서론
내 주문 리스트를 조회하는 api를 작성했다.
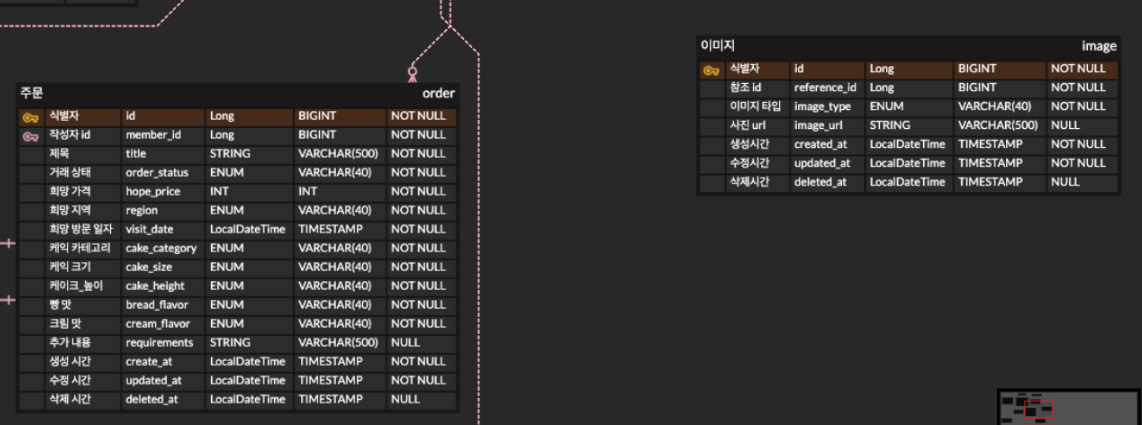
조회할 엔티티는 위와 같이 연관관계가 없는 두 테이블이다.
조건
- 주문과 이미지는 연관관계가 없는 1:N 관계이다.
(이미지 타입이 order이고, 참조 id가 order의 id와 같아야 한다.) - 주문과 매치되는 이미지가 여러개여도 리스트기 떄문에 첫번째 값만 반환한다.
- entity가 아닌 dto로 반환한다.
연관관계 없이 조인
세타조인 (from절에 조건 명시)
List<Order> orders = jpaQueryFactory
.select(qOrder)
.from(qOrder, qImage)
.where(
qOrder.id.eq(qImage.referenceId),
qImage.imageType.eq(ORDER)
)
.fetch();세타조인은 카티션 프로덕트 + select 연산으로 이루어지기 때문에 효율이 좋지 않다. 그리고 left outer join같은 외부 조인이 불가능 하다.
on절에 조건 명시
예전 버전은 안되지만 이제 연관관계가 없더라도 조인이 가능하다.
List<Order> orders = jpaQueryFactory
.select(qOrder, qImage)
.from(qOrder)
.leftJoin(qImage)
.on(
qOrder.id.eq(qImage.referenceId),
qImage.imageType.eq(ORDER)
)
.fetch();DTO로 반환
setter
List<OrdersResponse> orders = jpaQueryFactory
.select(Projections.bean(
OrderResponse.class,
order.id,
등등
)
)
.from(qOrder);생성자
필자는 객체를 생성할때 setter보다 생성자를 더 선호한다. 실수록 필드를 누락시킬 경우도 있고, 객체의 상태를 변경하는 코드가 흩어지기 때문이다.
List<OrdersResponse> orders = jpaQueryFactory
.select(Projections.constructor(
OrderResponse.class,
order.id,
등등
)
)
.from(qOrder);코드는 다를게 없다.
etc
QueryProjection어노테이션을 사용하면 DTO에 대해서도 q객체를 만들 수 있는데, 그렇게 되면 이렇게도 사용이 가능하다.
Map<OrdersResponse> orders = jpaQueryFactory
.select(new OrdersResponse(필드, 필드, 필드))
.from(qOrder);전체 코드
서론에 적은 조건을 다시 한번 보자.
- 1:N 관계에서 이미지가 존재하는 경우 첫 번째 이미지만 조회한다.
-> orderId key로 map에 넣어 중복을 없엔다. - 엔티티가 아닌 dto로 반환한다.
-> Projections로 DTO로 반환한다.
Map<Long, MyOrderResponse> myOrderResponseMap = jpaQueryFactory
.select(
//필요한 정보만 select
qOrder.id,
qOrder.title,
qOrder.orderStatus,
qOrder.region,
qOrder.visitDate,
qOrder.createdAt,
qOrder.cakeInfo,
qOrder.hopePrice,
qImage.imageUrl,
qOrder.offers
)
.from(qOrder)
.leftJoin(qImage)
//연관관계 없이 조인
.on(
qOrder.id.eq(qImage.referenceId),
qImage.imageType.eq(ORDER)
)
.where(
// 커서가 되는 시간보다 큰 데이터만 조회
gtVisitDate(cursorDate),
// 검색 조건 두가지
eqOrderStatus(option),
qOrder.memberId.eq(memberId)
)
.orderBy(qOrder.visitDate.asc(), qImage.id.asc())
// 요청하는 페이지 사이즈와 한 주문당 첨부할 수 있는 사진의 수
.limit(pageSize * MAX_PHOTOS_NUM_PER_ORDER)
// Map 으로 변환
.transform(
// key
groupBy(qOrder.id)
// value
.as(
Projections.constructor(
MyOrderResponse.class,
qOrder.id,
qOrder.title,
qOrder.orderStatus,
qOrder.region,
qOrder.visitDate,
qOrder.createdAt,
qOrder.cakeInfo,
qOrder.hopePrice,
qImage.imageUrl,
qOrder.offers.size()
)
)
);
// 페이지 사이즈 만큼 잘라서 list로 반환
if (myOrderResponseMap.size() > pageSize) {
return new ArrayList<>(myOrderResponseMap.values()).subList(0, pageSize);
}
return new ArrayList<>(myOrderResponseMap.values());
} 코드에 대한 대략적인 설명은 주석으로 적어놨다.
마무리
queryDsl을 사용하면 페이지 네이션, 동적쿼리, 연관관계 없이 조회, 1:N 중복값 제거, DTO로 반환하는 과정도 편하게 할 수 있다.
실제 쿼리를 호출했을때 소요 시간도 적게걸려서 현재 이대로 사용하고 있다.
무엇보다 queryDsl을 사용하면 컴파일 단계에서 휴먼에러를 방지할 수 있다는 장점이 있다.
한 가지 생각해볼점은 현재는 서버가 하나 올라가 있지만, 추후에 서버가 여러대 올라가있고, db가 1개 또는 replication을 해서 2개라고 가정할때 여러 서버가 db로부터 긴 트랜잭션을 가져가는 것이 좋은가에 대해 생각해볼 필요가 있다.
db에서는 각 데이터를 조회한 다음에, 각 서버의 메모리 영역에서 데이터를 조합해서 반환하는 것이 더 효율적이지 않을까?
