러개를 만들어서 앞서 A문단에서 언급한 구조를 구현할 수 있는 구조가 있다.
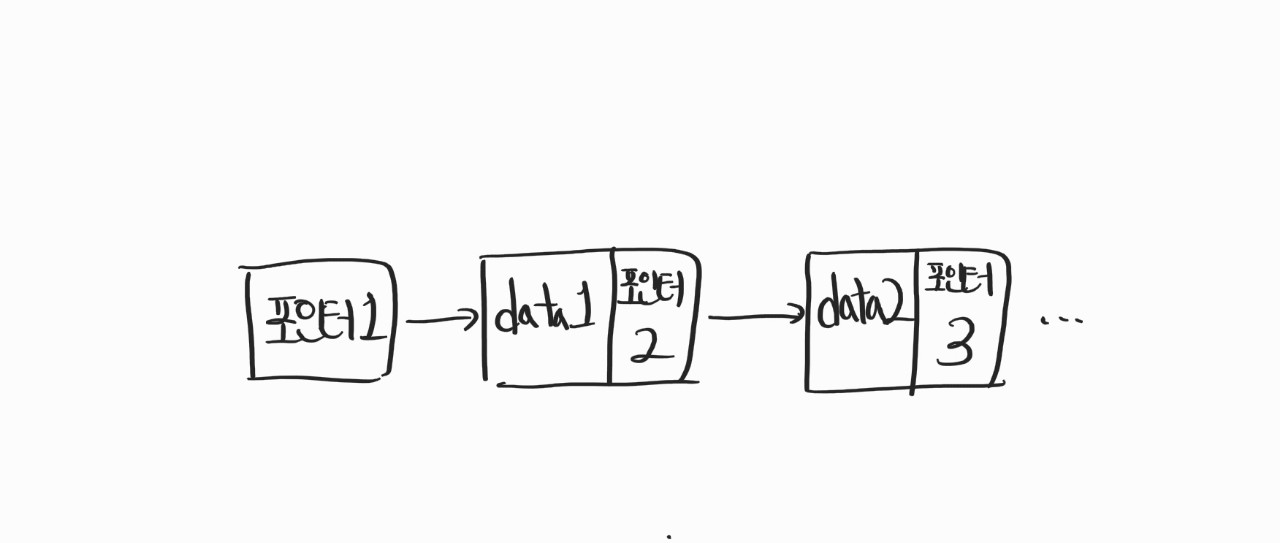
이런 식으로! 동적으로 할당된 메모리가 포인트로 연결되어있는 구조다.
이걸 Linked List라고 한다.
그리고 앞서 저 data와 포인터 한 블럭을 합쳐서 "노드"라고 한다. 알아두자.
이 노드의 기본적인 코드는
typedef struct __node {
int data; // data를 저장할 변수
struct node *next;
// 다음 노드를 가리킬 포인터, 즉 뒤의 노드와의 연결의 도구.
}라는거. 미리 인지해 두자.
지금부터는 자료구조 책으로 넘어가보자.
자료구조, Ch 04-1
자료구조 책을 기준으로, 앞서 "ADT", List 자료구조 특성 / 배열 기반 구현을 익혔다.
그러면 이번엔 위에서 언급한 Linked List를 익히고 구현해보자.
우선, 연결 리스트가 돌아가는 기본적인 원리를 이해하기 위해 그냥 아주 기본적인 코드 하나를 복습해보겠다.
#include <stdio.h>
#include <stdlib.h>
typedefs struct _node {
int data;
struct _node *next;
} Node;
int main() {
Node *head = NULL;
Node *tail = NULL;
Node *cur = NULL;
int readdata; // 입력받을 데이터 readdata
Node *newNode = NULL;
while (1) { // 데이터 입력 과정
scanf("%d", &readdata);
if (readdata < 1) break; // 만약 0 입력시 프로그램 종료
newNode = (Node *)malloc(sizeof(Node));
// 새로운 노드를 할당한다!
newNode -> data = readdata;
// 할당된 새로운 노드에 들어갈 data는 입력받은 read data
newNode -> next = NULL;
if (head == NULL) head = newNode;
// 만약 입력받은 데이터가 없으면 head에 데이터 입력받음
else tail->next = newNode;
// 앞서 입력받은 데이터가 있다면 그 뒤로 쭉쭉 저장
tail = newNode;
}
if (head == NULL) { // 데이터 조회 과정
printf("data가 없습니다\n");
} else {
cur = head;
printf("%d ", cur);
while (cur->next != NULL) {
cur = cur->next;
printf("%d ", cur);
}
}
if (head == NULL) { // 데이터 삭제 과정
return 0;
} else {
Node *delNode = head;
Node *delNextNode = head->next;
free(delNode);
if(delNextNode != NULL) {
delNode = delNextNode;
delNextNode = delNextNode->next;
free(delNode);
}
}
return 0;
}이런 식이다. 내가 복습하는 내용이니, 나만 알아볼 수 있으면 되니까, 그냥 코드만 내가 배운걸 토대로 붙여놨다. 직접 적어보면서 익히면 되니깐.
우선, 단순한 "단순 연결 리스트"를 학습해보도록 하겠다. 이 형태는 그냥 한 쪽 방향으로만 연결이 전개가 되는 것이다.
이 연결 리스트의 ADT는 저번 Ch.03에서 정의한 친구들과 똑같지만, 정렬 관련 기능 추가를 위해 하나를 더 추가한다.
// LData는 typedef int LData; 임.
// 리스트에 저장할 데이터의 자료형에 제한을 두지 않기 위해 선언함.
void ListInit (List *plist);
// 리스트 초기화. 변수를 처음 정의하고 초기화 하는 것과 같은 맥락
void LInsert (List *plist, LData data);
// list에 data 저장
int LFirst (List *plist, LData *pdata);
// 첫 번째 데이터 참조
int LNext (List *plist, LData *pdata);
// 두 번째 ~ 마지막 데이터들 참조
LData LRemove (List *plist);
// 데이터 삭제. 삭제된 데이터는 반환된다.
int LCount (List *plist);
// 리스트에 저장된 데이터 개수를 반환한다.
/* 새로 추가된 ADT */
SetSortRule (List *plist, int (*comp)(LData d1, LData d2);
뒤에 int (*comp) 뭐시기.. 저게 뭐냐고 물어본다면, 함수 포인터다.
이 velog에 아직 C언어 복습 내용을 올리진 않았지만, 그런게 있다.
뭔지 간단하게 다시 요약하고 가자면, "특정 함수를 구성하는 시작 명령의 위치를 가리키는 포인터"다.
만약 main함수에 앞서
int Sum(int a, int b) {
int result = 0;
result = a+b;
return result;
}라는 함수를 set했다고 가정하자.
그러면 이후 int (*p)(int,int)로 sum함수를 가리키는 함수 포인터를 set하고,
p = &Sum 처럼 함수의 주소를 p에 저장하면
int result = (*p)(3,4); 와 같은 식으로 함수를 사용할 수 있게 된다.
다시 원래 내용으로 돌아오자. 앞의
SetSortRule (List *plist, int (*comp)(LData d1, LData d2);에서 뒤의 함수 포인터는 "리스트의 정렬 기준"을 정해준다. 만약 이 함수가
int WhoIsPrecede (LData d1, LData d2) {
if (d1 < d2) return 0;
else return 1;
} 이렇게 된다면, "d1에 전달되는 인자가 정렬순서상 앞서서 head에 더 가까워야 하면 0을 반환, d2에 전달되는 인자가 정렬 순서상 앞서거나 같으면 1을 반환한다" 라는 의미가 된다. 자세한 응용은 이후에 다루겠다.
내가 C언어에서 배웠던 "연결 리스트" 에 관한 내용은, head 부분에 처음 데이터가 저장되고 (LFirst), 이후 데이터들을 쭉 쭉 연결하며 (LNext) tail을 사용하여 리스트를 만드는 과정이였다.
지금부터 다룰 연결 리스트는 이 "첫 번째 노드"에 변화를 줄 것이다.
앞서서 다룬 연결 리스트는 "노드를 추가 / 삭제 / 조회하는 모든 과정에서 첫번째 노드 / 그 이후의 노드들이 각각 차이가 있었다."
그래서 코드가 간결해지지 않고 각 경우를 모두 생각해줘서 구현해야 하는데, 이 "첫 번째 노드에 변화를 주는 연결 리스트" 대로라면 이게 간결해진다.
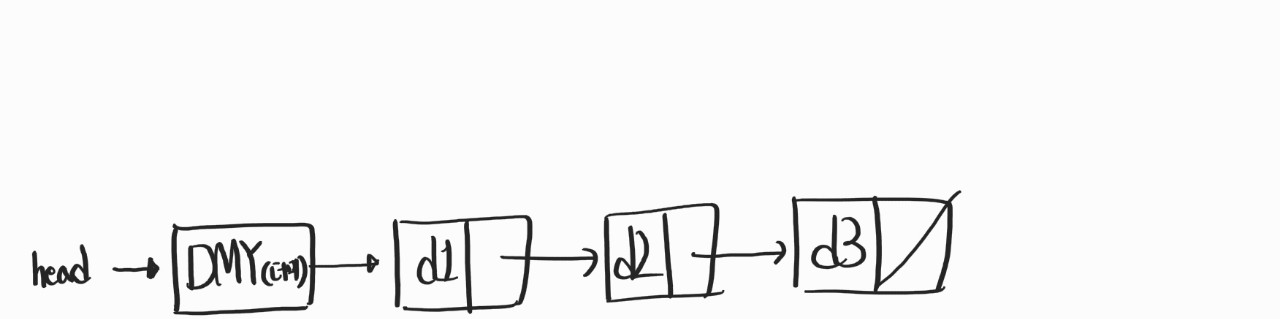
이렇게 되는거다. 보면, tail이 사라졌다!
앞서 Ch.03에서 배열 기반 리스트를 구현할 때 ArrayList.h를 정의 했었는데, 이 때
typedef struct __ArrayList
{
LData arr[LIST_LEN];
int numOfData;
int curPosition;
} ArrayList;
typedef ArrayList List;이런식으로, 배열 리스트를 의미하는 구조체를 별도로 정의했었다. 이번에도 이렇게 할 것이다.
typedef struct __LinkedList
{
Node *head; // DUMMY NODE
Node *cur; // 참조, 삭제 support
Node *before; // 삭제 support
int numOfData; // 데이터 수
int (*comp) (LData d1, LData d2); // for 정렬 기준 등록
} LinkedList;
typedef LinkedList List;이 구조체가 LinkedList.h 헤더파일에 들어가게 될 것이다. 그리고 이 헤더파일의 나머지 요소들은 뭐 Ch.03에서 본 친구들과 다 같다. SetSortRule과 Node 구조체, 이 연결리스트 구조체가 추가되고 바뀐거 정도? 가 차이일거다.
우선, 이 연결 리스트를 이 줄 아래부턴 그냥 리스트라 하고, DUMMY NODE는 DMY로 표기하겠다.
ADT를 구체적으로 짜보자.
구조체의 변수가 선언되었으니, 연결 리스트를 만들려면 가장 먼저 초기화를 진행한다.
지금 이 DMY 노드가 있는 구조에서 "리스트의 초기화"는, 더미노드를 만들어 주는 과정을 의미한다.
자세한 설명이 어느정도 필요한 부분은 주석으로 달아놨다.
void ListInit (List *plist) {
plist->head = (Node *)malloc(sizeof(Node));
// 더미 노드 만듬
plist->head->next = NULL;
plist->comp = NULL; // 정렬 기준이 아직은 없음
plist->numOfData = 0;
}이렇게 초기화를 해준다면 아래 그림과 같은 구조가 나올것이다.

이후, 노드를 추가해준다.
void LInsert(List *plist, LData data) {
if(plist->comp = NULL) FInsert(plist, data);
else SInsert(plist, data);
}
"아니 FInsert랑 SInsert가 먼데요!"
"힝!"
- 기다려봐.이 쪼꼬미 말대로, 헤더파일엔 이 FInsert와 SInsert가 없다. 잠시 대기. 리스트 내부적으로 호출이 되도록 정의한 함수니까.
그러면, FInsert랑 SInsert는 어케 생겼냐.
void FInsert(List *plist, LData data) {
Node *newNode = (Node *)malloc(sizeof(Node));
//새 노드 들어옴
newNode -> data = data;
newNode->next = plist->head->next;
// 새 노드가 다른 노드를 가르키도록 한다
plist->head->next = newNode;
// 더미노드의 다음이 새로 생긴 이 노드
(plist->numOfData)++
// 노드 한개 늘어남
}즉, 정렬 기준이 마련되어있지 않다면, 새 노드는 DMY 노드의 다음 부분에 추가된다는 얘기다.
SInsert는 조금 있다가..
그러면 이번엔 LFirst, LNext를 보자.
int LFirst(List *plist, LData *pdata) {
if (plist->head->next == NULL) return FALSE;
// 만약 DMY노트 뒤에 데이터가 하나도 없다면 FALSE
plist->before = plist->head; // 조회할 첫 노드의 앞부분은 더미노드
plist->cur = plist->head->next;
// 조회할 현재 노드는 더미 노트의 다음 부분, 즉 첫 노드
*pdata = plist->cur->data; // 현재 위치의 데이터 조회
return TRUE;
}int LNext(List *plist, LData *pdata) {
if(plist->cur->next == NULL) return FALSE;
//현재 참고하고 있는 노드 뒤에 더 이상 노드가 없다면 FALSE
plist->before = plist->cur; //before 하나 뒤로 이동
plist->cur = plist->cur->next; //cur 하나 뒤로 이동
*pdata->cur = plist->cur->data;
return TRUE;
}그렇다.
그 다음은 노드의 삭제인 LRemove 인데, 얘는 노드 새로 추가하는거만큼이나 조금 까다롭다.
LData LRemove(List *plist) {
Node *rpos = plist->cur;
LData rdata = plist->cur->data;
plist->before->next = plist->cur->next;
plist->cur = plist->before;
free(rpos);
(plist->numOfData)--;
return rdata;
}그림으로 표현 해보겠다.
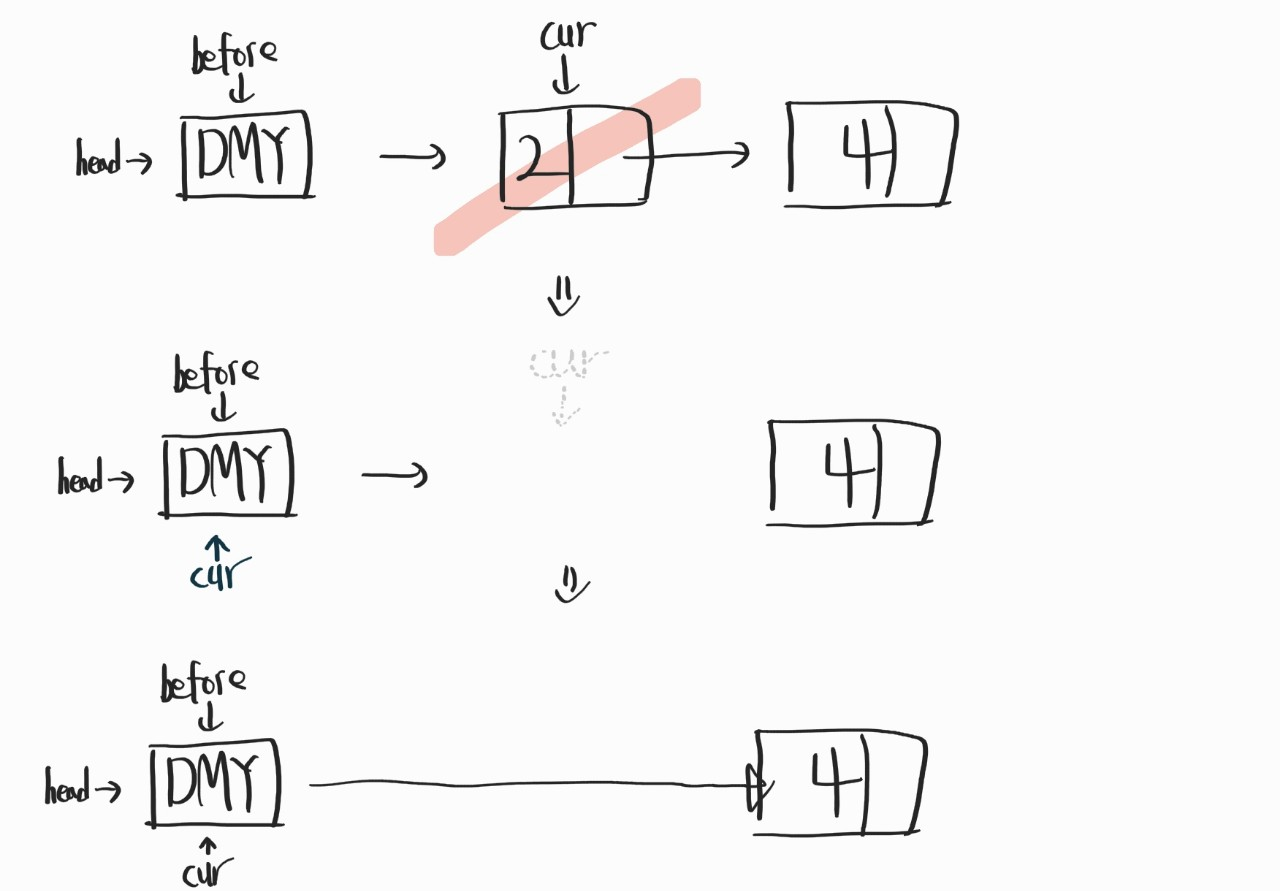
위와 같은 과정이 되는거다.
어 before는 왜 안 옮겨?
뭐 어짜피 나중에 진행되려면 cur만 하나 다시 뒤로 옮기면 되는데, 굳이 before은 앞으로 갔다 뒤로 갔다 할 필요가 없다. 그래서 그냥 쟨 놔뒀다.
복습이 너무 루즈해지고 길어지고 있다.. 나머진 내일 끝내겠다.
