데이터 로더 구성
tokenizer = Mecab() #1
stopwords = ['의','가','이','은','들','는','좀','잘','걍','과','도','를','으로','자','에','와','한','하다']
def load_data(train_data, test_data, num_words=10000):
# train data 데이터 중복 제거
train_data.drop_duplicates(subset=['document'], inplace=True)
# train data NaN 결측치 제거
train_data = train_data.dropna(how='any')
# test data도 위와 동일하게 처리
test_data.drop_duplicates(subset=['document'], inplace=True)
test_data = test_data.dropna(how = 'any')
# train data를 한국어 토크나이저로 토큰화
X_train = []
for sentence in train_data['document']:
temp_X = tokenizer.morphs(sentence) # 토큰화
temp_X = [word for word in temp_X if not word in stopwords] #불용어 제거
X_train.append(temp_X)
# test data에 대해 같게 실행
X_test = []
for sentence in test_data['document']:
temp_X = tokenizer.morphs(sentence) # 토큰화
temp_X = [word for word in temp_X if not word in stopwords] #불용어 제거
X_test.append(temp_X)
# counter을 쓰기 위해 2차원 리스트인 X_train을 1차원 배열로 변환 뒤 다시 리스트로 변환
words = np.concatenate(X_train).tolist() #2
counter = Counter(words)
counter = counter.most_common(10000-4)
vocab = ['<PAD>', '<BOS>', '<UNK>','<UNUSED>'] + [key for key, _ in counter]
word_to_index = {word:index for index, word in enumerate(vocab)}
# 텍스트 스트링을 사전 인덱스 스트링으로 변환
def wordlist_to_indexlist(wordlist):
return [word_to_index[word] if word in word_to_index else word_to_index['<UNK>'] for word in wordlist]
X_train = list(map(wordlist_to_indexlist, X_train))
X_test = list(map(wordlist_to_indexlist, X_test))
return X_train, np.array(list(train_data['label'])), X_test, np.array(list(test_data['label'])), word_to_index
X_train, y_train, X_test, y_test, word_to_index = load_data(train_data, test_data)-
Mecab 사용의 이유
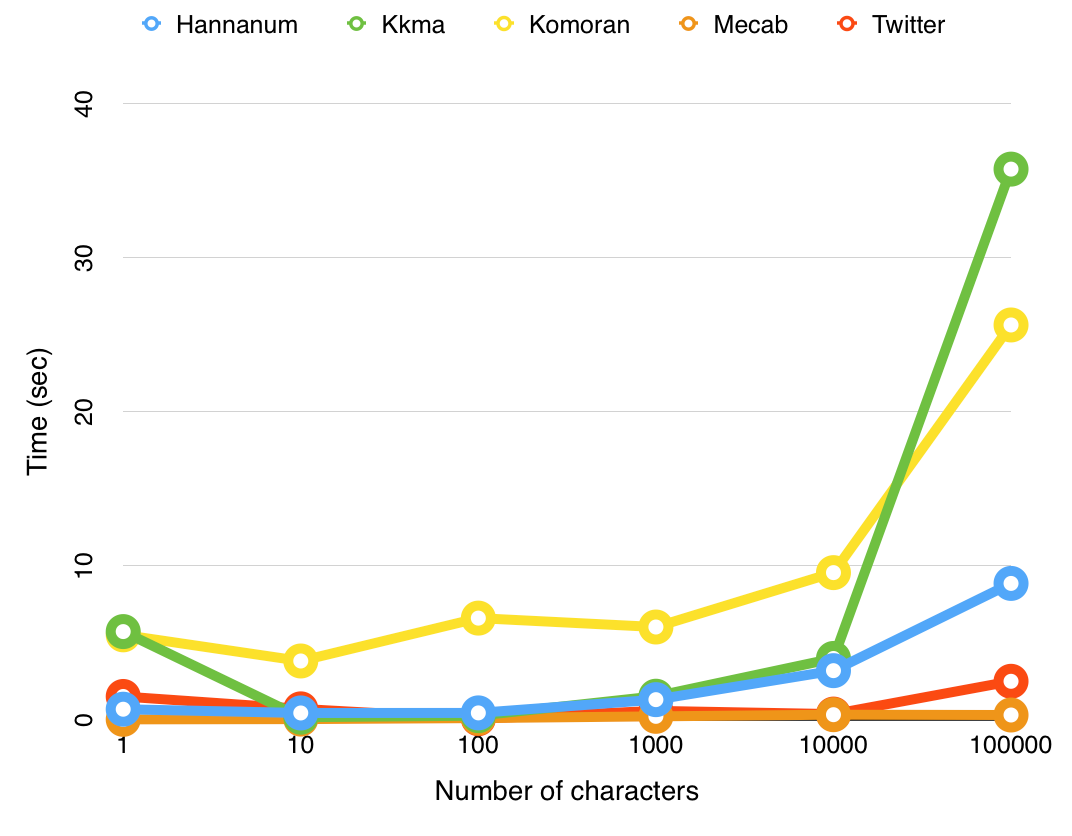
실행량이 늘어나도 실행 시간이 크게 바뀌지 않음 -
np.concatenate
공식 문서: Join a sequence of arrays along an existing axis.
axis 설정을 하지 않았기 때문에
a = np.array([[1, 2], [3, 4]])
b = np.array([[5, 6]])
>>> np.concatenate((a, b), axis=None)
array([1, 2, 3, 4, 5, 6])위와 같이 np의 배열로 선언된다. 배열로 바꾼 뒤 to list를 해줌.
모델 구성
vocab_size = 10000
word_vector_dim = 200
lstm_model = tf.keras.Sequential() #1
lstm_model.add(tf.keras.layers.Embedding(vocab_size, word_vector_dim, input_shape=(None,))) #2
lstm_model.add(tf.keras.layers.LSTM(128))
lstm_model.add(tf.keras.layers.Dense(8, activation='relu')) #3
lstm_model.add(tf.keras.layers.Dense(1, activation='sigmoid'))
lstm_model.summary()- 순차 구조를 가진 모델 객체 생성
- add 매서드를 사용해 입력층, 은닉층, 출력층 추가
embedding: 입력과 출력 크기 넘겨줘야함
embedding(15,3) : 총 단어 수 15개, 출력되는 크기는 3 - 은닉층: 8개의 출력 뉴런 사용, relu 활성화 함수 사용
출력층: 1개의 출력 뉴런 사용, sigmoid 활성화 함수 사용
compile
lstm_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
epochs=3
lstm_history = lstm_model.fit(partial_X_train,
partial_y_train,
epochs=epochs,
batch_size=512,
validation_data=(X_val, y_val),
verbose=1)- optimize: 최적화 방법 설정 - 정확도를 최대화하기 위해 파라미터를 조정, 모델의 성능을 최적화하는 알고리즘
- loss: 손실 함수 설정 (예측값과 실제 값 사이의 차이)
- metrics: 평가 지표

🐬 파이썬 / 인공지능 / 머신러닝