MachineLearning
1.머신러닝(Machine Learning)이란 무엇인가?
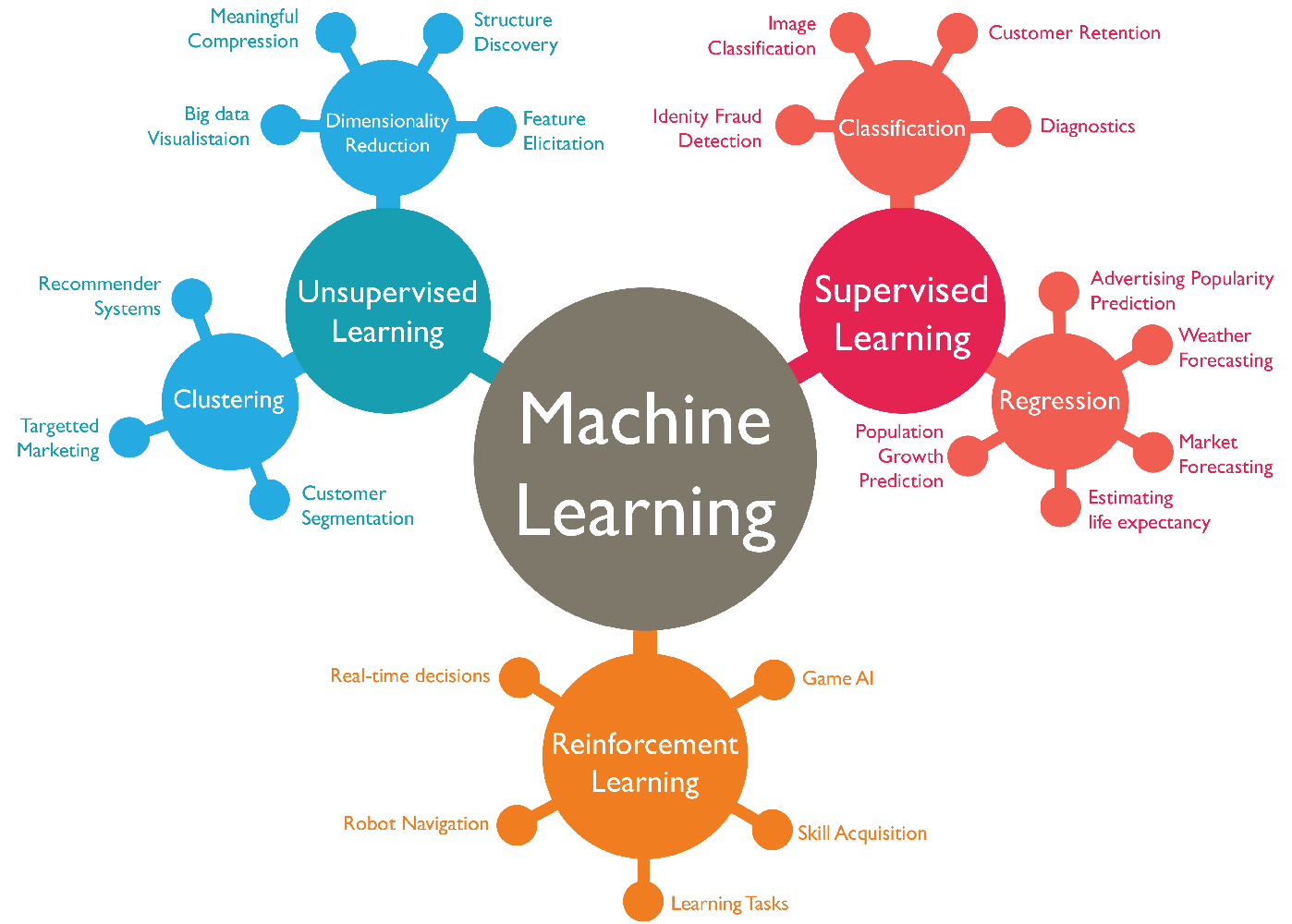
머신러닝 종류지도 학습 (Supervised Learning) \-비지도 학습 (Unsupervised Learning)강화 학습 (Reinforcement Learning)
2.머신러닝의 과정(Workflow) 정리

머신러닝 프로젝트는 단순히 모델을 학습시키는 것만으로 끝나지 않습니다.실제 현업이나 대회, 연구 등에서 머신러닝을 적용할 때는 여러 단계를 체계적으로 거쳐야 좋은 결과를 얻을 수 있습니다.이번 글에서는 머신러닝의 전형적인 전체 과정을 단계별로 자세히 설명합니다.무엇을
3.머신러닝 학습 3가지 종류
머신러닝은 데이터의 형태와 학습 방식에 따라 크게 지도학습, 비지도학습, 강화학습으로 나눌 수 있습니다.정답(label)이 있는 데이터로 학습입력 데이터와 그에 대응하는 정답(출력)이 쌍으로 주어짐입력과 정답(출력)이 모두 주어진 상태에서 학습모델이 정답을 맞추는 방향
4.머신러닝 평가지표
분류 문제는 정답이 카테고리(범주형)인 경우에 사용합니다.전체 데이터 중에서 정답을 맞춘 비율공식:Accuracy = (TP + TN) / (TP + TN + FP + FN)해석:전체 예측 중에서 맞춘 비율이므로, 데이터가 불균형할 때는 신뢰하기 어려움분류 결과를 표로
5.머신러닝 손실함수(오차값)
머신러닝에서 모델을 학습시킬 때, 예측값과 실제값의 차이를 수치로 계산하는 함수가 바로 손실함수(Loss Function, Cost Function)입니다.손실함수는 문제 유형(회귀/분류)에 따라 다르게 사용되며, 모델의 성능을 높이기 위해 반드시 이해해야 할 핵심 개
6.머신러닝 개념 추가 정리
머신러닝을 실무에서 제대로 활용하려면, 단순히 모델을 만드는 것뿐만 아니라 데이터 전처리, 모델 평가, 하이퍼파라미터 튜닝 등 다양한 개념을 이해해야 합니다.아래에서 추가 개념들을 정리합니다.데이터를 여러 개의 폴드(fold)로 나누어, 학습과 검증을 반복하는 방법과적