
이제 여정의 마지막을 달리고 있다.
이번 포스팅은 드디어 스크래핑한 내용을 토대로 excel에 그대로 넣어보는 과정을 따라 갈 것이다.
⦁ extract_indeed_jobs(keyword) 추가 코드
직전에 했던 extract_indeed_jobs함수에 page에 대한 코드를 추가로 넣었다.
def extract_indeed_jobs(keyword):
pages = get_page_count(keyword)
print("Found",pages,"pages")
results = []
for page in range(pages):
options = Options()
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
browser = webdriver.Chrome(options=options)
base_url = "https://kr.indeed.com/jobs"
final_url = f"{base_url}?q={keyword}&start={page*10}"
print("Requesting",final_url)
browser.get(final_url)여기서 주목해야 할 곳은 11~14줄이다.
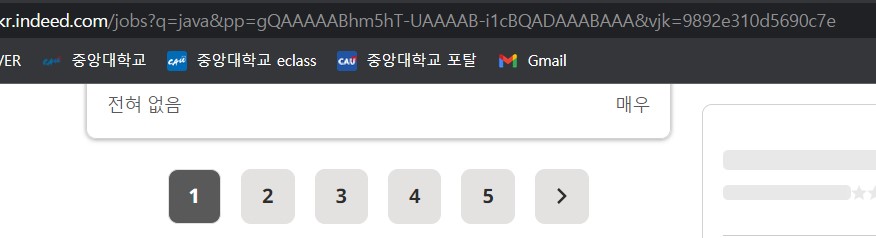
이건 첫번째 페이지를 확인했을때의 http 주소이다.
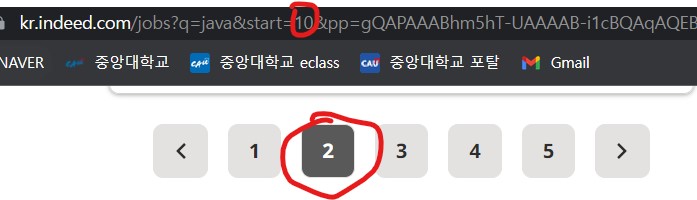
두번째 페이지의 주소이다. 두번째 부터는 10부터 시작해서 페이지당 10씩 늘어나는 규칙이 보이는 것을 확인해 볼 수 있었다.
다만, 첫번째 페이지는 ...start=0&...로 해도 작동하므로 첫번째는 0이라도 해도 무관하다.
그럼 이제 기존 base_url을 수정해서 페이지가 바뀌는 구간을 다시 바꿨는데, 앞에 부분은 base_url로 두고, 뒤에 부분은 page*10으로 해서 0부터 10씩 늘어나도록 하고, 다 합친 url을 final_url이라고 정의했다.
final_url을 불러들여 오는것으로 마무리를 했다.
이렇게되면 페이지마다 스크래핑하는것이 가능하게 된다.
이제 마지막 과정을 시작해 보도록 하겠다.
from extractors.indeed import extract_indeed_jobs
from extractors.wwr import extract_wwr_jobs
keyword = input("What do you want to search for?")
indeed = extract_indeed_jobs(keyword)
wwr = extract_wwr_jobs(keyword)
jobs = indeed + wwr
file = open(f"{keyword}.csv", "w", encoding="utf-8-sig")
file.write("Position,Company,Location,URL\n")
for job in jobs:
file.write(f"{job['position']},{job['company']},{job['location']},{job['link']}\n")
file.close()⦁ 1~4줄
from extractors.indeed import extract_indeed_jobs
from extractors.wwr import extract_wwr_jobs
keyword = input("What do you want to search for?")먼저 main에 있던 indeed 코드를 extractors폴더에 indeed파일을 만들어 넣어주었고, main함수에는 다음과 같은 코드를 적어나갔다.
일전에 만들어 두었던, wwr파일과 indeed파일을 import 해주었다.
그리고 사용자가 직접 주제를 입력할 수 있도록 input을 사용해, keyword를 받아주도록 했다.
⦁ 5~7줄
indeed = extract_indeed_jobs(keyword)
wwr = extract_wwr_jobs(keyword)
jobs = indeed + wwr'+'를 이용해서 indeed와 wwr 함수를 간단하게 합칠 수 있다.
⦁ 9~15줄
file = open(f"{keyword}.csv", "w", encoding="utf-8-sig")
file.write("Position,Company,Location,URL\n")
for job in jobs:
file.write(f"{job['position']},{job['company']},{job['location']},{job['link']}\n")
file.close()먼저 open은 2개의 인수를 요구한다. 하나는 파일이름, 다른 하나는 파일을 여는 방법인 모드(r : 읽기, w : 쓰기, x : 실행, ...)이다.
csv(comma-separated-vakue)는 파일 포맷이다.
마지막은 win10이상 오류가 나지 않게 써주는 코드다.
그래서 '내가 keyword라는 파일을 열건데, 쓰기를 허용한다' 는 의미이다.
file.write는 행을 만드는 작업을 해주어, 행의 주제를 정하기 위해 첫번째에 써주었다.
그래서 Position,Company,Location,URL 을 써주었다.
이제 key를 이용해서 한줄 한줄 채워가는 과정을 반복한다.
마지막으로 file은 open을 했으면 close를 해줘야 한다.
⦁ 실행
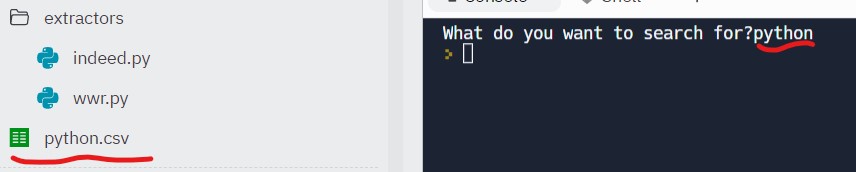
이제 파일을 실행해본다. input이 화면에 나타나면 원하는 검색어를 입력해준다.
그럼 csv파일이 생성되며 스크래핑 내용이 저장된다.
이 파일을 다운로드 받아 실행해보면 excel파일이 열리는데,
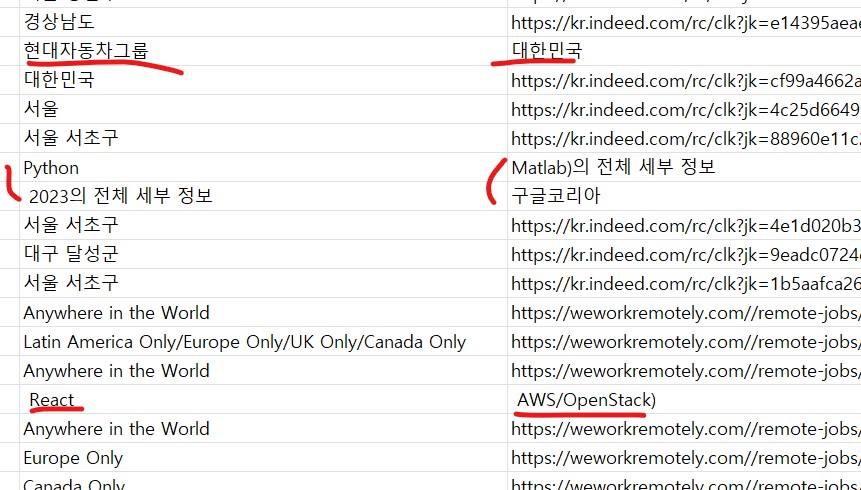
이렇게 열리는 것을 확인해 볼 수 있다.
여기 보이는 부분은 Location과 URL 부분인데, 대부분 실행이 잘 되었찌만, 부분부분 오류가 나는 곳이 있다.
밑줄 친 부분은 Location과 URL에 어긋나는 부분이 생기는데,
csv파일이 띄어쓰기로 칸을 구분하다 보니 그것이 원인으로 생긴 문제다.
이럴 때 해결하는 방법이있다.
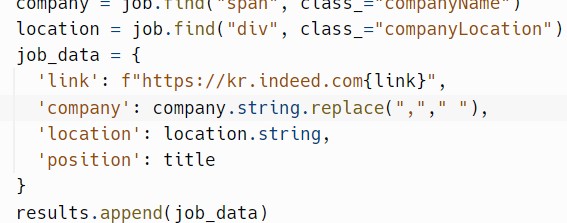
바로 job_data를 수정하는 방법이다.
존재하는 공백들을 쉼표로 치환하여 공백을 없애주는 방법이다.
모든 파일에 적용해준다.
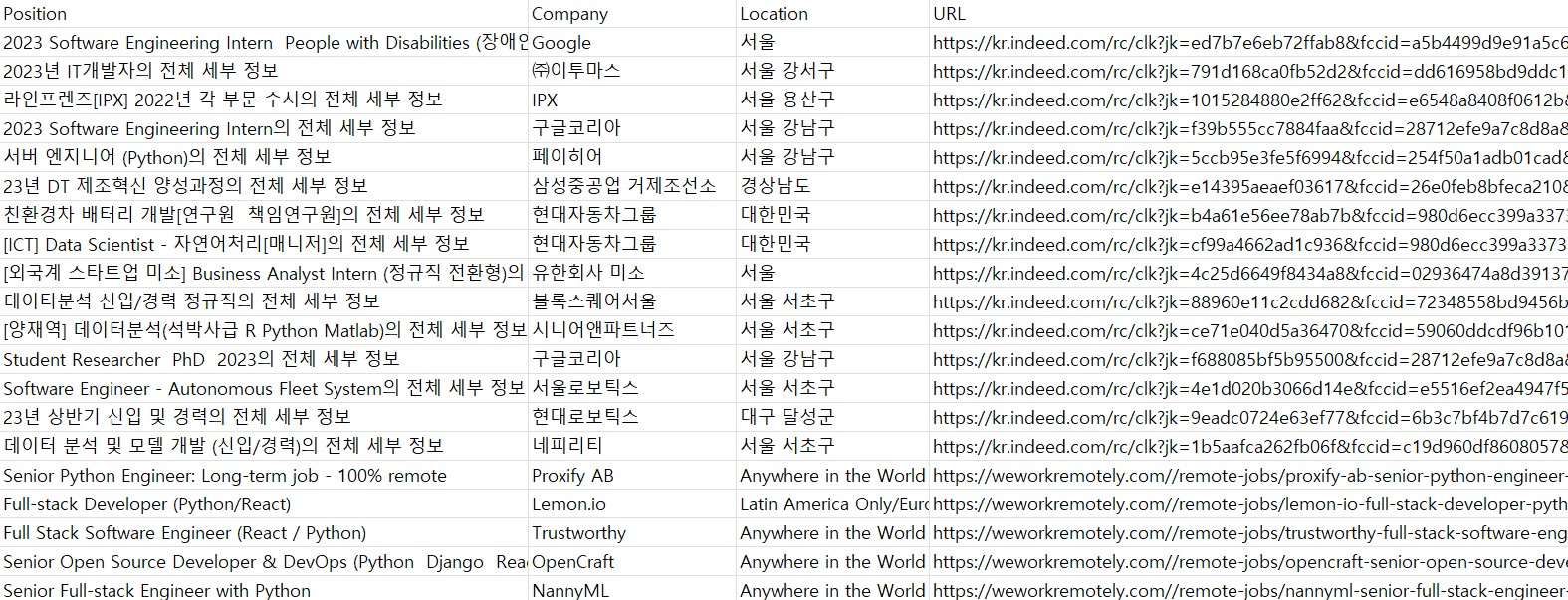
그럼 이와 같이 깔끔한 excel 파일이 만들어 진다.
⦁ 끝
드디어 phython 프로젝트의 마침표를 찍었다.
아직 배운 내용을 토대로 뭔가를 할 지식과 실력은 없지만 일단 끝까지 잘 따라 갔다는게 자랑스럽다. 다음에 시작하게 될 언어로 찾아 오도록 하겠다.
