데이콘에서 음향 데이터를 이용해 기계의 고장 여부를 판단하는 대회가 열렸다. 한번도 다뤄본 적 없는 음향데이터를 만져볼 좋은 기회라고 생각되어 대회에 참가하였다.
https://dacon.io/competitions/official/236036/overview/description
데이터 살펴보기
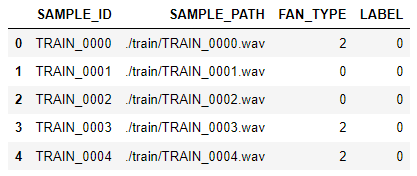
train.csv 에는 아래 사진과 같이 샘플의 고유ID, 음향 파일의 경로, FAN의 종류(0,2), 기계 고장 여부(0:정상, 1:고장)로 구성되어 있다. 이때, train의 LABEL은 모두 정상 샘플만 존재한다. train 폴더에는 SAMPLE_PATH 에 나타나는 소리파일(.wav)이 있다.
패키지 import
import numpy as np
import pandas as pd
from tqdm.auto import tqdm
import warnings
warnings.filterwarnings(action='ignore')
import librosa
import librosa.display
import matplotlib.pyplot as plt
from sklearn.svm import OneClassSVMlibrosa를 이용한 시각화
SAMPLE_ID 가 'TRAIN_0000'인 샘플을 load하여 시각화해 보았다. 파라미터 sr을 이용해 sampling rate(주파수 분석의 시간 간격)을 조정할 수 있다. 기본값은 22050 이다.
trainData = pd.read_csv('./train.csv')
train_path = trainData['SAMPLE_PATH'][0]
train_y, sr = librosa.load(train_path)
plt.plot(train_y)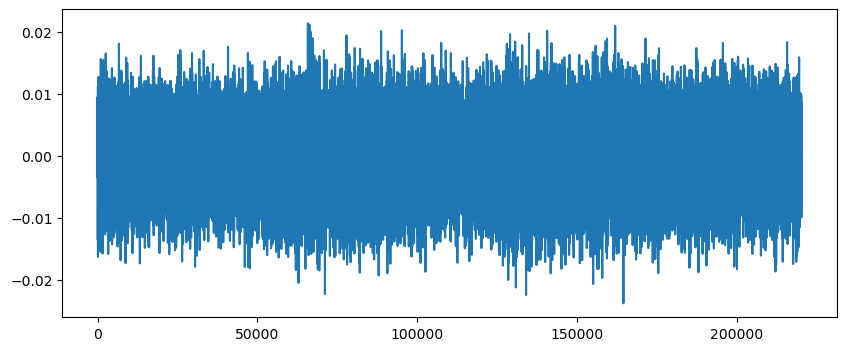
Short Time Fourier Transform (STFT)
시간 단위로 짧게 쪼개서 푸리에 변환을 하는 방법이다.
train_stft = np.abs(librosa.stft(train_y))
librosa.display.specshow(librosa.amplitude_to_db(train_stft, ref= np.mean),
y_axis='log', sr=sr, x_axis='time')
plt.colorbar(format='%+2.0f dB')
plt.title('STFT _train')
plt.tight_layout()
plt.show()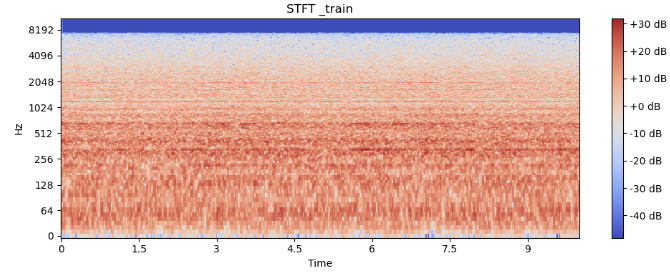
Mel Spectrogram
Mel Scale 변환을 통해 오디오를 분석하여 특징을 추출하는 방법이다.
train_mel = librosa.feature.melspectrogram(y= train_y, sr= sr)
train_mel_dB = librosa.amplitude_to_db(train_mel, ref= np.mean)
librosa.display.specshow(train_mel_dB, y_axis='mel', sr=sr, x_axis='time')
plt.colorbar(format='%+2.0f dB')
plt.title('Mel-Spectrogram _train')
plt.tight_layout()
plt.show()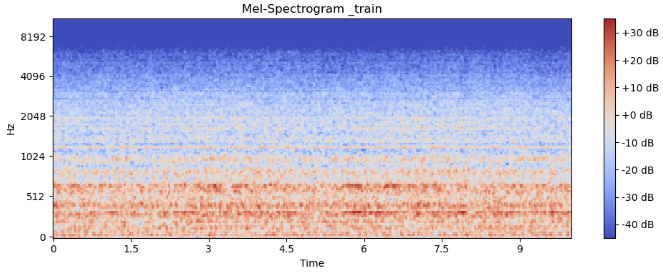
Mel-Frequency Cepstral Coefficients (MFCC)
사람의 청각구조를 반영하여 음성 정보를 추출하는 방법으로, mel-spectrum에서 Cepstral 분석으로 추출한 값이다. Cepstral 분석이란, 스펙트럼 신호의 로그값에 역푸리에 변환을 하는 것을 말한다.
train_mfccs = librosa.feature.mfcc(train_y, sr= sr, n_mfcc=128)
librosa.display.specshow(train_mfccs, sr=sr, x_axis='time')
plt.colorbar()
plt.title('MFCC _train')
plt.tight_layout()
plt.show()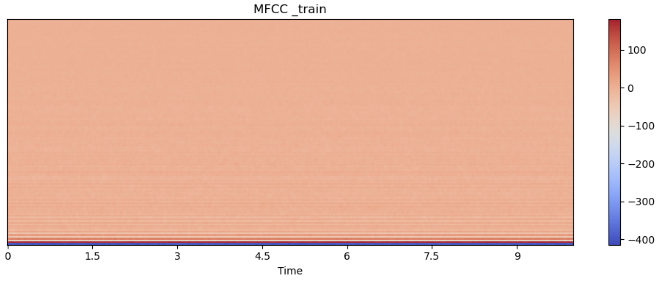
Chroma Frequencies
인간의 청각이 한 옥타브를 유사음으로 인지한다는 것에 기반하여, 모든 스펙트럼을 12개의 Bin으로 표현한다.
train_chromagram = librosa.feature.chroma_stft(train_y, sr= sr)
train_chromagram.shape # (12, 431)
librosa.display.specshow(train_chromagram, x_axis='time', y_axis= 'chroma')
plt.colorbar()
plt.title('Chroma _train')
plt.show()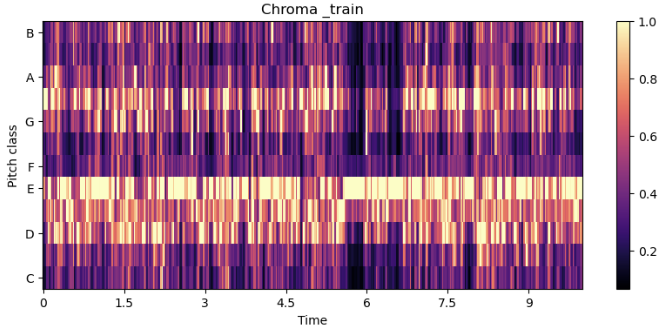
Zero Crossing Rate
음파가 양에서 음, 음에서 양으로 바뀌는 비율이다. 0을 많이 지날수록 노이즈가 많음을 뜻한다.
train_zero_crossings = librosa.zero_crossings(train_y, pad=False)
sum(train_zero_crossings) # 결과는 21960데이터 전처리
위에서 시도했던 여러 방법들 중 mfcc를 선택하고, 파라미터 n_mfcc = 27로 설정하여 소리의 특징을 추출하였다.
train_df = pd.read_csv('train.csv')
test_df = pd.read_csv('test.csv')
def get_mfcc_feature(df, num):
features = []
for path in tqdm(df['SAMPLE_PATH']):
y, sr = librosa.load(path, sr= 16000)
mfcc = librosa.feature.mfcc(y= y, sr= sr, n_mfcc= num)
y_feature = []
for e in mfcc:
y_feature.append(np.mean(e))
features.append(y_feature)
return features
train_features = get_mfcc_feature(train_df, 27)
test_features = get_mfcc_feature(test_df, 27)모델 적합
전처리를 통해 얻은 특징의 수치들을 데이터프레임으로 저장하여, 각 특징별 상관관계를 구하여 변수를 선택하는 과정을 추가하였다. 그 중 Col5, Col6, Col7 을 제외하였을 때 점수가 높게 나왔다.
모델로는 OCSVM을 선택하였다. 비지도학습의 머신러닝 모델로는 Isolation Forest, OneClassSVM, LocalOutlierFactor 등이 있다. 주어진 데이터들을 바탕으로 이 데이터에서 많이 떨어져 있는 데이터를 이상치로 판단하는 모델들이다. 그 중 OCSVM은 n차원의 좌표축에서 데이터와 원점 사이의 거리를 기준으로 이상치를 판단하는 방법이다. 파라미터는 kernel='rbf', gamma=0.004, nu=0.03 으로 설정하였다.
# 데이터 프레임으로 변환
train_features_df = pd.DataFrame(train_features, columns = [f'Col{i}' for i in range(1,28)])
test_features_df = pd.DataFrame(test_features, columns = [f'Col{i}' for i in range(1,28)])
# corr 구한 후, 0.7 이상의 값들만 확인
cor = train_features_df.corr()
pd.set_option('display.max_rows',None)
pd.set_option('display.max_columns',None)
cor[abs(cor) > 0.7]
# 변수 선택
train_features_df = pd.DataFrame(train_features, columns = [f'Col{n}' for n in range(1,28)])
train_features_df.drop(['Col6','Col5','Col7'], axis=1, inplace=True)
test_features_df = pd.DataFrame(test_features, columns = [f'Col{n}' for n in range(1,28)])
test_features_df.drop(['Col6','Col5','Col7'], axis=1, inplace=True)
# OCSVM 훈련
svm = OneClassSVM(kernel='rbf', gamma= 0.004, nu=0.03)
svm.fit(train_features_df)테스트 데이터 예측
test 데이터를 예측하여 1(정상)과 -1(불량)로 표현된 값들을 0(정상)과 1(불량)로 바꿔주고, 파일로 저장하여 제출하였다.
# 0, 1로 변환
def get_pred_label(model_pred):
# 1: 정상, -1: 불량 => 0: 정상, 1:불량 변환
model_pred = np.where(model_pred == 1, 0, model_pred)
model_pred = np.where(model_pred == -1, 1, model_pred)
return model_pred
# 예측
test_pred = svm.predict(test_features_df)
test_pred = get_pred_label(test_pred)
# 제출
submit = pd.read_csv('./answer/sample_submission.csv')
submit['LABEL'] = test_pred
submit.to_csv('./answer/ans1.csv', index= False)후기
모델을 선택하는 과정에서 deep SVDD 를 이용해보고 싶었다. 딥러닝까지 시도하기에는 시간이 부족하여 모델링은 하지 못했지만, 더 공부하여 딥러닝을 이용한 모델링도 도전해볼 것이다!
