
해당 자료를 참고하여 강화학습을 공부하고, 중요한 내용에 대해 잠시 점검하려 한다.
강화학습(ReinForcement Learning)이란?
상황(State) 속에서 행위(Action)를 행하여 보상(Reward)를 최대화하고자 하는 메커니즘
*자세한 설명은 자료를 참고하길 바랍니다. :: What is Reinforcement Learning
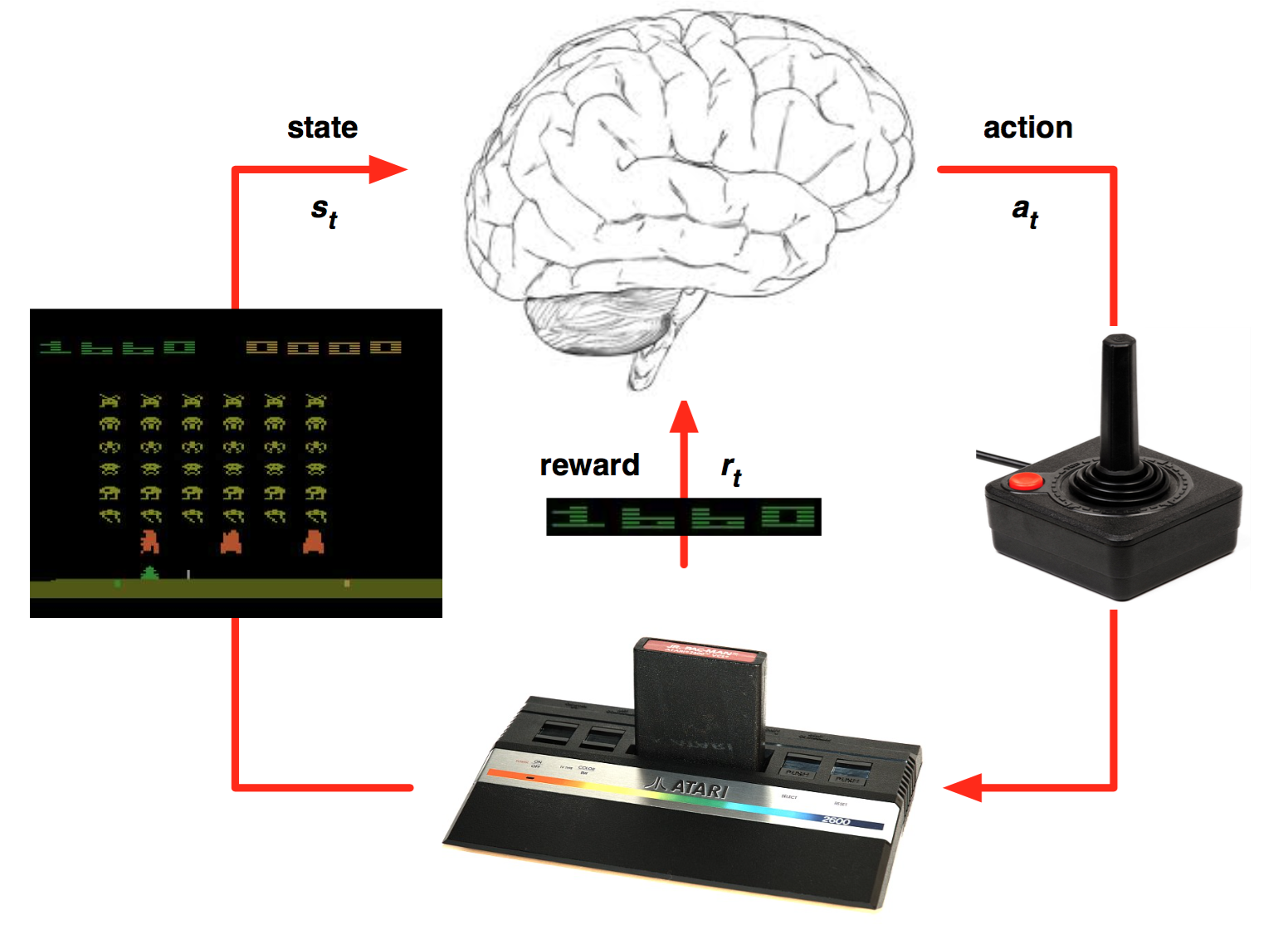
※ ReinForcement Learning Example
해당 그림(논문)에서 주목해야할 점
1. Input Data로 Raw Pixel을 받아와 CNN과 연결했다는 점
2. 같은 Agent로 여러 개의 게임에 적용되어서 학습이 된다는 점
3. Deep neural network를 function approximator로 사용
4. Experience Replay
5. Target networks
DNN을 Approximator로 사용하였다?
Approximation이란 데이터의 숫자가 너무 많아 일일이 저장하여 행동으로 변환하는 방법이 아닌 함수의 형태로 변환하는 방법이라고 한다. 이 때, 요새 Reinforcement Learning이 Approximation을 행하기 위해 사용하는 방법이 Deep Neural Network 이며, 이를 Deep Learning을 통해 강화학습 한다고 칭하는 것이다.
Approximation은 정확히 설명하기에 당장 애매하기 때문에 배워가면서 몸에 익히는 것이 좋은 단어인 것 같다. 나중에 Post로 다룰 기회가 있다면 다뤄보도록 하자.
( https://www.nervanasys.com/demystifying-deep-reinforcement-learning/ )
MDP(Markov Decision Process)
기본적으로 참고한 Gitbook에 자세하고 정확하게 기술되어 있지만, 한 줄 요약 느낌으로다가 한 번 더 정리하였다.
출처 : http://www0.cs.ucl.ac.uk/staff/d.silver/web/Teaching.html

0. MDP(Markov Decision Process)는 Environment에서의 State가 모두 Markov하다는 전제를 따른다.
1. State : Agent(행위자)가 인식하는 자신의 상태
2. Action : Agent(행위자)가 행위하는 것, State를 변화시킴
3. Environment : Agent(행위자)가 처한 환경.
4. Reward : Agent(행위자)가 Action을 취함으로써 Environment에서 얻는 보상
- 거리(얼마나 많이 움직였나?)
- 승률(얼마나 승리에 가깝나?)
5. Discount Factor : 오래된 보상의 가치이 줄어들고 현재와 가까운 보상일수록 가치가 커지는 개념
6. Policy : 어떤 State에서 어떤 Action을 취할 지(확률). 이 때, 강화학습은 Optimal Policy를 찾아내어 보상을 최대화 하고자 함
