
원하는 데이터가 정돈된 형태로 주어지는 경우는 많지 않습니다. 원하는 데이터를 얻기 위한 방법으로는 API를 통한 접근, 크롤링, 스크레핑이 있습니다. 오늘은 그 중 스크레핑에 대해 알아보려 합니다.
1. HTML & CSS이란
- 웹의 정보를 스크레핑하기 위해서는 웹의 구조를 먼저 파악해야 합니다.
- 웹의 구조를 파악하기 위해서 웹을 이루고 있는 html과 css에 대해 정리합니다.
1) HTML
- 우리가 보고 있는 웹은 HTML이라는 언어가 시각화된 결과입니다.
- HTML을 이루는 head, body, div, li 등의 요소가 있고, 이 요소를 통해 콘텐츠가 웹에서 어떻게 보여질지 표현할 수 있습니다.

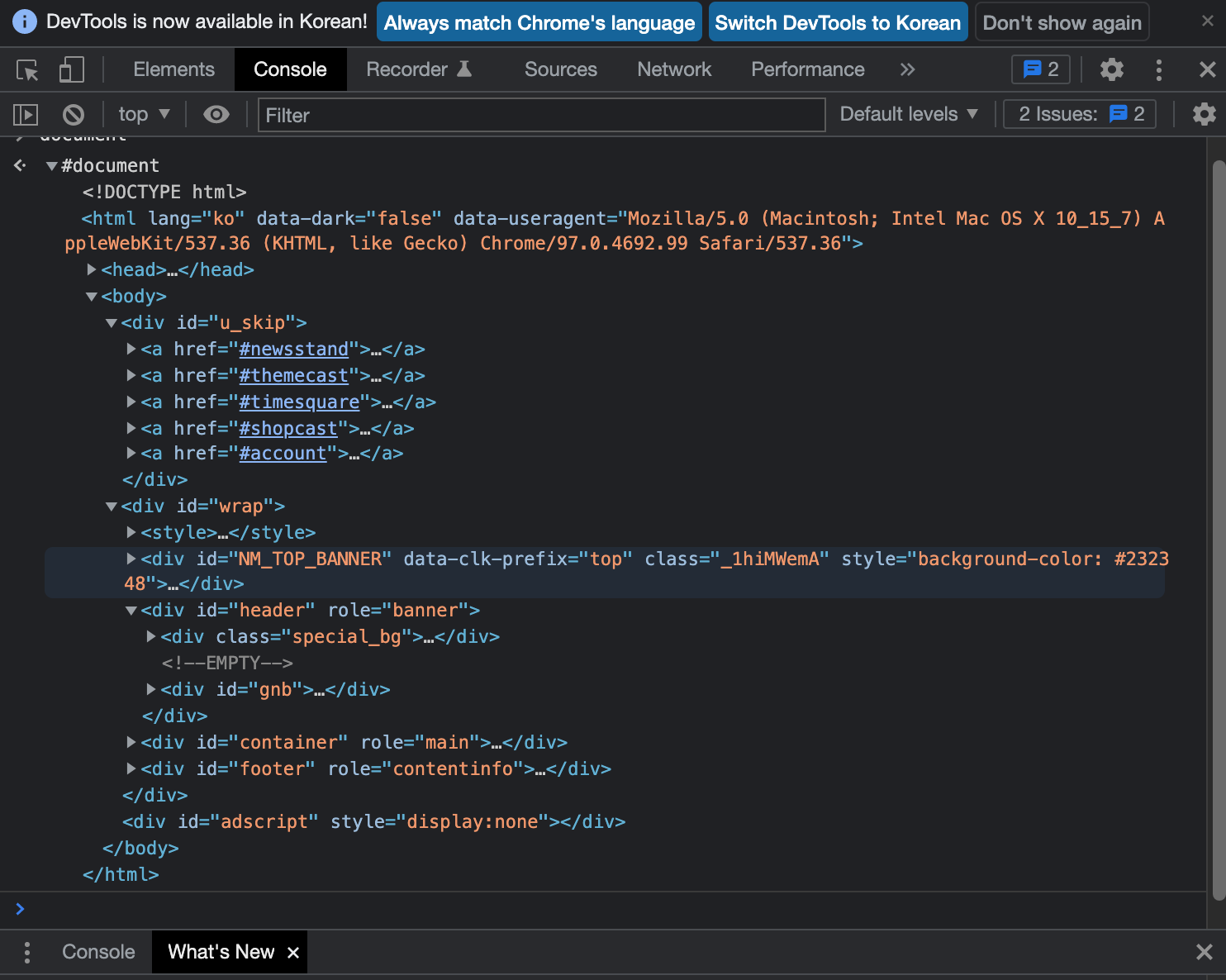
- 각 요소는 태그를 통해 표현되는데요. 위 이미지의
<head></head>가 각각 웹의 메타데이터 정보를 담는 여는 태그와 닫는 태그입니다.
2) CSS
- CSS는 HTML을 꾸미는 스타일시트 언어입니다.
- CSS에는 Selector라는 기능이 있습니다. 간단히 말해 특정 요소를 선택하는 방법입니다. Selector를 사용하는 방법은 크게 세 가지가 있습니다.
- Type Selector : HTML에서 소개한 태그를 선택하는 방법입니다.
- Class Selector : 부여된 클래스에 따라 접근하는 방법입니다.
- Id Selector : 고유의 Id로 접근하는 방법입니다.
- 뒤에 DOM을 소개할텐데, DOM에서 이러한 셀렉터들을 이용해 원하는 요소들을 스크레핑할 수 있습니다.
2. DOM이란
- 웹의 구조를 알아봤으니 이제 이 구조에 접근할 수 있는 인터페이스에 대해 알아보겠습니다.
DOM(The Document Object Model)은 HTML, XML 문서의 구조화된 표현을 제공하며, 프로그래밍 언어가 DOM 구조에 접근할 수 있는 방법을 제공하여 그들이 문서 구조, 스타일, 내용 등을 변경할 수 있게 돕는다.
- 앞서 살펴봤듯이 웹 페이지는 일종의 문서입니다. 그리고 문서는 element로 이루어져 있습니다.
- 우리는 이 element를 통해 문서에 접근할 수 있습니다. DOM은 웹 페이지의 구성요소에 접근할 수 있도록 돕는 일종의 interface입니다.
- 그렇기 때문에 DOM이 없다면 파이썬이나 자바스크립트 언어는 웹 페이지 또는 XML 페이지 및 요소들과 관련된 모델이나 개념들에 접근하지 못합니다.
- 엄밀히 말해 접근은 할 수 있지만, 구조화되어 있지 않은 정보 속에서 원하는 정보를 찾는데 어려움을 겪을 것입니다.
- DOM은 각자 사용하는 브라우저에서 접근할 수 있습니다.
- 모든 웹 브라우저는 스크립트가 접근할 수 있는 웹 페이지를 만들기 위해 DOM을 사용합니다.
- 위의 DOM에서 태그와 클래스를 통해 원하는 정보로 접근할 수 있습니다.
2. Scrapping
- DOM이라는 인터페이스를 거쳐 원하는 정보에 접근할 수 있다는 것을 알았습니다.
- 예제를 통해 스크레핑 과정을 소개하겠습니다.

- 네이버 뉴스의 헤드라인을 스크레핑해보겠습니다.
import requests
import sqlite3
from bs4 import BeautifulSoup
URL ='https://media.naver.com/press/028'
resp = requests.get(URL)
soup = BeautifulSoup(resp.content, 'html.parser')
- requests로 원하는 페이지의 콘텐츠를 get하면 스트링 형태의 데이터를 얻게 됩니다.
- 스트링 형태의 데이터를 우리가 접근할 수 있는 xml, json 등의 형식으로 바꿔주는 것을 파싱이라고 합니다. beautifulsoup으로 html 데이터를 파싱했습니다.
- 이 결과에서 우리가 원하는 헤드라인을 찾아야 합니다.
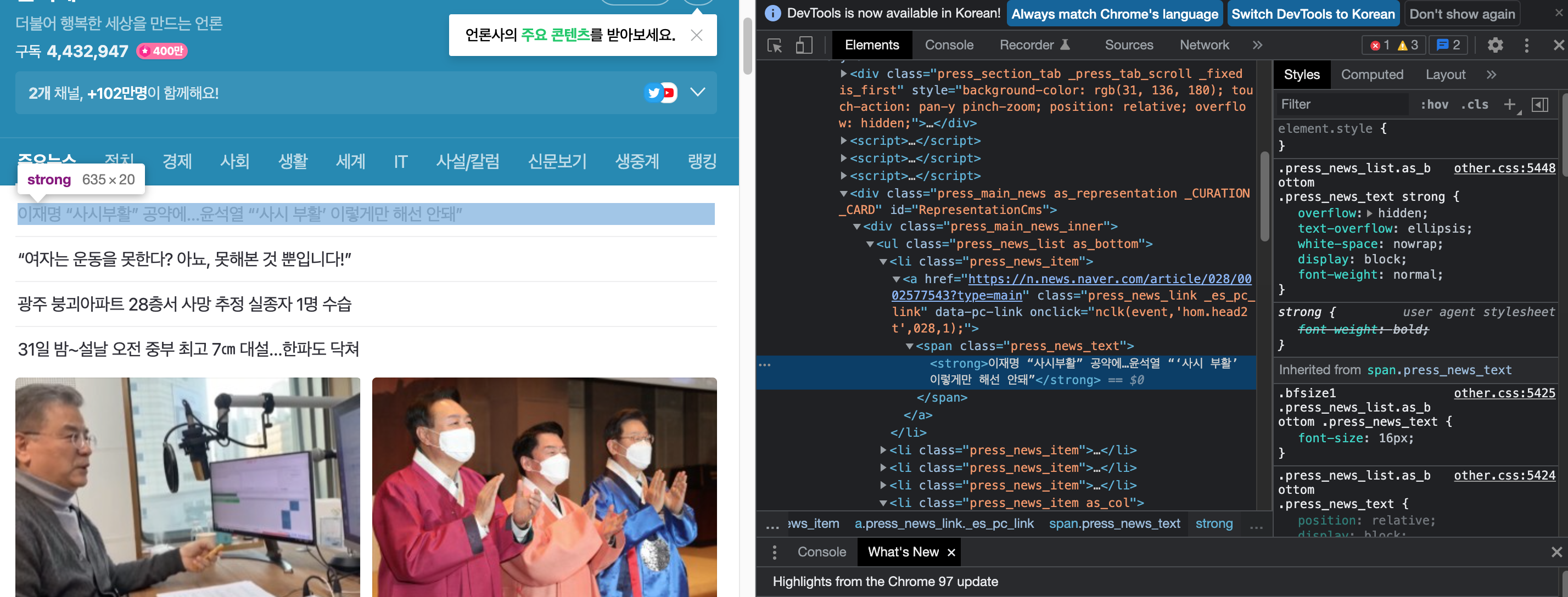
- DOM을 통해 헤드라인의 html elements를 찾아보겠습니다.
- 'span'라는 태그에 'press_news_text'라는 클래스를 가지고 있네요.
head_line = soup.find("span", class_ = 'press_news_text').text
print(head_line)- 파싱한 데이터에서 text만 뽑아내고 싶다면
.text를 사용합니다. find_all을 사용하면 같은 태그와 클래스를 가진 데이터를 모두 뽑아낼 수 있습니다. 다만find_all은.text메소드를 사용할 수 없으므로, for 문을 사용해서 데이터를 하나씩 분리해야 합니다.
head_line = soup.find_all("span", class_ = 'press_news_text')
head_line_list = [x.text for x in head_line]- 지금까지 정리한 스크레핑은 정적 스크레핑이라고도 부릅니다.
- java script의 기능으로 접근할 수 있는 웹 페이지의 경우에는 정적 스크레핑이 작동하지 않습니다. 예를 들어 페이지를 내려야 새로운 콘텐츠가 보이는 웹페이지에서는 정적 스크레핑으로는 아직 나타나지 않은 콘텐츠까지 스크레핑할 수 없습니다.
다음 포스팅에서는 스크레핑한 데이터를 DB에 저장하는 과정을 정리하도록 하겠습니다.

-