MultipleBagFetchException은 언제 발생할까?
@OneToMany 관계를 가진 컬렉션을 2개 이상 fetch join을 사용하면 발생합니다.
public class Post {
@Id
@GeneratedValue
@Column(name = "post_id")
private Long id;
private String title;
private String content;
private String categoryName;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "users_id")
private UserEntity user;
@OneToMany(mappedBy = "post")
private List<Comment> comments = new ArrayList<>();
@OneToMany(mappedBy = "favoritePost")
private List<Favorite> favorites = new ArrayList<>();public class Comment {
@Id
@GeneratedValue
@Column(name = "comment_id")
private Long id;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "post_id")
private Post post;
}@Entity
@Getter
@NoArgsConstructor
public class Favorite {
@Id
@GeneratedValue
@Column(name = "favorite_id")
private Long id;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "post_id")
private Post favoritePost;
}return em.createQuery(
"select p from Post p" +
" join fetch p.comments c" +
" join fetch p.favorites f" ,Post.class)
.getResultList();Post가 일대다 관계를 가진 연관관계 객체들을 다음과 같이 한번에 끌어오는 쿼리를 작성했습니다.
문제점
- 일대다 관계는 fetch join을 하면 데이터 중복이 발생합니다.
- 중복이 발생한 데이터에 다시 fetch join을 하게되면 카티션 곱 문제가 발생합니다.
- MultipleBagFetch Exception이 발생합니다.
쿼리를 실행 시 다음과 같은 문구를 확인할 수 있습니다.

잘못된 해결방안1 : Set
여러개의 Collection을 Fetch하게 되면 데이터 정합성 문제가 발생한다고 생각해서, 중복을 제거하여 List를 Set으로
@OneToMany(mappedBy = "post")
private Set<Comment> comments = new ArrayList<>();
@OneToMany(mappedBy = "favoritePost")
private Set<Favorite> favorites = new ArrayList<>();다음과 같이 코드를 변경하여 문제를 해결하려고 합니다.
마치 이 코드를 사용하면 MultipleBagFetch Exception이 해결된 것처럼 보입니다. 그러나 과연 그럴까요?


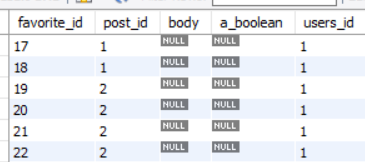
(favorite의 body, a_boolean_user_id의 null값은 신경안쓰셔도 됩니다.)
select
post0_.post_id as post_id1_2_0_,
userentity1_.users_id as users_id1_3_1_,
comments2_.comment_id as comment_1_0_2_,
favorites3_.favorite_id as favorite1_1_3_,
post0_.created_at as created_2_2_0_,
post0_.updated_at as updated_3_2_0_,
post0_.category_name as category4_2_0_,
post0_.content as content5_2_0_,
post0_.users_id as users_id7_2_0_,
post0_.title as title6_2_0_,
userentity1_.created_at as created_2_3_1_,
userentity1_.updated_at as updated_3_3_1_,
userentity1_.email as email4_3_1_,
userentity1_.encrypted_pwd as encrypte5_3_1_,
userentity1_.name as name6_3_1_,
userentity1_.user_id as user_id7_3_1_,
comments2_.body as body2_0_2_,
comments2_.post_id as post_id5_0_2_,
comments2_.users_id as users_id6_0_2_,
comments2_.status as status3_0_2_,
comments2_.username as username4_0_2_,
comments2_.post_id as post_id5_0_0__,
comments2_.comment_id as comment_1_0_0__,
favorites3_.a_boolean as a_boolea2_1_3_,
favorites3_.post_id as post_id3_1_3_,
favorites3_.users_id as users_id4_1_3_,
favorites3_.post_id as post_id3_1_1__,
favorites3_.favorite_id as favorite1_1_1__
from
post post0_
inner join
users userentity1_
on post0_.users_id=userentity1_.users_id
inner join
comment comments2_
on post0_.post_id=comments2_.post_id
inner join
favorite favorites3_
on post0_.post_id=favorites3_.post_id짠!! 쿼리는 우리가 원하던 것처럼 N+1문제가 발생하지 않네요....!! 그런데 정말 괜찮을까요?
다음과 같이 세 테이블을 fetch join으로 만날때, 커티션 곱이 발생하는지 결과를 확인해보면
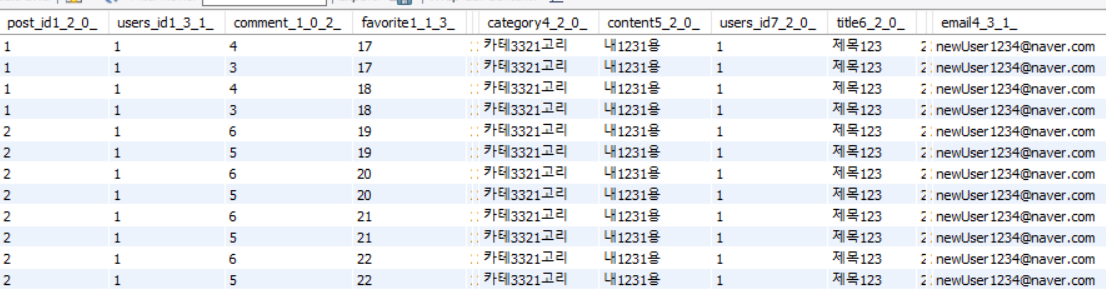
Post 1번 1개 Comment 2개 favorite 2개 = 4
Post 2번 1개 Comment 2개 favorite 4개 = 8
결론은 12개의 결과가 나오게 되었고, 커티션 곱은 Set으로는 db에서 해결되지 않습니다.
MultipleBagFetch Exception 해결된 것처럼 보이지만 db연산에서 굉장히 큰 문제가 발생할 수 있습니다.
우리는 왜 join fetch 연산을 사용할까?
fetch join으로 일대다 컬렉션을 한번에 갖고 싶어하는 경우, 왜 fetch join을 중복으로 사용해서 코드를 짜는 걸까요?
jpa는 객체지향적인 코드를 작성하기 위해서 db의존적이지 않기위해 사용합니다. 그렇다보니 db를 의식하지 않게 되면서 컬렉션 fetch join을 중복으로 사용하게 되는 것이죠.
무슨 말일까?
혹시 fetch join을 그냥 단순히 연관관계 지연로딩을 해결하기 위해서 사용하 신 거 아닌가요?
위의 fetch join의 경우 *ToOne에는 문제가 발생하지 않습니다. 오히려 필요한 데이터를 한번에 끌어 올 때 N+1문제를 해결할 수 있는 장점이 있습니다.
그러나 N+1의 문제를 해결해도 db의 join으로 곱셈연산을 계속 진행하는 것은 N+1보다 더욱 크리티컬한 문제로 이어집니다. (컬렉션 fetch join은 데이터 중복이 발생하므로 심지어 페이징도 할 수 없습니다.)
그렇다면 우리는 set을 사용하지 않고 MultipleBagFetch Exception을 어떻게 해결할 수 있을 까요?
컬렉션 fetch join은 2개 이상 사용하면 안됩니다.
2개 이상 사용하는 순간 부터 테이블간 곱셈연산이 N*M처럼 매우 비효율적으로 작동하는 것을 위에서 확인할 수 있습니다. 그렇다면 Post객체가 Comment List도 필요하고
Favorite List도 필요하면 어떻게 해야할까요?
정답은 default_batch_fetch_size: 100 를 사용하는 것입니다.
default_batch_fetch_size에 대해서 확실히 이해를 하기 위해서는 N+1문제에 대한 명확한 이해가 필요합니다.
Post 객체의 List를 지연로딩 조회시 쿼리는 몇번 발생할까요?
정답은 1번입니다.
List의 갯수만큼 발생하는 것이 아닌가요? 그렇지 않습니다.
Post 객체를 1개 조회시 Post.getComments()를 한다면 쿼리가 1개 추가로 발생합니다.
Post 객체를 1개 조회시 Post.getFavorites()를 한다면 쿼리가 1개 추가로 발생합니다.
즉 fetch join을 하지 않고 1번 Post 객체의 comments와 favorites를 가지고 온다면 Post 객체 select 1번 comments 1번 favorites 1번으로 총 3번 발생합니다.
만약 default_batch_fetch_size: 100 라고 yml 파일에 설정하면 쿼리가 몇번 발생할까요?
마찬가지로 Post객체 1번, comments 1번 favorites 1번 발생합니다.
default_batch_fetch_size는 N+1문제를 해결해 준다면서 왜 아직도 쿼리가 안줄고 3개가 나가요?
라고 생각하실 수 있습니다.
단건 조회의 경우, N+1문제는 발생하지 않습니다.
단건 조회의 객체가 일대다 컬렉션을 여러개 가지고 있는 것과 N+1문제는 다른 문제라는 것을 이해하셔야 됩니다.
Post객체들의 List 지연 로딩 조회시 쿼리는 몇번 발생할까요?
@GetMapping("/api/postAll")
public List<PostAllDto> getPostLazyAll(){
List<Post> posts = postRepository.findAll();
List<PostAllDto> result= posts.stream()
.map(p->new PostAllDto(p))
.collect(Collectors.toList());
return result;
}
public PostAllDto(Post p) {
postId=p.getId();
title=p.getTitle();
content=p.getContent();
comments=p.getComments().stream()
.map(comment -> CommentDto.builder()
.postId(comment.getId())
.body(comment.getBody())
.build()).collect(toList());
favorites=p.getFavorites().stream()
.map(favorite -> FavoriteDto.builder()
.aBoolean(favorite.getABoolean())
.build()).collect(toList());
} 다음과 같은 List < Post> 를 조회하면서 Post의 Comments와 Favorites를 가져오는 api를 날려보겠습니다.
쿼리는 몇번 발생할까요?
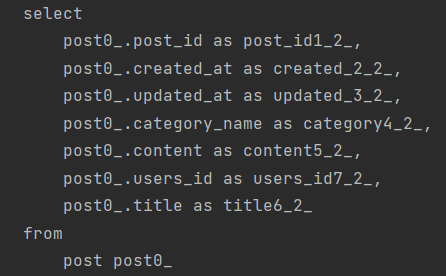
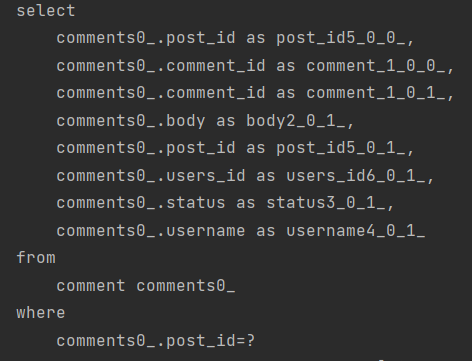
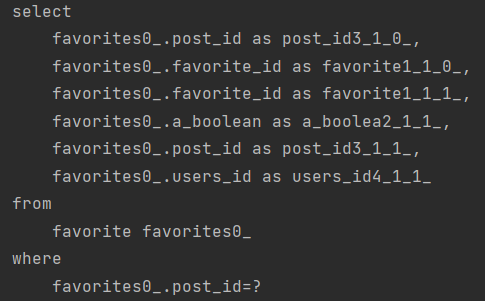
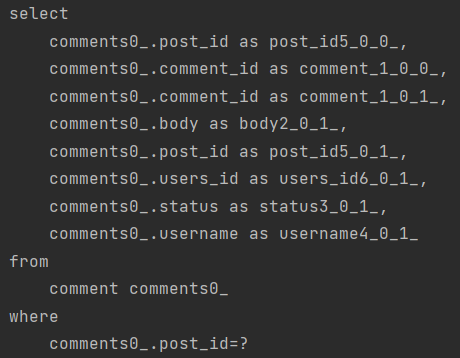
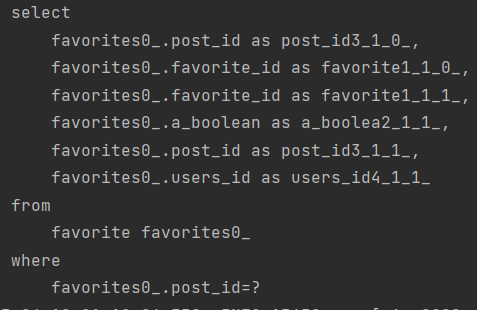
이렇게 총 5번 쿼리가 날라가는 것을 볼 수 있습니다.
Post는 db에 2개가 있었습니다. 그럼 N 은 2
Post 1번 + Post.Comments 1개 N + Post.Favorites N 으로 5개가 날라갑니다.
즉 N+1 문제가 발생하는 것을 볼 수 있습니다.
만약 default_batch_fetch_size: 100 라고 yml 파일에 설정하면 쿼리가 몇번 발생할까요?
default_batch_fetch_size: 100 을 설정하고 똑같이 api를 던져보자.
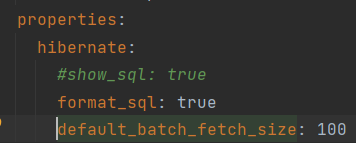
다음과 같이 default_batch_fetch_size: 100 을 설정을 추가 한 뒤 똑같이 api를 날렸을때 쿼리의 결과입니다.
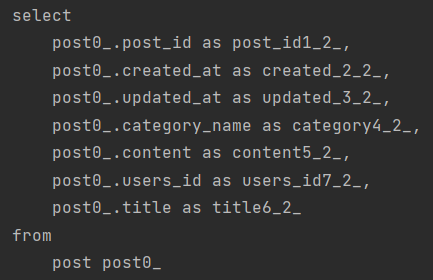
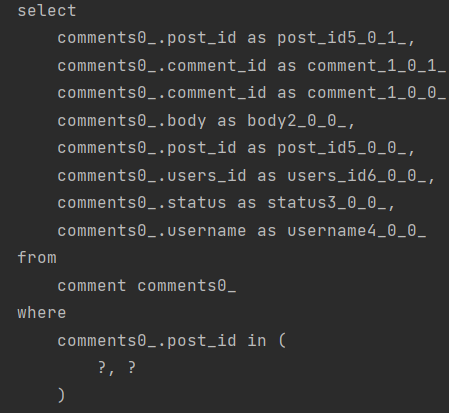
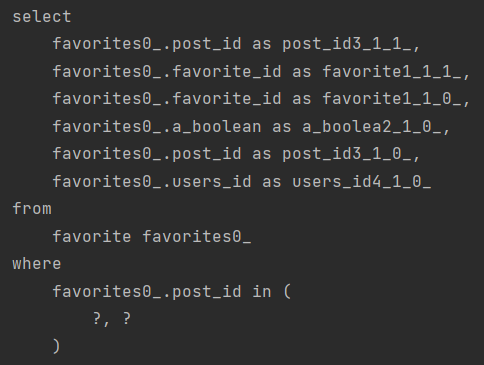
다음과 같이 N+1 문제가 해결된 것을 확인할 수 있습니다.
in 절이 SQL문에 추가가 되어 연관관계의 List들을 한번에! 가져오면서 문제를 해결하는 것이죠.
결론
우리는 fetch join을 왜 여러번 사용했을까요?
그것은 fetch join이 단순히 지연 로딩에서 프록시 객체를 초기화 시켜서 갖고 오는 것으로만 착각했기 때문입니다.
결국 fetch join도 db의 연산입니다.
일대다 관계의 컬렉션들을 fetch join으로 겹쳐서 사용하는 것은 db에 매우 위험한 것이라는 걸 간과한 것 입니다.
또한 Post의 단건 조회와 Post를 모두 조회하는 List 조회의 Case를 명확히 구분하셔야 합니다.
Post가 일대다 연관관계의 List들을 여러 개 가지고 있다고 해서, 단견 조회에서도 N+1이 발생할 것이라는 건 굉장히 큰 착각입니다.
Post를 모두 조회하는 List 조회일 경우 에만 N+1 문제가 발생하는 것이 핵심이죠
그리고 이 N+1 문제를 해결할 수 있는 방법은 default_batch_fetch_size를 설정하여, 쿼리문에 in절을 이용하는 것입니다.
