노래 가사를 통한 자연어 생성 모델 만들기
이번주 자연어 처리 과정을 진행하면서 배운 내용을 정리하고 싶어서 이렇게 정리하게 되었다.
다양한 전처리 방법도 있고, 생성 방법이 있지만 아주 기본적인 keras tokenizer와 konlpy를 이용하여 자연어 생성 모델을 만들어 보았다. Token화 되지 않은 단어가 들어간다면 생성을 할 수 없겠지만 생성 모델을 조금이나마 이해하고자 만들어 보았다.
Text Generation
- 시점별로, 준비된 단어들 중 어떤 단어를 가져와야 적절할지 '선택'하는 문제이다.
- 선택이란 곧, 분류이다.( 적절한 선택 or 그렇지 않은 선택들 )
- 당연히, 데이터가 엄청 많아야 '작사'다울 수 있다.
- 데이터가 부족한 지금은, 모델은 고장난 앵무새일 수 밖에 없다.
텍스트 데이터에 대한 자연어 모델에 이식을 위한 전처리 방법
형태소 구분이 되어 있고 불용어 처리 같은 과정들은 생략하고 진행하겠다.
크게 3부분으로 나누어서 설명할 수 있다.
- tokenize = 단어들을 index화 하여 번호를 지정해준다.
- text seq를 tokenize한 idx seq로 변경해준다.
- 모델에 적용하기 위해서 문장의 길이를 통일해준다. (padding, timming)
김동률 감사 가사를 활용한 생성 모델만들기
눈부신 햇살이 오늘도 나를 감싸면
살아있음을 그대에게 난 감사해요
부족한 내 마음이 누구에게 힘이 될 줄은
그것만으로 그대에게 난 감사해요
그 누구에게도 내 사람이란 게
부끄럽지 않게 날 사랑할게요
단 한순간에도 나의 사람이란걸
후회하지 않도록 그댈 사랑할게요
이제야 나 태어난 그 이유를 알 것만 같아요
그대를 만나 죽도록 사랑하는게
누군가 주신 나의 행복이죠
그 어디에서도 나의 사람인걸
잊을 수 없도록 늘 함께 할게요
단 한순간에도 나의 사랑이란 걸
아파하지 않도록 그댈 사랑할게요
이제야 나 태어난 그 이유를 알 것만 같아요
그대를 만나 죽도록 사랑하는게
누군가 주신 내 삶의 이유라면
더 이상 나에겐 그 무엇도 바랄게 없어요
지금처럼만 서로를 사랑하는게
누군가 주신 나의 행복이죠
전처리
* 가사를 문장내림에 맞춰서 문장으로 구분하기
gasa = gasa.split("\n")
* konlpy를 이용하여 전처리(형태소 분석)
from konlpy.tag import Okt
okt = Okt()
# 이랬던 문장이.
print("원본 문장 : ", gasa[1])
# okt.morphs -> 형태소 분석기
형태소토큰 = okt.morphs(gasa[1])
print("형태소 기준으로 tokenize : ", 형태소토큰)
다시문장으로 = " ".join(형태소토큰)
print("다시 문장으로 : ", 다시문장으로)원본 문장 : 살아있음을 그대에게 난 감사해요
형태소 기준으로 tokenize : ['살아있', '음', '을', '그대', '에게', '난', '감사해요']
다시 문장으로 : 살아있 음 을 그대 에게 난 감사해요
* 원본문장을 형태소 분석에 맞게 나누어 문장으로 만들기
print("원본 문장 : ", gasa[3])
for idx, sentence in enumerate(gasa) :
gasa[idx] = " ".join( okt.morphs(sentence) )
print("변경 후 :", gasa[3])원본 문장 : 살아있 음 을 그대 에게 난 감사해요
변경 후 : 살아있 음 을 그대 에게 난 감사해요
* 가사를 띄어쓰기 기준으로 toeknize하고, idx sequence로 만들기
keras의 Tokenizer를 불러와 형태소로 구분된 가사에 존재하는 모든 단어들을 인덱스처리해준다.
Embedding과정에서 문장의 길이를 맞춰주기 위한 padding이 필요하기 때문에 전체 단어의 수는 토큰화한 단어 + 1개이다.
from tensorflow.keras.preprocessing.text import Tokenizer
tk = Tokenizer()
tk.fit_on_texts(gasa)
gasa_seq = tk.texts_to_sequences(gasa)
vocab_size = len(tk.index_word)+1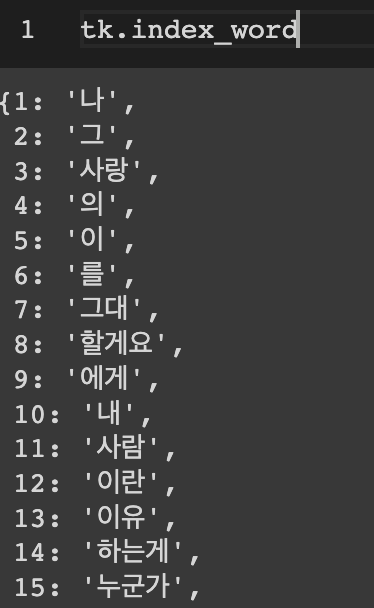
idx sequence화 된 문장들을 생성모델에 맞추어 재구성 해보기
gasa sequence가 [ [1,2,3], [7,2,9,10] ] 라면
gasa_seq = [ [1, 2], [1,2,3], [7,2], [7,2,9], [7,2,9,10] ] 이런식으로 변경해주어야 한다.
그래야 어떤 문장이 들어가든 토큰화된 단어 안에서는 문장을 만들어 줄 수 있다. 문장길이의 제한도 있겠지만.
re_gasa_seq = []
for seq in gasa_seq:
for i in range(1, len(seq)):
re_gasa_seq.append(seq[:i+1])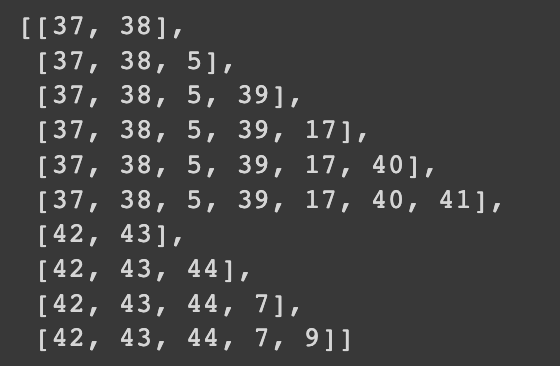
* 모델에 input으로 사용하기 위해 문장 길이를 가장 긴 문장의 길이에 맞춰 통일
전처리된 가사 문장들 중에서 가장 길이가 긴 문장의 길이를 공통 문자길이로 설정한다.
또한 모든 문장의 길이를 맞추기 위해서 keras의 pad_sequences를 사용한다.
패딩의 위치를 지정해줘야 하는건 알겠는데 왜 하는지는 잘 모르겠어서 GPT에게 물어봤다.
이전 시점의 정보를 사용할 예정이라 padding = 'pre'로 설정해주면 될거 같다.
pad_sequnces를 사용하게 된다면 padding 토큰은 0으로 지정되게 된다.
from tensorflow.keras.preprocessing.sequence import pad_sequences
max_len = max(len(seq) for seq in re_gasa_seq)
pad_gasa_seq = pad_sequences(re_gasa_seq, maxlen=max_len, padding='pre')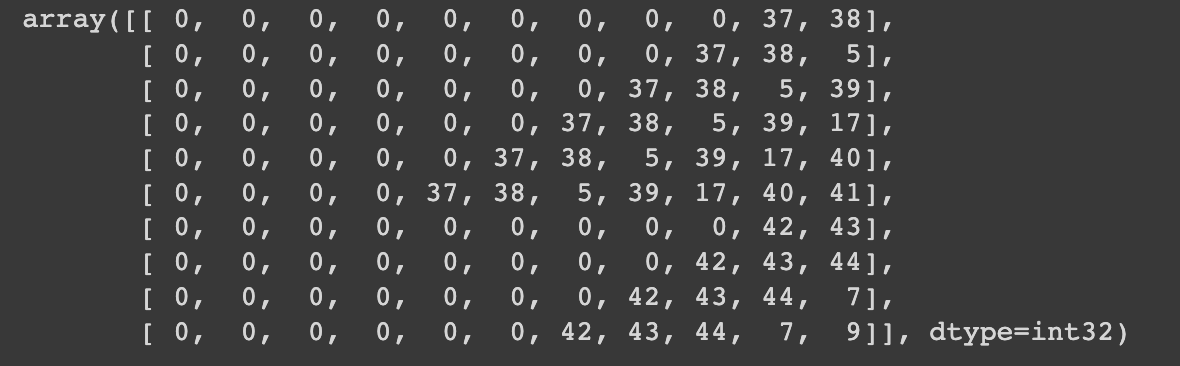
* 학습 데이터 만들기 (pad_gasa_seq의 마지막 컬럼은 y로, 나머지 컬럼은 x로 분리)
문장들을 재구성할 때 단어의 갯수를 2개부터 시작한 이유는 뒤에 나올 단어를 나눌때 편하게 하기 위해서였다.
sequence에서 마지막에 나오는 단어는 앞에 입력들에 대한 출력값으로 생각해주면 된다.
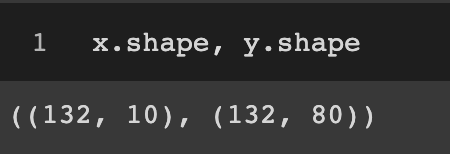
x = pad_gasa_seq[:, : -1]
y = pad_gasa_seq[:, -1]* y를, vocab_size에 맞추어 원핫 인코딩 하기.
모델입장에서는 분류모델로 생각하기 때문에 y데이터에 대해서 keras의 to_categorical을 이용하여 one-hot인코딩 해준다.
from tensorflow.keras.utils import to_categorical
y = to_categorical(y, num_classes = vocab_size)이렇게 전처리를 마무리하면 다음과 같이 데이터가 만들어지게 된다.
간단한 모델 만들기
- 모델 구조는 아래와 같다.
- 임베딩 레이어 : 임베딩 차원 32
- GRU, 32, 모든 출력을 다음 layer로
- GRU, 48, 모든 출력을 다음 layer로
- GRU, 64, 마지막 출력만 다음 레이어로.
- 멀티클래스 분류 아웃풋레이어
## 모델 쌓기
# Input Layer
il = Input(shape=(10))
# Embedding
em = Embedding(input_dim = vocab_size,
output_dim = 32,
input_length = max_len-1 )(il)
# GRU
hl = GRU(32, return_sequences=True)(em)
# GRU
hl = GRU(48, return_sequences=True)(hl)
# GRU
hl = GRU(64, return_sequences=False)(hl)
# output layer
ol = Dense(vocab_size, activation = 'softmax')(hl)
# model 생성
model = Model(il, ol)
# Compile
model.compile(loss = 'categorical_crossentropy',
optimizer = keras.optimizers.Adam(),
metrics = 'accuracy')
model.summary()학습데이터 양이 적었기 때문에 모델 성능은 기대조차 할수도 없어서 여기서 마무리하는게 좋을거 같다. 노래 가사 안에 있는 단어를 잘 골라서 토큰화 하여 모델에 넣는다면 이상한 말도 안되는 문장들이 만들어 질것 같다.
그래도 한번 만들어 보았다.

역시나 말이 안된다.
seq2seq, attention, transformer를 사용해서 다시한번 만들어봐도 재밋을거 같다.
