Intro
서비스 계층에서 @Transactional을 사용하는 위치(클래스 혹은 메서드)에 대해서 좀 더 알아보기 위해 서칭하던 중, 좋은 글을 있어서 번역한다. 원문은 해당 글을 참조~
@Transactional 은 어떤 계층에 속할까?
@Transactional은 Service 계층의 경계를 정의해야할 책임을 가지고 있기 때문에, 서비스 계층에 속한다.
웹 계층(Presentation layer)에서는 사용하지 말아야 한다. 데이터베이스 트랜잭션 응답 시간이 증가하고 주어진 데이터베이스 트랜잭션 오류(예: 일관성, 교착 상태, 잠금 획득, 낙관적 잠금)에 대해 올바른 오류 메시지를 제공하기가 더 어려워질 수 있기 때문이다.
DAO(Data Access Object) 또는 Repository 계층은 응용 프로그램 수준의 트랜잭션이 필요하지만 이 트랜잭션은 서비스 계층에서 전파되어야 한다.
@Transactional을 가장 효율적으로 사용하는 방법
서비스 계층에는 데이터베이스 관련(database-related) 서비스와 데이터베이스 관련 서비스가 아닌(non-database-related) 서비스가 모두 있을 수 있다.
주어진 비즈니스 서비스가 이들을 혼합해야 하는 경우, 데이터베이스 트랜잭션이 가능한 한 늦게 시작되는 것이 가장 좋다.
다음과 같이 넌-트랜잭션(non-transactional)인 게이드웨이 서비스가 있다고 가정하자.
@Service
public class RevolutStatementService {
@Transactional(propagation = Propagation.NEVER) (1)
public TradeGainReport processRevolutStocksStatement(
MultipartFile inputFile,
ReportGenerationSettings reportGenerationSettings) {
return processRevolutStatement(
inputFile,
reportGenerationSettings,
stocksStatementParser
);
}
private TradeGainReport processRevolutStatement(
MultipartFile inputFile,
ReportGenerationSettings reportGenerationSettings,
StatementParser statementParser
) {
ReportType reportType = reportGenerationSettings.getReportType();
String statementFileName = inputFile.getOriginalFilename();
long statementFileSize = inputFile.getSize();
StatementOperationModel statementModel = statementParser.parse( (1-1)
inputFile,
reportGenerationSettings.getFxCurrency()
);
int statementChecksum = statementModel.getStatementChecksum();
TradeGainReport report = generateReport(statementModel); (1-2)
if(!operationService.addStatementReportOperation( (2)
statementFileName,
statementFileSize,
statementChecksum,
reportType.toOperationType()
)) {
triggerInsufficientCreditsFailure(report);
}
return report;
}
}
- processRevolutStocksStatement() 는 넌-트랜잭션이다. 따라서
Propagation.NEVER전략을 사용하여, 활성화된 트랜잭션에 합류되지 않도록 명시해준다.따라서, statementParser.parse () 와 generateReport() 는 데이터베이스 연결이 필요 없고, 단순히 application-level의 처리만을 원하기 때문에, 넌-트랜잭션 컨텍스트에서 실행된다.
- 트랜잭션 컨텍스트에서 실행이 필요한 작업으로, 아래와 같이 @Transactional annotation의 사용이 필요
@Service
@Transactional(readOnly = true) (1)
public class OperationService {
@Transactional(isolation = Isolation.SERIALIZABLE) (2)
public boolean addStatementReportOperation(
String statementFileName,
long statementFileSize,
int statementChecksum,
OperationType reportType) {
...
}
}
- 메서드에서 자체 @Transactional을 정의하지 않는 한, 기본적으로 모든 서비스 메서드는 읽기 전용 트랜잭션을 사용
트랜잭션 서비스의 경우, 클래스에서
readOnly 속성을 true설정하고,데이터베이스의 쓰기의 사용이 필요한 서비스 메서드에서 트랜잭션을 오버라이딩해서 사용하는 것이 좋음, 예를 들면 다음과 같은 패턴을 사용하자- 기본 격리(isolation) 설정을 오버라이딩
@Service
@Transactional(readOnly = true)
public class UserService implements UserDetailsService {
@Override
public UserDetails loadUserByUsername(String username) (1)
throws UsernameNotFoundException {
...
}
@Transactional
public void createUser(User user) { (2)
...
}
}
- 읽기 전용 트랜잭션만 사용하고, Hibernate를 사용할 경우, 스프링은
읽기 전용 최적화도 수행한다.- 반면, 데이터베이스의 쓰기를 사용한다. 그러므로 readOnly 속성을 default(false)로 오버라이딩하여 읽기-쓰기 트랜잭션으로 사용한다.
읽기-쓰기 및 읽기 전용 메서드를 분할할 때의 또 다른 큰 이점은 이 기사 에서 설명하는 것처럼 서로 다른 데이터베이스 노드로 라우팅할 수 있다.
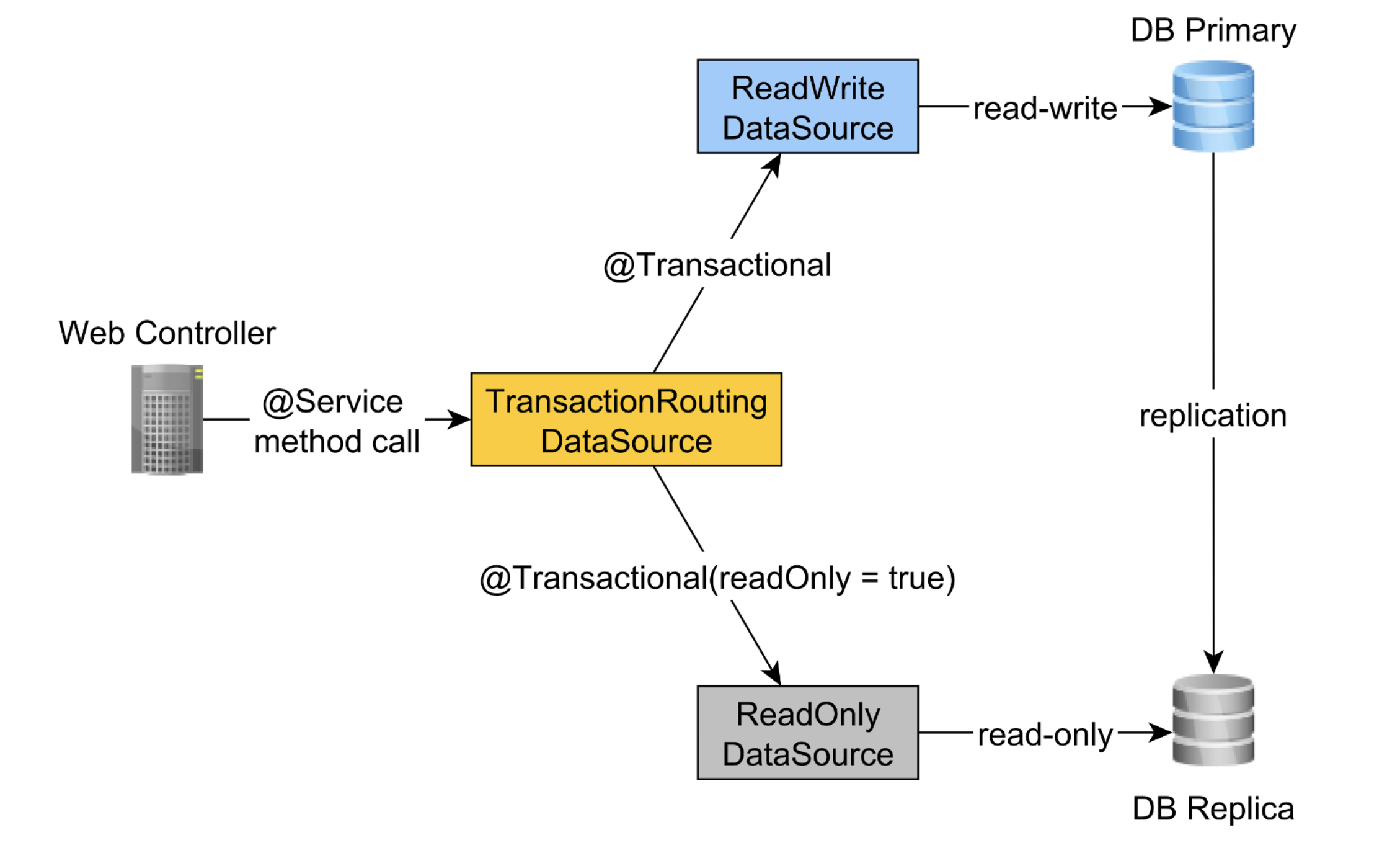
이러한 방식은 replica node 수를 늘려, 읽기 전용 트래픽을 확장할 수 있다
