좋은 아키텍처
- 좋은 아키텍처를 만드는 일은 객체 지향(Object-Oriented) 설계 원칙을 이해하고 응용하는 데서 출발한다.
객체지향이란?
(1) 데이터와 함수의 조합
- 1966년 객체지향이 발명되기 이전부터 프로그래머는 데이터 구조를 함수에 전달해 왔다. → 만족스러운 대답이 아님.
(2) 실제 세계를 모델링 하는 새로운 방법
- 의미조차도 불분명하며, 정의가 너무 모호함. → 객체지향이 무엇인지를 설명해주지 못한다.
(3) 캡슐화, 상속, 다형석
- 그나마 접근 가능한 방식이다.
캡슐화
객체지향에서 오히려 캡슐화가 훼손되었다!
- 캡슐화를 통해 데이터와 함수가 응집력 있게 구성된 집단을 서로 구분 짓는 선을 그을 수 있다.
- 구분선 바깥에서 데이터는 은닉되고, 일부 함수만이 외부에 노출된다.
- 이 개념들이 실제 객체지향 언어에서는 각각 클래스의 private 멤버 데이터와 public 멤버 함수로 표현된다.
- 그러나 캡슐화는 오히려 C 언어에서 완벽히 가능하다.
- 오히려 C++ 부터 완전한 캡슐화가 깨지게 됨.
- C++ 컴파일러는 클래스의 인스턴스 크기를 알 수 있어야 하므로 클래스의 멤버 변수를 해당 클래스의 헤더 파일에 선언할 것을 요구했다.
- 헤더 파일을 사용하는 측에서는 멤버 변수를 알게 되어 캡슐화가 깨져버린다.
- 언어에 private, public, protected 키워드를 도입함으로써 어느정도 보완하긴 했지만 이는 컴파일러가 헤더 파일에서 멤버 변수를 볼 수 있어야 했기 때문에 조치한 임시방편일 뿐이다. -
- 자바와 C#은 헤더와 구현체를 분리하는 방식을 모두 버렸고, 이로 인해 캡슐화는 더욱 심하게 훼손되었다.
상속
캡슐화 보단 낫지만, 여전히 부족한 설명이다.
- 상속만큼은 객체지향 언어가 확실히 제공했다.
- 하지만 상속이란 단순히 어떤 변수와 함수를 하나의 유효 범위로 묶어서 재정의하는 일에 불과하다.
- 이러한 기능은 객체지향 이전에도 C프로그래머는 언어의 도움 없이 구현할 수 있었다.
- 그렇지만 이는 상속을 흉내 내는 정도였지, 사실상 상속만큼 편리한 방식은 절대 아니다.
- 게다가 다중 상속을 구현하기란 훨씬 더 어려운 일이었다.
- 객체지향은 상속을 통해 이러한 기능을 편리하게 구현할 수 있도록 제공해주었다.
다형성
- 객체지향이 다형성을 새롭게 만든 것은 전혀 없다.
- 1940년대 후반 폰 노이만 아키텍처가 처음 구현된 이후 프로그래머는 다형적 행위를 수행하기 위해 함수를 가리키는 포인터를 사용해왔다.
- 그러나 객체 지향 언어가 다형성을 제공하지는 못했지만, 다형성을 좀 더 안전하고 더욱 편리하게 사용할 수 있게 해준다.
- 함수에 대한 포인터를 직접 사용하여 다형적 행위를 만드는 이 방식은 위험하다.
-
포인터를 초기화하는 관례를 준수해야 한다는 사실을 기억해야 하며,
-
이들 포인터를 통해 모든 함수를 호출하는 관례를 지켜야 한다는 점도 기억해야 한다.
-
지키지 않으면 버그가 발생하고, 이러한 버그는 찾아내고 없애기가 매우 어렵다.
→ 객체지향 언어는 이러한 관례를 없애주며, 실수할 위험을 없애준다. 객체지향 언어를 사용하면 다형성은 매우 쉽게 처리된다.
이러한 이유로 객체지향 언어는 제어흐름을 간접적으로 전환하는 규칙을 부과한다고 결론지을 수 있다.
-
다형성이 가진 힘
의존성 역전
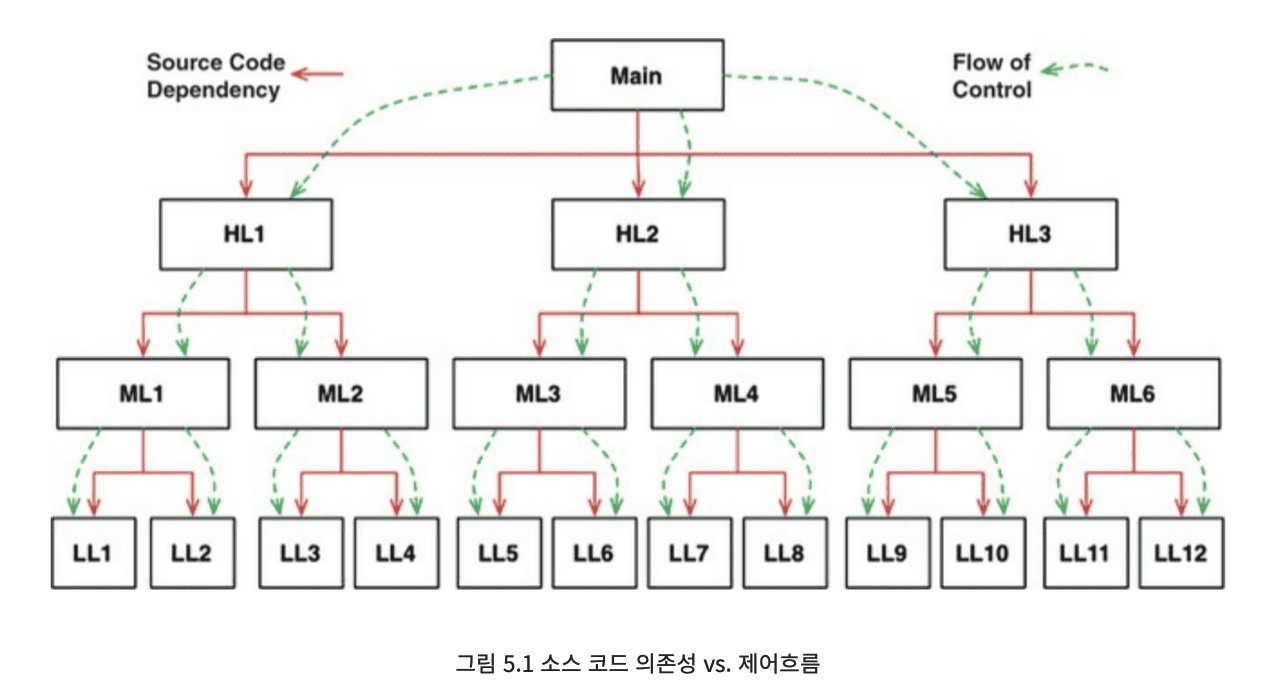
- 다형성을 안전하고 편리하게 적용할 수 있는 메커니즘이 등장하기 전 소프트웨어의 모습이다.
- main함수가 고수준 함수를 호출하고, 고수준 함수는 다시 중간 수준 함수를 호출하며, 중간 수준 함수는 다시 저수준 함수를 호출한다.
- 이러한 호출 트리에서 소스 코드 의존성의 방향은 반드시 '제어흐름(flow of control)'을 따르게 된다.
- 모든 호출 함수는 피호출 함수가 포함된 모듈의 이름을 명시적으로 지정해야 한다.
- 제어흐름은 시스템의 행위에 따라 결정되며, 소스 코드 의존성은 제어흐름에 따라 결정된다.
-
다형성을 적용해보자.
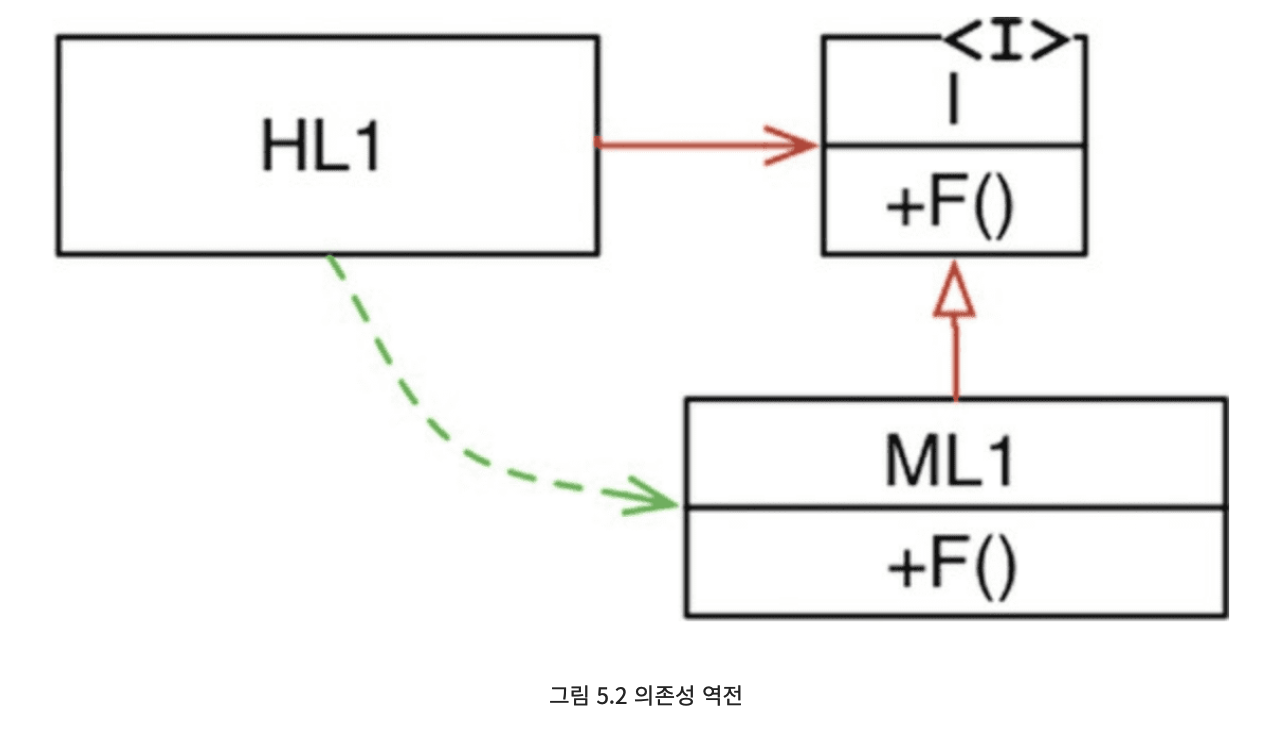
- HL1 모듈은 ML1 모듈의 F() 함수를 호출한다. 소스 코드에서는 HL1 모듈은 인터페이스를 통해 F() 함수를 호출한다. 이 인터페이스는 런타임에는 존재하지 않는다. HL1은 단순히 ML1 모듈의 함수 F()를 호출할 분이다.
- 하지만 ML1과 I 인터페이스 사이의 소스 코드 의존성(상속 관계)이 제어흐름과는 반대인 점을 주목. 이는 '의존성 역전(dependency inversion)이라고 부르며, 소프트웨어 아키텍트 관점에서 이러한 현상은 심오한 의미를 갖는다.
-
객체지향 언어가 다형성을 안전하고 편리하게 제공한다는 사실은 소스 코드 의존성을 어디에서든 역전시킬 수 있다는 뜻이다.
-
이러한 접근법을 사용한다면, 객체지향 언어로 개발된 시스템을 다루는 소프트웨어 아키텍트는 시스템의 소스코드 의존성 전부에 대해 방향을 결정할 수 있는 절대적인 권한을 갖는다.
-
즉, 소스코드 의존성이 제어흐름의 방향과 일치되도록 제한되지 않는다. 호출하는 모듈이든 아니면 호출 받는 모듈이든 관계없이 소프트웨어 아키텍트는 소스 코드 의존성을 원하는 방향으로 설정할 수 있다.
-
이것이 다형성의 힘이고, 객체지향이 제공하는 힘이다!
-
또한 객체지향이 지향하는 것이다!

-
-
다형성으로 생기는 변화
- 배포 독립성(independent deployability)
- 각 컴포넌트는 개별적이며 독립적으로 배포 가능해진다.
- 업무규칙이 데이터베이스와 사용자 인터페이스(UI)에 의존하는 대신에, 시스템의 소스 코드 의존성을 반대로 배치하여 데이터베이스와 UI가 업무 규칙에 의존하도록 만들 수 있다.
- UI와 데이터베이스가 업무 규칙의 플러그인이 된다.
- 업무 규칙의 소스 코드에서는 UI나 데이터 베이스를 호출하지 않는다.
- 업무 규칙, UI, 데이터베이스는 세 가지로 분리된 컴포넌트 또는 배포 가능한 단위로 컴파일 할 수 있고, 이 배포 단위들의 의존성 역시 소스 코드 사이의 의존성과 같다.
- 따라서 업무 규칙을 포함하는 컴포넌트는 UI와 데이터베이스를 포함하는 컴포넌트 사이에 의존하지 않는다.
- 또한 업무 규칙을 UI와 데이터베이스와는 독립적으로 배포할 수 있다.
- UI나 데이터베이스에서 발생한 변경사항은 업무 규칙에 일절 영향을 미치지 않는다.
- 각 컴포넌트는 개별적이며 독립적으로 배포 가능해진다.
- 개발 독립성(independent developability)
- 시스템의 모듈을 독립적으로 배포할 수 있게 되면, 서로 다른 팀에서 각 모듈을 독립적으로 개발할 수 있다.
- 배포 독립성(independent deployability)
결론
- 객체지향이란 다형성을 이용하여 전체 시스템의 모든 소스 코드 의존성에 대한 절대적인 제어 권한을 획득할 수 있는 능력이다.
- 객체지향을 사용하면 아키텍트는 플러그인 아키텍처를 구성할 수 있고, 이를 통해 고수준의 정책을 포함하는 모듈은 저수준의 세부사항을 포함하는 모듈에 대해 독립성을 보장할 수 있다.
- 저수준의 세부사항은 중요도가 낮은 플러그인 모듈로 만들 수 있고, 고수준의 정책을 포함하는 모듈과는 독립적으로 개발하고 배포할 수 있다.

하루하루 꾸준히