
📖 '자료구조와 알고리즘' 책을 공부한 내용을 담고 있습니다.
5장. 빅 오를 사용하거나 사용하지 않는 코드 최적화
알고리즘의 효율성을 빅 오 표기법으로 많이 사용한다. 하지만, 빅 오 표기법이 모든 알고리즘을 정확하게 표현하지는 않는다. 이번 장에서는 동일한 빅 오를 갖은 알고리즘 중에서 더 효율적인 알고리즘을 고르는 법을 알아보자!
5-1. 선택 정렬
'선택 정렬'이란?
최솟값을 찾아 원소 간 비교/교환 과정을 반복하여 배열을 정렬하는 알고리즘
선택 정렬 알고리즘
배열 [2, 6, 1, 3] 을 오름차순으로 선택정렬하면 다음의 단계를 따른다.
1. 첫 번째 패스스루 (pass through)
- 왼쪽부터 오른쪽 방향으로 하나의 셀씩 이동하며 가장 작은 값의 인덱스를 변수에 저장한다.
1-1. 현재 최솟값은 2이므로, 0번째 인덱스를 변수에 저장
| 2 | 6 | 1 | 3 |
|---|---|---|---|
| ↑ |
1-2. 현재 최솟값은 여전히 2
| 2 | 6 | 1 | 3 |
|---|---|---|---|
| ↑ |
1-3. 현재 최솟값이 1로 이므로, 변수를 3번째 인덱스로 변경
| 2 | 6 | 1 | 3 |
|---|---|---|---|
| ↑ |
1-4. 현재 최솟값은 1
| 2 | 6 | 1 | 3 |
|---|---|---|---|
| ↑ |
1-5. 첫 번째 패스스루에서 최솟값으로 저장된 인덱스의 값을 첫 번째 인덱스의 값과 교환한다.
| 1 | 6 | 2 | 3 |
|---|---|---|---|
| 완료 |
2. 두 번째 패스스루
- 두 번째 패스스루는 두 번째 인덱스부터 시작하여 위의 과정을 진행한다.
2-1. 인덱스 1부터 최솟값을 다시 찾는다. 현재 최솟값은 6
| 1 | 6 | 2 | 3 |
|---|---|---|---|
| 완료 | ↑ |
2-2. 현재 최솟값은 2이므로, 변수에 인덱스 2를 저장한다.
| 1 | 6 | 2 | 3 |
|---|---|---|---|
| 완료 | ↑ |
2-3. 현재 최솟값은 여전히 2
| 1 | 6 | 2 | 3 |
|---|---|---|---|
| 완료 | ↑ |
2-4. 인덱스 1의 값과 인덱스 2의 값을 교환(swap)한다.
| 1 | 2 | 6 | 3 |
|---|---|---|---|
| 완료 | 완료 |
3. 마지막 인덱스까지 오름차순 정렬될 때까지 패스스루를 반복한다.
| 1 | 2 | 3 | 6 |
|---|---|---|---|
| 완료 | 완료 | 완료 | 완료 |
5-2. 선택 정렬 실제로 해보기
- 다음은 Javascript로 구현한 선택 정렬이다.
function selectionSort(array) {
// 인덱스 0 부터 값을 하나씩 비교해서 lowestNumberIndex 찾기
for (let i = 0; i < array.length - 1; i++) {
// lowestNumberIndex에 현재 인덱스 값을 저장
let lowestNumberIndex = i;
// 인덱스 간 값을 비교
for (let j = i + 1; j < array.length; j++) {
// 현재 값보다 다음 값이 작으면 lowestNumberIndex에 j를 저장
if (array[j] < array[lowestNumberIndex]) {
lowestNumberIndex = j;
}
}
// lowestNumberIndex이 현재 인덱스와 같지 않으면 값 교환(swap)
if (lowestNumberIndex !== i) {
let temp = array[i];
array[i] = array[lowestNumberIndex];
array[lowestNumberIndex] = temp;
}
}
// 모든 패스스루가 끝나면 정렬된 배열을 반환
return array;
}
5-3. 선택 정렬의 효율성
5개의 원소를 가진 배열을 예제로 사용하여 선택정렬의 효율성을 알아보자
선택 정렬의 효율성은 비교(comparison)와 교환(swap)의 횟수에 의해 결정된다.
- 비교 (comparison)
첫 번째 패스스루에서 각 원소 간 비교가 4회 발생한다. 패스스루가 반복될수록 횟수가 1번씩 줄어서 네 번째 패스스루에서는 비교 1회가 발생한다.
N개의 원소의 배열일 경우, (N-1) +(N-2) ・・・ + 1번의 비교가 발생한다.
| 패스스루 | 비교 횟수 |
|---|---|
| 1 | 4번 |
| 2 | 3번 |
| 3 | 2번 |
| 4 | 1번 |
- 교환(swap)
1번의 패스스루 당 최대 1 번 일어난다. 최솟값이 이미 올바른 위치에 있느냐에 따라서 교환이 1번 발생하기 때문이다.
다음 표는 버블 정렬과 선택 정렬을 비교한 것이다.
선택 정렬이 버블 정렬보다 약 2배정도 빠른 것을 볼 수 있다.
| 원소 개수(N) | 버블 정렬에서 최대 단계 수 | 선택 정렬에서 최대 단계 수 |
|---|---|---|
| 5 | 10 | 14 (10번의 비교+4번의 교환) |
| 10 | 90 | 54 (45번의 비교+9번의 교환) |
| 20 | 380 | 199 (180번의 비교+19번의 교환) |
| 40 | 1560 | 819 (780번의 비교+39번의 교환) |
| 80 | 6320 | 3239 (3160번의 비교+79번의 교환) |
5-4. 상수 무시하기
버블 정렬과 선택 정렬의 단계 수는 확실히 차이가 있다.
하지만 빅 오 표기법은 두 알고리즘을 O(N²)으로 표기하는데 왜 그런걸까?
위 버블 정렬과의 비교표에서 보았듯이, 선택 정렬은 버블 정렬과 두 배정도 차이난다. 즉, 버블 정렬이 N² 단계가 걸린다면, 선택 정렬은 약 N² / 2 단계 걸린다고 볼 수 있다.
| 원소 개수(N) | N² / 2 | 선택 정렬에서 최대 단계 수 |
|---|---|---|
| 5 | 5² / 2 = 12.5 | 14 |
| 10 | 10²/ 2 = 50 | 54 |
| 20 | 20²/ 2 = 200 | 199 |
| 40 | 40²/ 2 = 800 | 819 |
| 80 | 80²/ 2 = 3239 | 3239 |
하지만 빅 오 표기법으로 선택 정렬을 O(N²)으로 표기한다. 그 이유는 빅 오의 규칙 때문이다.
빅 오 표기법은 상수를 무시한다.
- N / 2 단계의 알고리즘은 O(N)으로 표현
- N² + 10 단계의 알고리즘은 O(N²)으로 표현
- 2N 단계의 알고리즘은 O(N)으로 표현
- 100N 단계의 알고리즘은 O(N)으로 표현
5-5. 빅 오 카테고리
빅 오 표기법은 '장기적인 궤적'에 따라 카테고리별로 묶어서 표현한다.
O(N²)의 알고리즘과 O(N)의 알고리즘을 비교해보면, O(2N), O(10N), O(100N) 처럼 어떤 수를 곱해도 N²과 효율성에서 많은 차이가 난다. 그렇기 때문에 O(2N), O(10N), O(100N)를 모두 O(N) 카테고리로 분류한다.
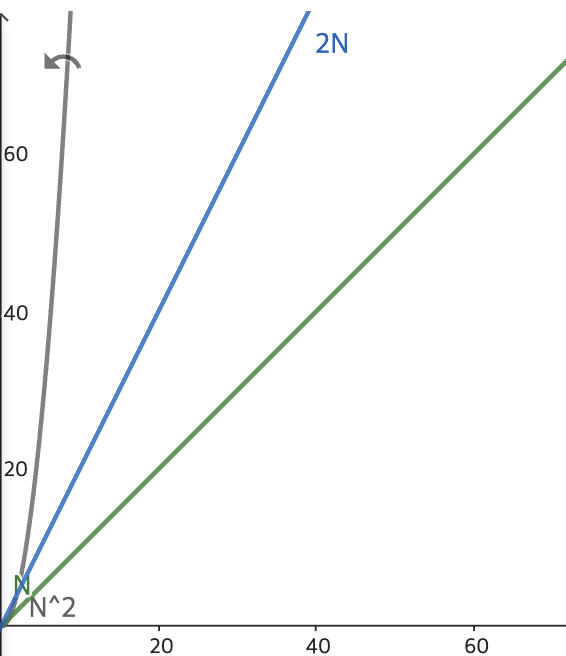
빅 오 표기법은 O(N²)와 O(N), O(logN), O(1) 등 서로 다른 카테고리에 속하는 알고리즘을 비교할 때 좋은 도구이다. 하지만 같은 카테고리에서 서로 다른 알고리즘을 비교할 때는 정확하지 않을 수 있다. 더 세밀하게 분석할 필요가 있다.
실전예제
O(N)이라는 동일한 카테고리의 2개의 알고리즘를 비교해보자.
두 알고리즘은 upperLimit = 100이고, 2부터 시작하여 짝수를 출력한다.
-
알고리즘 (1)
: number가 짝수인지 확인한다. 짝수면 number를 출력한다. number가 1씩 증가한다.
총 100단계가 걸린다. -
알고리즘 (2)
: number에 2씩 더한다.
총 50단계가 걸린다.
// 알고리즘 (1)
function print_number_v1(upperLimit) {
let number = 2;
while (number <= upperLimit) {
// number가 짝수면 출력
if (number % 2 === 0) {
console.log(number);
}
number += 1;
}
}
// 알고리즘 (2)
function print_number_v2(upperLimit) {
let number = 2;
while (number <= upperLimit) {
console.log(number);
number += 2;
}
}
알고리즘 과정에는 for 문의 반복 외에도 비교 단계(if (number % 2 === 0)), 출력 단계(console.log(number), number 증가 등 여러 단계가 걸린다. 이 모든 단계가 중요하지만, 빅 오 표기법은 단계를 표현할 때 상수를 버리고 표현식을 단순화한다. 그렇기 때문에 빅 오 표기법은 루프 실행 횟수에 더 초점을 맞추어 표기하게 된다.
연습문제
- 빅 오 표기법을 사용해서 4N + 16 단계가 걸리는 알고리즘의 시간 복잡도를 나타내자.
- O(N)
- 빅 오 표기법을 사용해서 2N² 단계가 걸리는 알고리즘의 시간 복잡도를 나타내자.
- O(N²)
- 빅 오 표기법을 사용해서 다음 함수의 시간 복잡도를 나타내자. 함수는 주어진 배열의 모든 수를 두 배로 만든 후 그 합을 반환한다.
function doubleAndSum(arr) {
let sum = 0;
for (let i = 0; i < arr.length; i++) {
arr[i] *= 2; // 배열의 각 요소를 두 배로 만듦
sum += arr[i]; // 두 배로 만든 요소를 합산
}
return sum;
}- O(N), 2N 단계이지만 2를 무시하여 O(N)으로 표기
4.빅 오 표기법을 사용해서 다음 함수의 시간 복잡도를 나타내자. 함수는 문자열 배열을 받아 각 문자열을 다양한 형태로 출력한다.
function processStrings(arr) {
for (let i = 0; i < arr.length; i++) {
const originalString = arr[i];
// 각 문자열을 대문자로 만들어서 출력
const upperCaseString = originalString.toUpperCase();
console.log("UpperCase:", upperCaseString);
// 각 문자열을 소문자로 만들어서 출력
const lowerCaseString = originalString.toLowerCase();
console.log("LowerCase:", lowerCaseString);
// 각 문자열의 첫 글자만 대문자로 만들어서 출력
const capitalizeString = originalString.charAt(0).toUpperCase() + originalString.slice(1).toLowerCase();
console.log("Capitalize:", capitalizeString);
}
}- O(N), 3N 단계이지만 3를 무시하여 O(N)으로 표기
- 다음 함수는 수로 된 배열을 순회하며 인덱스가 짝수이면 배열 내 모든 수에 대해 그 인덱스의 수를 더해 출력한다. 빅 오 표기법으로 나타내면 이 함수의 효율성은 무엇일까?
function everyOther(array) {
array.forEach((number, index) => {
if (index % 2 === 0) {
array.forEach((otherNumber) => {
console.log(number + otherNumber);
});
}
});
}- O(N²), forEach 매서드를 이중으로 사용하여 배열의 길이만큼 반복하기 때문이다.
