1. 개념 정리
1) 편향성
-
수집된 데이터 내에 이미 편향성이 존재한다면 이를 통해 도출된 결과 또한 편향성을 지닐 수밖에 없음
-
편향성을 측정하는 방법론: Word Embedding Association Test (WEAT)
-
편향성에 관한 연구
2) WEAT의 원리
- 심리학의 IAT(Implicit Association Test)라는 인지편향성 실험 구조에서 따온 것
- 특정 단어와 각각의 성별 간의 거리가 동일하지 않을 때, 그 차이를 이용해 편향성을 계산
- 편향성이 드러나는 단어와 각각의 성별을 가장 잘 대표하는 단어를 여러 개 골라 set을 생성
- 단어 셋에 속한 모든 단어끼리 편향성을 각각 전부 계산해서 평균을 수치화
- target, attribute
3) WEAT를 이용한 편향성 계산
- WEAT score: 절댓값이 클수록 두 개념축 사이의 편향성이 크게 나타남
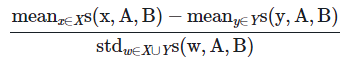
- cosine similarity: dot product, magnitude
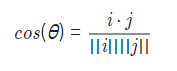
- cos(θ) = 1: 두 벡터의 방향이 같음
- cos(θ) = 0: 두 벡터가 직교할 때
- cos(θ) = -1: 두 벡터의 방향이 반대
- X에 속하는 단어와 Y에 속하는 단어가 A-B 개념축에 대해 가지는 편향성의 정도가 뚜렷이 차이 날수록 분자가 커짐
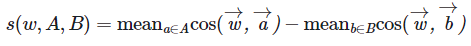
- -2에서 2사이의 값을 가지게 됨
- 절댓값이 클수록 w는 A-B 개념축에 대해 편향성을 가짐
4) 오류
- 'Word2VecKeyedVectors' object has no attribute 'index_to_key'
- w2v = KeyedVectors.load_word2vec_format(model_dir, binary=True, limit=500000)
를 실행했을 때 결과가 코랩에서는 <gensim.models.keyedvectors.Word2VecKeyedVectors>로 나온 반면 아이펠에서는 <gensim.models.keyedvectors.KeyedVectors>로 나옴. - stackoverflow에 같은 오류를 겪은 사람을 확인했지만 해결방법은 나오지 않음
- 버전 문제일 거라 생각해서 확인해봤더니 코랩의 gensim 버전은 3.6.0이었고 아이펠은 4.1.2였음.
- 코랩에서의 버전을 업그레이드 해주니 됨
! pip install --upgrade 원하는 패키지 명
2. 회고
편향성을 어떤 식으로 측정하는지에 관해 배웠다. 일전에 분류 모델이 인종차별적인 분류를 수행했다는 기사를 본 적 있었다. 특정 동물을 흑인으로 분류해서 문제가 되었다고 했는데, 또 다른 동물은 백인으로 분류해 정말 분류 모델이 차별적인 관점을 학습한 것인지, 아니면 단순히 유사도를 그렇게 판단한 것인지 이러한 현상을 구분해야겠다는 생각을 했었다. 또 한 편으로는 성별에 관해서도 특정한 성역할과 관련있는 결과가 나오는 경우가 많다고도 한다.
차별적인 관점을 내재한 데이터에서 어떻게 편향성을 없앨 것인지, 그 방법을 꾸준히 생각하고 해결하고자 하는 것은 엔지니어가 기본적으로 가져야할 윤리적 태도라고 생각한다. 그래서 이번 노드가 특히 더 인상깊었는데, 관련해서 프로젝트를 해봐도 좋을 거 같다.

🐬 파이썬 / 인공지능 / 머신러닝