1. 머신러닝 개념 정리
1) 라이브러리
- missingno
- 결측 유무 확인, 시각화
2) 데이터 전처리
2-1) 베이스 라인 활용
1. 결측치 확인
# id column의 결측치 확인
null_check = pd.isnull(data['id'])
print(null_check)
# 결측치인 데이터만 선별
null_data = data.loc[null_check, 'id']
null_data.head()
# 결측치인 데이터의 개수를 셉니다.
print('{}: {}'.format('id', len(null_data.values)))- date라는 열에 해당하는 값을 0-5자리까지만 저장
data['date'] = data['date'].apply(lambda x : str(x[:6]))- 한 쪽으로 치우친 그래프를 log 함수를 이용해 변환
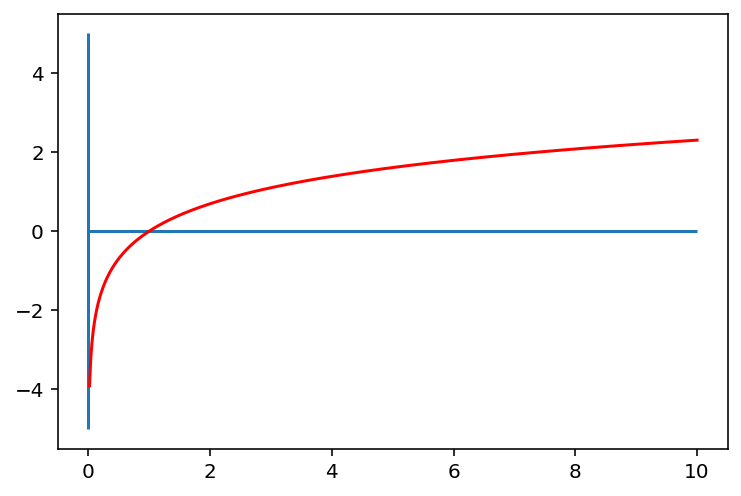
- 로그 함수 특징
- 0<x<1에서 기울기가 가파름 => 0에 가까운 값을 x로 입력할 경우 y값은 큰 범위로 벌어지게 됨
0에 가깝게 분포한 값들을 넓은 범위로 펼칠 수있음
- 1보다 큰 범위에서 기울기가 완만함 => x값에 대한 y값의 변화가 크지 않음
- 0<x<1에서 기울기가 가파름 => 0에 가까운 값을 x로 입력할 경우 y값은 큰 범위로 벌어지게 됨
2-2)
✔✔✔🤔
- 파라미터: 최적화가 필요한 파라미터. 학습과정에서 나은 출력을 위해 변화
- 하이퍼 파라미터: 사람이 직접 입력. 모델이 학습하는 과정에서 변화하지 않음
train['date'] = train['date'].apply(lambda i: i[:6]).astype(int)- astype: 타입을 바꿔줌
3) 앙상블 기법
앙상블 기법이란?
앙상블 기법 예시 설명
1. 의미: 여러 개의 학습 알고리즘을 사용해 도출된 예측을 결합함으로써 최종 예측의 정확도를 높이는 기법
예) 성능이 70퍼센트인 다섯 개의 분류기가 있을 경우
다섯 개가 완전히 맞는 경우 + 네 개만 맞는 경우 + 세 개만 맞는 경우
네 개만 맞는 경우, 세 개만 맞는 경우엔 5개 중 각 개수를 선별하는 식도 곱해줘야함
4) 그리드 탐색, 랜덤 탐색
- 그리드 탐색
사용자가 탐색을 위한 하이퍼 파라미터를 먼저 정해두면, 그 값으로 생성 가능한 모든 조합을 탐색함. 특정 값에 대한 하이퍼 파라미터를 탐색할 때 유용함 - 랜덤 탐색
사용자가 하이퍼 파라미터의 공간을 먼저 지정. 그 안에서 랜덤으로 조합을 선택해 탐색하는 방식
2. 회고
데이터 전처리를 가이드 라인 없이 하는 건 처음이어서 감이 잘 안잡혔다. 관계가 없어보이는 열을 제외하거나 값을 적절히 변형시키면 좋다고 하는데 내가 세운 기준이 적절하게 적용될 수 있을지를 모르겠다. 모델을 모두 구축하고 학습을 시킨 후에 성능을 계산하면 되겠지만 앞서 드는 생각이 있다보니 뭔가 쉽게 시도를 못하겠다. 저런 감각도 따로 키울 수 있는 건지 궁금하다. 따로 키울 수 있다면 역시 직접 많은 데이터를 분석해보면서 부딪혀보는 방법이 최고일 거 같다.

🐬 파이썬 / 인공지능 / 머신러닝