1. 딥러닝 개념 정리
1) Mini-batch
- 확률적 경사하강법의 경우 시간을 기준으로 할 때 효율이 가장 좋지만 데이터 확인 자체를 적게 하기 때문에 정확도 측면에서는 정밀도가 떨어진다.
- 위와 같은 상황에서 타협점을 찾는 방법이 mini-batch 기법
- cf) Full batch: 모든 문제를 순회한 후 업데이트
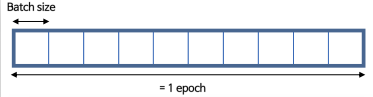
- Mini-batch: training data에서 일정한 크기(batch size)의 데이터를 선택해 비용을 계산하고 경사하강법을 적용함
- 설계자의 의도에 따라 속도와 안정성 관리 가능
- GPU 기반의 효율적인 병렬 연산 가능
batch, epochs 차이
- 1 iteration: batch size에 대한 1회의 gradient descent
2) 오류
- augmentation 추가했을 때:
train_ds = train_list_ds.map(process_path, num_parallel_calls=AUTOTUNE)
val_ds = val_list_ds.map(process_path, num_parallel_calls=AUTOTUNE)위와 같이 선언하지 않고 train_ds를 바로 prepare_for_training으로 설정해서 오류남
- Grid search 관련
grid search를 시도했는데 오류가 났다. 아마 train set과 validation, test set을 분류할 때 train_test_split() 함수를 쓰고 grid search를 해야 오류가 안나는 것 같다.
2. 회고
긴 연휴가 끝나고 첫 노드였다. 이전에 마무리 못한 노드를 마무리하고 진행했는데, 오랜만에 CV를 하니까 시간도 오래 걸리고 그만큼 오류도 많이 봤다. grid search를 시도해봤는데 실패해서 아쉬웠다. 접해본 개념은 늘어나는데 다른 프로젝트에서 배운 개념을 활용해보려고 해도 실패하는 것 같아 답답하다.

🐬 파이썬 / 인공지능 / 머신러닝