if(kakao)dev2022 - Batch Performance 극한으로 끌어올리기: 1억 건 데이터 처리를 위한 노력 요약

Batch Performance 극한으로 끌어올리기: 1억 건 데이터 처리를 위한 노력 / if(kakao)2022 영상을 보고 정리한 내용입니다.
Batch로 개발하는 경우
흠...오후 4시에 상품 주문 배송 정보를 고객들에게 문자로 일괄 전송해야 하는구나.
간단하네! Batch로 개발해서 16시에 스케줄을 걸어놔야지!
- 특정 시간에 많은 데이터를 일괄 처리에 대해 서버 개발자들이 자주 애용하는 방식
- 배치 방식이 실시간 방식보다 개발 부담이 낮다고 생각함
Batch로 개발하는 상황
일괄 생성
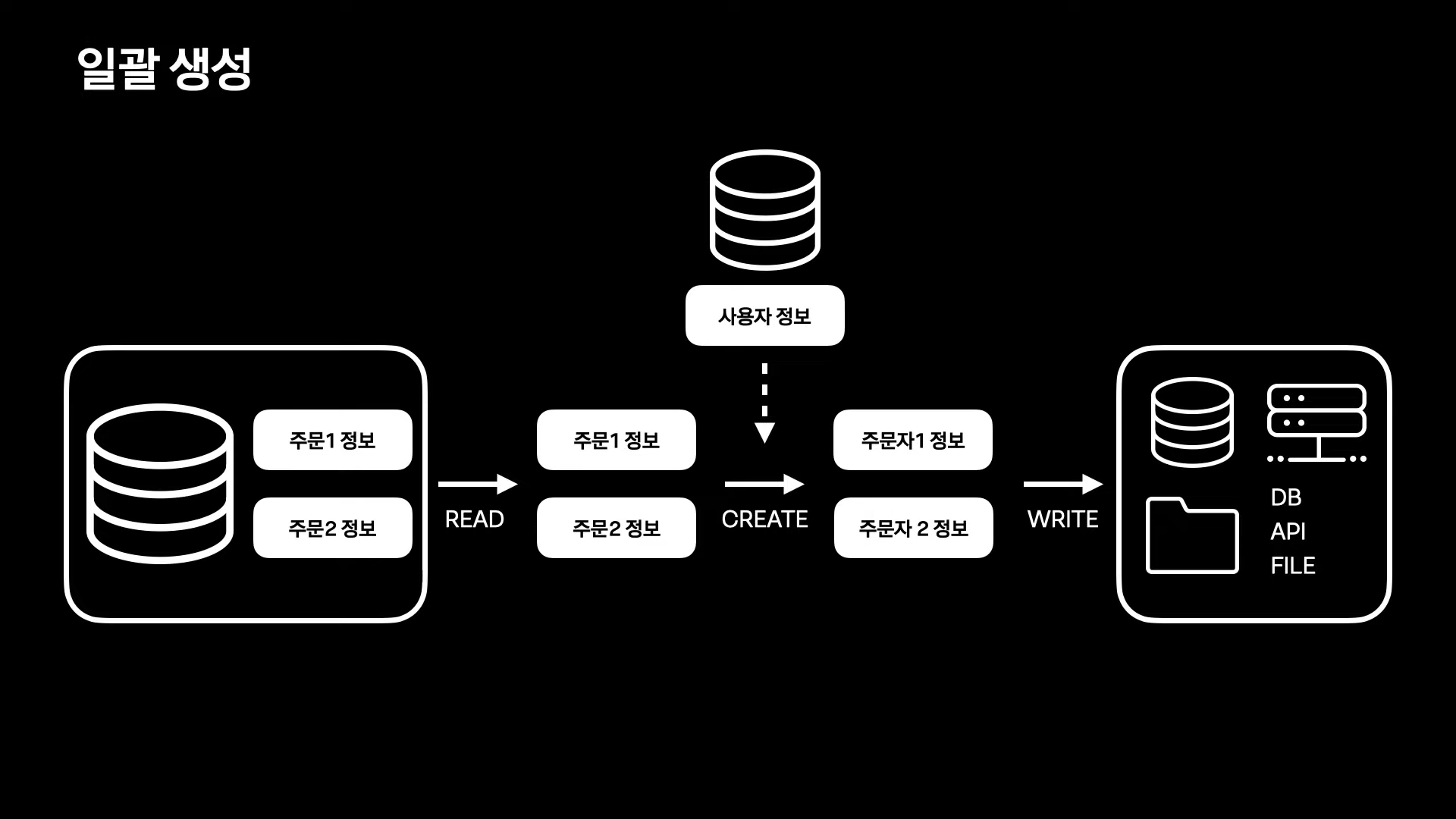
기존에 저장된 정보를 조합해서 새로운 정보를 만들 때
일괄 수정
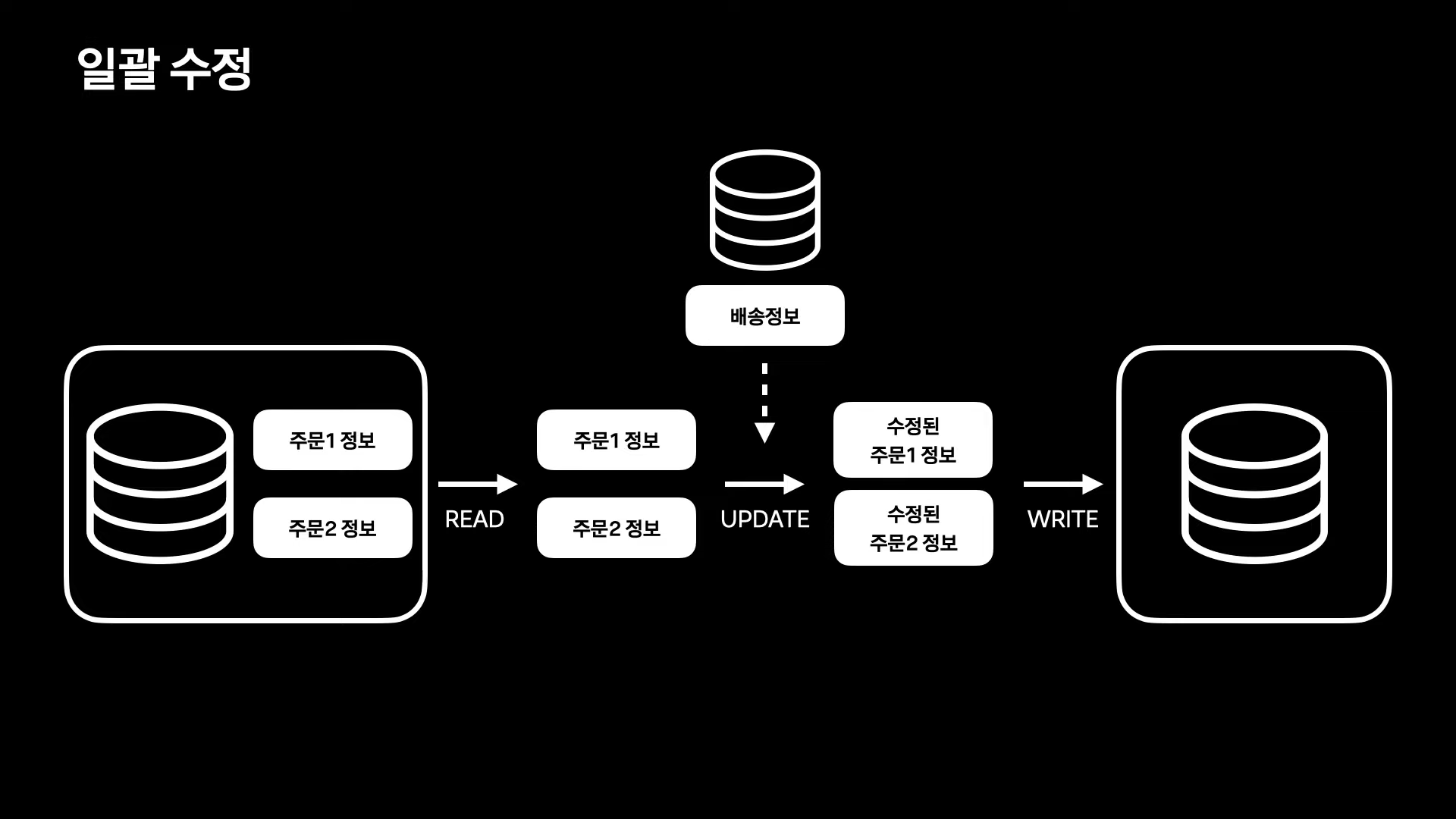
이미 저장된 데이터를 일괄로 수정할 때
통계
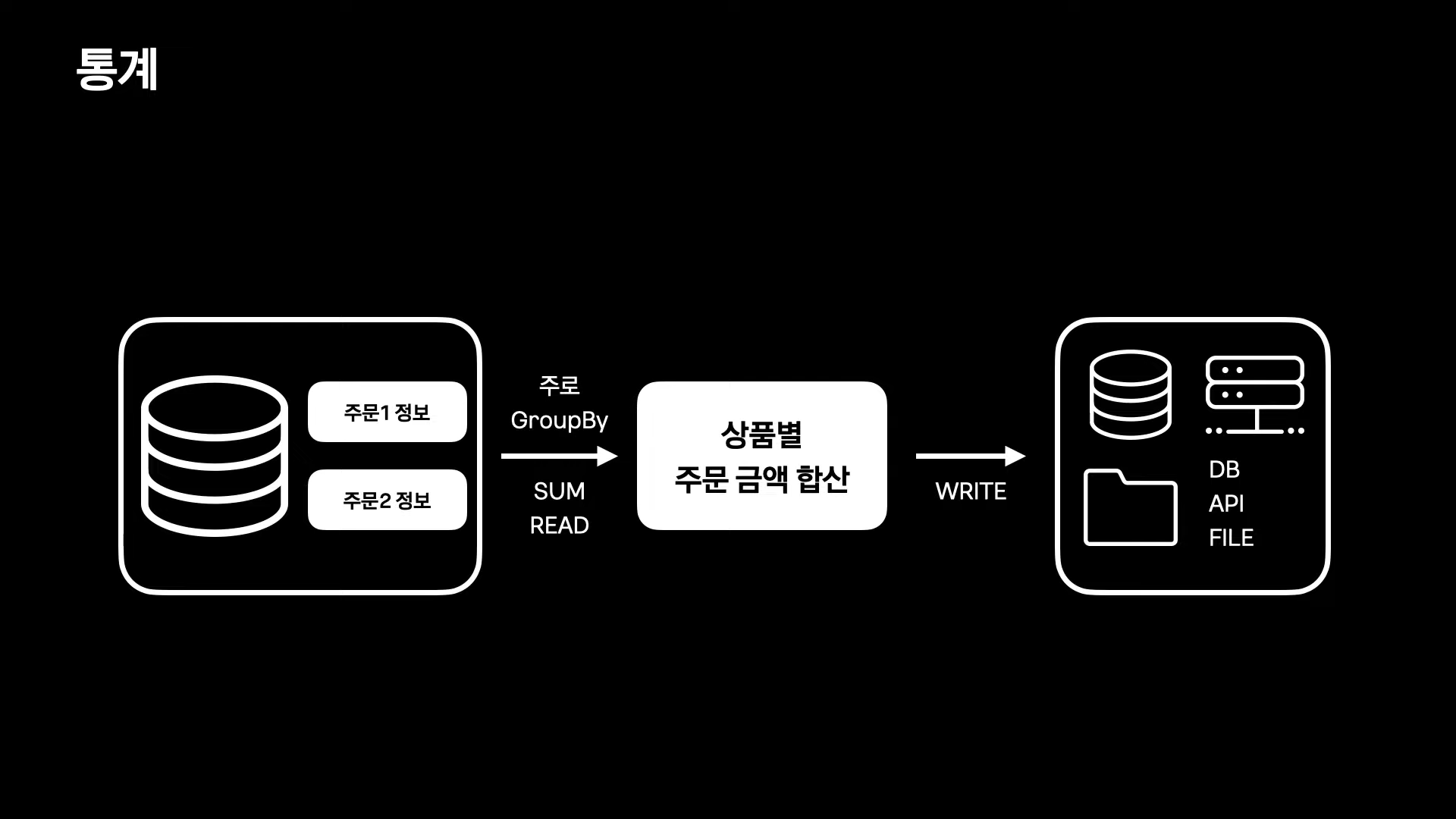
통계 형식의 데이터를 만들 때
카카오페이의 Batch Performance
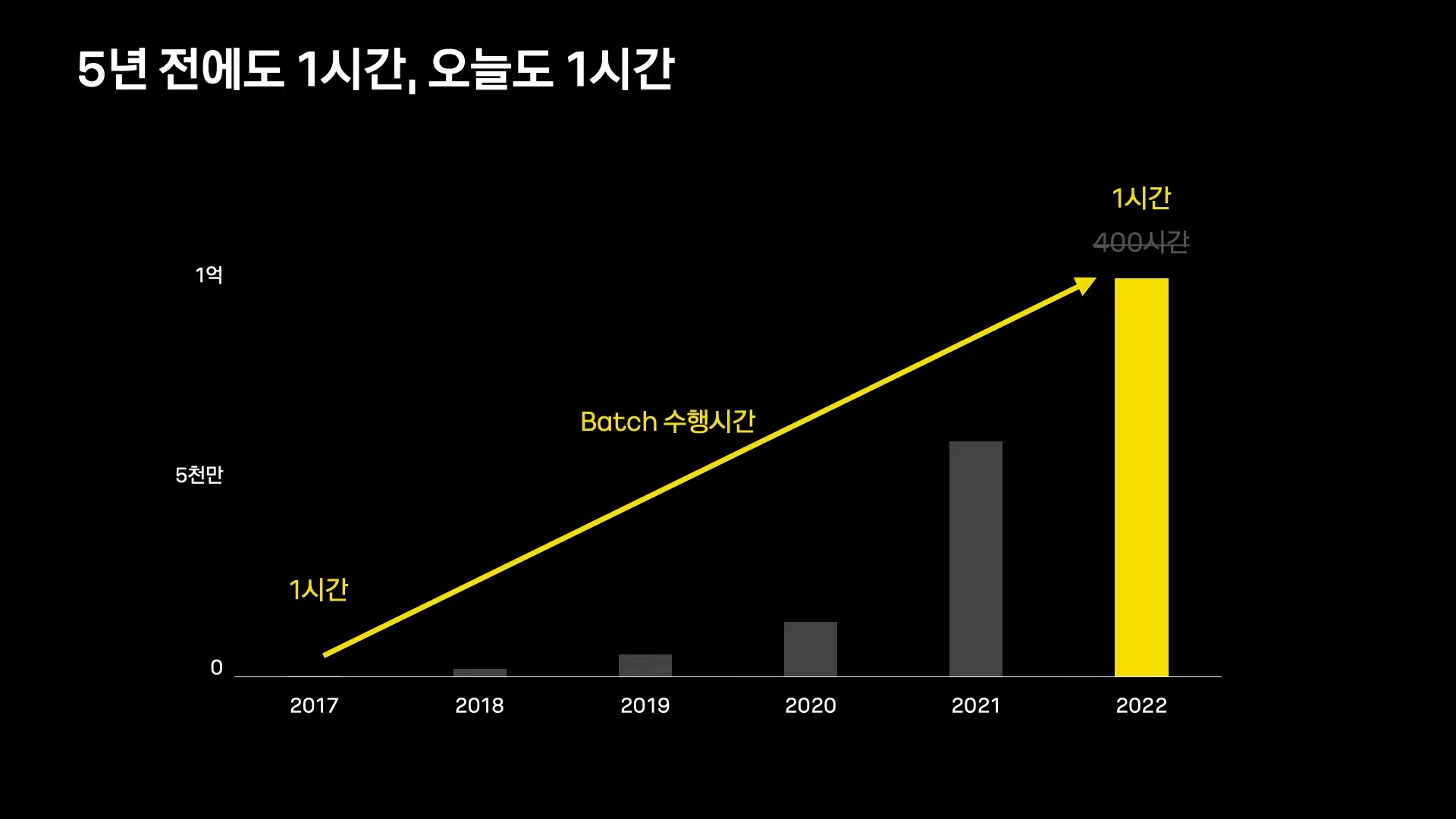
카카오페이는 늘어나는 데이터량에도 불구하고 Batch 수행시간을 5년전과 비슷한 수준으로 유지하고 있음
Batch 처리의 성능 개선 방법
대량 데이터 READ
Batch 성능 개선의 첫 걸음 = Reader 개선
(Batch 성능에서 차지하는 비중이 Reader가 가장 높기 때문)
Reader의 복잡한 조회 조건이 배치 전체의 성능을 크게 좌우
따라서 SELECT 쿼리를 튜닝하는 것만으로도 극적으로 성능이 개선됨
ZeroOffsetItemReader (with QueryDSL)
Chunk Processing을 위한 Pagination Reader를 사용할 수 있음
(Limit, Offset 사용)

하지만 Offset이 커질수록 성능이 크게 저하
(MySQL은 N번째 아이템을 찾는 작업에 큰 부담을 느낌)
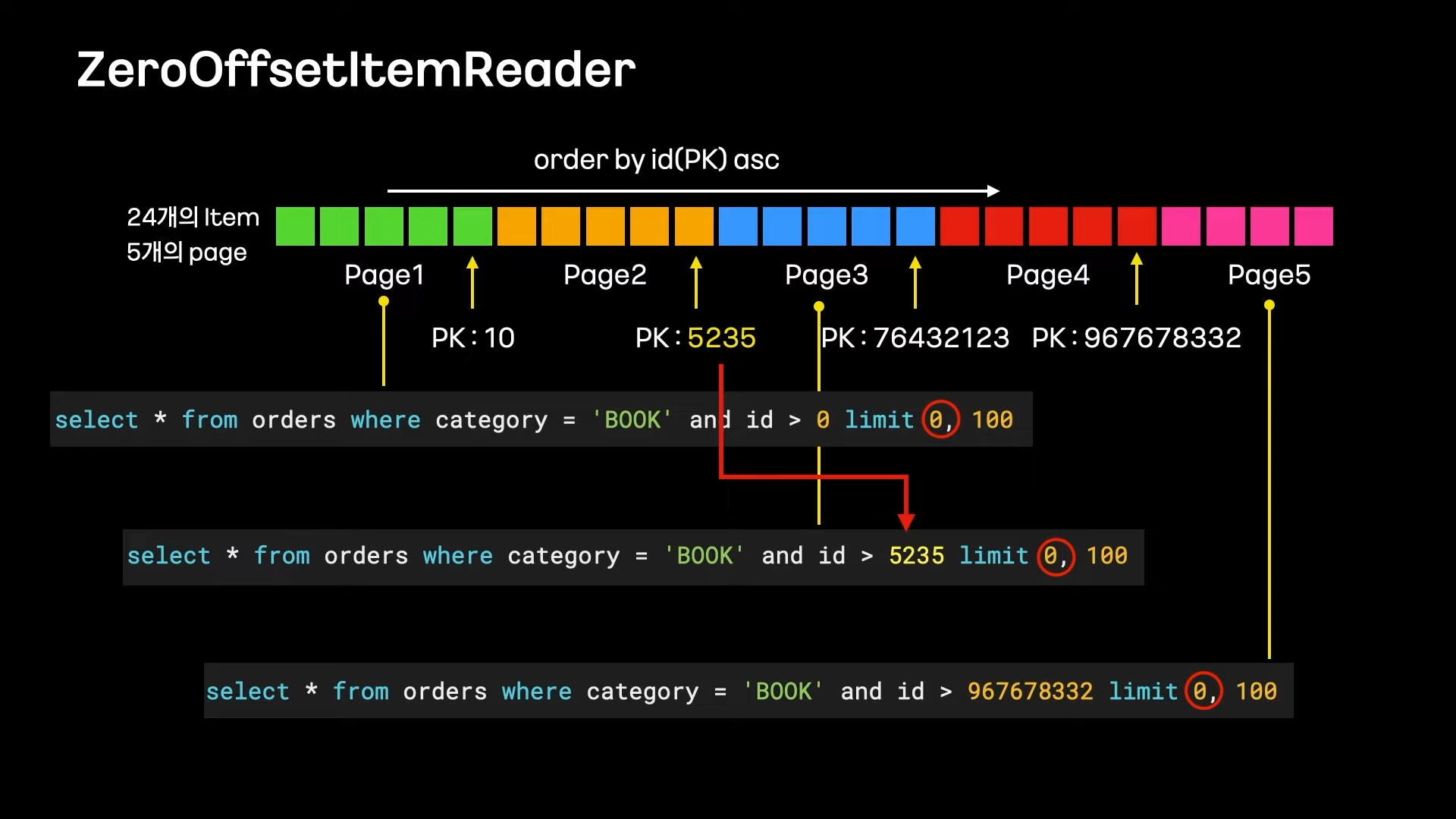
그래서 Offset을 항상 0으로 유지하고 직전 페이지의 마지막 id보다 큰 조건을 넣는 방식 사용
Offset이 0이기 때문에 조회 속도 저하가 없음
이때, 편하고 안전하게 쿼리를 작성하기 위해 QueryDSL을 사용
CursorItemReader (with Exposed)
MySQL Cursor는 데이터가 없을 때까지 일정 개수릐 데이터를 반복해서 가져오는 방식
(Chunk Processing에 잘 어울리는 방식)

JpaCursorItemReader는 아예 사용을 안하는 것을 추천
JdbcCursorItemReader는 Native Query를 사용해야 함
그래서 안전하고 세련된 쿼리 구현 방식으로 Exposed 사용


정리


데이터 Aggregation 처리
통계 -> Batch -> GroupBy & Sum
데이터가 적을 때는 합리적이고 개발도 간단한 흐름
하지만, 데이터가 많아지고 쿼리가 복잡해지면 문제 발생
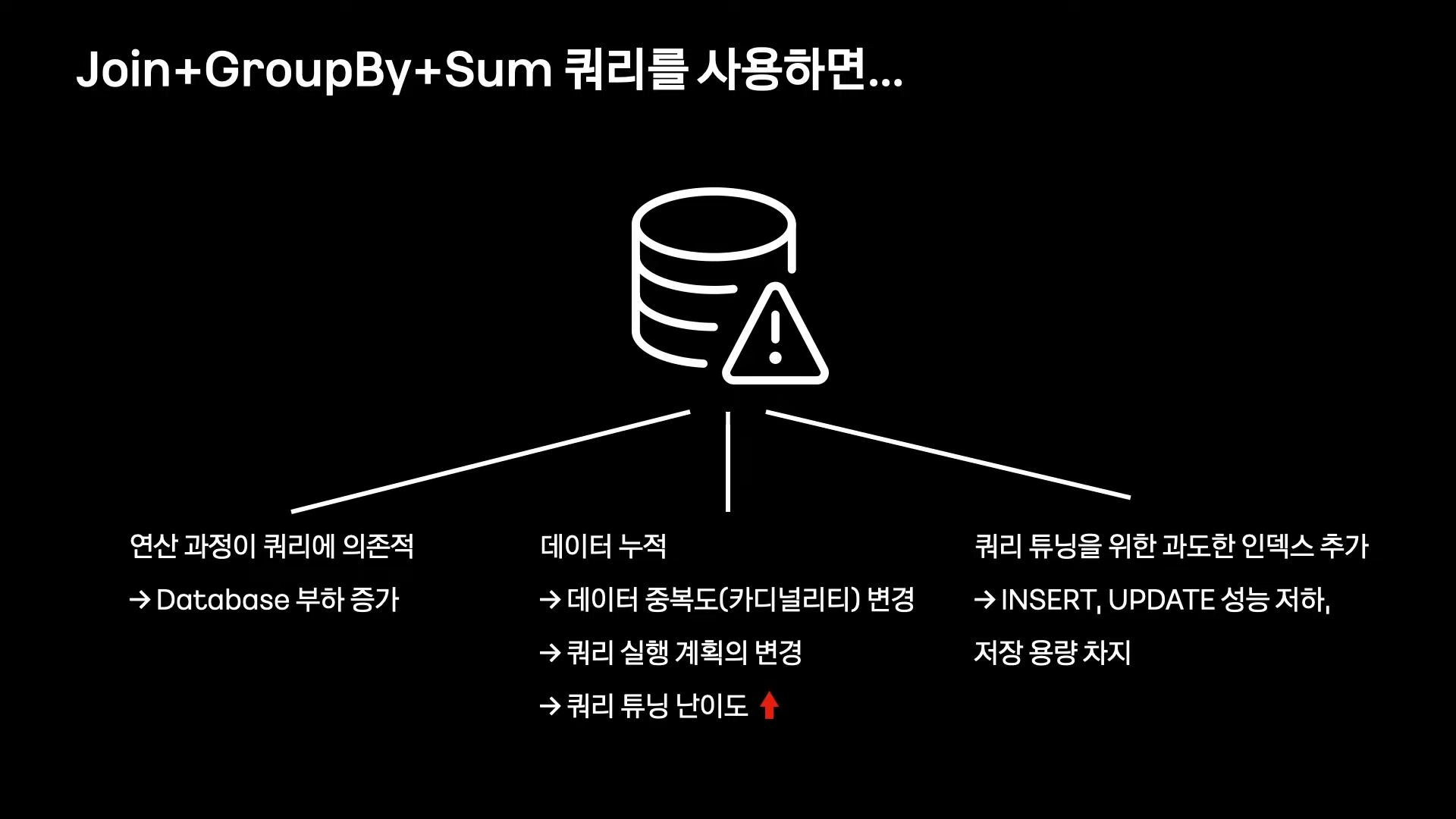
쿼리 자체가 너무 느려서 개선된 ItemReader가 무용지물이 됨
쿼리는 단순하게!
- 그냥 GroupBy를 안 쓰면 되겠네
- 직접 Aggregation을 하면 되겠네
하지만 직접 Aggregation을 위한 대용량 리소스를 애플리케이션에서 할당하기는 거의 불가능
(이를 위한 새로운 아키텍처 필요)
Redis(with Pipeline)를 통한 Aggregation
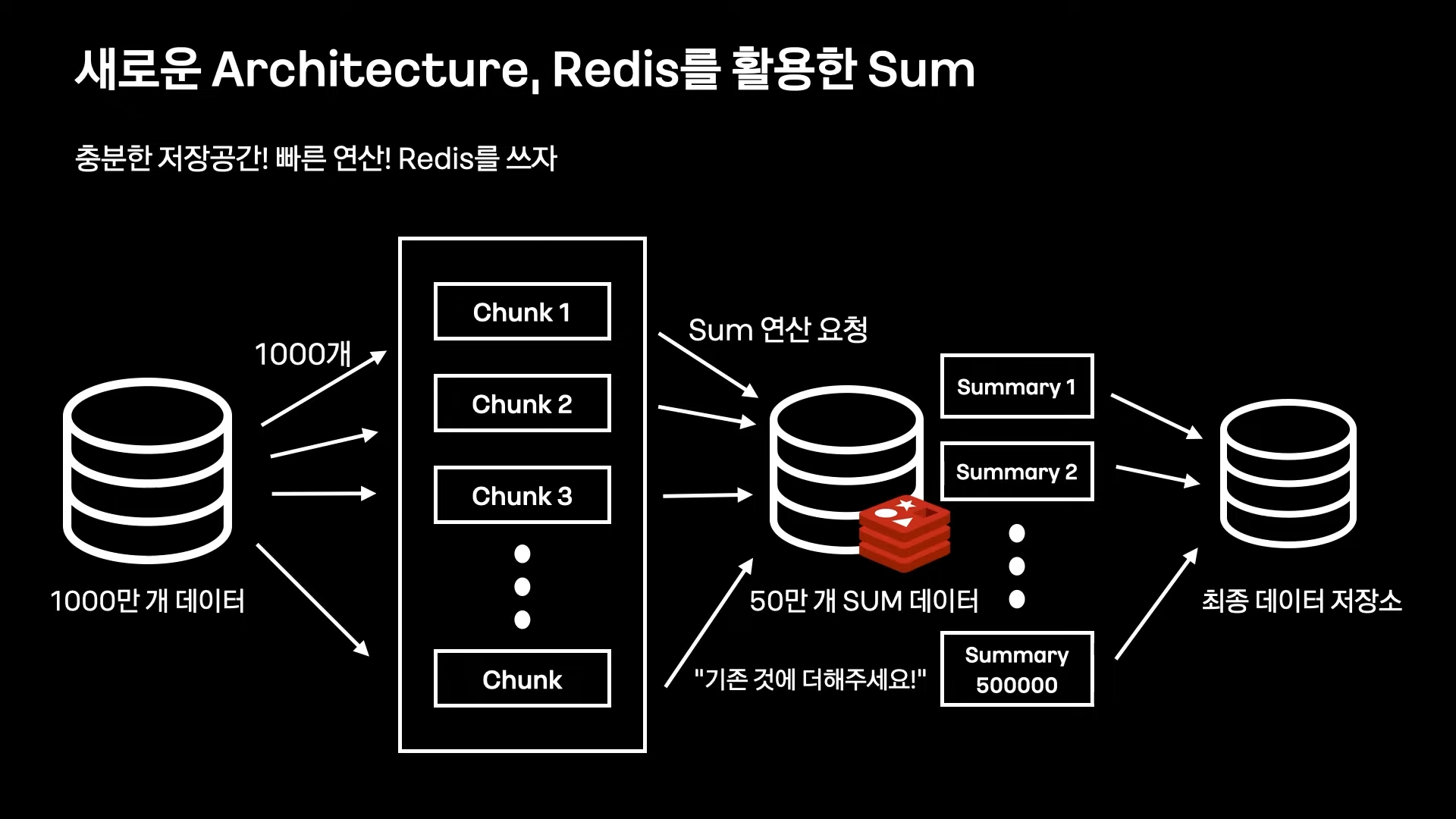

하지만 네트워크 I/O 레이턴시 문제가 생김
(1000만 개의 데이터를 합상하기 위해 1000만번의 요청 필요)
이를 해결하기 위해 Redis Pipeline을 사용해서 다수의 Command를 묶어서 처리
(Spring Data Redis로는 처리할 수 없는 부분이기 때문에 카카오페이에서는 자체 라이브러리를 개발해서 사용중)
대량 데이터 WRITE
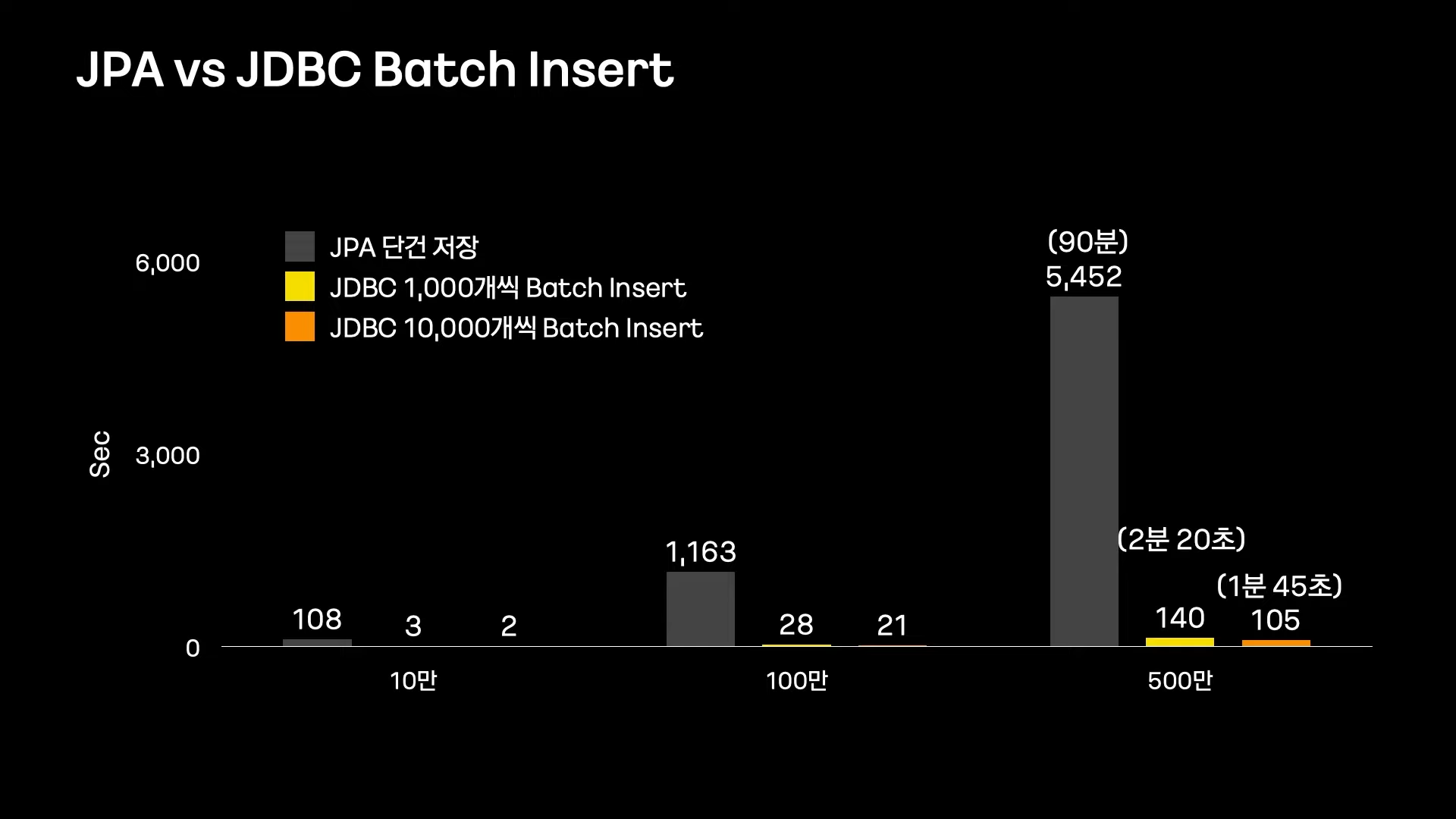
- Batch Insert 사용
(일괄로 쿼리 요청) - 명시적 쿼리
(필요한 칼럼만 UPDATE, 영속성 컨텍스트를 사용하지 않음)
Batch에서 JPA WRITE에 대한 고찰
- Dirty Checking과 영속성 관리
(불필요한 Check 로직으로 성능상 손해를 봄) - UPDATE할 때 불필요한 칼럼도 UPDATE
(Dynamic Update가 있지만 이는 동적으로 쿼리를 생성해서 성능 저하가 일어남) - JPA Batch Insert 지원이 어려운 부분
(ID 생성 전략을 IDENTITY로 하면 Batch Insert를 지원하지 않음)
따라서, Writer에서 JPA를 포기하고 Batch Insert할 것
Batch 구동 환경
Batch 구동 환경의 특징
- 자원 관리의 어려움
(언제 자원을 많이 사용하고 언제 적게 사용하는지 판단하기 어려움) - Batch 상태 파악(Monitoring)의 어려움
- Batch에서는 동작 하나하나가 매우 길다
- 대부분 스케줄 Too에서 로그를 볼 수 있지만 로그 정보가 매우 빈약하다
- 서비스 상태를 로그로 판단하는 것 자체가 전혀 시각적이지 않다
Spring Cloud Data Flow

- K8s와 완벽한 연동으로 Botch 실행 오케스트레이션
- 다수 Batch가 상호 간섭 없이 Running (by 컨테이너)
- K8s에서 Resouce 사용과 반납을 조율
- Spring Batch 유용한 정보 시각적으로 모니터링
- Spring Cloud Data Flow 자체 Dashboard 제공
- 그라파나 연동 가능
