들어가기 전에 ..
데이터나 프로그램을 저장하는 저장 공간은 계층 구조를 가진다.
CPU에서 가장 가까운 저장 공간은 레지스터이고,
레지스터 → CPU 캐시 메모리 → 메인 메모리 → 보조기억장치 → 외부기억장치 순으로 CPU와 멀어진다.
CPU로부터 멀어질수록 데이터를 저장하는 용량이 커지고 접근 속도는 느려진다.
진짜로 들어가기 전에.. ROM vs RAM
ROM은 Read Only
RAM은 Read / Write 가능
이제 진짜로 시작함 ..
프로그램의 작성과 실행은 다음과 같은 순서로 진행된다.
- 프로그램 작성
- 작성한 프로그램을 디스크에 저장
- 사용자가 운영체제에 프로그램의 실행을 요청
- 운영체제가 프로그램의 정보를 읽어 메인 메모리에 공간을 할당해 load
메모리 공간의 구조
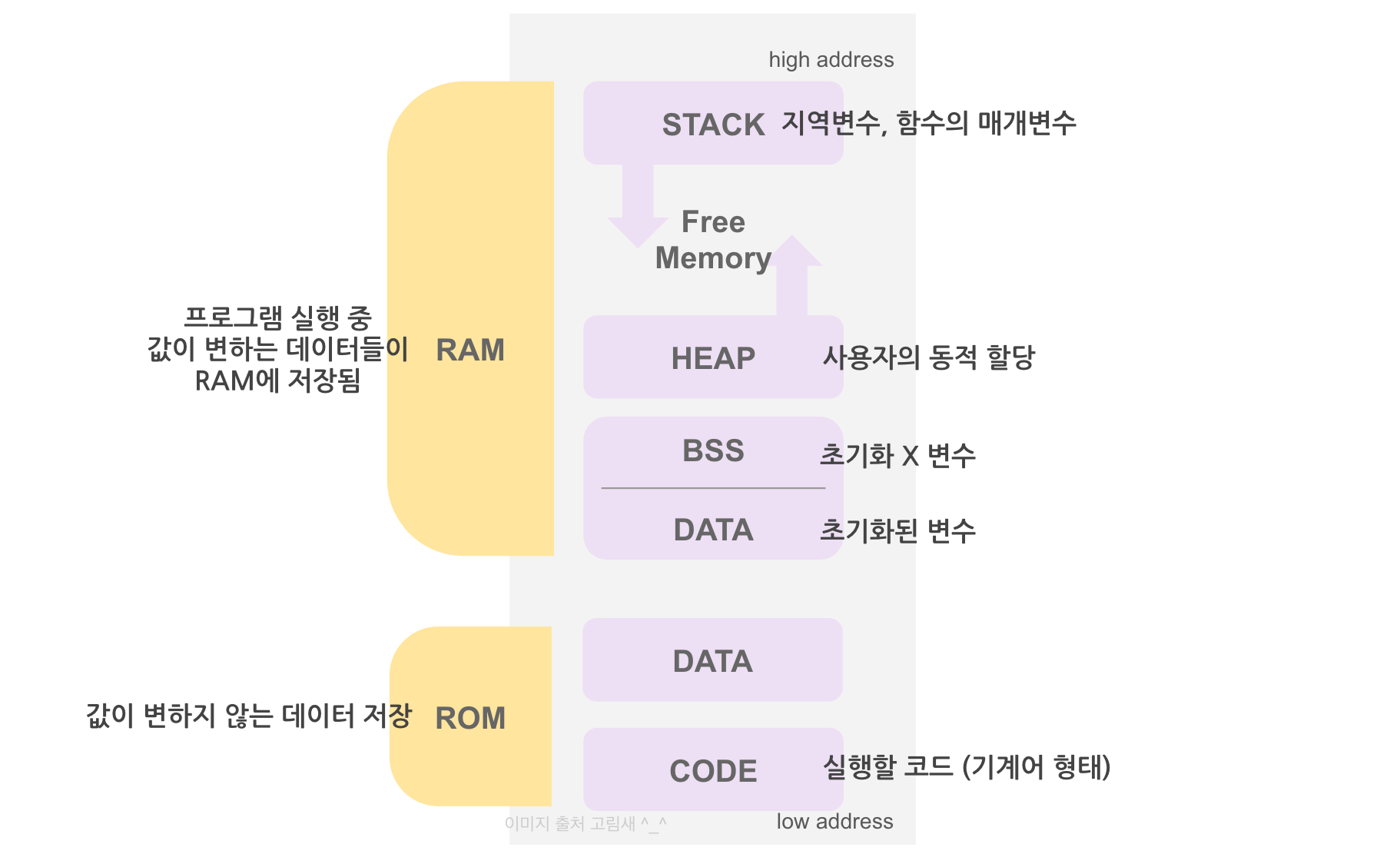
Code 영역(Text 영역)
- 사용자가 작성한 코드가 저장되는 영역이다. 즉, 실행할 프로그램의 코드가 저장되어 있는 영역.
- 이 코드는 컴파일된 후 기계어 형태로 저장되어 있다.
- 이렇게 컴퓨터에게 일을 시키는 실행 코드를 Instruction 이라고 한다.
- CPU는 코드 영역에 저장된 명령어를 하나씩 가져가서 처리한다.
- 프로그램이 실행되고 끝날 때까지 메모리에 남아있다.
- 읽기 전용
- 다른 프로세스에서 참조 가능한 영역 ← ???????????
Data 영역
- 프로그램의 전역 변수와 static 변수 등이 저장되어 있는 영역이다.
- 프로그램 실행 시, 전역 변수와 static 변수는 메인 함수가 호출되기 전에 데이터 영역에 할당된다.
- 프로그램이 실행되고 끝날 때까지 메모리에 남아있다.
- 데이터 영역은 BSS 영역, Data 영역으로 나뉜다.
- BSS(Block Stated Symbol) 영역
- Data 영역
- 초기화가 이루어진 변수들이 저장된다.
- 프로그램 실행 중 자유롭게 접근해서 수정, 변경이 가능하다.
- 사실 데이터 영역은 ROM에 위치하는데, 전역변수와 static 변수를 ROM에 저장하면 런타임 시 변경된 값이 적용되지 않고, 계속 초기값만을 가지고 있게 된다. (ROM은 read only니까!) 그래서 데이터 영역을 RAM에 복사해서 런타임 시 변경되는 값을 저장할 수 있도록 한다고 합니다. ..
- BSS와 Data 영역을 나누는 이유는?
- 초기화된 데이터는 ROM의 data 영역에 저장된다. 하지만 아직 초기화되지 않은 데이터들까지 ROM에 저장되면 큰 사이즈의 ROM이 필요하기 때문에 이 영역을 나눈다고 함..
Heap 영역
- 프로그램이 실행되는 동안 동적으로 사용할 데이터가 저장된다.
- 사용자가 직접 관리하는 영역이다. 즉, 사용자에 의해 메모리가 동적으로 할당, 해제된다.
class,closure와 같은 참조 타입의 데이터가 저장된다.- swift의 경우 ARC가 참조 타입의 할당, 해제 시점을 자동으로 관리한다
- Java의 경우 가비지 콜렉터가 관리함
- C의 경우 사용자가 동적으로 할당, 해제 해줘야 함. (malloc, free?)
- 메모리의 낮은 주소 → 높은 주소로 할당된다.
- 런타임 시(= 프로그램이 실행되는 도중)에 힙 영역의 크기가 결정된다.
Stack 영역
- 함수 호출 시 생성되는 지역 변수와 매개 변수가 저장된다.
- 즉, 함수 호출 시 할당되며 실행이 끝나면 메모리에서 해제된다.
- 프로그램이 사용하는 임시 메모리 영역 정도로 생각
- 함수 호출 시 스택에 push 되고, return 을 하면 스택에서 pop
- 할당과 해제를 반복하기 때문에 데이터의 용량이 불확실하다.
- 이렇게 스택 영역에 저장된 함수 호출 정보를 Stack Frame이라고 한다.
- struct, enum과 같은 값 타입의 데이터가 저장된다.
- 메모리의 높은 주소 → 낮은 주소로 할당된다.
- 왜 이렇게 할당하지??
- 컴파일 시에 할당될 영역의 크기가 결정된다.
- 운영체제에 따라 제한된 스택 영역의 크기가 다르다. 이 크기를 초과해 push 할 수 없음!
Stack 영역 vs Heap 영역
-
스택 영역과 힙 영역은 사실상 같은 공간을 사용한다. 그래서 스택 영역이 클 수록 힙 영역이 작아지고, 힙 영역이 클 수록 스택 영역이 작아진다.
-
스택 영역이 높은 주소 → 낮은 주소로 할당되고, 힙 영역이 낮은 주소 → 높은 주소로 할당되기 때문에 자신의 영역이 상대의 영역을 침범하는 사태가 발생할 수 있다. 이를 각각 스택 오버플로우, 힙 오버플로우 라고 한다.
-
할당 속도 비교
-
스택은 컴파일 시 이미 할당된 공간을 사용한다.
- 스택에서 말하는 할당이란 이미 생성된 스택에 대해 포인터의 위치만 바꿔주는 단순한 CPU Instruction을 말한다.
-
힙은 사용자가 따로 할당해서 사용하는 공간이다.
- 힙에서의 할당이란 요청된 chunk의 크기, 현재 메모리의 fragmentation 상황 등 다양한 요소를 고려하기 때문에 더 많은 CPU Instruction을 필요로 한다.→ 그러면 스택 할당 속도가 훨씬 빠르겠지요?
-
전역 변수와 지역 변수
- 하나의 프로세스는 여러 개의 스레드를 가질 수 있다. 이 때 스레드는, 프로세스의 모든 메모리 영역을 공유하는 것이 아니라,
code,data,heap영역만 공유하고,stack영역은 각자 가지고 있다. 그래서 스레드끼리 공유할 정보는 전역 변수로 선언해 data 영역에 저장되게끔 하고, 각 스레드에서 사용하고 끝나면 버릴(?) 정보는 지역 변수로 선언해 stack 영역에 저장되게끔 하면 된다. - 스레드를 하나의 함수처럼 생각하면 이해하기 쉬움 ~! 프로세스와 스레드에 관한 글은 이거 읽으세요 .. 아주 명문임 !!
swift에서 static을 사용하는 경우는 ..
..
swift ARC vs Java 가비지 콜렉터 ?
-
ARC
- 힙 영역의 데이터들이 얼마나 참조되고 있는지 count해서 메모리 할당/해제를 관리
- 즉, 컴파일 시에 reference counting을 함
- 어떻게 counting을 하는데?
- 컴파일 시 인스턴스 해제 시점을 알기 때문에 언제 이 인스턴스가 메모리에서 해제될 지 예측할 수 있다.
- 메모리 관리를 위한 시스템 자원을 추가할 필요가 없다.
-
가비지 콜렉터
-
프로그램 동작 중에 reference counting
-
프로그램을 동작할 때, 메모리 감시를 위한 추가 자원이 필요하다.
-
명확한 규칙이 없기 때문에 인스턴스가 언제 메모리에서 해제될 지 예측하기가 어려움.
(ㅈㅅ합니다 자바는 여기까지밖에 모릅니다...)
-
Reference
https://kant0116.tistory.com/17
