1. Optimization
1-1 Program Optimization
- 컴파일러는 최적화를 해줌
- 곱하기 보다 덧셈이 빠르다
- 불필요한 연산 컴파일러가 줄여줌
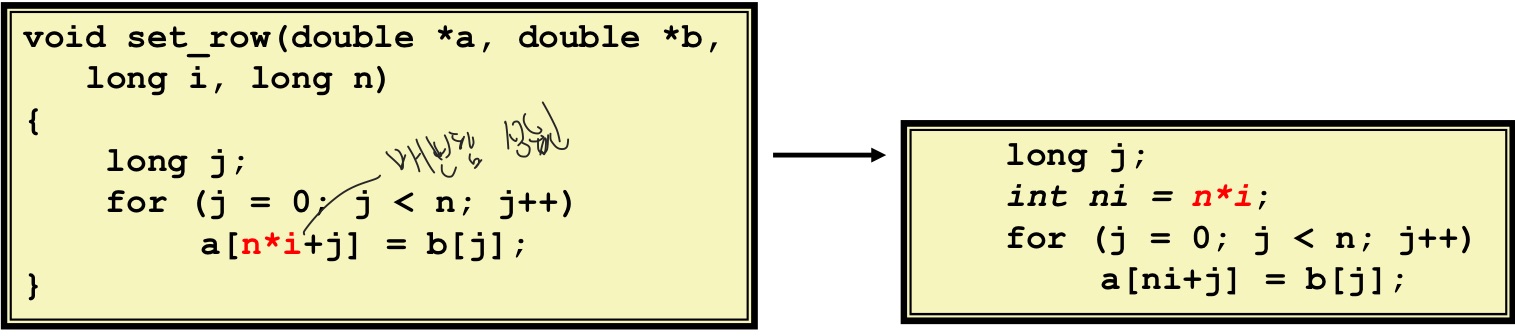
- 빨간색 부분 매번 계산하기 때문에 효율 낮음
- 컴파일러는 오른쪽 그림처럼 되게끔 최적화 작업 수행
- 최적화 단계 0~3 까지 있는데 단계가 높다고 다 빠르지 않음 전부 수행해보며 빠른 것으로 채택
- optimization 높다고 빨라지는 것은 아님 잘못된 판단 있을 수 있고, 옳다 하더라도 코드가 추가 될 수 있다.
1-2 Optimizatoin Blocker
- 컴파일러가 만질 수 없는 부분
- 프로그램의 동작이 달라질 수 있기 때문
- e.g. procedure calls ...


- Output이 달라질 수 있다. 즉 프로그램의 동작에 이상이 생길 수 있기 때문에 strlen을 옮기지 않고 그대로 실행
- 프로그래머가 직접 해당 함수 옮겨야함
1-3 Memory Aliasing
a, b는 포인털써 어떤 메모리의 주소를 각자 가리키고 있을텐데 만약 a, b외에 c라는 다른 포인터가 같은 메모리 공간 가리키고 있을 때의 상황을 의미

- 최적화 불가능
- b[I] += a[I*n + j]; 에서 b[I]에다 a를 더하고 있다. Double b[3] = A + 3; 과 같이 B가 배열 A의 중간 어딘가 부분을 가리키고 있었다고 하자 -> 이것이 memory aliasing, A는 크기가 9인 메모리 공간을 가리키고 있을텐데, B가 A의 한 가운데인 {4, 8 , 16} 쪽을 가리키고 있다.
- 해결방법
- memory aliasing 대신에 val += a[I*n]+j] 처럼 하여 b[I]에다 val 할당
2. Program Optimization 2
2-1 Benchmark
- 어떤 특정 기능의 성능 알고 싶을 때 그 기능에 대해 계속 스트레스를 주입해 성능 파악하는 것
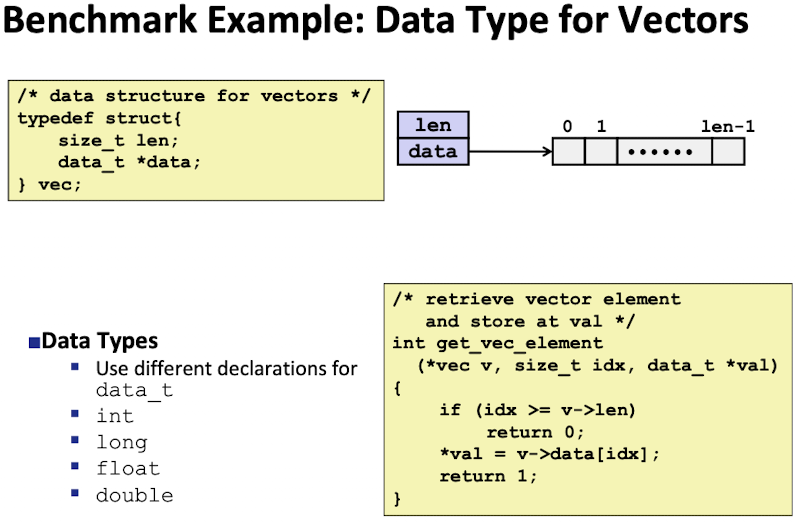
해당 함수는 idx 인덱스에 들어있는 값을 얻어와 val 포인터가 가리키고 있는 메모리에 저장
- daat_t, int, long, float, double 등의 어떤 데이터 타입 할당하는가에 따른 성능 분석하는 benchmark

- v의 Length 만큼 For문을 돌면서 벡터의 각 원소의 값을 가져와서 현재 리턴할 값에다가 덧셈 또는 곱셈을 해준다.
- 초기값이 0이면 덧셈, 1이면 곱셈
- CPE = Cycles per OP = input element 갯수, n = Length
- T = CPE * n + Overhead
- CPE 많아질수록 걸리는 시간 커질텐데, slope가 낮아질수록 직선의 기울기가 낮아서 성능이 더좋은것

- int, double를 부여했을때 덧셈, 곱셈의 수행시간 나타낸 것
- -O1 compile => 옵션 부여 X 시간 / 2
- 더 최적화 하는 방법
- length를 Loop 밖에서 받도록 컴파일러에서 최적화 -> 이 내용을 코드로 다시 작성 후 compile
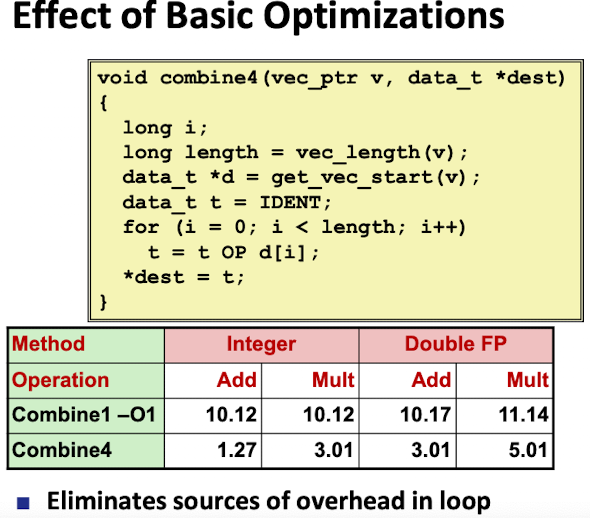
- 직접 code motion 한게 -O1보다 성능 좋음
- 컴파일시 최적화 옵션 준 후 코드 수정된 것을 code motion 통해 수정시 대폭 향상

- Latency Bound : 최소 처리 지연시간(처리하는데 걸리는 시간)
- 연산 속도가 상황에 따라 다를텐데, 아무리 빨라도 이 시간보다 빠를 수 없다
- Int, add가 월등히 빠름

항상 든든하게 코딩 한그릇🧑💻🍚