1. 파이썬 기본 개념 정리
1) byte, encoding, decoding
- byte는 컴퓨터의 기본 저장 단위
- 1 byte = 8 bit
- 1 byte에는 2의 8승(256)개의 고유한 값을 저장할 수 있음
- 1 byte = 8 bit
- encoding: 문자열을 바이트로 변환하는 과정
- decoding: 바이트를 문자열로 변환하는 과정
2) 유니코드
ISO(International Standards Organization)에서 지정한, 전 세계 문자를 모두 표시할 수 있는 표준 코드
utf-8과 utf-16은 유니코드와 같지 않다. 유니코드의 여러 버젼이라고 생각하기 쉽지만, 유니코드는 오직 한 가지 버젼만 존재하며, utf-8, utf-16 같은 경우는 유니코드로 정의된 텍스트를 메모리에 인코딩하는 방식을 의미한다.
3) 파이썬 내장함수 ord(), chr()
ord(문자) : 해당 문자에 대응하는 유니코드 숫자를 반환
chr(숫자) : 해당 유니코드 숫자에 대응하는 문자를 반환
4) 원시 문자열 (raw string)
문자열을 시작하는 따옴표 앞에 r 을 붙이면 이스케이프 문자가 적용되지 않는다. 있는 그대로의 원시 문자열을 출력한다.
5) 공백문자
- trimming - 공백문자 제거
- 스페이스(space) : 한 칸 띄어쓰기
- 탭(tab) \t : 네 칸 띄어쓰기
- 줄 바꿈(new line) : 줄 바꿈
- 라인 피드 (line feed, 개행) \n : 줄 바꿈을 엄밀히 말하면 라인 피드라고 함.
- 캐리지 리턴 (carriage return, 복귀) \r : 커서를 맨 앞으로 이동시키는 것, 즉 커서를 원위치로 복귀(return)한다는 의미임. 커서를 맨 앞으로 보내고,\r 뒤에 문자가 있으면 그 문자를 출력함.
6) 정규표현식
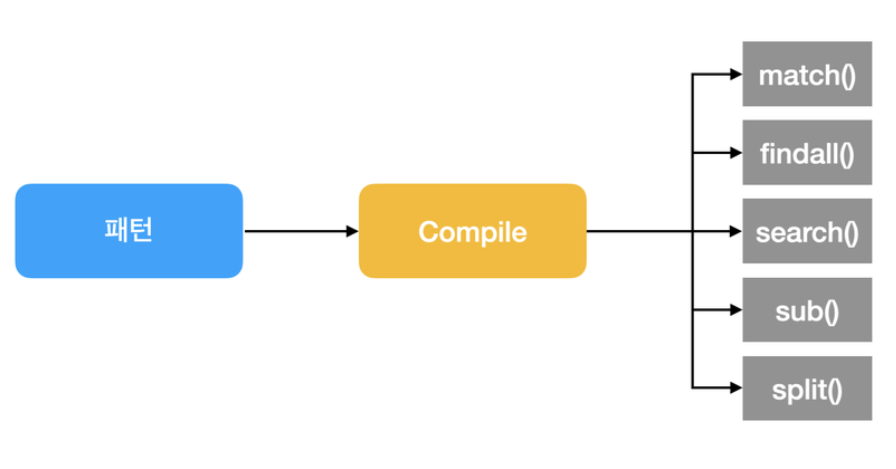
정규표현식을 사용하는 과정
1. import re 를 통해 정규식 모듈을 가져옴.
2. re.compile() 함수로 Regex 객체를 만듦.
3. 검색할 문자열을 Regex 객체의 search() , findall() 메소드로 전달.
-
.
[.] => 정규표현식에서 문장부호 .을 나타내고 싶을 때 []를 이용함. 정규표현식에서 .은 모든 문자를 의미한다.ex)
a[.]b
=> a.b와는 매치 되지만 a0b와는 매치되지 않는다. -
?
non-greedy 문자로, ?는 *?, +?, ??, {m,n}?와 같이 사용할 수 있다.
반복되는 것을 최소화 해준다.ex)
This is a <div> simple div <div/>
<.> => <div> simple div <div/>
<.?> => <div>
7) 파일 읽기
- with 구문
with open('파일이름', 'r') as f:with 구문을 사용해서 open된 객체의 경우 with문이 종료될 때 자동으로 close 되기 때문에 f.close()가 필요없다. 시스템 리소스의 안정적 사용을 위해서 with문을 활용하는 것이 좋다.
- f.seek(offset)
해당 파일의 위치(offset)을 찾아서 파일의 커서를 옮김. 파일의 처음 위치는 0이다. - f.tell()
현재 커서의 위치를 반환
2. 회고
학교 수업에서 가장 헷갈렸던 정규표현식을 봐서 어려웠다. 예전에 풀었던 문제까지 같이 복습해봤는데 해도 해도 모르겠는 기분이다. 자연어 처리 쪽으로 가려면 필수인 거 같은데 어떻게 공부해야 새로운 문제를 봐도 풀 수 있는 정도가 될 지 감도 안잡힌다. 그래도 오늘 수용할 수 있을 만큼 정리했으니 됐다고 생각한다. 그 외에 자잘하게 기억해야할 함수가 많아서 그냥 복사해 붙여넣기밖엔 되지 않을 거 같아 그런 부분은 생략했다.
