
1. Permutaion Importance
- Feature Importances는 각각의 특성이 모든 트리에 대해 어느정도 불순도를 감소시키는지 평균을 계산한 값입니다(mean decrease impurity).
- 문제는 class가 많은 특성은 분기 기회가 많기 때문에 불순도를 감소시킬 기회가 많고, 평균 불순도 감소에서 쉽게 이득을 봅니다.
- 관심 특성을 drop해서 성능평가지표(정확도, F1, R2)가 얼마나 감소하는지 측정하는 방식으로 특정 특성의 중요도를 가늠하는 방법도 있습니다. 다만, drop할 때마다 다시 fitting 해야하기 때문에 시간이 너무 오래걸린다는 단점이 있습니다.
- 순열 중요도는 앞서 언급한 Featrue Importances와 Drop-Column 중요도 중간에 위치하는 특징을 가지고 있습니다.
- 순열 중요도는 관심있는 특성에만 무작위로 노이즈를 주고 예측했을 때 성능평가지표가 얼마나 감소하는지를 측정합니다.
- Drop column 중요도를 계산하기 위해 재학습을 해야 했다면, 순열중요도는 검증 데이터에서 각 특성을 제거하지 않고 특성값에 무작위로 노이즈를 주어 기존 정보를 제거하여 특성이 기존에 하던 역할을 하지 못하게 하는 방식으로 성능을 측정합니다.
- 이때 노이즈를 주는 가장 간단한 방법은 그 특성값들을 샘플 내에서 섞는 것입니다.
import eli5
from eli5.sklearn import PermutationImportance
# permuter 정의
permuter = PermutationImportance(pipe.named_steps['rf'],# model
scoring='accuracy', # metric
n_iter=5, # 다른 random seed를 사용하여 5번 반복
random_state=2)
# 실제로 fit 의미보다는 스코어를 다시 계산하는 작업입니다
permuter.fit(X_val, y_val);
feature_names = X_val.columns.tolist()
pd.Series(permuter.feature_importances_, feature_names).sort_values()2. PDP
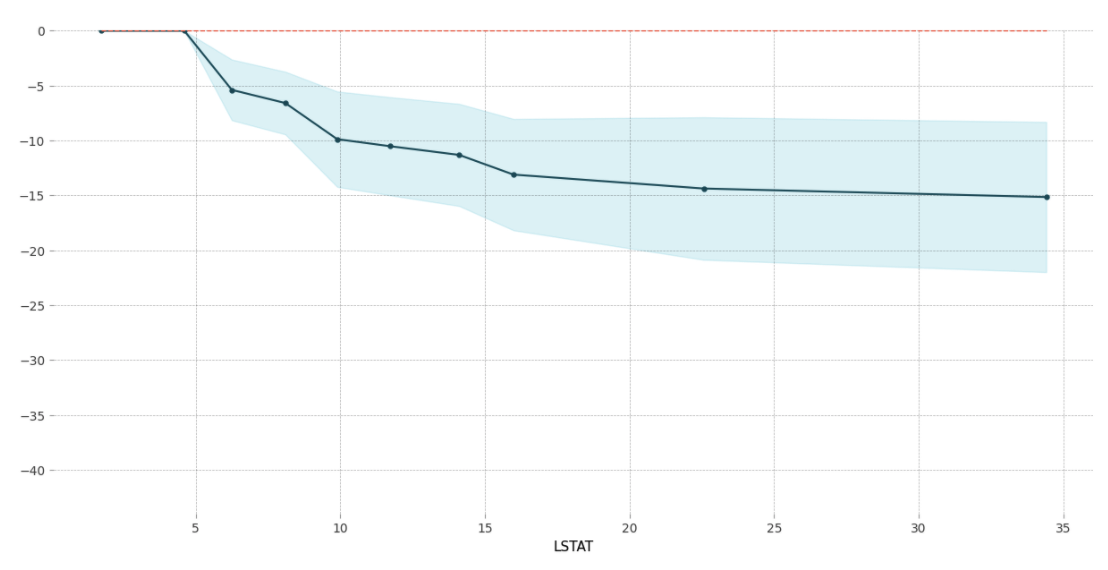
- PDP는 관심 있는 특성들이 타겟에 어떤 영향을 주는지 보여주는 시각화 알고리즘입니다.
- 특정 특성의 global한 영향력을 볼 수 있습니다.
- 위 그래프를 예로 들어 설명하면, "LSTAT" 0~5일 때 target값 예측에 변화가 없지만, 5 이후부터는 "LSTAT"가 증가함에 따라 target 예측값이 감소합니다.
- 특성 간에 공분산성이 없음을 전제하고 있습니다. 해석에 주의를 요하는 부분입니다.
from pdpbox.pdp import pdp_isolate, pdp_plot
from sklearn.metrics import r2_score
feature_list = ['LSTAT' , 'B', 'TAX', 'CRIM']
for i in feature_list:
isolated = pdp_isolate(
model=model,
dataset=X_test,
model_features = X_test.columns,
feature = i)
pdp_plot(isolated, feature_name=i);- 두 개의 특성을 하나의 그래프로 시각화할 수도 있습니다.
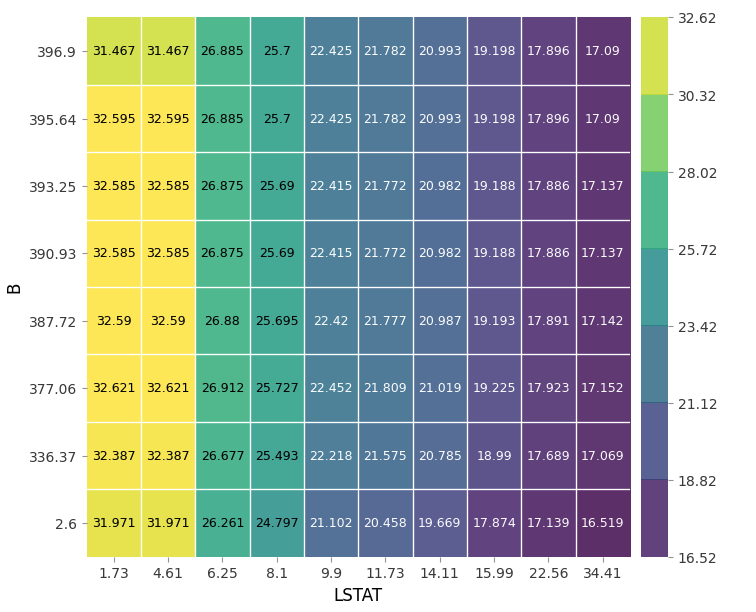
- 두 특성의 관계를 히트맵 방식으로 구현했습니다.
- 작은 사각형 안의 숫자가 타겟값입니다. 분류 문제에서는 확률로 나타납니다.
from pdpbox.pdp import pdp_interact, pdp_interact_plot
feature_list = ['LSTAT' , 'B']
interaction = pdp_interact(
model=model,
dataset=X_test,
model_features=X_test.columns,
features=feature_list
)
pdp_interact_plot(interaction, plot_type='grid',
feature_names=feature_list);
- PDP를 사용할 때 주의할 점은 해석하려는 모델이 pipe로 묶여 있으면 안된다는 점입니다. 기술적인 문제인지 pipe 안의 모델을 해석하지 못하는 것 같습니다. 전처리 pipe와 학습 모델을 따로 만들어서 PDP에 적합해야 합니다.
3. SHAP
- 관심 특성이 단일 관측치 차원에서 어떤 기여를 하는지 확인하는 시각화 알고리즘입니다.

- 위 그래프는 분류 문제에 관한 시각화 결과입니다. 0.48이라는 확률이 어떤 특성의 기여로 산출됐는지 보여줍니다. Violations과 Risk(high)가 해당 샘플의 위생검사 Fail 확률을 높였으나, 결과적으로 Inspection Type(canvass)과 Facility Type(restaurant)가 해당 샘플이 위생검사에 통과하는데 큰 기여를 했습니다.
import shap
explainer = shap.TreeExplainer(model)
row_processed = processor.transform(row)
shap_values = explainer.shap_values(row_processed)
shap.initjs()
shap.force_plot(
base_value=explainer.expected_value[1],
shap_values=shap_values[1],
features=row
)- PDP와 마찬가지로 학습 모델을 pipe로 묶으면 SHAP가 모델을 인식하지 못합니다.
- N개의 샘플을 뽑아서 N개의 샘플에 각 특성이 어떤 영향을 미쳤는지 확인하는 방법도 있습니다.
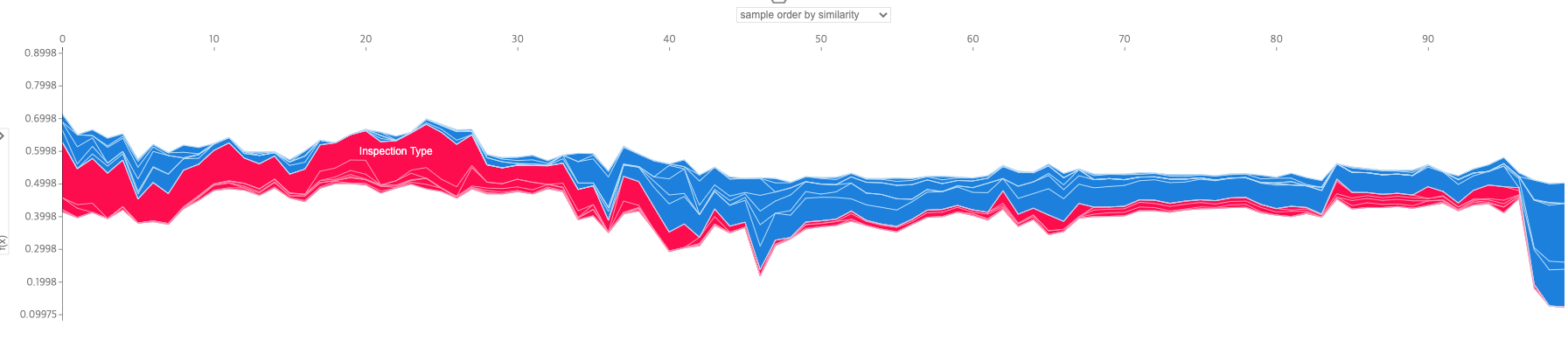
- 65%의 확률로 양성으로 판별된 32번째 샘플의 경우 검사 유형과 시설 유형, 경도가 검사 결과에 가장 큰 기여를 했습니다.
- 35%의 확률로 음성으로 예측된 65번째 샘플의 경우에도 검사 유형과 시설 유형이 큰 영향을 미쳤으며, Risk 타입도 검사 결과에 기여했습니다. 특성이 y축에서 차지하는 범위가 특성의 영향력입니다. 빨간색은 양성 확률을 높이는 특성이고, 파란색은 음성 확률을 높이는 특성입니다.
- 아래는 시각화 구현 코드입니다.
sample = X_test.iloc[:100]
explainer = shap.TreeExplainer(model)
sample_processed = processor.transform(sample)
shap_values = explainer.shap_values(sample_processed)
shap.initjs()
shap.force_plot(
base_value=explainer.expected_value[1],
shap_values=shap_values[1],
features=X_test
)

-