추상적 자료구조 (Abstract Data Structures)
* Data
- ex) 정수, 문자열, 레코드...
* A set of operations
- 삽입, 삭제, 순회....
- 정렬, 탐색...
연결 리스트
데이터 원소들을 순서를 지어 늘어놓는다는 점에서 연결 리스트 (linked list) 는 선형 배열 (linear array) 과 비슷한 면이 있지만, 데이터 원소들을 늘어놓는 방식에서 이 두 가지는 큰 차이가 있다. 구체적으로는, 선형 배열이 "번호가 붙여진 칸에 원소들을 채워넣는" 방식이라고 한다면, 연결 리스트는 "각 원소들을 줄줄이 엮어서" 관리하는 방식이다.
기본적 연결 리스트
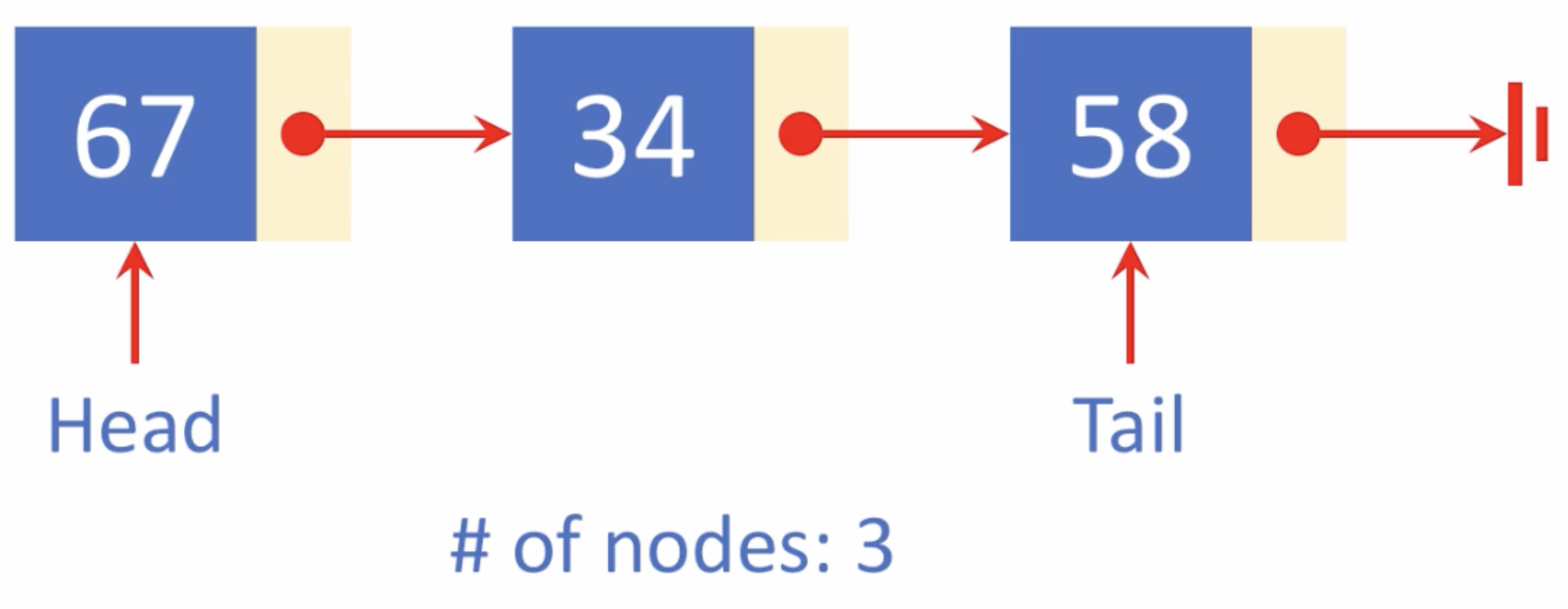
Node
- Data
- Link (next)
Node 내의 데이터는 다른 구조로 이루어질 수 있다.( ex> 문자열, 레코드, 또 다른 연결 리스트 등~)
class Node:
def __init__(self, item):
self.data = item
self.next = None
class LinkedList:
def __init__(self):
self.nodeCount = 0
self.head = None
self.tail = None
# print 같은 출력시 설정
def __repr__(self):
if self.nodeCount == 0:
return 'LinkedList: empty'
s = ''
curr = self.head
while curr.next:
curr = curr.next
s += repr(curr.data)
if curr.next is not None:
s += ' -> '
return s
# 특정 원소 참조, 노드 구하기
def getAt(self, pos):
if pos< 0 and pos > self.nodeCount :
return None
i = 1
curr = self.head # 처음 위치를 head로 지정
while pos < i: # 찾고자 하는 위치가 현재 위치보다 낮다면
curr = curr.next
i +=1
return curr
# 리스트 순회
def traverse(self):
if self.head == None: #비어있는 리스트 경우
return [] # 빈 리스트 출력
tr_list = [] # 순회를 위한 리스트 초기화
curr = self.head # 시작 노드 지정
while curr != None: # 다음 노드가 None이 아닐 때까지
tr.list.append(curr.data) # 현재 노드의 data 삽입
curr = curr.next # 다음 노드 지정
# 원소 삽입
'''
pos 가 가리키는 위치에 (1 <= pos <= nodeCount + 1)
newNode를 삽입하고
성공/실패에 따라 True/False 를 리턴
'''
def insertAt(self, pos, Newnode)
# 잘못된 pos경우
if pos < 1 or pos > self.nodeCount +1:
return False
# 리스트 맨 앞에 삽입하는 경우
if pos == 1:
newNode.next = self.head
self.head = newNode
else: # 일반적인 경우
if pos == self.nodeCount + 1:
prev = self.tail
else:
prev = sefl.getAt(pos - 1)
newNode.next = prev.next
prev.next = newNode
# 리스트 맨 마지막에 삽입하는 경우
if pos == self.nodeCount +1:
self.tail = newNode
retrun True
# 원소의 삭제
def popAt(self, pos):
if pos < 1 or pos > self.nodeCount + 1:
return IndexError # pos가 리스트 범위보다 클때
if pos == 1: # 리스트 데이터가 하나만 존재할 때
curr = self.head
self.head = curr.next
if self.nodeCount == :
self.tail = self.head
else:
prev = self.getAt(pos-1)
curr = prev.next
prev.next = curr.next
if pos == self.nodeCount:
self.tail = prev
self.nodeCount -= 1
return curr.data
# 두 리스트의 연결
def concat(self, L):
self.tail.next = L.head
if L.tail:
self.tail = L.tail
self.nodeCount += L.nodeCount
연결 리스트에서 원소의 삽입 및 삭제
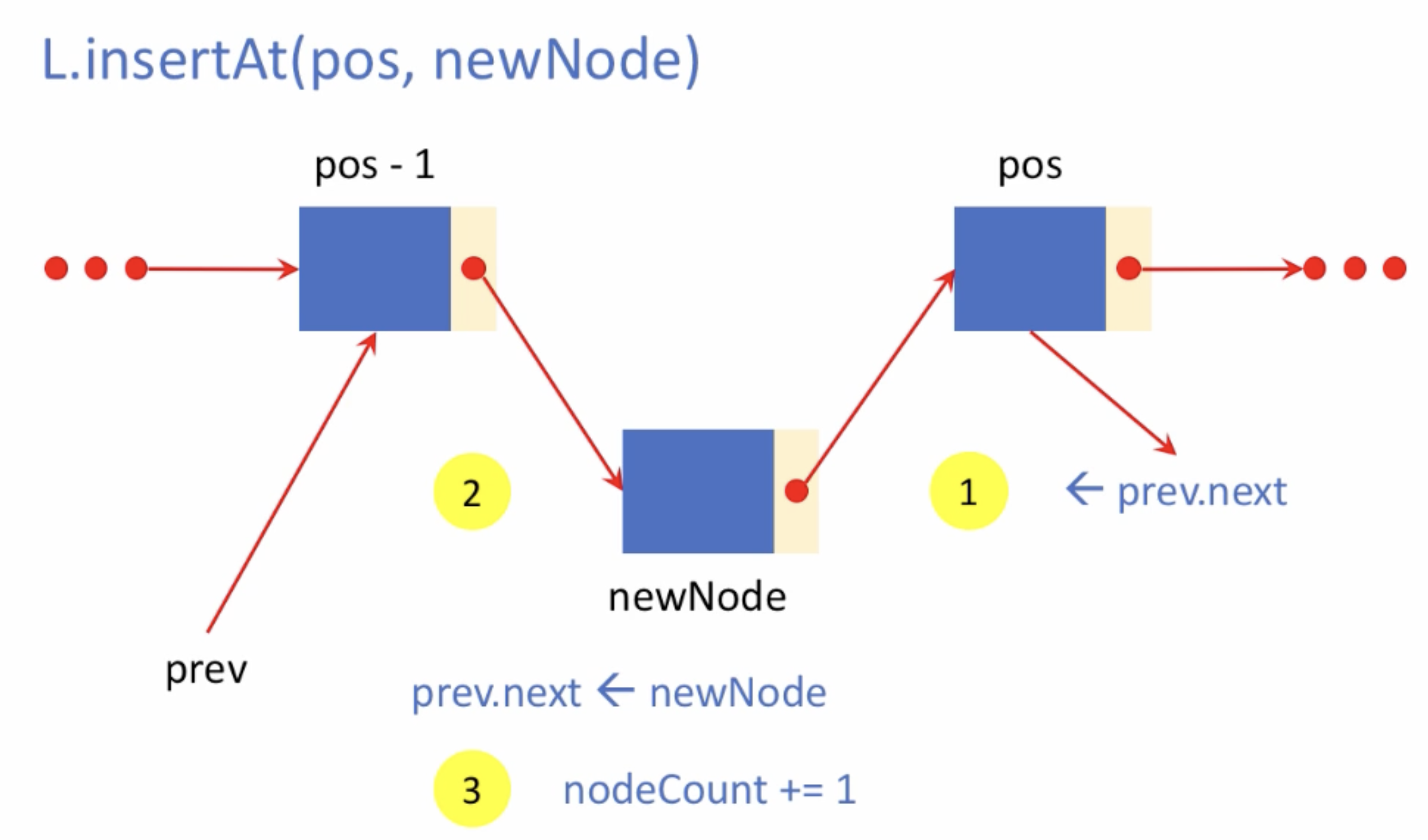
기존에 있던 노드들의 연결 결 관계를 새로 수정해주어야 한다.
- 원소 삽입 코드 구현시 주의사항
(1) 삽입하려는 위치가 리스트 맨 앞일 때
- prev 없음
- Head 조정 필요
(2) 삽입하려는 위치가 리스트 맨 끝일때
- tail 조정 필요
(3) 빈 리스에 삽입할때
- 위 두 조건에 의해 자동으로 처리됨
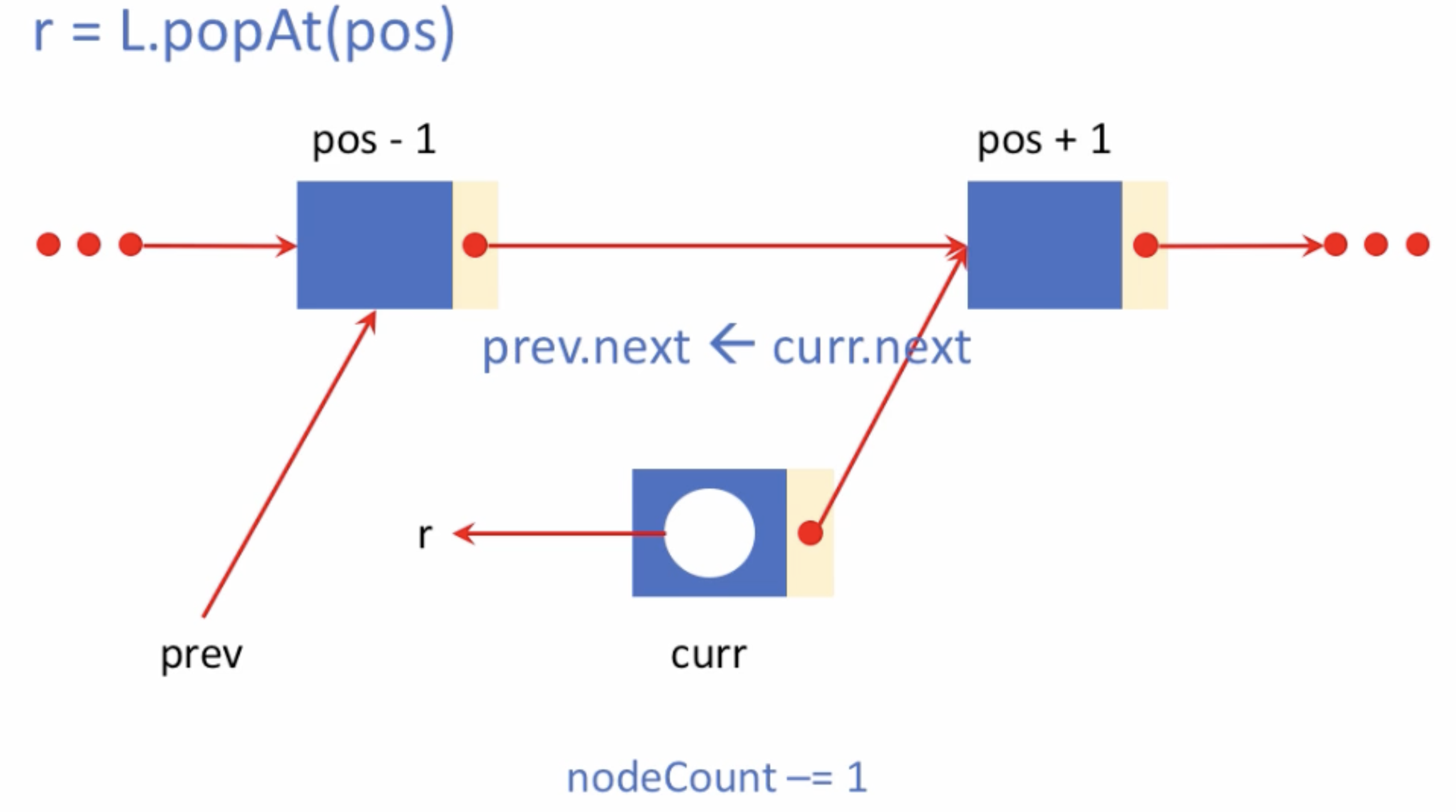
- 원소 삭제 코드 구현시 주의 사항
(1) 삭제하려는 node 가 맨 앞의 것일 때
- prev 없음
- Head 조정 필요
(2) 리스트 맨 끝의 node를 삭제할 때 - Tail 조정 필요
(3) 유일한 노드를 삭제할 때
조금 변형된 연결 리스트
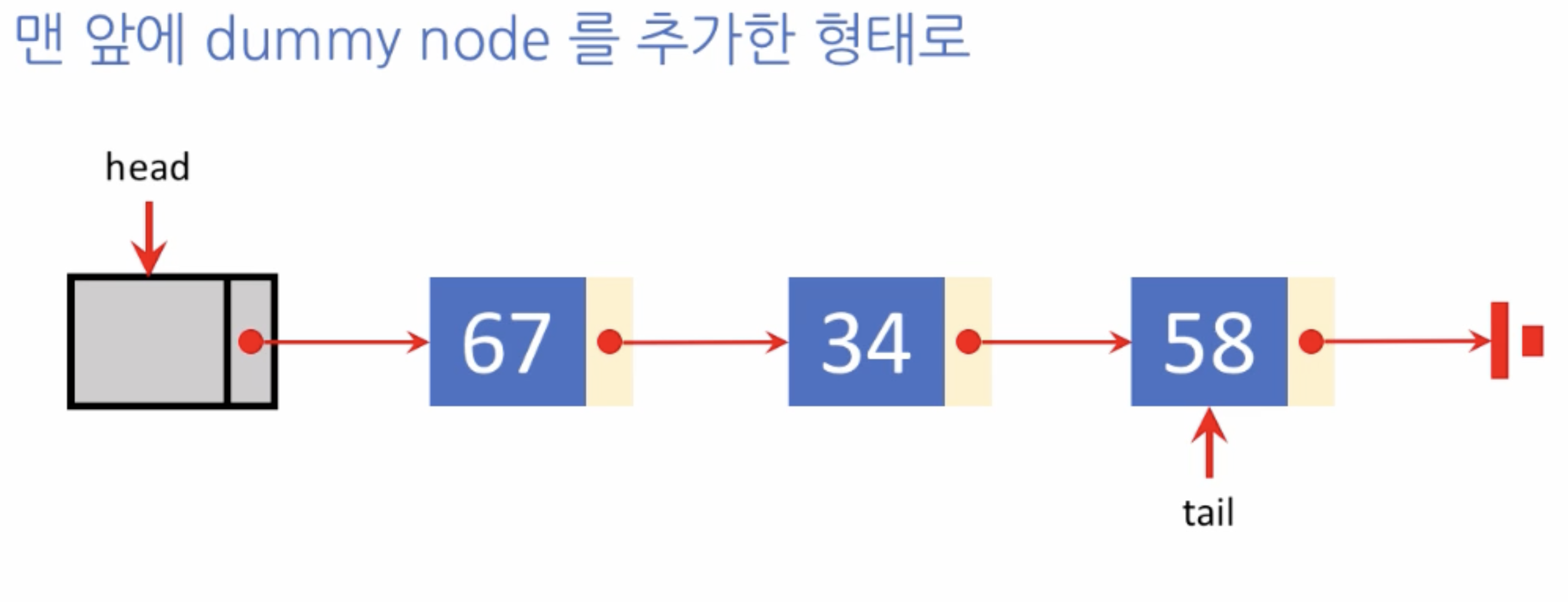
# 맨 앞에 dummy node를 추가한 linked list
class LinkedList:
def __init__(self):
self.nodeCount = 0
self.head = Node(None)
self.tail = None
self.head.next = self.tail
# 리스트 순회
def traverse(self):
result = []
curr = self.head
while curr.next:
curr = curr.next
result.append(curr.data)
retrun traverse
# k번째 원소 얻어내기
def getAt(self, pos):
if pos< 0 and pos > self.nodeCount :
return None
i = 0
curr = self.head # 처음 위치를 head로 지정
while pos < i: # 찾고자 하는 위치가 현재 위치보다 낮다면
curr = curr.next
i +=1
return curr
# 원소의 삽입
## prev가 가리키는 node의 다음에
## newNode를 삽입하고
## 성공/실패에 따라 True/False 리턴
def insert After(self, prev, newNode):
newNode.next = prev.next
if prev.next is None:
self.tail = newNode
prev.next = newNode
self.nodeCount += 1
return True
# insertAt
'''
(1) pos범위 조건 확인
(2) pos == 1인 경우에는 head뒤에 새 node 삽입
(3) pos == nodeCount + 1 인 경우에는 prev <- tail
(4) 그렇지 않은 경우에는 prev <- getAt(...)
'''
def insertAt(self, pos, newNode):
if pos < 1 or pos > self.nodeCojnt + 1:
return False
if pos != 1 and pos == self.nodeCount + 1:
prev = self.tail
else:
pev = self.getAt(pos - 1)
return self.insertAfter(prev, newNode)
# 원소의 삭제
## prev의 다음 node를 삭제하고 그 nodedml data를 리턴
'''
(1) prev가 마지막 node일 떄 (prev.next == None)
삭제할 노드 X
retrun None
(2) 리스트 맨 끝의 node를 살제할 때 (curr.next == None)
Tail 조정 필요
'''
def popAfter(self, prev):
curr = prev.next
pop_data = curr.data
if curr.next == None:
self.tail = prev
prev.next = None
else:
prev.next = curr.next
self.nodeCount -= 1
curr = None
return pop_data
def popAt(self, pos):
if pos < 1 or pos > self.nodeCount:
raise IndexError
else:
prev = self.getAt(pos-1)
return self.popAfter(prev)
# 두 리스트의 연결
def concat(self, L):
self.tail.next = L.head.next
if L.tail:
self.tail = L.tail
self.nodeCount += L.nodeCount
