Reference
- https://medium.com/@adrianchang/apache-spark-checkpointing-ebd2ec065371
- https://www.waitingforcode.com/apache-spark/cache-in-spark/read#cache_types
- https://jaemunbro.medium.com/apache-spark-rdd-%EC%9E%AC%EC%82%AC%EC%9A%A9%EC%9D%84-%EC%9C%84%ED%95%9C-%EC%98%81%EC%86%8D%ED%99%94-persist-cache-checkpoint-12c121dac8b6
- https://stackoverflow.com/questions/26870537/what-is-the-difference-between-cache-and-persist
- https://github.com/JerryLead/SparkInternals/blob/master/markdown/english/6-CacheAndCheckpoint.md
- https://stackoverflow.com/questions/35127720/what-is-the-difference-between-spark-checkpoint-and-persist-to-a-disk
- https://stackoverflow.com/questions/52651282/cache-vs-localcheckpoint-and-how-to-stop-spark-from-removing-it
- https://tomining.tistory.com/84
- https://livebook.manning.com/book/spark-in-action-with-examples-in-java/16-cache-and-checkpoint-enhancing-spark-s-performances/v-14/51
1 spark Cache 란?

- Spark 캐시는 Executor 메모리 또는 디스크에 DataFrame(/RDD/Dataset)을 저장하는 메커니즘입니다.
- 이를 통해 DataFrame을 한 번만 계산하고, 그 이후의 Transformation 및 Action에 재사용할 수 있습니다
- 이때 캐시를 사용하면 다음과 같은 이점이 있습니다.
- 매번 연산할 때마다 데이터 세트가 메모리 내에 존재하고 있는 것이 보장되므로 성능 향상을 기대할 수 있습니다.
- 각 파티션의 연산 비용이 너무 큰 경우 중간 결과를 캐시로 저장하여 실패 시의 비용을 줄일 수 있습니다.
- 하나 예시를 생각해봅시다.

- 위는 특정한 Dataframe 에 대해
explain()의 결과입니다. 위처럼 엄청나게 긴 데이터 Transform 문이 있을 경우, 중간에 Fault 가 발생할 경우, 다시 계산해야되기 때문에 시간이 매우 오래 걸릴 수 있습니다. 이때에 cache 를 활용하여서 이러한 Lineage 를 끊어준다면, 계산 시간을 매우 절약할 수 있습니다.
df = ..... (엄청난 연산)
pdf = df.persist()
# 뒤의 연산은 이제 빠르게 일어날 수 있다.2 Spark Cache 사용하기
- 스파크는 RDD의 재사용을 위해 몇 가지 방식을 제공합니다.
persistence,caching,checkpointing
- Cache, Persist, Checkpoint, Shffule files 와 같은 재사용 방식들에 대해서 조금 더 자세히 알아봅시다.
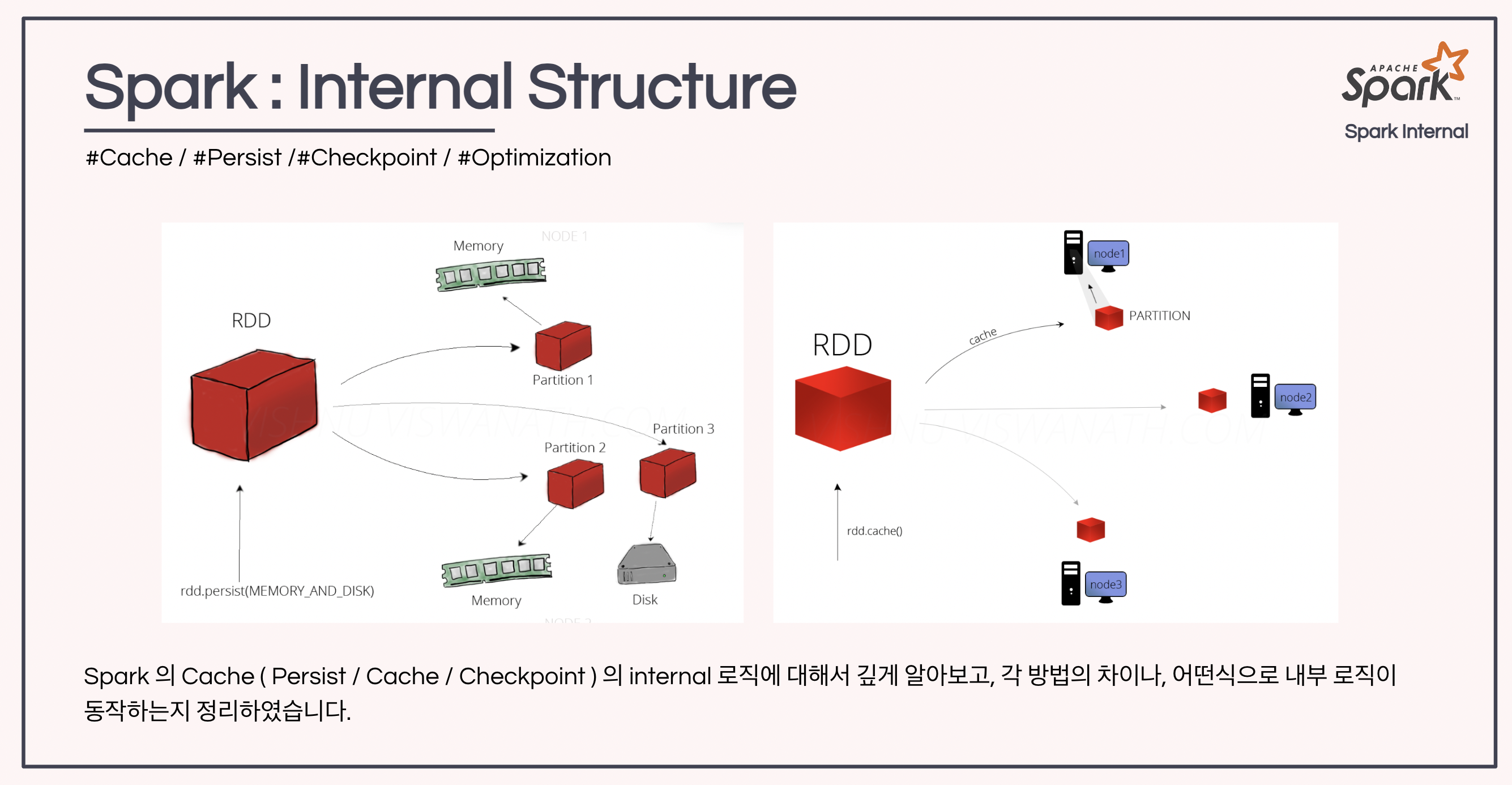
2.1 Persist / Cache
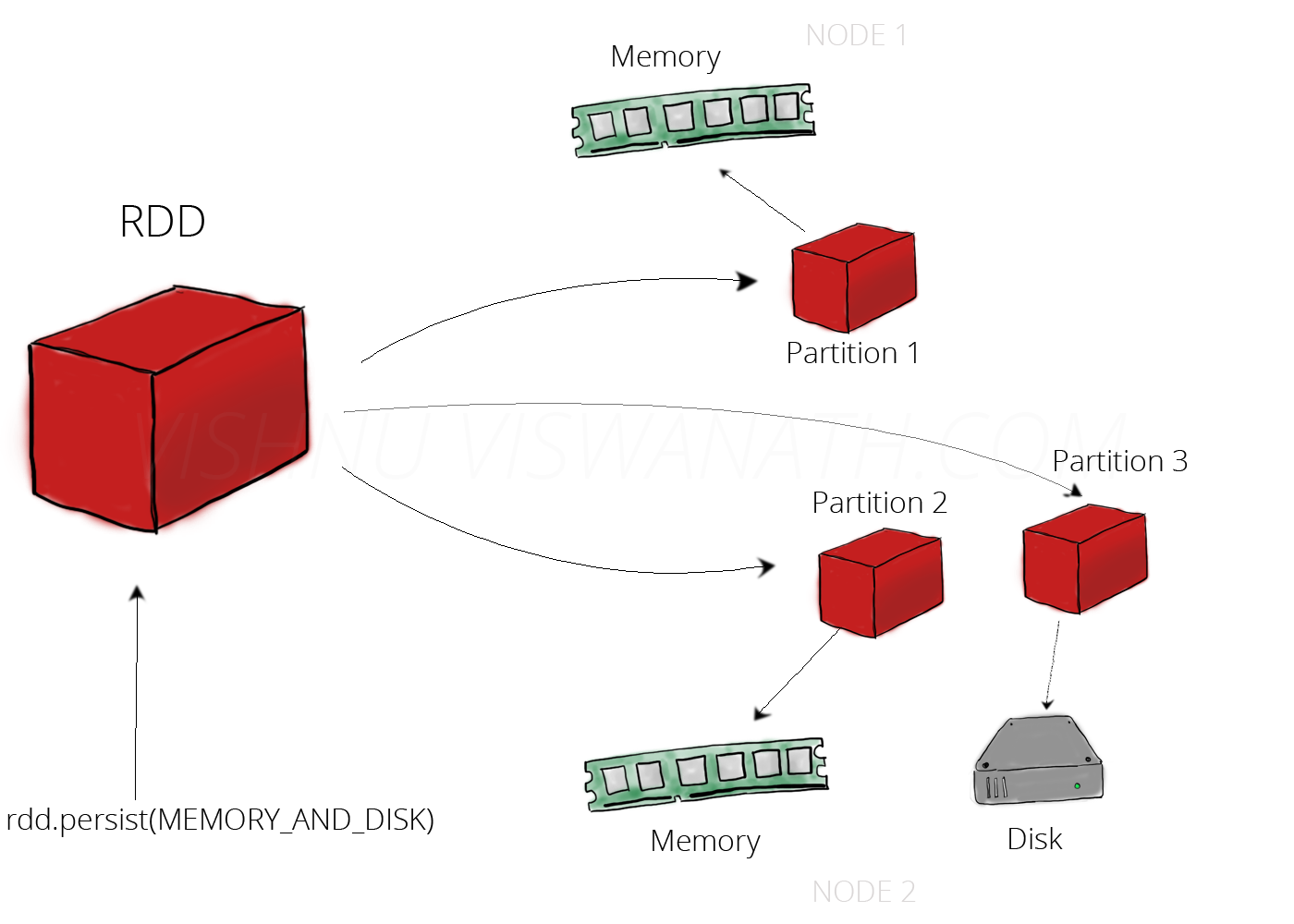
persist 와 cache 는 , RDD 를 Memory 또는 Disk 에 저장하는것입니다. 하지만 이때 이 두개를 구분하기 힘들어 하시는데요,
The difference between
cacheandpersistoperations is purely syntactic. cache is a synonym of persist or persist(MEMORY_ONLY), i.e.cacheis merelypersistwith the default storage levelMEMORY_ONLY
- 즉 위 설명을 보면 cache 와 persist 의 차이는 매우 간단합니다.
- cache : 단순히 memory 에만 결과를 저장
- persist : 다양한 storage level 에 결과를 저장할 수 있음
- persist 는 아래에서 설명하는 여러 stroage level 인자를 이용해서 저장되는 위치를 조절할 수 있습니다. 이때 이러한 위치는 어떻게 조절할 수 있는지 알아봅시다.
2.1.1 Persist : Storage Level
- persist 를 이용하면, Storage Level 을 아래처럼 다양하게 설정할 수 있습니다.

- Refer : http://spark.apache.org/docs/latest/rdd-programming-guide.html#rdd-persistence
위 표의 Storage Level은 아래 다섯가지 설정의 조합으로 만들어졌습니다. 아래 5가지를 이해하면 됩니다.
- userDisk :
- 데이터를 Disk 에 저장합니다.
- 디스크 IO 비용도 크므로 이 옵션을 사용하는 경우는 재연산 비용이 큰 경우가 될 것입니다.
- 재연산의 비용이 크지 않은 경우 일부 파티션을 재연산하는 것이 더 빠를 수도 있다.
- useMemory
- 데이터를 메모리에 저장합니다.
- 데이터를 Disk 보다 훨씬 빠르게 접근할 수 있습니다.
- useOffHeap
- Tachyon과 같은 executor 밖의 외부 시스템에 데이터를 저장합니다.
- 메모리이슈가 심각하거나 클러스터가 혼잡한 편이고 파티션이 자꾸 메모리에서 제거된다면 고려해볼만 합니다.
- serialized(SER) :
- serialized Java objects 객체로 데이터를 저장합니다.
- JAVA 객체로 메모리에 저장해야하기 때문에 Serialization Step 이 추가됩니다. ( Raw data 를 Java Type 로 변환하는 Serializtion 과정이 필요 ) 그에 따라 속도는 느려집니다. (https://www.waitingforcode.com/apache-spark/cache-in-spark/read#cache_types )
- MEMORY_ONLY_SER 처럼 suffix로 _SER이 붙는 옵션들은 JAVA - 직렬화를 사용하게 됩니다.
- RDD가 메모리에 들어가기 너무 크다면 우선 MEMORY_ONLY_SER 옵션으로 직렬화를 시도해봅시다. 이 방법은 RDD에 빨리 접근하도록 유지하면서도 저장에 필요한 메모리는 줄어듭니다.
Note : 직렬화시에는 데이터 용량이 늘어날까?
- 자바 직렬화시에 기본적으로 타입에 대한 정보 등 클래스의 메타 정보도 가지고 있기 때문에 상대적으로 다른 포맷에 비해서 용량이 큽니다.
- 특히 클래스의 구조가 거대해지게 되면 용량 차이가 커지게 됩니다. 예를 들면 클래스 안에 클래스 또 리스트 등 이런 형태의 객체를 직렬화 하게 되면 내부에 참조하고 있는 모든 클래스에 대한 메타정보를 가지고 있기 때문에 용량이 비대해지게 됩니다.
- replication
- persist 데이터의 복사본 개수를 정수로 지정합니다. default = 1.
- 빠른 Fault - Tolerance 를 원하는 경우에, ( Spark 를 사용해서 Web Application 의 요청을 처리하는 경우. 빠르게 처리되어야하기도 하지만, 데이터 손실이 없어야함. ) 2 이상으로 정의하면, 복제된 Storage 수준을 유지할 수 있습니다.
- 물론 이를 1 로 지정하더라도, 어떤 Executor 가 손실되면 손실된 데이터에 대해서는 recomputing 이 이루어져서 fault tolerance 가 유지되지만, replicated 가 있었을 경우에는, lost-partition 에 대해서 서 recomputing 할 필요 없이 빠르게 다시 사용이 가능합니다.
In Pyspark 에서는?
python 에서는, Stored Object 는 항상 Pickle Library 를 이용하여 Serialized 됩니다. 즉 serialized 가 어떤식으로 저장되는지를 정하는것은 의미가 없습니다. (즉 SER 의 접미사가 붙은설정은 의미 없음) Python 에서 가능한 Storagelevel 은 다음과 같습니다.
MEMORY_ONLY,MEMORY_ONLY_2MEMORY_AND_DISKMEMORY_AND_DISK_2DISK_ONLYDISK_ONLY_2DISK_ONLY_3
그럼 storage Level 을 어떻게 설정해야 할까?
- default 는
MEMORY_ONLY인데, 웬만하면 그대로 사용하는것이 좋음. 일반적으로 cache 를 하는 이유는 메모리에서의 접근이 매우 빠르다는것을 활용하는 경우가 많은데, Disk 를 섞어서 저장하면 매우 비효율적이게 됩니다.MEMORY_ONLY_SER와 빠른 직렬화 라이브러리 를 선택하면, RDD 를 저장할떄에 훨씬 더 공간 효율적으로 만들면서도 여전히 합리적으로 빠르게 액세스할 수 있습니다. (자바와 스칼라인 경우에만 해당되고, 파이썬일때에는 불가능하긴 합니다.)- 웬만하면 디스크에 저장하지 않는게 좋습니다.
- 디스크에 저장한 뒤에 연산하는것은, hadoop 에 저장한 데이터를 이용하는것보다 더 느릴 수 있음
- Fault 에 대한 빠른 복구를 원하는 경우엔 (예: Spark를 사용하여 웹 애플리케이션의 요청을 처리하는 경우) 복제된 스토리지(replication)를 사용해도 좋습니다.
- 이때 복제된 스토리지 레벨을 사용하면 손실된 파티션을 재계산할 때까지 기다리지 않고, 저장된 다른 파티션을 불러올 수 있으므로, RDD에서 작업을 계속 실행할 수 있습니다.

2.2 checkpointing / localcheckpoint
df = df.checkpoint()persist와 달리 RDD - Lineage 를 없앤 후 DIsk 에 저장하는 방법입니다.
- checkpointing
- Checkpointing 한 RDD를 HDFS나 S3같은 외부 저장 시스템에 씁니다.
- RDD가 스파크 외부에 저장되므로, 스파크 애플리케이션이 종료된 이후에도 데이터가 유효한채로 남아있게 됩니다.
- 일반적으로 IO비용은 매우 비싸므로 persist보다 느릴 수 있으나, 스파크의 메모리를 전혀 쓰지 않으며, 스파크의 worker node에 문제가 생기더라도 재연산이 필요치 않다는 장점이 있습니다.
- Checkpointing 은 실패나 재연산의 비용에 대한 우려가 클 때 사용할 수 있습니다.
- localcheckpoint
- executors storage (Memory) 또는 disk에 에 데이터를 저장합니다.
- Executor 의 Storage 에 데이터를 저장하므로, Spark Application 이 종료되거나, Node 에러시에 재계산을 해야할 수 있습니다.
- 일반적으로 checkpoint 는 hdfs 같은 storage 에 쓰는게 일반적이라서, 이러한 방식은 잘 쓰이지 않습니다. (그리고 그게 더 안정적이기 때문입니다.)
2.2.3 checkpoint : Lineage 제거
Checkpointing 를 썻을때 Lineage 제거 되는 모습을 실제로 볼까요?
(https://medium.com/@adrianchang/apache-spark-checkpointing-ebd2ec065371)
만약 DataFrame 이 매우 크다면 이를 캐시하기 위한 램이 충분하지 않을 수 있습니다. 물론 이 상황에서 Disk 에 저장하기 위해 persist(StorageLevel.DISK_ONLY) 를 쓸 수도 있을것입니다.

위와 같은 데이터를 Checkpointing 한 뒤에 Expain 을 통해서 Lineage 를 살펴보겠습니다.!

위처럼 RDD 의 Lineage 가 모두 없어진 상태로 저장되는것을 볼 수 있습니다. 이렇게 History 를 날려버린 상태에서 저장한다는 점입니다. 여러 단계를 거쳐 데이터를 변환하는 경우, 중간에 checkpoint를 걸어 lineage를 단축해 성능을 향상시킬 수 있습니다
2.2.4 checkpoint : HDFS 에 데이터 저장
# eager : 즉시 데이터를 지정된 디렉토리에 저장하라는 으미
df = df.checkpoint(eager=True)
# dirName 위치에 저장
spark.SparkContext.setCheckpointDir(dirName)df_modeling_all = spark.read.parquet("....")
df_modeling_all = df_modeling_all.where(F.col("alter_key") % 2 == 1)
spark.sparkContext.setCheckpointDir("hdfs/...../tmp/checkpoint")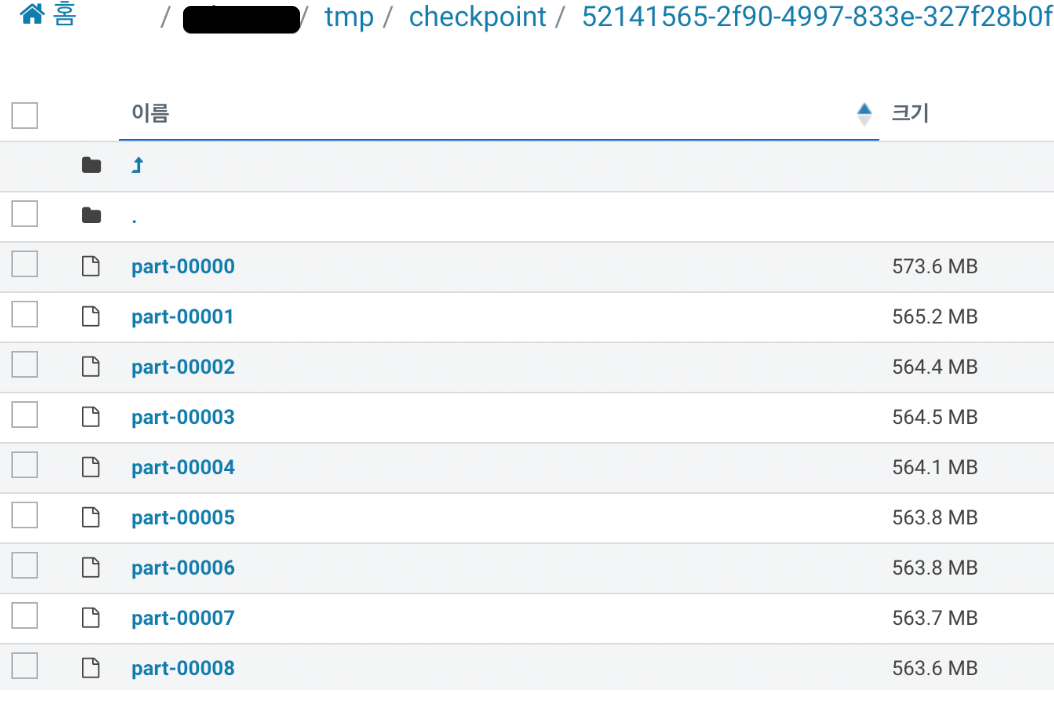
- 위처럼 checkpoint 를 통해 지정된 하둡에 저장된것을 볼 수 있습니다.
Note : Write to Disk vs Checkpoint
https://stackoverflow.com/questions/51772790/spark-efficiency-of-dataframe-checkpoint-vs-explicitly-writing-to-disk- 개인적인 생각으로는, 사실 HDFS 에 쓰는게 훨씬 더 간편하긴 해서, 이걸 추천하지는 않습니다;
2.3 SQL 을 이용한 캐시
- DataFrame DSL 대신 SQL을 직접 사용할때에도 캐싱을 사용할 수 있습니다.
spark.sql("cache table table_name")
# 위처럼 하면,table_name 이라는 캐시된 테이블을 spark sql 에서 계속 사용할 수 있다.- 우리가 이전에 보던 코드와 다른점은, SQL을 사용하면 기본적으로 캐싱이 즉시 실행되므로 작업이 즉시 실행되고 데이터가 caching layer에 저장된다는 것 입니다.
- DataFrame DSL에서와 같이 Lazy - Execution 으로 만들기 위해 lazy 키워드를 명시적으로 사용할 수 있습니다.
spark.sql("cache lazy table table_name")- 캐시에서 데이터를 제거하려면 다음을 실행하면 됩니다.
spark.sql("uncache table table_name")3 Spark Internal
이제 위에서 cache 를 어떻게 사용하는지 대충 알았는데요, 아래에서는 이러한 cache 가 어떻게 동작하는지에 대해서 한번 알아봅시다.
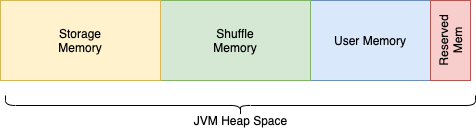
3.1 Memory
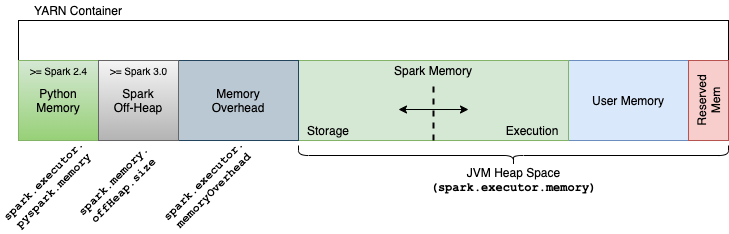
Storage Memory
메모리 사이즈 : (Java Heap Memory - Reserved Memory) * spark.memory.fraction * spark.memory.storageFraction
- spark.memory.storageFraction = 0.5, default)
- 캐싱 (DataFrame.cache, CACHE TABLE) 또는 Broadcast, Driver 로 보내는 결과들이 이 영역의 메모리를 사용합니다.
- persist 옵션이
MEMORY이면 이 영역에 데이터가 캐싱됩니다. - 캐싱할 공간이 부족하여 오래된 캐시 데이터를 지울 경우엔 LRU(Least Recently Used) 방식으로 제거한다. (즉, 블록이 디스크로 강제 추방될 수 있음.)
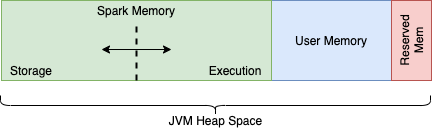
이전 Spark 버전(<1.6) 에서는 Storage 와 Shuffle 메모리를 나눠서 설정하였으나, 이후 버젼에서는 두개 메모리가 통합되어서 동적으로 관리되게 됩니다.
Spark < 1.6 Memory (Decoding Memory in Spark)
Spark >= 1.6 Memory (Decoding Memory in Spark)
3.2 LRU Caching
- 더 이상 쓰이지 않는 RDD라고 해서 자동으로 persist가 해제되지는 않습니다.
- 드라이버에서 명시적으로 unpersist 함수가 호출되거나, 메모리 공간의 압박으로 축출(evict)되기 전까지는 메모리에 남아있게 됩니다.
- 스파크는 executor가 메모리 부족을 겪을 때 뺄 파티션을 결정하기 위해 LRU(Least Recently Used) caching 방식을 사용하여 쓰인지 가장 오래된 데이터를 빼고 있습니다.
- 영속화된 RDD를 빼고 공간을 확보하고 싶다면 unpersist를 사용합시다.
- 공간이 부족해지기 시작하면 Spark는 LRU(최근에 사용한 것) 정책을 사용하여 캐시를 제거하기 시작하므로 캐시를 지우는 것이 좋습니다. 자동 삭제는 PySpark 애플리케이션에 필수적인 캐시를 삭제할 수 있으므로 일반적으로 자동 삭제에 의존하지 않는 것이 좋습니다!
3.3 Cache Manager
- 캐싱은 지연 변환이므로 함수를 호출한 직후 데이터에는 아무 일도 일어나지 않습니다.
- 하지만 쿼리 계획에 InMemoryRelation 를 추가하게 됩니다. 이 InMemoryRealtion 은 query execution 을 실행할때에, 캐시된 데이터를 사용하도록 해 주는 연산자입니다.
- 일반적으로 Spark 는 데이터를 읽을때에 먼저 캐싱 계층에서 데이터를 찾고 사용 가능한 경우 거기에서 읽습니다.
- 캐싱 레이어에서 데이터를 찾지 못하면(쿼리가 처음 실행될 때 발생함) 실행 계획에 따라 데이터를 직접 가져오게 됩니다.
- Cache Manager는 쿼리 계획 실행시에 이미 캐시된 계산을 추적하고 관리하는 임무를 맡게됩니다.
- cahce function 이 호출되면 Cache-Manager가 직접 호출되고 캐싱 기능이 호출되는 DataFrame의 analyzed logical plan 을 끌어내고 해당 계획은 cachedData 라는 이름으로 저장됩니다.
- 이러한 Cache Manager 단계는 Logical 계획의 일부가 되고, 이는 Optimizer 의 최적화가 일어나기 전에 발생합니다.
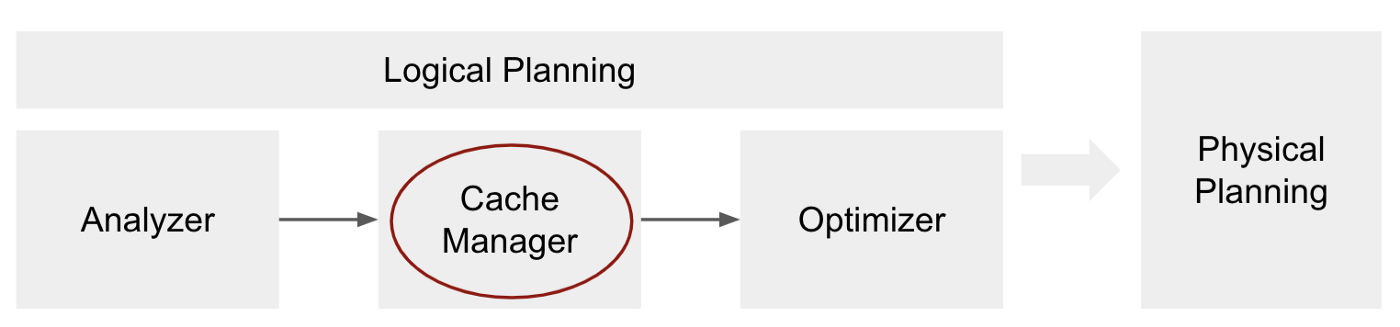
- Cache Manager 의 단계 (옵티마이저 직전)에서 Spark는 분석된 계획의 각 하위 트리가 cachedData 에 저장되어 있는지 확인합니다.
- 일치하는 항목을 찾으면 동일한 계획(동일한 계산)이 이미 캐시되어(아마도 이전 쿼리에서) Spark가 이를 사용할 수 있고 따라서 다음을 수행할 InMemoryRelation 연산자를 사용하여 해당 정보를 쿼리 계획에 추가합니다.
- InMemoryRelation 은 physical planning 단계에서 물리적 연산자인 InMemoryTableScan 을 만드는 데 사용됩니다 .
df = spark.table("users").filter(col(col_name) > x).cache()
df.count() # now check the query plan in Spark UI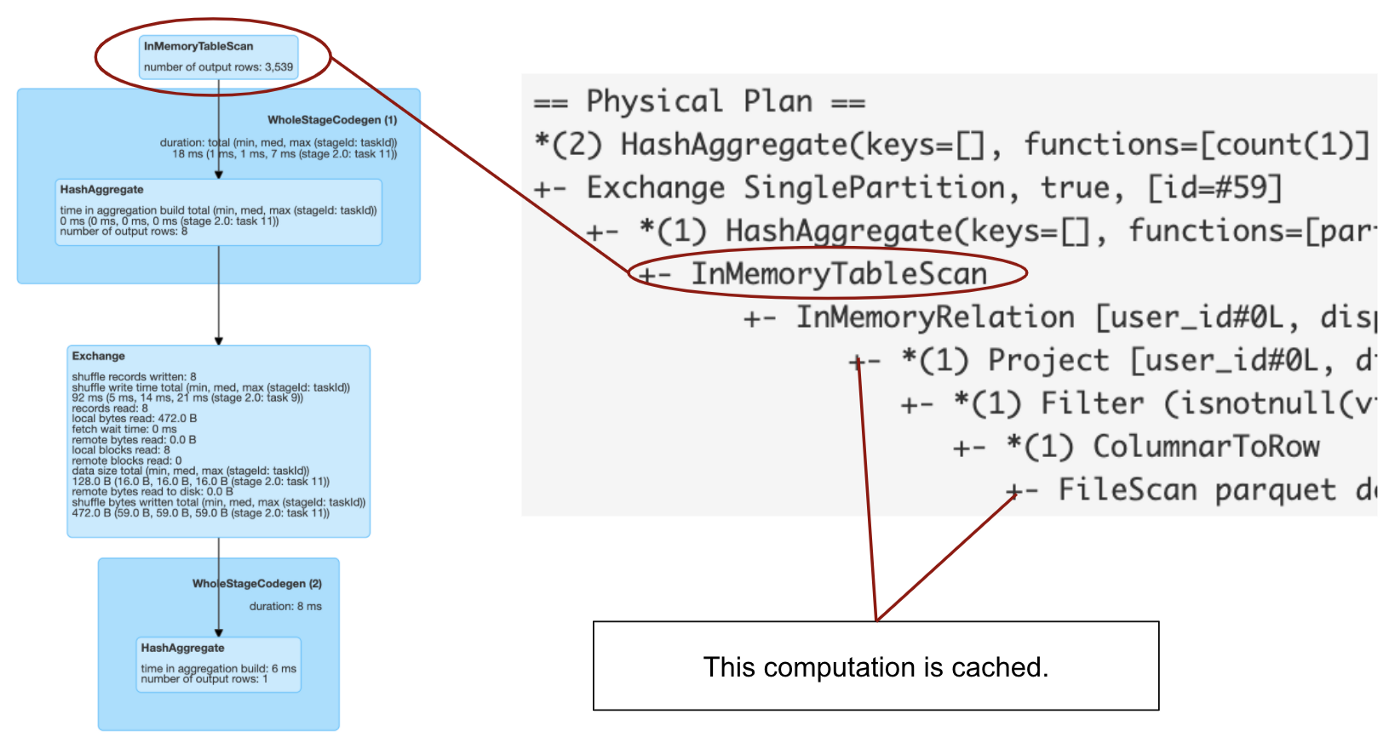
- 여기 위의 그림에서 캐싱을 사용할때의 쿼리를 볼 수 있습니다.
- 물론 어떤 변환이 캐시되었는지 확인하려면 그림에 이 정보가 표시되지 않기 때문에 계획의 string representation 을 조사해야 합니다.
3.4 Example
- Cache Manager 이 어떻게 작동 하는지 더 잘 이해하기 위해 간단한 예를 살펴보겠습니다.
df = spark.read.parquet(data_path)
df.select(col1, col2).filter(col2 > 0).cache()- 다음 세 가지 쿼리를 생각해봅시다. 이중 어느 것이 캐시된 데이터를 활용할까요?
# 1) df.filter(col2 > 0).select(col1, col2)
# 2) df.select(col1, col2).filter(col2 > 10)
# 3) df.select(col1).filter(col2 > 0)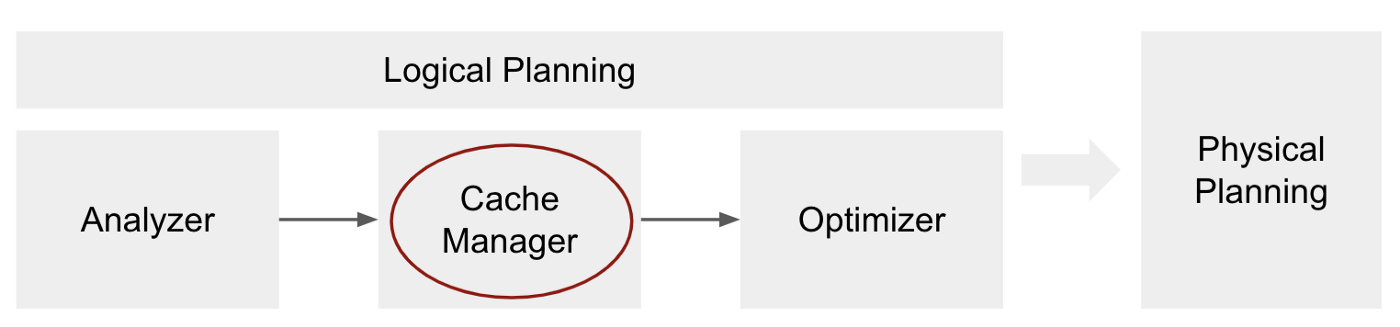
1번 쿼리 : 1) df.filter(col2 > 0).select(col1, col2)
- 이떄 Cache Manager 가 작동하는 부분은 analyzed logical plan 입니다. 캐시된 쿼리가 Analysis Plan과 동일하면 캐시를 활용합니다.
- 위에서 1) 번의 쿼리의 경우. 어짜피 스파크의 최적화 프로그램에 의하여df.select(col1, col2).filter(col2 > 0)->df.filter(col2 > 0).select(col1, col2)가 되기 때문에 동일한 계획이고, 이에 따라서 캐시된 데이터를 사용한다고 생각할 수 있습니다. - 그러나 이것은 정확하지 않습니다. 중요한 것은 캐시 관리 프로그램의 단계가 옵티마이저 보다 먼저 발생 한다는 것 입니다.그래서 쿼리 1의 분석된 계획이 다르기 때문에 캐시를 활용하지 않습니다.
2번 쿼리 df.select(col1, col2).filter(col2 > 10)
- 필터가 캐시된 쿼리의 필터(>0)보다 더 제한적(>10)이기 때문에 캐시된 데이터를 사용할 것이라고 생각할수도 있습니다
- 쿼리된 데이터가 캐시에 있음을 알 수 있지만 이전과 같은 이유로 Spark는 캐시에서 데이터를 읽지 않습니다.
- 이번에는 필터링 조건이 동일하지 않고, 그럼에 따라 Analyezed Plan 이 달라져 캐시를 활용하지 않습니다.. 그러나 캐시된 데이터를 사용하기 위해 필터를 추가하여 두 번째 쿼리를 수정할 수 있습니다.
df.select(col1, col2).filter(col2 > 0).filter(col2 > 10)- 언뜻 보기에 필터 col2 > 0 은 여기에서 쓸모없는 것처럼 보이지만 이제 analyzed logical plan의 일부가 캐시된 계획과 동일하고 캐시 관리자 가 이를 찾아 InMemoryRelation 에서 사용할 수 있기 떄문에 좋은 쿼리입니다!

3번 쿼리 : df.select(col1).filter(col2 > 0)
- 언뜻 보기에는 쿼리가 다르기 때문에 캐시된 데이터를 사용하지 않아보일 수 있습니다.
- 코드상에서는 col1만 선택합니다. 그러나 필터링 조건은 이전 프로젝션에 없는 col2 를 사용하므로 Analyzer 는 결국 ResolveMissingReferences 규칙을 호출합니다. 이는 결국 col2 를 프로젝션 에 추가 하고 분석된 계획은 실제로 캐시된 계획과 동일하게 됩니다.
ResolveMissingReferencesis a physical optimization rule in Apache Spark SQL that is used to optimize query execution by resolving missing references in a query plan. - 이번에는 캐시 프로그램이 이를 찾아 사용합니다.
따라서 최종 답변은 쿼리 3입니다. 이는 캐시된 데이터를 활용하게 됩니다!
4 Best practices
- 개인적으로, Cache 는 되도록이면 사용하는것을 싫어하지만, 어쩔 수 없이 사용해야 할 때 아래 Practice 들을 따르는것이 좋습니다.
4.1 캐시된 object 는 새 변수에 할당하자.
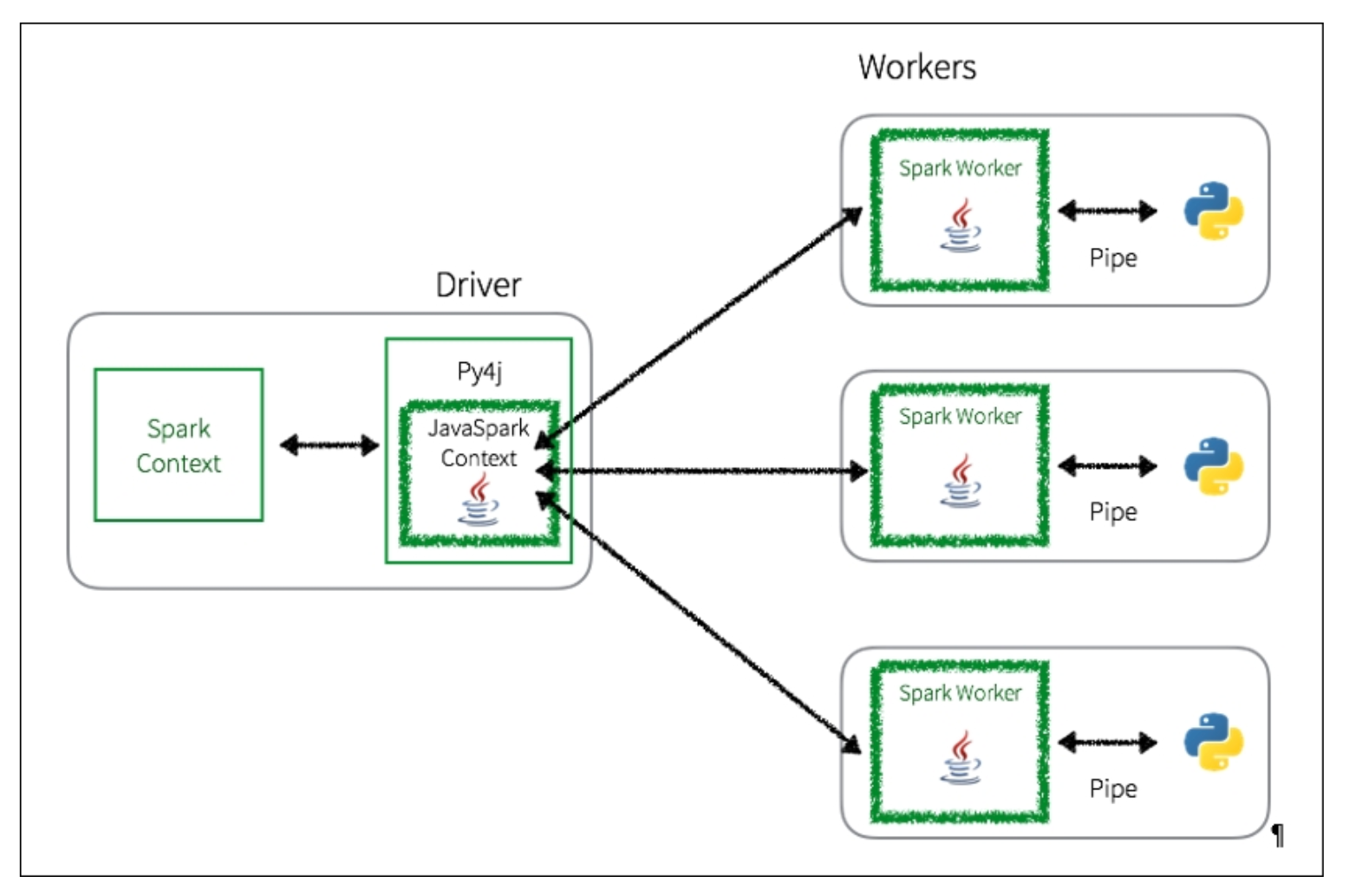
- DataFrame을 캐시할 때 cachedDF = df.cache() 와 같이 새 변수를 할당해서 만들면서 코드를 짜야 합니다.
- 왜냐하면 위 그림을 보면 알 수 있듯이, Driver Node 에서는 캐싱된 데이터를 특정한 object 에 할당하면, 그 object 는 여러 cluster 에 캐싱된 데이터와 매핑되게 됩니다. 하지만 이 object 에 다른 데이터셋을 할당하게 된다면, driver node 에서는 캐싱된 데이터를 사용할 수 없게 되고 , 캐시된 데이터는 계속 Executor 에 남게 되므로 관리가 매우 힘들게 됩니다.
- 아래 예시를 통해서 살펴보면
df = df.cache() # 캐쉬된 실행 내역
df = df.select("col1"."col2").where(col>10)...
...
# 위와 같이 계속 df 를 덧씌우면 캐시를 한 시점에서의 실행 계획은 캐시되겠지만,캐쉬된것을 계속 사용하는데에는 무리가 있습니다.
df_cached = df.cache()
df_cached_filter = df_cached.select("col1"."col2").where(col>10)...
...
# 위와 같이 사용한다면 cache 를 활용하고자 할때에 df_cached 에서 시작하면 됩니다. 굳이 실행 계획을 다시 되짚어가면서 계산할 필요가 없습니다.- 위처럼 df.cache() 를 통해 캐쉬된 데이터를 사용합시다! (저는 개인적으로
cdf를 사용합니다) 아래 같은 이름을 사용하는걸 선호합니다.
- cdf : cached spark dataframe
- sdf : spark dataframe
- pdf : pandas dataframe
4.2 필요하지 않으면 바로 Unpersist
- 더 이상 필요하지 않은 DataFrame 에 대해서는 cache 유지를 해제 하기 위해 cachedDF.unpersist() 를 쓰는것이 좋습니다.
- 캐싱 레이어가 가득 차면 Spark는 LRU(최근에 사용한 것) 전략을 사용하여 메모리에서 데이터를 제거하기 시작합니다. 이런 로직때문에 사용하지 않는 캐시 데이터때문에 다른 캐시 데이터가 영향받아 삭제될 수 있습니다.
- 또한 캐시 데이터 때문에 Executor 의 Memory 가 부족해져서 Operation 돌아가지 않을 수 있습니다.
4.3 ML 모델 돌리기 전에 cache 하기
- ML 모델은 대부분 같은 데이터를 반복적으로 사용하게 됩니다. 그러므로 메모리가 된다면 데이터를 넣기 전에 cache 하는것이 좋습니다. (안된다면, 전처리 된 데이터를 Disk 에 쓴 다음, 해당 데이터를 사용하는게 중요합니다.)
- 체감상 memory 에 persist 한 경우 20배정도 빠르게 작동합니다.
- 이때에 Cache 할때에는 꼭 "필요한 Column 만 선택해서" Persist 하는게 중요합니다. 예를 들면 ML 모델에서는 'target' 과 'features' 2개의 column 만 요구하는 경우가 잦기때문에, 모델 돌리기 전에 이 두개의 Feature 만 persist 해서 돌리는게 좋습니다.
4.4 필요한것만 캐시하자.
- 캐시하기 전에 쿼리에 필요한 것만 캐시하고 있는지 확인합시다.
- 예를 들어, 한 쿼리가 (col1, col2, col3) 을 사용하고 두 번째 쿼리가 (col2, col3, col4) 를 사용 하는 경우 다음 열의 상위 집합을 선택해서 캐시하는게 좋습니다.
- cachedDF = df.select(col1, col2, col3, col4) .cache() .
- 의미가 있는 경우에만 캐싱을 사용하는게 좋습니다. (즉 빠르게 갱신될 필요가 없는 경우에 대해서는 그냥 Disk 를 활용하는게 좋습니다.)
4.5 캐시가 오히려 느릴때도 있다.
- 캐싱이 전혀 도움이 되지 않고 반대로 실행 속도가 느려지는 상황이 있습니다.
- 전체 데이터 세트를 캐시한 다음 그 위에서 몇 가지 쿼리를 실행하는 다음 예를 살펴보겠습니다. 다음 데이터세트 및 클러스터를 사용하겠습니다.
먼저 캐싱을 사용하지 않는 쿼리의 실행 시간을 측정해 보겠습니다. (아래 원본 데이터는 parquet 파일니다.)
df = spark.table(table_name)
df.count() # runs 7.9s
df.filter(col("id") > xxx).count() # runs 18.2s이제 캐싱을 사용하여 동일한 쿼리를 실행합니다 (전체 데이터 세트가 메모리에 맞지 않아서 약 30%가 디스크에 캐시됨).
df = spark.table(table_name).cache()
# this count will take long because it is putting data to memory
df.count() # runs 1.28min
df.count() # runs 14s
df.filter(col("id") > xxx).count() # runs 20.6s- 캐시된 경우, 첫 번째 count가 1.3분이 걸리는 것은 당연합니다. 이는 데이터를 메모리에 넣는 것과 관련된 오버헤드이기 떄문입니다. 그러나, count 이후에 실행하는 필터가 있는 쿼리도 parquet에서 직접 읽는 것과 비교하여 캐시된 데이터 대해 더 오래 걸립니다!
오래 걸린 이유
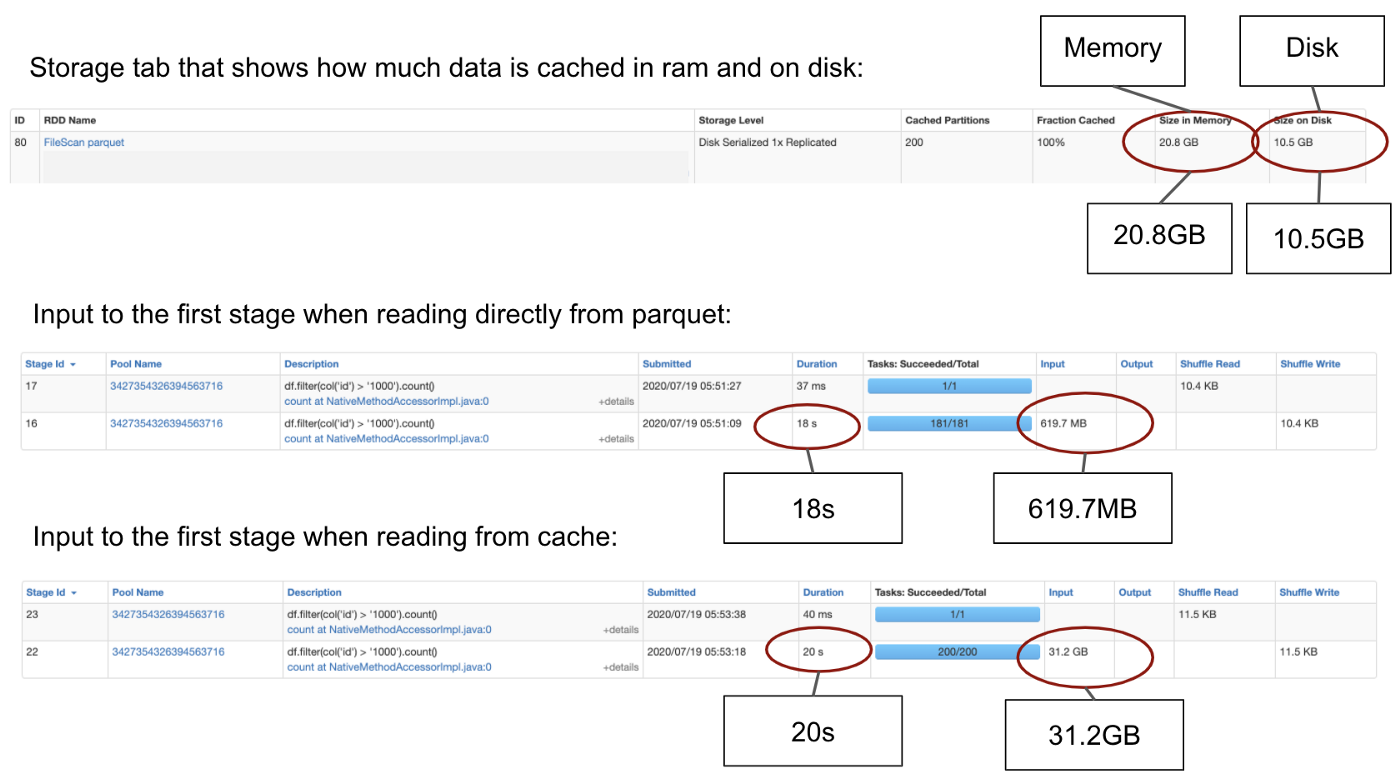
- 첫 번째는 parquet 파일 형식의 속성 덕분입니다.. parquet를 기반으로 하는 쿼리는 자체적으로 빠릅니다.
- parquet에서 데이터를 읽는 경우 Spark는 메타데이터만 읽어서 개수만 먼져 가져오므로 전체 데이터 세트를 스캔할 필요가 없습니다.
- 필터링 쿼리의 경우 Column Pushdown 을 사용하고 ID column만 스캔합니다. - 반면에 캐시에서 데이터를 읽을 때 Spark는 전체 데이터 세트를 읽습니다.
- 이는 첫 번째 Stage 의 입력 크기를 확인할 수 있, 위 Spark UI에서 확인할 수 있습니다.
- parquet에서 데이터를 읽는 경우 Spark는 메타데이터만 읽어서 개수만 먼져 가져오므로 전체 데이터 세트를 스캔할 필요가 없습니다.
- 두 번째 이유는 데이터 세트가 크고 램에 완전히 맞지 않기 때문입니다. 데이터의 일부는 디스크에도 저장되며 디스크에서 읽는 것이 램에서 읽는 것보다 훨씬 느립니다.
4.6 세션을 바로바로 종료하기
- Cache 를 하고나면 각 Executor 의 메모리에 데이터가 저장되게 되는데요, 이때문에 Executor 는 Dynamic - Allocation 을 True 로 했더라도 이 자원들을 잘 뻇기지 않습니다.
- (dynamic allocation 설정에서, chached 된 데이터가 있을경우, executor 를 해재하지 말라고 설정되어있기 떄문이죠.) - 그러므로 Cache 를 쓰고 난 이후에는 세션을 종료하는게 좋습니다. (unchace 를 꼭 하는것도 좋은 Practice)
spark.dynamicAllocation.cachedExecutorIdleTimeout (1.4) (inf)
- Executor 가 chached 된 데이터를 들고 있었더라도, 이 시간이 지나도록 아무 작업이 없다면 Executor 가 제거됩니다.
- defualut 값은 inf 이므로, cache 된 데이터가 있으면 제거가 안됨
5 Conclusion
- 개인적으로 Cache 를 많이 사용해보고, 최적화 및 전체 리소스 운영적으로도 생각을 많이 해보았는데, 저는 다음과 같이 Cache 를 사용해야 된다고 생각합니다.
내가 생각하는 Cache Practice는 다음과 같았습니다. - 캐시는 되도록 쓰면 안된다.
- 전체적인 리소스 관리 관점에서 너무 비효율적임. Dynamic Allocation 으로 관리되는 경우가 많은데, 이 설정을 거의 무력화 시키고 강제로 Memory 를 사용하다 보니, 효율화가 되지 않음
- ML 모델 돌릴때는 쓰면 좋다.
- 이 경우, 반복적인 데이터 사용이 심한데, 이때 사용하는건 오히려 리소스적으로 훨씬 더 절감이 됩니다.
- 웬만해서는 중간 데이터를 HDFS 에 써서 해결하자.
- CheckPoint 든, Persist(Disk) 든, 이러한 로직은 오히려 느리고 불편하고 관리가 힘듦. 그냥 하둡에 쓰는게 제일 간단하고, 관리가 편했음!
