CNN
CNN 한글로 풀어 말하자면 합성곱 신경망을 의미한다.
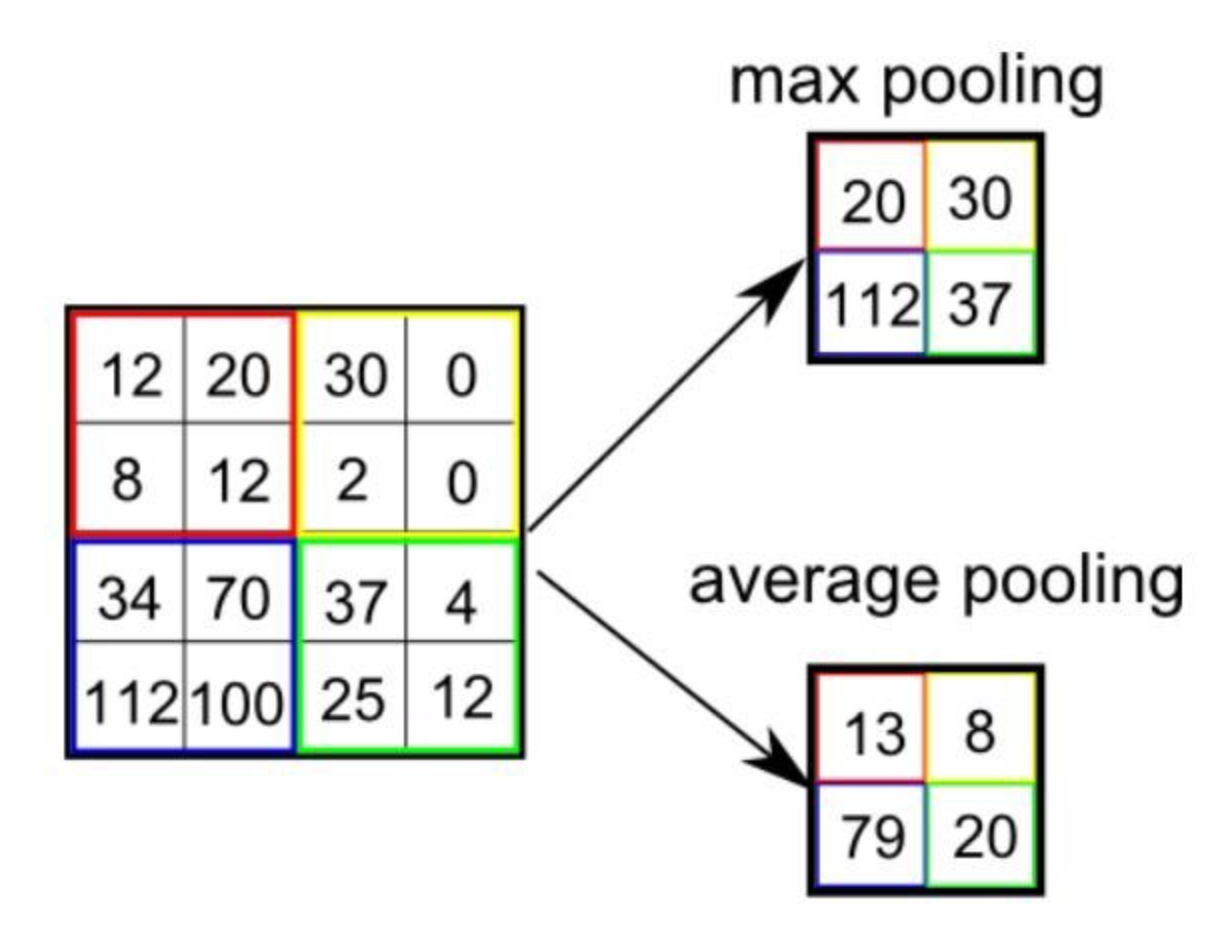
입력 데이터로 부터 Feature를 추출하기 위해 합성곱(Convolution)과 풀링(Pooling)과정을 거친다. 합성곱은 입력 데이터에 필터를 적용하여 Feature Map을 추출하는 과정이다. 풀링은 특징 맵에서 정보를 간추리는 (Down Sampling)과정으로, 최대값 풀링(Max Pooling)과 평균값 풀링(Pooling)등이 있다.
CNN은 딥러닝 알고리즘 중에서도 이밎와 같은 2D 데이터를 처리하는데 강점이 있다.
CNN이 기존 Fully Connected Neural Network와 비교하면 다음과 같은 차별성을 갖는다.
-
각 레이어의 입출력 데이터의 형상 유지
-
이미지 공간 정보를 유지하면서 인접 이밎와의 특징을 효과적으로 인식 (Fliter)
-
복수의 필터로 이미지의 특징 추출 및 학습 (표현 학습과 분류를 동시에 진행)
-
추출한 이미징의 특징을 모으고 강화하는 Pooling 레이어
-
필터를 공유 파라미터로 사용하기 때문에, 일반 인공 신경망과 비교하여 학습 파라 미터가 매우 적음
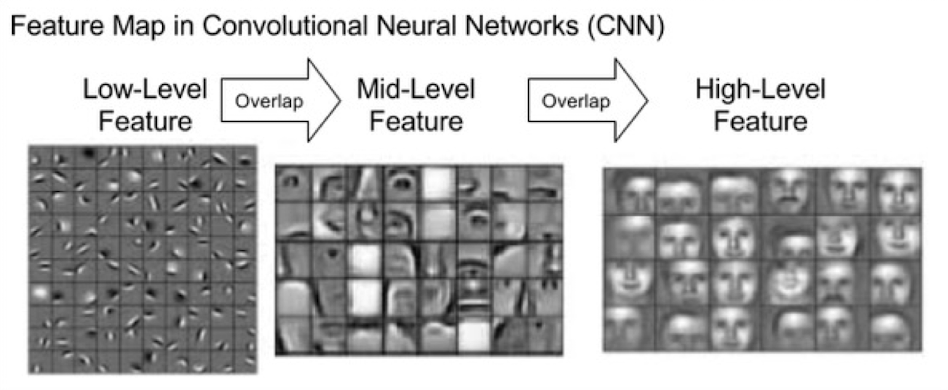
CNN의 구성요소
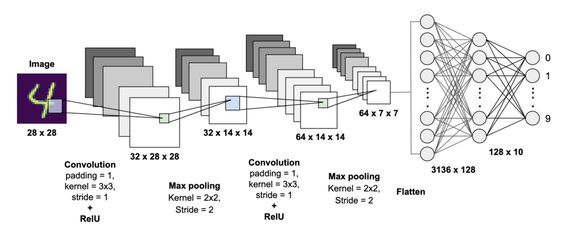
- Convolutional Layer (합성곱 층) - 학습 가능한 필터로 궁성
- Pooling Layer (통합 층) - Down Sampling
- Fully Connected Layer (MLP 층)
Convolutional Layer, 합성곱 층
MLP와 다르게 Conv Layer는 국소적으로 연결되어 있다. (Local connectivity)
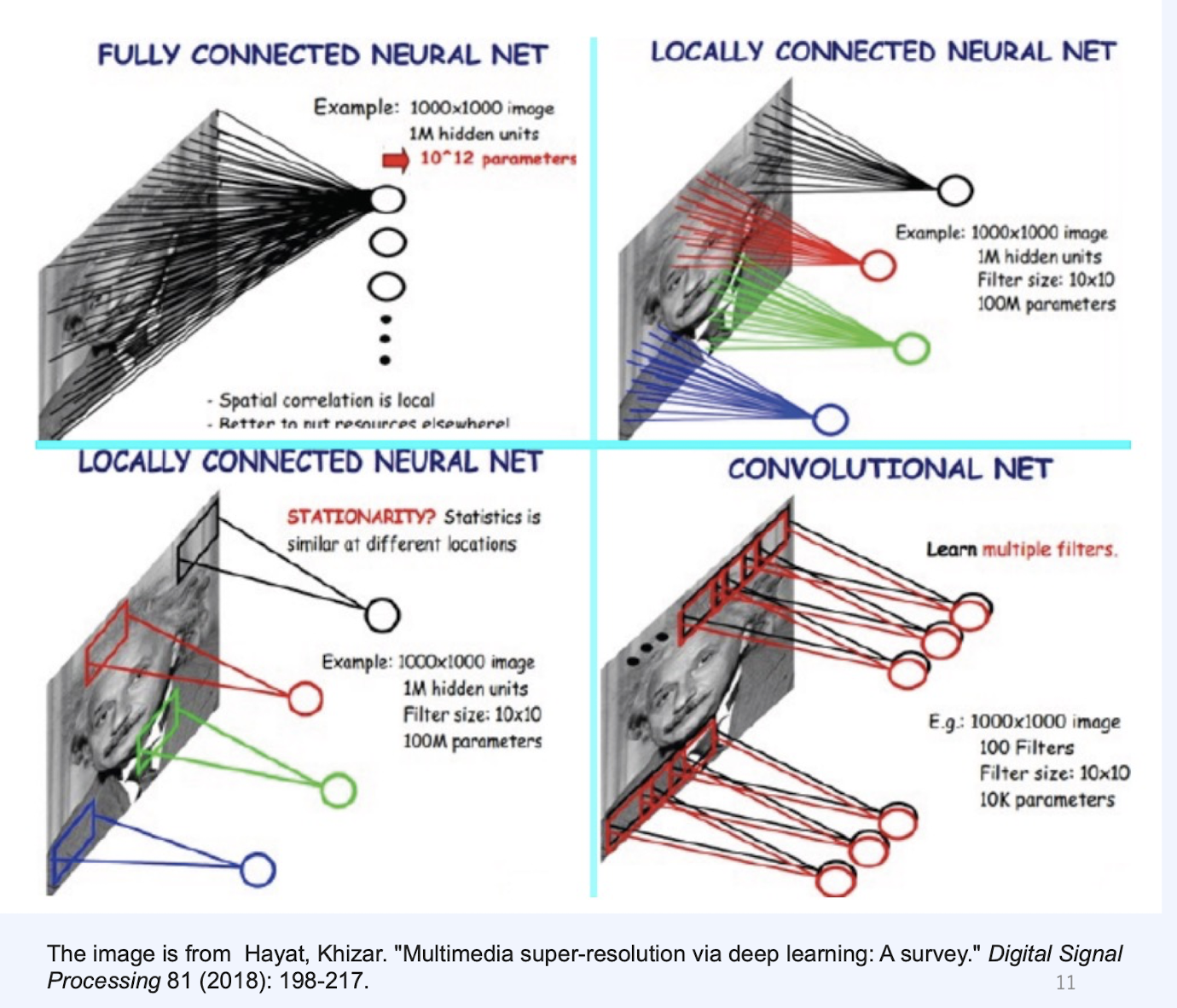
- 극접한 영역을 픽셀(Feature)에 집중하여, 특징을 더 관찰할 수 있다.
- 메모리 & 컴퓨팅 코스트를 줄이는 효과가 있다. (학습 파라미터를 공유)
- Translate invariant(병진 대칭) 하게 작동한다.
채널(Channel)
이미지 픽셀 하나하나는 실수로 표현되어질 수 있다. 컬러 사진은 천연색을 표현하기 위해, RGB 3개의 차원으로 표현한 데이터이다. 국소 weight에 집중하지 않기 위해 사용이 되고, Convolution Layerdp n개의 필터가 적용된다면 출력데이터는 n개의 필터를 가지게 된다.

합성곱(convolution)과 필터(Filter)
필터는 이미지의 특징을 찾아내기위한 공용 파라미터 이다. CNN에서는 같은 의미로 커널(kernel)이라 한다. 일반적으로 (3,3), (4,4) 사용하여 지정된 간격 (Stride)에 따라 이동하게 된고 채널별로 합성곱의 합을 Feature Map을 만든다.

- 특수하게 (1,1)필터 사이즈의 convolution을 사용하는 경우
인풋 값의 shape을 유지하면서 채널수를 조절할 수 있다.
비선형 변환 효과가 있다. (convolution뒤에 activatio을 바로 사용하기 때문)
계산하는 파라미터 수가 줄 수 있다.인풋이 128 채널이고, 3x3 필터를 가진 128채널의 convolution layer를 적용한다 했을 때, 파라미터 수는 3x3X128x128 = 147,456 개이다
만약, 이전에 먼저 3x3 필터를 가진 128 채널의 convolution layer 용 이전에 1x1 필터를 가진 32개 채널을 거친 뒤 간다면, 1x128x32 + 3x3x32x128 = 4,096 + 36,864 = 40,960 개로 줄어든다 !
Bottleneck 효과를 가질 수 있다!
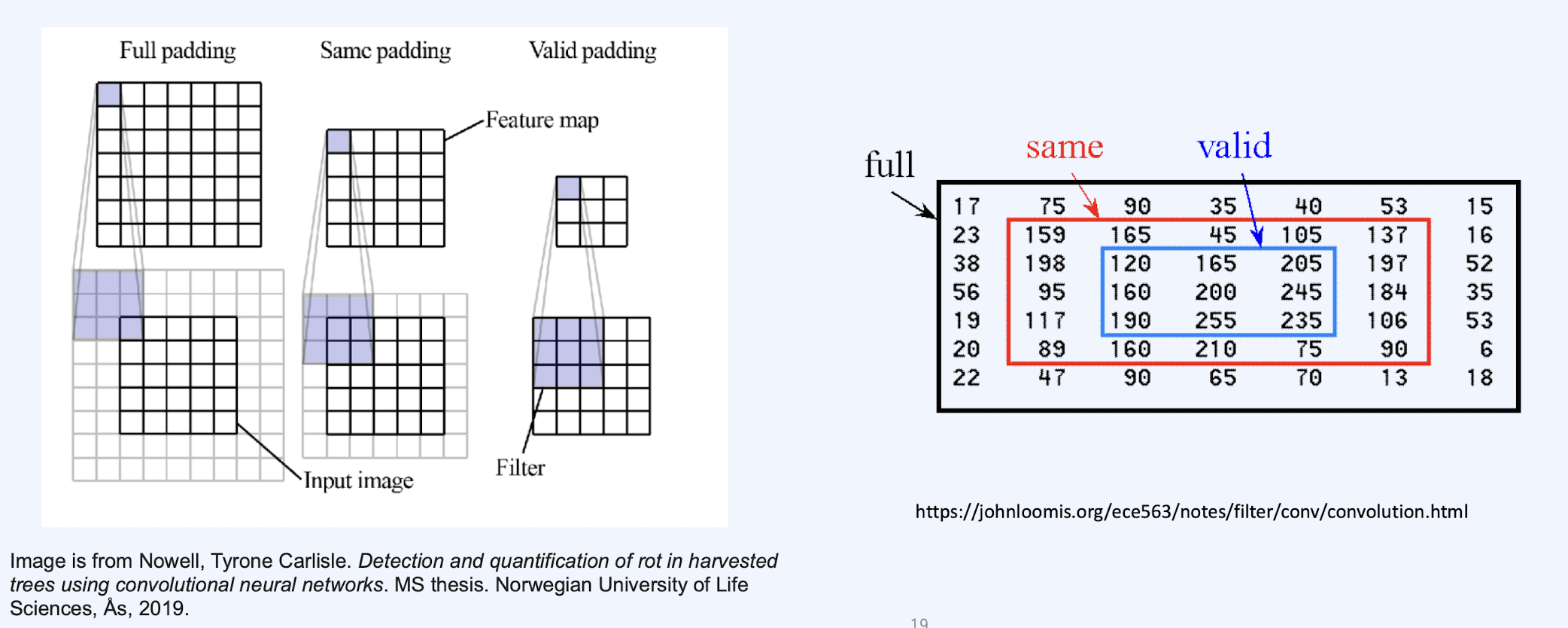
패딩(Padding)
Convolution 레이어의 Filter와 Stride에 따라 결과(Feature Map)의 shape이 바뀌게 된다. Convolution 레이어와 출력 데이터가 줄어드는 것을 방지하기 위해 패딩이 사용되게 된다. 보통의 패딩 값은 0으로 채워진다. 패딩을 통해서 Convolution 레이어의 출력 데이터 사이즈의 조절하는 기능외에도 인공신경망의 이미지 외각을 인식하는 학습 효과도 있다.
여담: Pooling의 대체 가능성
이런 이야기가 있는데 자세하게 찾아보지 못해서 chatgpt에게 물어 보았다.
정답이 아니므로 그냥 대충 훑고 가면 될거 같다.
Feature Map Shape

Pooling Layer, 통합 층
Convolution 레이어의 출력 데이터를 입력으로 받아서 출력 데이터(Activation Map)의 크기를 줄이거나 특정 데이터를 강조하는 용도로 사용된다. 또한 Shape을 줄여 학습할 파라미터의 수를 줄이는 목적으로도 사용되게 된다.
Pooling layer는 Convolutional layer와 함께 사용되어서 입력 이미지에서 특징을 추출하고, 이를 이용하여 더 높은 수준의 추상화된 특징을 학습하는 데에 사용된다. (low level -> high level Feature)
-
Max pooling: 입력 feature map에서 filter 크기 안에서 가장 큰 값을 선택하여 출력 feature map의 해당 위치의 값을 설정한다. 이렇게 함으로써 입력 feature map에서 가장 중요한 특징을 추출할 수 있다.
-
Average pooling: 입력 feature map에서 filter 크기 안에 있는 값들의 평균을 계산하여 출력 feature map의 해당 위치의 값을 설정하고 이렇게 함으로써 입력 feature map에서의 평균적인 특징을 추출한다.
Pooling Layer output shape

CNN과 다른 기법들 합치기
- CNN 저자에 따르면 activation function뒤에 dropout을 적용하면 좋다고 한다.
(추후 기회가 된다면 activation에 대해서 정리를 해봐야 겠다.)
- Batch normalization: 원 논문에 따르면 conv레이어와 fully-connected layer 뒤에 적용하는 것을 추천하고 있다.
배치 정규화의 목적이 네트워크 연산 결과과 원하는 방향의 분포대로 나오는 것이기 때문에, 핵십 연산인 conv layer뒤에 적용하여 정규화 하는것이 좋다. activation이 적용되어 분포가 달라지기 전에 적용하는 것이 효과적이다.
Conv Layer -> Batch Normalization -> Activation function -> Pooling Layer
