1. 개념 정리
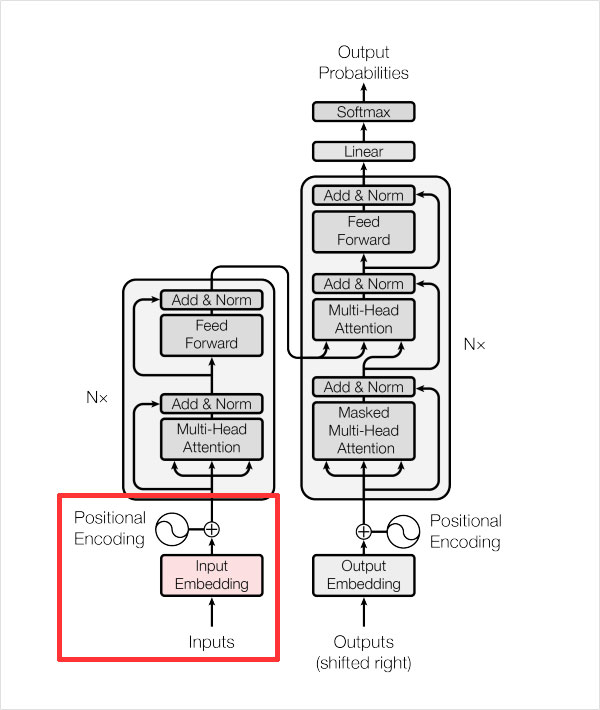
1) 내부 모듈 구현
- 최초의 텍스트 입력 데이터: batch_size * length
- 최종 출력 데이터: batch_size * length * vocab_size
매 스텝마다 vocab_size와 같은 수로 존재하는 클래스 수 중 적당한 단어를 선택하는데, 이 선택을 length 만큼 반복
- Tensor의 변화
- 입력 데이터 → [ batch_size x length ]
- Source & Target Embedding → [ batch_size x length x d_emb ]
- Positional Encoding → 2번 결과에 더해지므로 결과의 변화는 없음
- Multi-Head Attention → 여러 개의 서브 모듈들이 존재
- Split Heads →[ batch_size x length x heads x (d_emb / n_heads) ]
- Masking for Masked Attention
- Scaled Dot Product Attention
- Combine Heads →[ batch_size x length x d_emb ]
- Residual Connection
- Layer Normalization
- Position-wise Feed-Forward Network → [ batch_size x length x d_ff ]
- Output Linear Layer → [ batch_size x length x vocab_size ]
2. 회고
학습시키는 데 3 epochs 돌렸는데 9시간 째 하고 있다. 데이터 셋을 50 토큰 이하로 줄여도 별로 줄어들지 않던데 한 30으로 확 줄였어야하는 거 같다. 일단 계속 해보는데 안되겠다 싶으면 중간에 멈추고 데이터 셋을 다시 줄여야겠다.

🐬 파이썬 / 인공지능 / 머신러닝