파이썬의 객체에는 mutable한 객체와 immutable한 객체가 있다. 용어를 잠시 살펴보면 다음과 같다.
- mutable : 변할 수 있는
- immutable : 변할 수 없는
그리고 검색을 하다보면 mutable은 call by reference로 동작하고 immutalbe은 call by value로 동작한다고 설명한 글들이 많은데, 파이썬의 변수를 이 두 가지 개념으로 설명하는 것은 적절하지 않다고 느껴졌다.
더구나 파이썬이 객체로 동작한다는 사실을 모르고 위 용어를 통해 변수에 대한 개념을 이해하려다보면 굉장히 혼란 스러운 요소가 많아진다. 깊게는 아닐질도 C나 C++에서 ref, pointer, call by value, call by reference 등을 접했다면 더 헷갈린다.
파이썬 공식문서나 파이썬의 내부구조를 깊게 이해해서 글을 작성하는 것은 아니지만, 쉽게 이해하고 헷갈리지 않도록 정리를 해보려 한다.
C, C++ 변수 선언
C언어에서는 변수를 선언하기 위해서 변수의 type과 변수명이 필요하다.
변수를 선언만 할 수도 있고 값을 넣으면서 초기화를 할 수도 있다.
int a;
int a = 100;이때 변수가 선언되는 방식을 간단하게 살펴보면, a라는 바구니에 어떤 특정 값을 담는 방식인 것이다. 그리고 변수라는 각 바구니는 주소를 가지고 있고 값을 그 바구니에 담아두는 구조이다. 우리는 주소값을 통해 변수의 값에 접근한다. 초기화를 한다면 초기화한 그 값이 담기고 전역 변수라면 0 값이, 지역 변수라면 쓰레기 값이 담겨있게 된다.
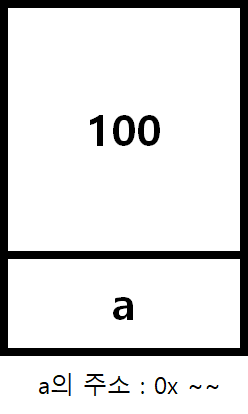
C, C++ 변수 값 복사
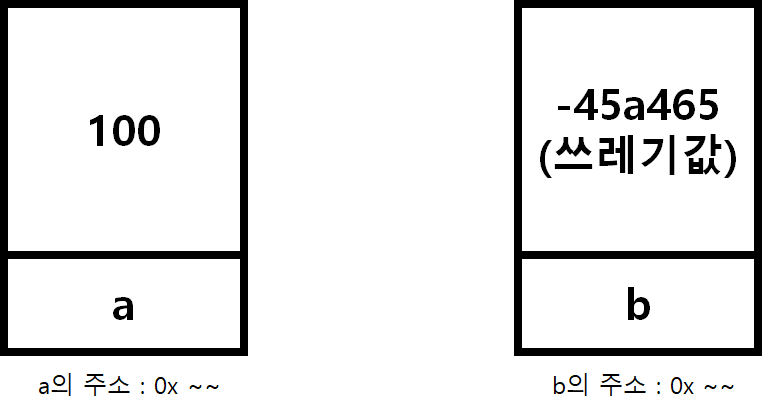
int a = 100;
int b; // 그냥 선언만위와 같이 우리가 두 변수를 선언한다고 하면 우리는 아래의 그림 처럼 두 바구니를 가지게 되는 것이다.
그리고 아래의 코드와 같이 = 을 통해 대입 연산을 하게 되면 b에는 a의 값인 100이 들어가게 된다.
- 대입 연산
b = a;- 선언과 동시에 초기화
int b = a;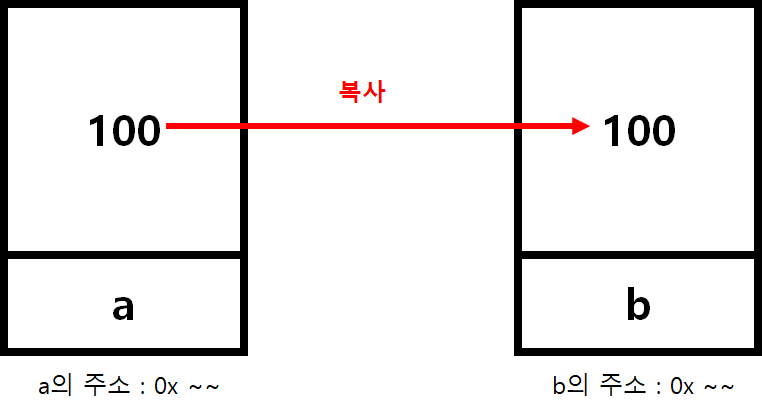
맨 처음 배우는 기본 변수들을 통해서는 원본데이터를 건드린다거나 하지 않는다. 기본적으로는 이런 방식으로 동작하는 원리 때문에 함수의 호출에서 call by value를 통해 전달하면, 원본 데이터에 접근을 하지 못하기 때문에 우리는 포인터나 참조 변수를 이용하게 된다.
int main()
{
int a = 100;
int b = a;
int& ref = a; // 참조변수는 선언과 동시에 초기화를 해줘야 한다.
int* ptr = &a;
cout << "a의 주소 입니다 : " << &a<<'\n';
cout << "b의 주소 입니다 : " << &b<<'\n';
cout << "a의 값 입니다 : " << a<<'\n';
cout << "b의 값 입니다 : " << b<<'\n';
cout << "ref의 주소 입니다 :" <<&ref<< '\n';
cout << "ref의 값 입니다 : " << ref << '\n';
cout << "ptr의 주소 입니다 : " << &ptr << '\n';
cout << "ptr의 값 입니다 : " << ptr << '\n';
cout << "ptr이 가리키는 값 입니다 : " << *ptr << '\n';
return 0;
}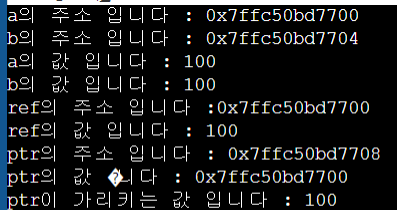
여기서 참조형을 제외하고는 모든 변수들이 선언을 하게 되면 자신만의 고유한 영역(바구니)이 생긴다고 생각하면 된다. (참조형은 내부적으로는 포인터와 같은 방식으로 동작한다)
파이썬의 변수 선언 방식
파이썬의 변수는 조금 다른 방식으로 동작한다. 위 개념을 잊고 객체 방식으로 동작한다는 것을 이해해야 한다. 객체 방식으로 동작한다는 개념을 아래의 코드로 이해해보자
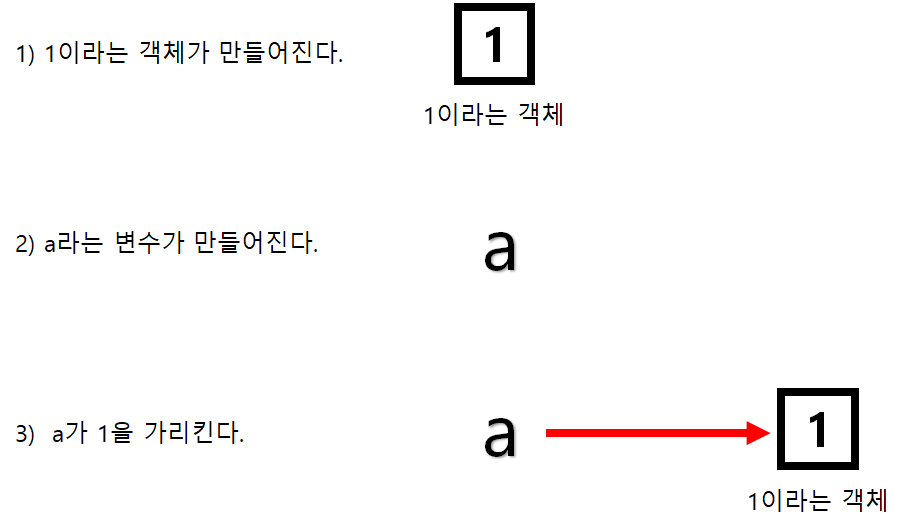
a = 1파이썬은 변수의 타입을 지정해줄 필요가 없기 때문에 위와 같은 코드로 변수를 선언할 수 있다.
그렇다면 이 변수는 어떻게 만들어지는걸까? 1이라는 객체가 만들어 지고 그 1을 a가 가리키고 있는 것 이다.
다시 객체라는 키워드를 떠올리면서 아래의 과정을 이해해보자
(정확한 설명은 아니고 이해를 돕기 위한 쉬운 설명이라고 보면 되겠다.)
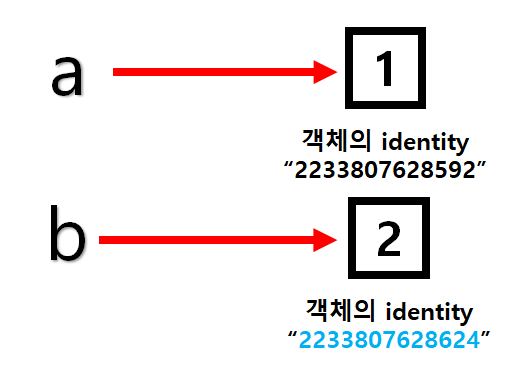
이제 b = a라는 대입 연산을 해보자. 그리고 주소를 return하는 id함수를 통해 각 주소(?)를 출력해보자
a = 1
b = a
print(id(a))
print(id(b))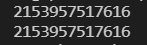
결과를 보면 같은 값이 나오는 것을 알 수 있다. id()함수로 주소(?)을 출력해보자고 했는데 id는 정확히 주소를 출력하는 함수가 아니다.
python 공식문서를 살펴보면 id는 객체의 유일한 identity를 리턴한다고 설명되어 있다.
id(object)
Return the “identity” of an object. This is an integer which is guaranteed to be unique and constant for this object during its lifetime. Two objects with non-overlapping lifetimes may have the same id() value.
참고
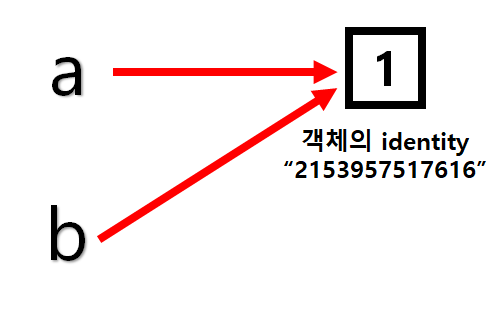
여기서 id(a)와 id(b)의 출력값이 같았던 이유는 같은 객체를 가리키고 있었기 때문이다.
그런데 우리가 아래와 같이 b에 더하기 연산을 해 값을 증가시키고 id값을 출력하면 다른 값을 가진다는 것을 확인할 수 있다.
a = 1
b = a
print(id(a))
print(id(b))
b +=1
print(id(a))
print(id(b))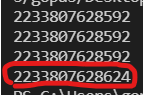
(객체의 identity값은 실행할 때마다 바뀐다.)
위에서 b를 증가시키고 나서 보니 id(b)의 값이 변경된 것을 알 수 있다. 즉, 새로운 객체가 생성이 되었다고 이해할 수 있다.
앞서 언급한 mutable immutable 키워드로 돌아가보자.
mutable은 바뀔 수 있는, immutable을 바뀔수 없는이라는 의미를 가지고 있다고 했다.
결론부터 이야기 하면 1과 같은 number 타입은 immutable 타입으로 변경 불가능해서 새로운 객체가 만들어졌다.
이 두 키워드는 *객체*가 변경 불가능한 객체인지 아니면 변깅이 가능한 객체인지를 이야기 하는것이다.
number 타입은 변경이 불가능하기 때문에 2라는 새로운 객체를 만들어 b가 2를 가리키게 한 것이다. 그래서 b는 2에 접근한다.
위의 과정을 다시 돌아보면
1) a=1이라는 연산을 통해 a가 1이라는 immutable한 객체를 가리키도록 하였고
2) b=a라는 연산을 통해 b가 a를 가리키게 하였다. (여기서 b=1을 해도 1이라는 객체가 이미 존재 하기 때문에 b의 id값은 a의 id값과 같다. 아래 참고)
3) 그리고 b += 1 이라는 연산을 통해 1에서 1을 증가시킨 2라는 새로운 객체를 만들고 b는 2를 가리킨다.
참고)
a = 1
b = 1
print(id(a))
print(id(b))mutable 객체 살펴보기
위의 경우 immutable 객체는 변경자체가 불가능하기 때문에 새로운 객체를 만드는 것을 볼 수 있다.
그렇다면 mutable한 객체는 어떤 것이 있을까? 대표적으로 list이다.
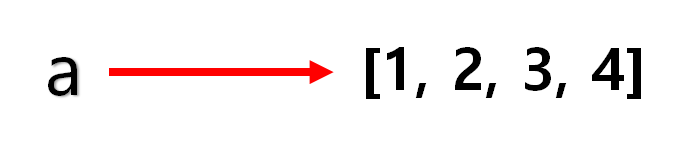
a = [1,2,3,4]아까와 마찬가지로 [1,2,3,4]라는 리스트 타입의 객체를 만들고 a가 이 객체를 가리키도록 한다.
그리고 위와 같이 대입 연산을 하고 id 값을 확인해보면 같은 id값을 return 하는 걸 볼 수 있다.
a = [1,2,3,4]
b = a
print(id(a))
print(id(b))
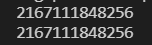
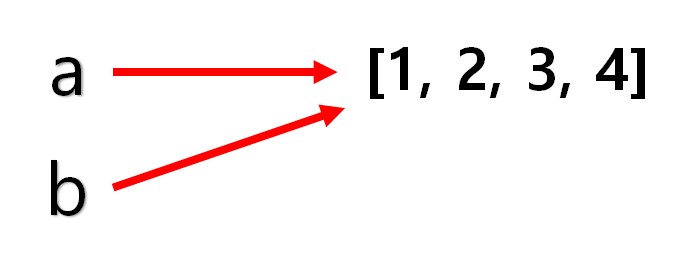
그리고 아까와 같이 b의 변수에 어떤 변화를 줘보자.
a = [1,2,3,4]
b = a
print(id(a))
print(id(b))
b.append(5)
print("a 리스트 출력 :", a)
print("b 리스트 출력 :", b)
print("id 값 확인해보자")
print("a의 id값 :",id(a))
print("b의 id값 :",id(b))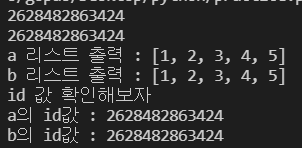
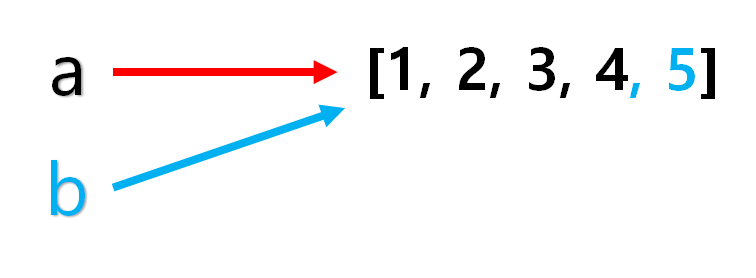
b를 이용해서 리스트에 값을 추가 시켰는데, id 값은 바뀌지 않았고 a로 출력하는 리스트도 b로 출력하는 리스트도 모두 같은 것을 볼 수 있다.
즉, list 형은 mutable한 객체라서 변경이 가능하다. 위 int타입은 변경이 불가능한 객체라서 새로운 객체를 만들었지만, list는 변경이 가능하기 때문에 b를 통해 해당 객체에 접근을 해서 변경을 하였고 a또한 그 객체를 가리키고 있었기 때문에 같은 리스트와 같은 id값을 출력하는 것이다.
파이썬의 call by
파이썬의 call by는 어떻게 될까? 파이썬은 call by value나 call by reference가 아닌 call by assignment (또는 call by object-reference)이다.
변수의 이름은 어떤 걸 가리키는데 사용이 되고 새로운 이름으로 다른 변수가 가리키는 객체에 접근하였을 때 그 객체가 immutable 하냐 mutable 하냐를 판단해서 동작시킨다.
C나 C언어의 경우 swap 함수를 구현하기 위해 매개변수를 포인터나 참조를 이용해주는 것과는 다른 양상이다.
void swap(int* a, int* b);
void swap(int& a, int& b);파이썬의 경우 객체의 타입을 판단해서 전달하기 때문에 굳이 swap 함수를 만든다면 아래와 같이 만들 수 있을 것이다.
def swap(a,b):
# 이것저것 작성하고
return b, a
a, b = swap(a,b)그리고 C++의 경우 함수를 통해 외부의 vector값을 수정하기 위해 참조로 전달했다면 파이썬의 경우 리스트는 mutable 객체이므로 그냥 이름만 적어주면 된다.
void function(vector<int>& a){
// 작업
}def function(a):
# a는 변수이름
pass 파이썬은 객체다!!
